Yume-1.5: A Text-Controlled Interactive World Generation Model
Abstract: Recent approaches have demonstrated the promise of using diffusion models to generate interactive and explorable worlds. However, most of these methods face critical challenges such as excessively large parameter sizes, reliance on lengthy inference steps, and rapidly growing historical context, which severely limit real-time performance and lack text-controlled generation capabilities. To address these challenges, we propose \method, a novel framework designed to generate realistic, interactive, and continuous worlds from a single image or text prompt. \method achieves this through a carefully designed framework that supports keyboard-based exploration of the generated worlds. The framework comprises three core components: (1) a long-video generation framework integrating unified context compression with linear attention; (2) a real-time streaming acceleration strategy powered by bidirectional attention distillation and an enhanced text embedding scheme; (3) a text-controlled method for generating world events. We have provided the codebase in the supplementary material.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Yume1.5, a computer model that can create an explorable, moving “world” (like a first‑person video game scene) from either a short text description or a single picture. You can move around in this world using your keyboard (WASD and arrow keys), and you can also use text to trigger events (like “it starts raining” or “a cat runs across the street”). The big goal is to make these worlds look realistic, stay consistent over time, and run fast enough to feel interactive.
What questions did the researchers ask?
The authors focused on three simple questions:
- How can we make very long, continuous videos (worlds) without the computer slowing down or forgetting what happened earlier?
- How can we generate these videos fast enough to react to keyboard input in real time?
- How can we let text descriptions not only create the world but also trigger new events inside it while you’re exploring?
How did they do it?
To answer these questions, the team designed three main ideas. Below is a short explanation, using everyday language and analogies.
1) Building long videos efficiently: “TSCM” (Temporal–Spatial–Channel Modeling)
Problem: As a world gets longer, the model needs to “remember” more past frames. Keeping all details from the past makes things slow and heavy.
Idea: Compress the history smartly, like summarizing a long movie.
- Temporal and spatial compression: For older frames, keep fewer frames and smaller versions. For recent frames, keep more detail. This is like keeping high‑resolution photos of the last minute and tiny thumbnails of what happened ten minutes ago.
- Channel compression with fast “linear attention”: Think of each frame as not only a picture in time and space, but also a bundle of feature channels (like layers of information). They compress these channels for history frames and use a faster way to “pay attention” to them, so the model can still use their information without slowing down.
Why it helps: The model keeps the important “memory” of what happened before, but in a lighter, summarized form. This keeps quality high and speed stable, even as the world gets longer.
2) Making it run in real time: faster “few‑step” generation with a teacher–student trick
Problem: Diffusion models (the kind used here) usually need many small steps to create each frame; that’s too slow for interactive worlds.
Idea: Teach the model to do the same job in fewer steps.
- Teacher–student training: A “teacher” model shows what good results look like. A “student” model learns to match the teacher’s results but in far fewer steps—like learning to solve a math problem in 3 steps instead of 30.
- Train like it’s real use: During training, the model uses its own previously generated frames as history (not the perfect ground truth). This reduces mistakes piling up over time when you generate long videos.
Why it helps: You get high‑quality frames with just a few steps, which makes the world feel responsive to your keyboard input.
3) Letting text trigger events: separate “what happens” from “how you move”
Problem: You want both keyboard control (move/turn) and text control (trigger events like “a UFO appears”).
Idea: Split the text into two parts:
- Event description: What should happen in the world (e.g., “sudden heavy rain,” “a cat crosses the path,” “a dragon breathes fire”).
- Action description: What the camera/player is doing (based on keyboard inputs like W, A, S, D, and arrow keys).
Because action phrases are limited (like a small set of commands), the model can pre‑compute them, saving time. The event text only needs to be processed when something new happens.
Data and training in simple terms
- Real videos of walking and moving cameras were used to teach the model how first-person scenes change as you move. These motions were translated into keyboard commands (WASD + arrows).
- Extra synthetic videos (AI‑generated but high quality) kept the model’s general skills strong.
- Special “event” clips (like weather changes or fantasy scenes) helped it learn text‑triggered happenings.
- The model switches between text‑to‑video and image‑to‑video training so it’s good at both starting from text and continuing from an image.
What did they find?
- Real-time speed: On a single high‑end GPU, Yume1.5 can generate about 12 frames per second at 540p resolution using just a few steps per frame, which is fast enough to feel interactive.
- Better control: On a benchmark that checks whether the video follows instructions (like moving and turning correctly), Yume1.5 scored higher than other methods tested. It handles keyboard-driven camera motions more reliably.
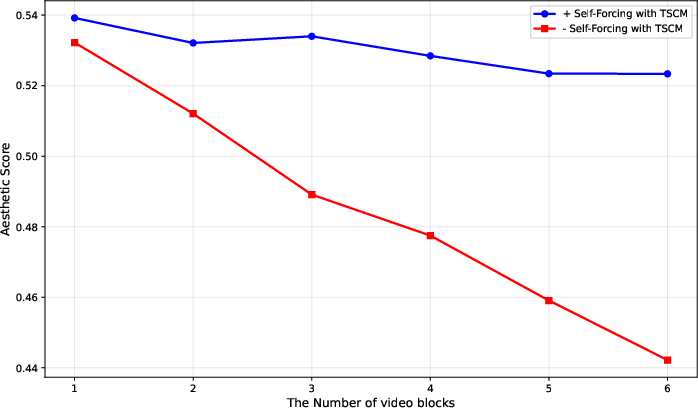
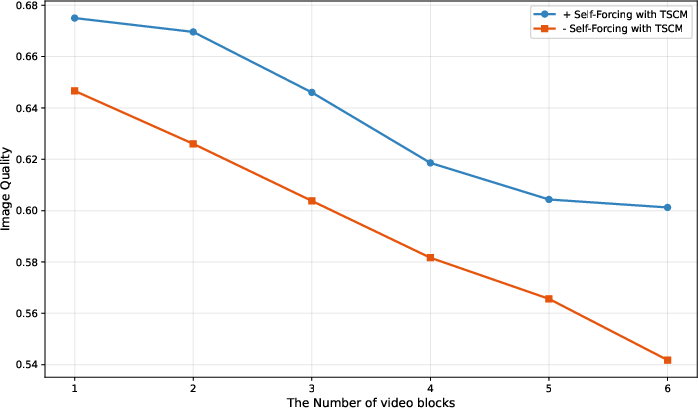
- Quality stays stable in long videos: As the video (world) goes on, Yume1.5’s visual quality (like aesthetics and image clarity) stays more consistent compared to versions without the new training and compression tricks.
- Multiple modes: It supports text‑to‑world, image‑to‑world, and text‑based event editing, all while you control movement with the keyboard.
Why this matters: Most earlier systems were either too slow for real‑time use, couldn’t handle very long, continuous worlds without losing track, or didn’t let text trigger new events mid‑exploration. Yume1.5 improves all three.
What could this change?
- Games and virtual worlds: Quickly create explorable scenes from a short description or a single picture, then add events on the fly with text. This could speed up prototyping and make creative tools more accessible.
- Simulation and training: Cheaply generate realistic, continuous environments for robotics, driving, or safety training, where worlds need to be long, consistent, and controllable.
- Storytelling and education: Teachers, students, and creators could turn ideas into interactive experiences with simple text prompts.
Limitations and future work
- Sometimes objects move oddly (like cars going backward) or crowded scenes look messy. Higher resolution helps a bit but doesn’t fully fix it.
- The current model size keeps speed manageable, but larger models might improve quality. The authors suggest using Mixture‑of‑Experts (MoE) to scale up without slowing down too much.
In short
Yume1.5 is like a fast, smart director for a first‑person movie you can walk through. It remembers the past efficiently, reacts in real time to your keyboard, and listens to your text to make new things happen. That combination—speed, memory, and control—makes it a strong step toward practical, text‑controlled interactive worlds.
Knowledge Gaps
Unresolved Knowledge Gaps and Open Questions
Below is a single, focused list of limitations, uncertainties, and missing analyses that remain open in the paper, phrased to enable concrete follow-up work:
- Quantify text-controlled event generation: no success-rate metrics for whether prompted events occur, when they occur (timing), where they occur (spatial localization), and how well they adhere to the specified attributes under interactive control.
- Long-horizon persistence and drift: no measurement of how scene layout, object identities, and camera pose stability degrade over long (>30 s) sessions; define and report maximum duration before semantic/world-state drift becomes unacceptable.
- World-state memory and object permanence: lacks mechanisms and metrics for tracking persistent entities across minutes (e.g., re-encountering the same car/person) and evaluating consistency of their attributes and positions.
- Physics and causality: no modeling or evaluation of physically plausible interactions (collisions, occlusions, cause-effect chains); assess whether events follow basic physical constraints and whether agents/objects behave consistently.
- Domain generalization: training/evaluation are dominated by urban walking and limited event categories; validate on diverse domains (indoor scenes, rural/natural environments, non-first-person viewpoints, nighttime/low-light, extreme weather).
- Interactive event composition: no support or evaluation for scheduling multiple sequential or overlapping events, conflict resolution between events, or interruptible/responsive events tied to user inputs.
- Camera control discretization: untested impact of discrete keyboard pose space on smoothness/fidelity versus continuous control; compare against explicit trajectory conditioning and analog controllers (gamepads/VR).
- Control latency and responsiveness: missing end-to-end latency breakdown (prompt/keyboard-to-frame), jitter analysis, and human-in-the-loop evaluation of responsiveness during fast camera motions.
- TSCM design sensitivity: no systematic study of compression ratios, temporal sampling policies, and their trade-offs; learnable/adaptive compression policies remain unexplored, as do scaling laws relating context length to speed/quality.
- Linear attention choice: lacks ablation versus alternative efficient attentions (FlashAttention-2, Performer, Hyena, Mamba) and kernel feature maps; quantify numerical stability, channel sensitivity, and quality-speed trade-offs.
- Self-Forcing with TSCM theory and limits: no convergence or error-accumulation analysis; evaluate performance across step counts (1, 2, 4, 8), context length, and teacher-student gaps; compare against KV-cache approaches at matched budgets.
- Event dataset coverage and bias: small (4k) curated set across four categories and heavy reliance on synthetic videos; measure prompt diversity, demographic/scene biases, and misalignment rates; incorporate real videos with verified event labels.
- Text-action embedding decomposition: no ablation proving the benefit of splitting Event vs Action descriptions; quantify T5 caching gains and alignment improvements versus single-caption baselines; assess sensitivity to LLM-generated caption errors.
- Evaluation breadth: instruction following focuses on camera/walking; add tasks requiring spatial navigation fidelity (e.g., reach a target), object tracking consistency, and map-building coherence; include human preference studies for interactivity/immersion.
- Real-time performance generality: 12 fps at 540p on A100 only; report memory footprint, throughput, and energy use across commodity GPUs (e.g., RTX 4070/3080), higher resolutions (720p/1080p), and longer contexts.
- Robustness and failure taxonomy: artifacts (vehicles/people moving backward) are noted but not analyzed; categorize failure modes, identify triggers (crowd density, motion speed, lighting), and evaluate mitigation strategies.
- Comparative baselines: limited comparisons (Wan-2.1, MatrixGame, Yume); include contemporary long-video generators and camera-control methods under matched conditions to isolate control vs quality contributions.
- Metrics for world coherence: VBench aesthetics/quality do not capture spatial/layout continuity or semantic consistency; develop and report metrics for map stability, object identity preservation, and event correctness over time.
- Determinism and reproducibility: no controls for randomness and seed determinism in interactive sessions; measure run-to-run variability in event occurrence and camera-following accuracy under identical inputs.
- Safety and content moderation: no strategy to prevent harmful/unsafe event generation (accidents, violence); propose and evaluate filtering/moderation pipelines and prompt-level constraints.
- Multimodal and 3D outputs: lacks audio, depth, segmentation, or 3D geometry; explore extending to audio-conditioned events, depth-consistent rendering, or layered scene representations enabling downstream simulation.
- Multi-agent and crowd scenarios: degraded performance in dense crowds; research model changes (e.g., agent-aware conditioning, higher-capacity motion modules) and training data to improve multi-agent realism and coordination.
- Persistent/shared worlds: no mechanism for saving/loading world state or synchronizing across multi-user sessions; investigate state serialization, networking, and consistency in collaborative exploration.
- Scaling strategies: MoE is suggested but untested; characterize latency, memory, routing stability, and quality impacts of MoE versus monolithic scaling for real-time interactive generation.
- Dataset governance and ethics: detail volunteer annotation protocols (inter-rater reliability), legal compliance of synthetic sources, and release/licensing status; assess potential privacy or bias implications before public deployment.
- Release readiness: weights/code are “will be made public”; specify exact release artifacts (models, training scripts, data processing pipelines), compute requirements, and minimal reproducible configurations for the community.
Practical Applications
Immediate Applications
The following applications can be deployed now with Yume1.5’s current capabilities (e.g., text/image-to-world generation, keyboard-based camera control, text-controlled event editing, real-time streaming at ~12 fps on a single A100, TSCM acceleration and linear attention).
- Interactive previsualization and world scouting (media/entertainment, software)
- Use Yume1.5 to turn text briefs or reference images into explorable virtual sets for storyboarding, blocking, and shot planning, with keyboard navigation and text-triggered events (e.g., “crowd appears,” “rain starts”).
- Tools/Products/Workflows: Unity/Unreal plugin for “text-to-set,” DCC integration (Maya/Blender) for previz plates, OBS plugin for live previz overlays.
- Assumptions/Dependencies: Requires GPU capacity (A100-class for stated performance), visual artifacts may occur (e.g., reversed walking), resolution constraints (~540p–720p), not a physically accurate simulator.
- Rapid prototyping for indie game studios and XR teams (gaming, XR/VR, software)
- Generate walkable mood boards, level sketches, and ambient scenes from text or concept art, with controllable camera and simple text-driven events to test pacing and navigation.
- Tools/Products/Workflows: Level prototyping toolkit (“Text-to-Level Draft”), keyboard-to-camera discretizer middleware, asset capture/export pipeline for later manual refinement.
- Assumptions/Dependencies: Domain gap vs. real gameplay constraints, no physics-grounded object interactions, content licensing and IP review for production use.
- Virtual tour and marketing content creation (marketing, real estate, architecture)
- Create immersive, explorable scenes (streets, lobbies, showrooms) from a single image or brief for early-stage client reviews, marketing reels, and social content.
- Tools/Products/Workflows: “Text-to-Tour” generator, real-time streaming overlay for pitches, scenario toggles via text (e.g., “sunset,” “busy foot traffic”).
- Assumptions/Dependencies: Not suitable for exact measurements or compliance reviews, realism/artifacts vary, disclosure needed that scenes are synthetic.
- Synthetic data augmentation for computer vision (academia, R&D, robotics/AV)
- Produce controllable urban walking scenes and rare text-triggered events (e.g., “jaywalker appears,” “vehicle cuts in”) for training/evaluation of perception, tracking, and camera control models.
- Tools/Products/Workflows: “EventInjector” for rare-case generation, data labeling pipeline using mixed captioning scheme (event/action decomposition), Yume-Bench metrics for quality checks.
- Assumptions/Dependencies: Domain gap vs. real-world data, artifacts can bias models, not recommended for safety-critical deployment without additional validation.
- Human-computer interaction and navigation research (academia, HCI)
- Study discrete keyboard-based camera control schemes and user navigation strategies in generative worlds; evaluate instruction-following via Yume-Bench.
- Tools/Products/Workflows: HCI sandbox with camera/action vocabularies, logging APIs for pose/trajectory adherence, experimental task runners.
- Assumptions/Dependencies: Experimental findings depend on generative world fidelity; needs reproducible seeds and versioned model weights.
- Education and storytelling exercises (education, daily life, creator economy)
- Students and creators can write prompts to generate explorable scenes and inject events for narrative practice, creative writing, or language learning (e.g., “describe a market and trigger a sudden downpour”).
- Tools/Products/Workflows: Classroom “Prompt-to-World” app, creator presets for genre events (urban, sci-fi, fantasy, weather).
- Assumptions/Dependencies: Content moderation required; GPU access; expectations managed for visual artifacts and limited controllability.
- Live streaming and experiential backgrounds (media, creator economy)
- Use Yume1.5 as a real-time ambient world generator behind streamers or stage performances; control camera via keyboard and trigger text events to match music or themes.
- Tools/Products/Workflows: OBS/VJ plugin, MIDI-to-event bridge (e.g., “drop confetti” at beat), low-latency streaming server with TSCM-enabled runs.
- Assumptions/Dependencies: Compute budget, framed resolution and fps constraints, content moderation and audience transparency.
- Model evaluation and benchmarking adoption (academia, AI tooling)
- Employ Yume-Bench metrics (instruction following, consistency, aesthetics) to evaluate new video diffusion models or control modules.
- Tools/Products/Workflows: Evaluation suite replication, reference datasets (Sekai-Real-HQ subset, curated event sets), protocol for long-form quality tracking.
- Assumptions/Dependencies: Access to evaluation data and codebase; consistent seeds; clear reporting of sampling steps vs. fps.
- Diffusion pipeline acceleration via TSCM (software, AI infra)
- Integrate joint temporal–spatial–channel modeling and linear attention into existing video diffusion backbones to reduce latency and manage long-context inference.
- Tools/Products/Workflows: “TSCM Inference Layer” library, attention distillation recipes (few-step inference) for real-time streaming.
- Assumptions/Dependencies: Access to backbone internals or fine-tuning hooks; compatibility with current attention stacks; QA on quality-vs-speed trade-offs.
- Scenario-based UX testing and signage prototyping (industry design, marketing)
- Generate explorable urban scenes and inject crowd/weather events to test visibility and wayfinding under varied conditions.
- Tools/Products/Workflows: “Scenario Studio” with text prompts for event variations; path-following tasks with instruction adherence scoring.
- Assumptions/Dependencies: Not physically precise; qualitative insights only; disclosure that scenes are synthetic.
Long-Term Applications
These applications require further research, scaling, integration with physics/agents, larger models or MoE, higher resolution, and validation to be feasible.
- Autonomous driving and robotics simulators with text-controlled rare events (automotive, robotics, policy)
- Inject controlled hazards (e.g., “child runs across street,” “sudden heavy rain”) into long, coherent urban drives; train/test perception and planning under rare conditions.
- Tools/Products/Workflows: “Generative Hazard Simulator” with event DSL, agent APIs to couple AV stacks, realism validation suite, physics-in-the-loop modules.
- Assumptions/Dependencies: Stronger physical realism and multi-agent dynamics, higher resolution and temporal coherence, regulatory acceptance; avoid artifacts that mislead training.
- City-scale digital twins and crowd management training (public sector, urban planning, emergency response)
- Persistent, explorable city models with text-driven crowd/weather/event scripts for evacuation drills, signage placement, and policy scenario testing.
- Tools/Products/Workflows: GIS integration, “EventScript DSL,” crowd simulators coupled to generative visuals, analytics dashboards for flow/visibility metrics.
- Assumptions/Dependencies: Validated crowd and traffic models, data governance, stakeholder transparency; integration with non-generative simulators.
- Embodied AI agent training in open-ended generative worlds (academia, AI research)
- Train memory-augmented agents in long-horizon tasks using Yume1.5’s infinite-context generation; program curricula via text events and keyboard-conditioned trajectories.
- Tools/Products/Workflows: Agent API and world state interfaces, memory managers built on TSCM, curriculum generators, evaluation harnesses for generalization.
- Assumptions/Dependencies: Stable long-term coherence, better controllability, standardized rewards/state representation; reduce artifacts that confound learning.
- Consumer-grade generative VR/AR experiences (XR, consumer tech)
- On-device real-time generation of explorable worlds guided by voice/text prompts and intuitive controls; dynamic event injection for personalized experiences.
- Tools/Products/Workflows: Model compression/MoE for edge devices, “Streaming Diffusion Server” for hybrid cloud-edge rendering, safety and content filters.
- Assumptions/Dependencies: Significant inference acceleration, thermal/power constraints, content moderation and UX safety.
- End-to-end virtual production (film/TV) with generative worlds (media/entertainment)
- Move from previz to production-quality plates: multi-camera control, 4K+ resolution, consistent lighting and high realism; scriptable world events for continuity.
- Tools/Products/Workflows: Camera tracking bridges, MoCap integration, denoising/super-res stack, asset locking for continuity, editorial review tools.
- Assumptions/Dependencies: Substantial fidelity and resolution improvements, predictable behavior under complex direction, rights/ownership and archival workflows.
- Emergency response and safety training scenarios (public safety, policy)
- Generate controlled training environments with text-triggered events (fires, floods, crowd surges) for responders; run exercises and after-action analyses.
- Tools/Products/Workflows: Scenario planner with event playbooks, logging/telemetry, integration with physical training props, policy-compliant reporting.
- Assumptions/Dependencies: Validated scenario realism, bias and fairness reviews, clear disclosure of synthetic nature; avoid miscalibrated risk perceptions.
- Sim2real research for navigation and perception (academia, robotics)
- Use generative worlds for domain randomization and robustness testing, then measure transfer to real platforms.
- Tools/Products/Workflows: Randomization suites coupling text events, physics augmenters, transfer metrics; “World Memory Manager” for consistent long-context generation.
- Assumptions/Dependencies: Better physical grounding, controllable distributions, rigorous real-world validation; improved artifact handling.
- Live generative venues and theme-park experiences (location-based entertainment)
- Large-scale clusters render audience-responsive worlds with event scripting and precise camera/object control for immersive shows.
- Tools/Products/Workflows: HPC render orchestration, low-latency control surfaces, safety systems, creative scripting tools.
- Assumptions/Dependencies: High compute budgets, reliability, safety and compliance; content moderation at scale.
- Cross-model acceleration layer for video generators (AI infra, software)
- Generalize TSCM and attention distillation into a reusable layer for long-form, low-latency generation across multiple backbones.
- Tools/Products/Workflows: “TSCM Runtime” microservice, model-agnostic adapters, profiling/QA suites for quality vs. speed.
- Assumptions/Dependencies: Access to model internals, standardized attention interfaces, robust assurances on quality under compression.
Global Assumptions and Dependencies
- Compute: Current real-time performance is reported on A100-class GPUs at ~12 fps (540p). Wider deployment requires optimization, model scaling (e.g., MoE), and/or cloud-edge orchestration.
- Fidelity and safety: Artifacts (e.g., reversed motion, crowd density degradation) can impact downstream uses; not suitable for safety-critical decisions without validation.
- Physics and multi-agent dynamics: Many long-term uses need physics-grounded behavior and agent simulation beyond current visual generation.
- Content governance: Licensing, rights, IP ownership, and content moderation must be addressed for industry and public sector adoption.
- Tooling and integration: Most applications depend on plugins, APIs, and adapters for engines (Unity/Unreal), OBS/DCC tools, GIS systems, and agent/simulator interfaces.
- Reproducibility and evaluation: Adoption in academia/policy requires transparent benchmarks (e.g., Yume-Bench), versioned models/data, and documented sampling settings.
Glossary
- Autoregressive: A generation or inference process where each new output depends on previously generated outputs. "enabling autoregressive generation of explorable and persistent virtual worlds."
- Bidirectional attention distillation: A training strategy that distills attention-based knowledge to accelerate generation while preserving quality, considering both directions of information flow. "a real-time streaming acceleration strategy powered by bidirectional attention distillation and an enhanced text embedding scheme;"
- CausVid: A method that combines transformer key-value caching with diffusion to support autoregressive video generation. "CausVid~\cite{yin2025slow} combines KV cache~\cite{vaswani2017attention} with a diffusion model to enable autoregressive inference."
- Catastrophic forgetting: The loss of previously learned capabilities when fine-tuning on new data. "relying solely on real-world data may lead to catastrophic forgetting."
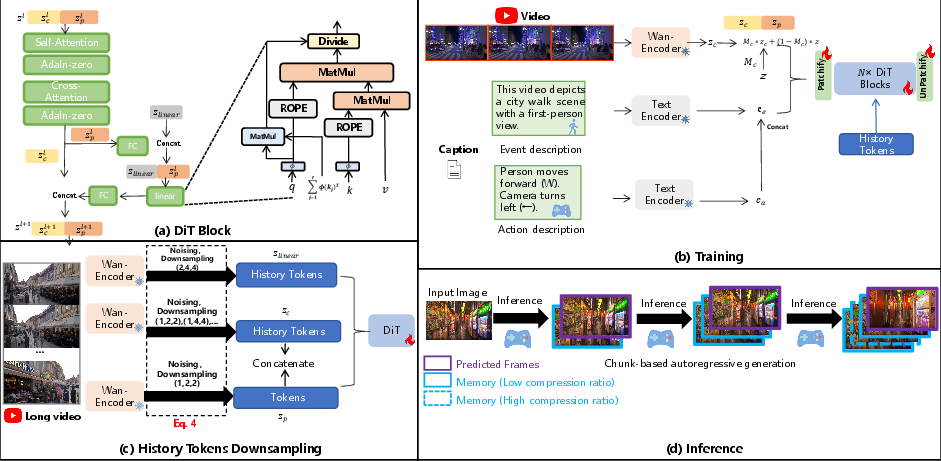
- Channel-wise compression: Reducing the dimensionality of feature channels to lower computation while preserving essential information. "we apply channel-wise compression to historical frames and fuse them with the prediction frame in the linear attention layer of the DiT block."
- Cross-attention: An attention mechanism that aligns and fuses information across different sequences or modalities. "After the video tokens pass through the cross-attention layer in the DiT block, they are first processed by a fully connected (FC) layer for channel reduction, after extracting the predicted frames , concatenate them with $z_{\text{linear}$."
- Diffusion models: Generative models that synthesize data by iteratively denoising from Gaussian noise according to a learned process. "Recent approaches have demonstrated the promise of using diffusion models to generate interactive and explorable worlds."
- DiT (Diffusion Transformer): A transformer-based diffusion architecture used as the backbone for video generation. "historical frames are compressed along temporal-spatial dimensions for input to the DiT~\cite{dit}, while channel-wise compressed features are processed by a parallel linear DiT."
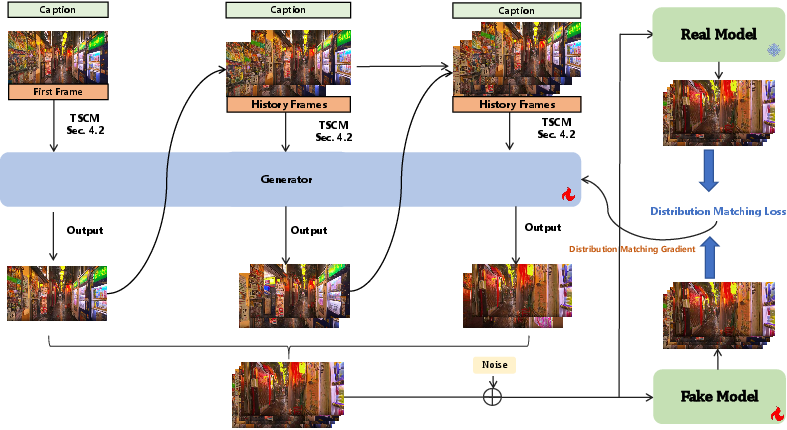
- Distribution Matching Distillation (DMD): A distillation technique that matches the generated data distribution to the real data distribution to enable few-step diffusion. "The key distinction from DMD lies in using model-predicted data rather than real data as video conditioning, thereby alleviating the train-inference discrepancy and associated error accumulation."
- Distribution matching gradient: The gradient used to align distributions between teacher and student models during distillation. "the Fake Model (student) is optimized to match the trajectory of the Real Model (teacher) via a distribution matching gradient."
- Event-driven generation: Generation that emphasizes dynamic events and their semantics rather than static scene description. "thereby enhancing the model's event-driven generation capabilities."
- Field-of-view overlap: The degree to which two camera views cover the same region, used for selecting relevant historical frames. "compute the field-of-view overlap between historical frames and the current frame to be predicted, selecting frames with the highest overlap."
- Forward diffusion: The process of progressively adding noise to data at specified timesteps in a diffusion framework. "where is the forward diffusion at step ~\cite{yin2024improved}."
- FramePack: A technique for compressing historical video frames with varying rates across time to manage context length. "Methods such as FramePack~\cite{zhang2025packing} and Yume~\cite{mao2025yume} compress historical frames, applying less compression to frames closer to the prediction frame and greater compression to those farther away."
- Image-to-Video (I2V): The task of generating a video conditioned on an input image. "Our Yume1.5 framework supports three interactive generation modes: text-to-world generation from descriptions, image-to-world generation from static images, and text-based event editing."
- Instruction Following: A metric assessing whether generated videos adhere to intended controls (e.g., camera motion and walking direction). "IF: Instruction Following"
- KV cache: Cached key-value pairs in transformer attention reused across timesteps to speed up sequence generation. "we replace the KV cache with our proposed TSCM, establishing a novel training paradigm."
- Latent Diffusion Models (LDMs): Diffusion models that operate in a compressed latent space to improve efficiency. "The adoption of Latent Diffusion Models (LDMs) was pivotal for efficiency, leading to works like Video LDM~\cite{Blattmann2023align} which integrated temporal awareness for high-resolution video."
- Linear attention: An attention mechanism with linear complexity in sequence length using kernel feature maps instead of softmax. "The combined tokens are fused via a linear attention layer to produce $z^l_{\text{fus}$."
- Mixture-of-Experts (MoE): An architecture that routes inputs to specialized expert subnetworks to increase capacity without proportional cost. "Inspired by Wan2.2, we consider exploring Mixture-of-Experts (MoE) architectures as a promising direction to achieve both larger parameter counts and reduced inference latency."
- Patchify: A module that converts images or video frames into patch tokens (often with downsampling) for transformer processing. "followed by using a high-compression-ratio Patchify."
- Rectified Flow loss: A training objective for flow-based generative modeling that rectifies trajectories to improve sampling. "The model is trained using the Rectified Flow loss~\cite{liu2022flow}."
- ROPE (Rotary Positional Embeddings): A positional encoding technique that rotates query/key vectors to encode relative positions. "prior to applying ROPE to and , while incorporating normalization layers to prevent gradient instability."
- Self-Forcing: A training/inference paradigm where the model uses its own generated frames as context to reduce error accumulation. "we designed an approach similar to Self-Forcing~\cite{huang2025self} to mitigate this issue."
- Sliding window: A strategy that uses a fixed-size window of recent frames as context for predicting the next frames. "adopts a diffusion forcing~\cite{chen2024diffusion} framework and employs a sliding window approach, using the last few generated frames as 'historical context' or conditioning to predict and generate subsequent video segments."
- Space-Time U-Net: A U-Net architecture adapted to jointly process spatial and temporal dimensions for video generation. "Large-scale models like Google's Lumiere~\cite{BarTal2024lumiere}, featuring a Space-Time U-Net, ..."
- Subject Consistency: A metric evaluating the consistency of the main subject across frames. "SC: Subject Consistency"
- Temporal-Spatial-Channel Modeling (TSCM): A joint compression and fusion strategy across time, space, and channels for long-context video generation. "We propose Joint Temporal-Spatial-Channel Modeling (TSCM) for infinite-context generation, which maintains stable sampling speed despite increasing context length."
- Text-to-Video (T2V): The task of generating videos conditioned on a textual description. "To enhance model training and enable both Text-to-Video (T2V) and Image-to-Video (I2V) capabilities, we constructed a comprehensive dataset..."
- VBench: A benchmarking suite and set of metrics for assessing video generation quality. "We then computed quality scores using VBench~\cite{huang2024vbench} and filtered the results to retain the top 50,000 videos."
- Video diffusion models: Diffusion models extended to video to generate temporally coherent sequences. "Video diffusion models~\cite{Singer2023makeavideo,BarTal2024lumiere,Blattmann2023stablevideo,Ma2024hunyuanvideo,Nagrath2024mochi,Singer2023makeavideo,StepVideo2025technical,Chen2025skyreelsv2}, which have shown remarkable capabilities in synthesizing high-fidelity and temporally coherent visual content..."
- World Memory: A technique that uses camera trajectory overlap to select historical frames most relevant to the current prediction. "Approaches like World Memory~\cite{xiao2025worldmem} leverage known camera trajectories to compute the field-of-view overlap between historical frames and the current frame to be predicted, selecting frames with the highest overlap."
Collections
Sign up for free to add this paper to one or more collections.