- The paper proposes an intermediate spatial value map interface that decouples future video prediction from action generation for efficient robotic manipulation.
- It employs a two-stage training protocol with intent-causal attention and GRPO-based policy optimization to enhance sample efficiency and robustness.
- Experiments on RoboTwin 2.0 demonstrate state-of-the-art performance with success rates of 94.0% (Easy) and 92.1% (Hard) across various manipulation tasks.
AIM: Intent-Aware Unified World Action Modeling with Spatial Value Maps
Motivation and Problem Statement
Existing unified world action models, which build on strong pretrained video generation backbones, exhibit limitations in robot control: decoding reliable actions from future visual representations remains data- and adaptation-intensive because the action inference is confounded by dense, task-agnostic appearance signals. The core issue is a structural mismatch between world modeling (what changes visually) and control execution (where and why to interact). Robotic manipulation necessitates explicit spatial reasoning about interaction regions and manipulation intent, which are only implicitly encoded in prior generative or VLA approaches.
AIM Model: Spatial Value Map Interface for World-to-Action Decoding
The proposed AIM model precisely addresses this by introducing an explicit spatial value map interface between video-based future prediction and action generation. Rather than directly inferring control actions from future visual latents, AIM decodes an intermediate value map spatially aligned with forthcoming RGB observations, encoding task-relevant interaction structures in a control-oriented abstraction. Actions are then conditioned on this value map, bridging the gap between perception and actionable intent.
The high-level contrast between classical models and AIM is captured in (Figure 1):
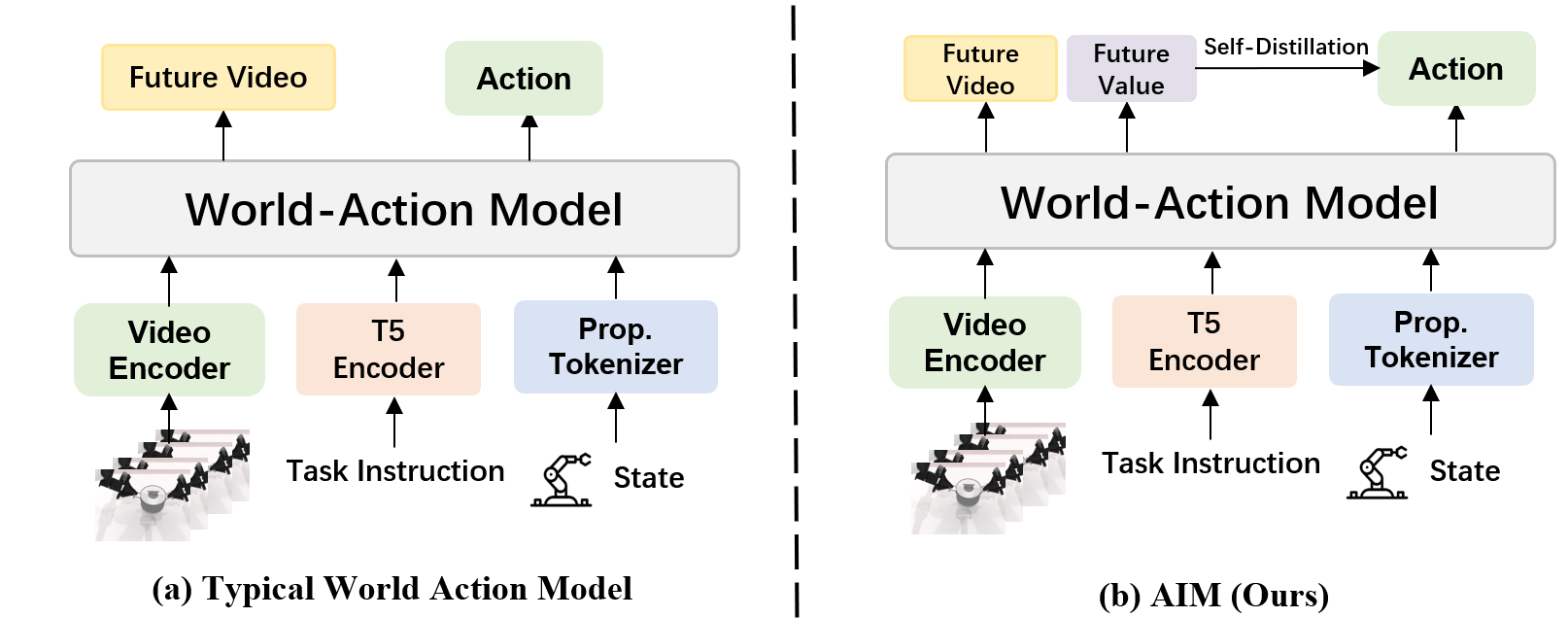
Figure 1: (a) Traditional world action models decode actions directly from visual futures; (b) AIM inserts an intermediate, spatially-aligned value map as the control interface.
AIM utilizes a pretrained visual backbone (Wan2.2-TI2V-5B), adapting it via mixture-of-transformers to jointly model future frames, spatial value maps, and actions. Key to AIM is the “intent-causal attention” mechanism: action decoding only attends to predicted value maps, not the dense future video tokens, enforcing structural disentanglement between world and action reasoning.
The architecture and sequential training protocol are shown in (Figure 2):
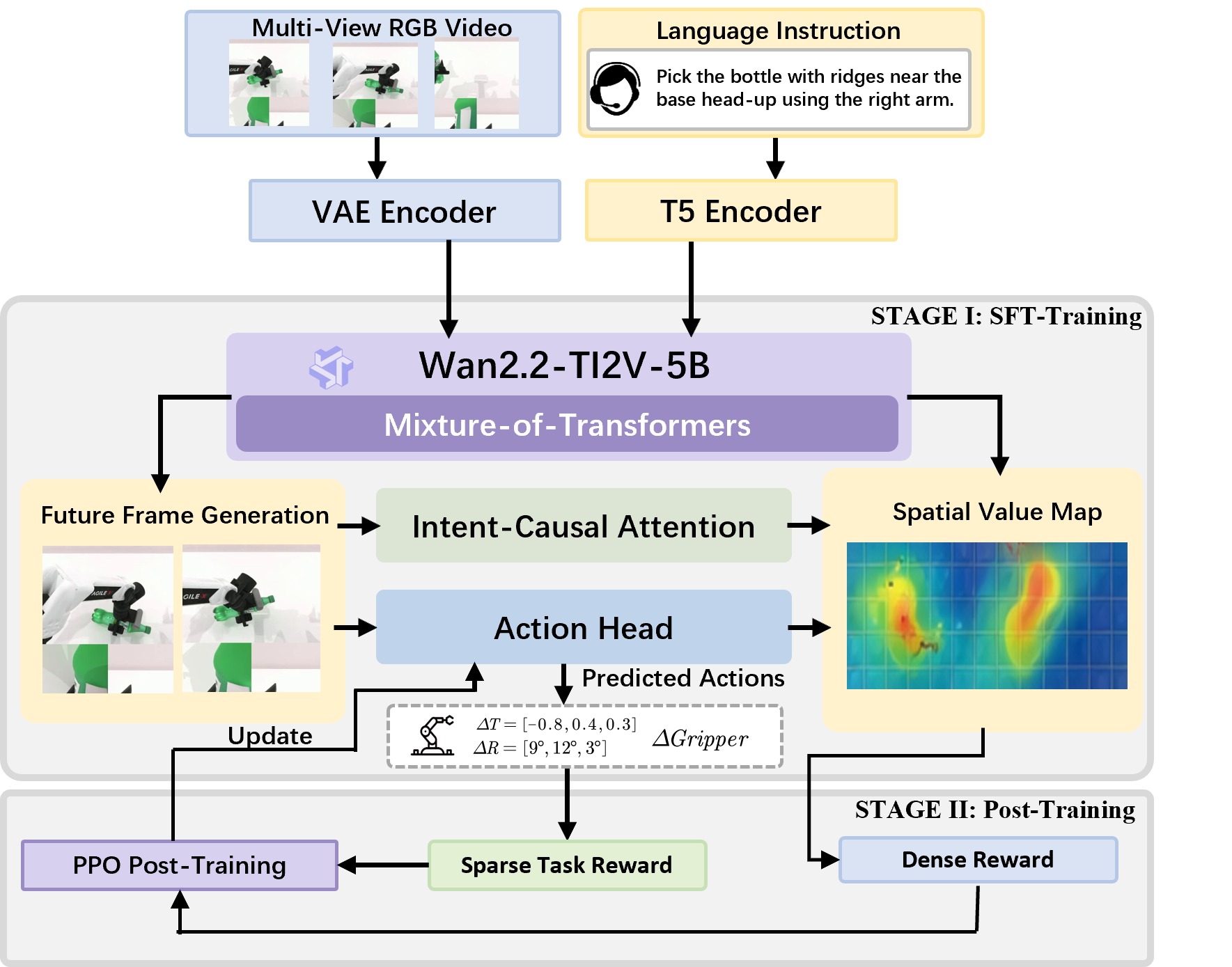
Figure 2: The AIM framework: Stage I jointly learns visual prediction, action generation, and value-map modeling via intent-causal attention. Stage II applies policy optimization (GRPO), finetuning only the action head against dense/sparse rewards derived from value map responses.
Methodology Details
Data and Tokenization
AIM operates on manipulation trajectories with synchronized multi-view video, action vectors, and per-step value map annotations (highlighting contact/affordance regions via simulator-based ground-truth generation). Video and value maps are discretized using a shared VAE tokenizer, maintaining geometric alignment; actions are projected to tokens via an MLP, and linguistic instructions are encoded by a pretrained T5 encoder, injected only into the world modeling pipeline.
Policy Factorization and Attention Structure
AIM factorizes the predictive model as:
p(X+,M+,A+∣Ht)=p(X+,M+∣Ht)p(A+∣Ht,M+)
with Ht denoting the history window. Under the intent-causal self-attention, action tokens are restricted visibilities: at each transformer layer, actions can access only the value tokens—not future video tokens or direct language features. This forces manipulation intent to be mediated through an interpretable, spatially localized map, simplifying inverse dynamics learning for the action head.
Self-Distillation Reinforcement Learning
AIM incorporates a two-stage training paradigm: initial supervised chunked sequence prediction (joint world, value, and action learning), followed by RL-based policy optimization (Stage II) focused exclusively on the action head. The world and value branches are frozen; the action head is updated via GRPO, driven by (i) sparse environment reward and (ii) dense, model-derived reward from the alignment of executed actions with high-value map regions (self-distillation). This approach stabilizes visual semantics and prevents catastrophic forgetting of visual priors.
Dataset and Value Map Supervision
The study introduces a comprehensive simulation dataset on RoboTwin 2.0, providing 30K trajectories. Value maps are annotated by simulating grasp/contact (pick) or object placement (place), projecting physical contact areas into the observation space, and producing Gaussian-smoothed affordance maps. This enables consistent, large-scale spatial supervision critical for explicit interaction reasoning.
Experimental Results
AIM is evaluated on 50 RoboTwin 2.0 manipulation tasks under both Easy and Hard settings, systematically compared to leading world-action and VLA baselines including π0.5, Motus, X-VLA, Fast-WAM, GigaWorld, and LingBot-VA. AIM achieves an average SR of 94.0% (Easy) / 92.1% (Hard), outperforming all external baselines and delivering the strongest success rates, particularly on tasks demanding long-horizon planning or precise spatial contact (see the representative task executions in (Figure 3)).

Figure 3: Qualitative rollouts on complex RoboTwin 2.0 tasks, demonstrating temporally-aligned visual prediction and stage-localized value maps directing interaction.
AIM’s explicit value-map interface confers especially robust gains on contact-sensitive and spatially localized manipulation tasks, where prior models falter by overfitting to appearance features or failing to identify actionable regions.
Discussion and Implications
The introduction of a spatial value map as an explicit, temporally grounded intent interface decouples visual prediction from control requirements, enabling more sample-efficient and interpretable action generation. This design solves the task sparsity and intent localization challenge that plagues dense action-from-video methods. The two-stage training protocol, utilizing self-distilled dense rewards from frozen value maps, demonstrates stable policy finetuning without retraining the entire generative backbone.
Practically, AIM advances the construction of generalist robot policies by enabling more reliable action decoding across diverse tasks without expensive robot-specific data. Theoretically, it provides further evidence that intermediate, spatially grounded intent representations are not only beneficial but essential for efficient visuomotor control. Related avenues for future work include scaling this spatial value framework to real-world robot vision under partial observability and extending the value map concept toward 3D/affordance reasoning in unstructured settings.
Conclusion
AIM redefines world-to-action modeling for robotic manipulation by introducing an intent-causal, spatial value map interface, backed by a principled mixture-of-transformers architecture and a robust two-phase training regime. The resultant system achieves state-of-the-art control success on the RoboTwin 2.0 benchmark, evidencing the value of explicit spatial reasoning for generalizable, interpretable robotic action generation. Continued exploration of spatial intent interfaces holds promise for bridging generative world models and actionable control in embodied AI.