- The paper presents a unified framework that integrates egocentric video synthesis conditioned on full-body 3D actions and anchor-view customization.
- The methodology employs hybrid-view training and projection-based spatial grounding to achieve state-of-the-art metrics in scene consistency and camera accuracy.
- The results illustrate improved dynamic evolution and robust performance across both simulated and real-world environments.
AnchorWorld: Embodied Egocentric World Simulation with View-Based Evolution Customization
AnchorWorld addresses the longstanding challenge in interactive egocentric world modeling: achieving spatially precise human-action-conditioned visual synthesis while supporting flexible, local world-state customization and dynamic evolution. Unlike prior works that rely on coarse control signals (e.g., camera trajectories, text prompts) or limited bodily action cues, AnchorWorld formalizes world-customizable embodied egocentric simulation. This involves two distinct control streams:
- Human Motion Control: Egocentric navigation and interaction are conditioned on full-body 3D actions, enabling nuanced correspondence between visual output and embodied agent behaviors—even outside the camera's field of view.
- Anchor-View World Customization: World states are defined locally via anchor views, each comprising an appearance image, a spatial pose, and an evolution prompt, affording explicit, spatially grounded specification of scene content, including regions initially out-of-sight.
AnchorWorld intervenes by creating a unified framework where first-person and third-person viewpoints are jointly leveraged for robust action-driven synthesis, and anchor views enable temporally controlled, spatially coherent world evolution.
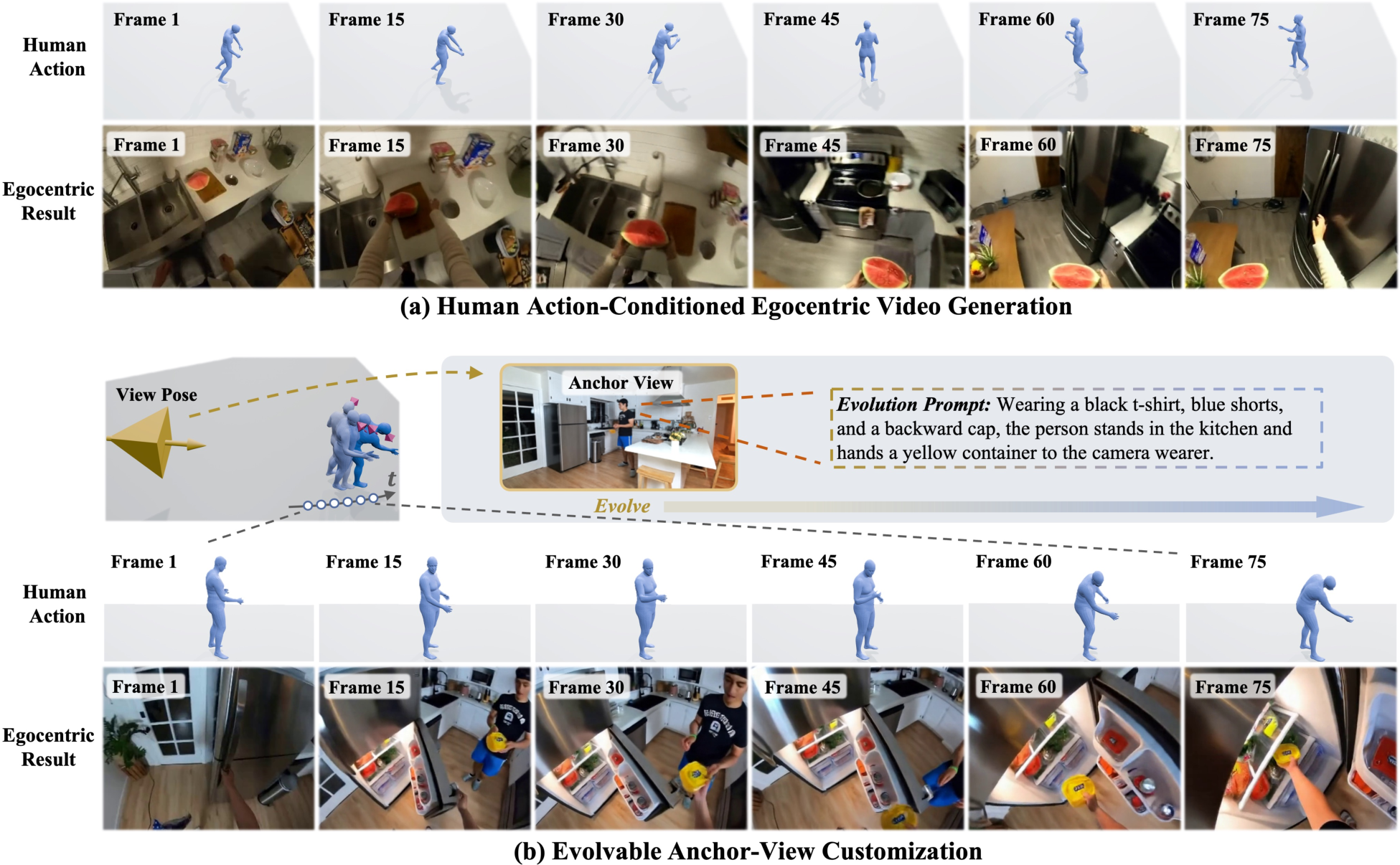
Figure 1: AnchorWorld synthesizes egocentric videos conditioned on human action and initial ego-view frame, and supports explicit world customization via anchor views.
Methodology: Unified Action and World-State Control
Hybrid-View Action Conditioning
AnchorWorld incorporates hybrid-view training: third-person videos provide full visibility of body motion and interactions for auxiliary supervision, while first-person videos deliver the natural egocentric perspective. Action conditioning is projection-based, pairing SMPL-X human motion with camera pose, fusing root global navigation and local limb interactions.
Spatial pose attention injects motion encoding and camera trajectory into the latent video representation, ensuring frame-wise alignment and robust spatial grounding. This approach circumvents view truncation inherent to egocentric data and benefits from rich TPV supervision.
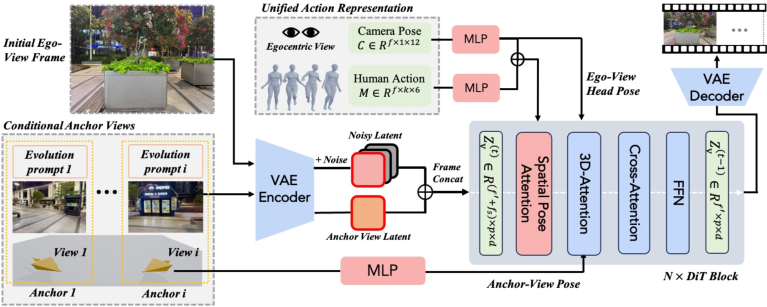
Figure 2: Egocentric video synthesis conditioned on spatial pose-aware action streams and anchor views; anchor view attributes (RGB, pose, evolution prompt) are injected for world customization.
Anchor-View World Customization
World customization is realized through anchor views. Each anchor includes:
- RGB Image: Specifies local appearance.
- 6-DoF Pose: Explicit spatial grounding within a unified world coordinate system.
- Evolution Prompt: Semantic description governing local state changes.
Anchor views are contextually injected via concatenation of image latents and spatial pose embeddings, further facilitated by position-aware embedding (RoPE) to disambiguate views. Evolution prompts are incorporated through masked cross-attention, restricting semantic influence to relevant visual tokens for localized dynamics.
Progressive Multi-Stage Training
AnchorWorld employs progressive, multi-stage training:
- Stage I: Pre-train on TPV action data for projection-based spatial grounding.
- Stage II: Adapt to FPV action using head-aligned camera trajectory.
- Stage III: Static anchor-view customization for pose-aware consistency.
- Stage IV: Dynamic evolution with anchor-specific prompts for temporally evolving world states.
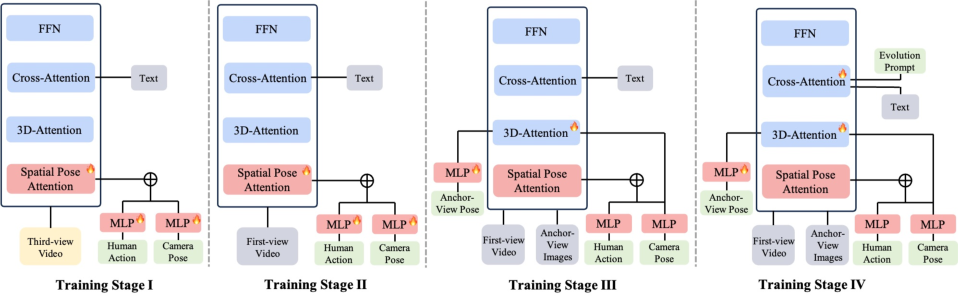
Figure 3: Multi-stage training progression, sequentially equipping action control and anchor-view customization.
Experimental Results
Quantitative Evaluation
AnchorWorld demonstrates superior quantitative performance across all relevant metrics:
- Scene Consistency: Highest GIM-based matched pixel ratio ($4493.4$ for static ego scenes), CLIP-V semantic similarity ($0.885$), PSNR ($16.06$), SSIM ($0.578$), and lowest LPIPS ($0.470$).
- Camera Accuracy: Lowest Absolute Translation Error ($0.112$), Relative Translation Error ($0.029$), and Relative Rotation Error ($3.145$).
- Dynamic Evolution: Outperforms in VideoAlign text-alignment ($0.717$).
- Video Quality: Matches or exceeds baselines on VBench composite measures ($0.748$ for static, $0.885$0 for dynamic scenes).
Strong generalization is observed on out-of-distribution UE and real-world scenes, particularly in cases with non-overlapping viewpoints and anchor-view manipulation.
Qualitative Analysis
AnchorWorld achieves robust egocentric action control and scene consistency under large viewpoint changes, and superior dynamic scene evolution driven by anchor-specific evolution prompts.

Figure 4: Qualitative comparison: improved egocentric action control, scene consistency, and dynamic evolution relative to baselines.

Figure 5: AnchorWorld generalizes to rendered UE scenes and real-world capture, maintaining spatial integrity across diverse settings.
Figures reveal precise spatial pose awareness, effective out-of-sight scene evolution, and anchor-specific control even when local appearance overlaps (or does not) with current ego-view.
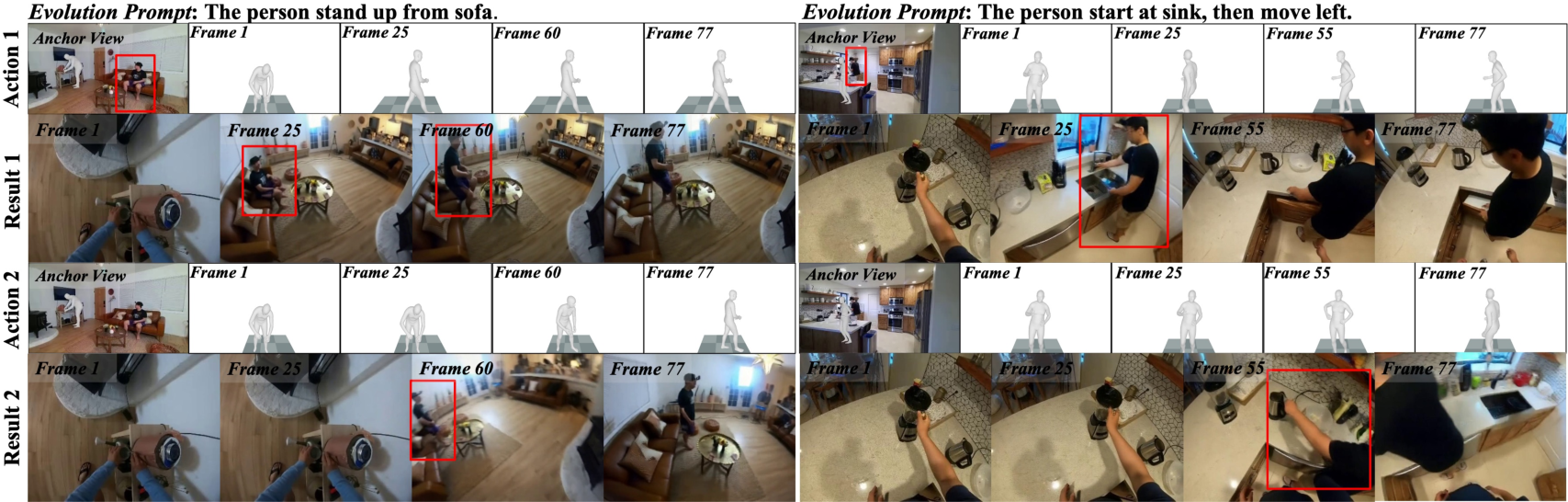
Figure 6: Model infers state changes in dynamic elements beyond observed views, reasoning about scene evolution.

Figure 7: AnchorWorld maintains spatial pose awareness: pose flipping experiments demonstrate overlap-based detail retrieval.

Figure 8: Evolution prompt manipulation drives local scene transitions, confirming prompt-controllable dynamic evolution.
Ablation Studies and Analyses
Ablations on training stage composition, anchor-view pose encoding, projection-based control, and RoPE embedding affirm the necessity of each design, with marked deterioration in action accuracy and scene consistency upon removal of key components.
Increasing anchor views further improves scene consistency metrics, substantiating the model’s ability to integrate multi-view spatial constraints.
Limitations and Future Directions
AnchorWorld is constrained by the base model capacity, yielding inconsistent fine-grained details in locally complex regions and blurry artifacts when training data contains rapid viewpoint changes. Future directions include:
Conclusion
AnchorWorld establishes a scalable framework for embodied egocentric simulation, integrating hybrid-view action supervision with spatially explicit, anchor-driven world customization, further empowering text-driven local dynamic control. Extensive empirical validation underscores its superiority in action-conditioned synthesis, spatial consistency under viewpoint transitions, and flexible dynamic world evolution. This work paves the way for future advancements in embodied AI, interactive virtual environments, and customizable real-time simulation, with implications for robotics, AR/VR, and human-centric generative visual modeling.
