Walk through Paintings: Egocentric World Models from Internet Priors
Abstract: What if a video generation model could not only imagine a plausible future, but the correct one, accurately reflecting how the world changes with each action? We address this question by presenting the Egocentric World Model (EgoWM), a simple, architecture-agnostic method that transforms any pretrained video diffusion model into an action-conditioned world model, enabling controllable future prediction. Rather than training from scratch, we repurpose the rich world priors of Internet-scale video models and inject motor commands through lightweight conditioning layers. This allows the model to follow actions faithfully while preserving realism and strong generalization. Our approach scales naturally across embodiments and action spaces, ranging from 3-DoF mobile robots to 25-DoF humanoids, where predicting egocentric joint-angle-driven dynamics is substantially more challenging. The model produces coherent rollouts for both navigation and manipulation tasks, requiring only modest fine-tuning. To evaluate physical correctness independently of visual appearance, we introduce the Structural Consistency Score (SCS), which measures whether stable scene elements evolve consistently with the provided actions. EgoWM improves SCS by up to 80 percent over prior state-of-the-art navigation world models, while achieving up to six times lower inference latency and robust generalization to unseen environments, including navigation inside paintings.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a video-making AI to not just imagine any future, but the correct future that matches what a robot actually does. The authors build a system called Egocentric World Model (EgoWM) that can predict what a robot will see next from its own camera when it takes a series of actions—like moving forward, turning, or moving its arms and hands.
“Egocentric” means the camera is on the robot, so the video shows what the robot itself would see. A “world model” is an AI that can mentally simulate how the world changes when you do something, which is crucial for planning and making decisions.
What questions did the researchers ask?
They focused on simple, practical questions:
- Can we take powerful video generators trained on internet videos and make them follow robot actions, instead of training a new model from scratch?
- Will this work for many kinds of robots, from simple wheeled robots to full humanoids with lots of moving joints?
- Can the predictions be both realistic and physically correct—meaning that the world moves the way it should when the robot acts?
- How do we fairly measure “physical correctness,” not just whether the video looks pretty?
How did they do it?
They start with big, pre-trained video diffusion models. These are AIs that make short videos by starting with random noise and cleaning it up step-by-step, like a sculptor slowly carving a statue from a block. Because they were trained on tons of internet videos, these models already “know” a lot about how the world looks and moves.
Step 1: Use internet video knowledge
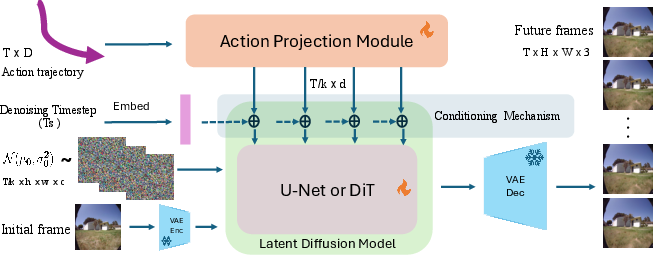
- Instead of training a new model from scratch, they take existing video generators and keep their visual understanding.
- This saves time and lets the model generalize to new places and even unusual styles (like paintings).
Step 2: Teach the model to obey actions
- Robots have “actions” they take over time. For a simple robot, that might be move forward, move sideways, and turn (3 degrees of freedom, or 3-DoF). For a humanoid, it might be 25 different joint angles for legs, arms, head, and hands (25-DoF).
- The team turns each action sequence into a set of small vectors (think: a compact summary) using tiny neural networks.
- They inject these action summaries into the video model through its existing “timestep” pathway. The timestep is like a metronome the model uses to keep track of which step of the denoising process it’s on. By adding the action signal along this path, the model naturally learns to move the scene in sync with the robot’s commands—no big architectural changes needed.
- For humanoids (where not all body parts are visible), they also include the robot’s starting pose, so the model knows how the body is arranged before moving.
Analogy: Imagine the video model is a skilled filmmaker who knows how scenes should look. The “timestep” is the beat they edit to. The “action conditioning” is like handing them a storyboard that says “now turn right,” “now reach out,” and they incorporate that into their edit so the video follows the plan.
Step 3: Measure physical correctness with a new score
- Pretty videos aren’t always correct. A model might make sharp, realistic frames but drift the wrong way.
- The authors propose the Structural Consistency Score (SCS). It tracks stable objects in the scene (like walls and furniture) and checks if those objects move in the generated video the same way they do in the real video for the same actions.
- This focuses on structure and motion, not just appearance, so it better reflects whether the model truly followed the actions.
What did they find, and why does it matter?
In tests across several datasets (indoor, outdoor, and humanoid navigation and manipulation), the method worked well. Here are the key takeaways:
- Better action-following: Their model improved the Structural Consistency Score (SCS) by up to about 80% compared to a strong prior system called Navigation World Models (NWM). This means the predicted videos tracked the true motion of the world much more accurately.
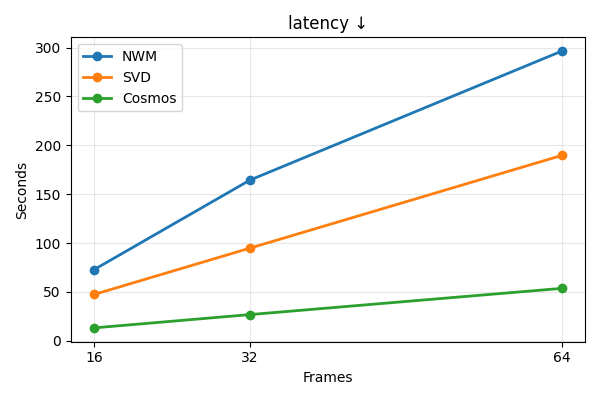
- Faster and more practical: It ran up to about 6 times faster than the baseline in some settings, which is important for real-time use.
- Works across many robots and tasks: It handled simple 3-DoF navigation and complex 25-DoF humanoid control (walking, reaching, grasping) without changing the core architecture.
- High-quality visuals: Because it starts from big internet-trained video models, the results look sharp and realistic.
- Generalizes to new and unusual environments: Amazingly, it can even “walk through” paintings—following action commands while respecting the painted style—because of the broad visual knowledge learned from internet-scale data.
- Needs only modest fine-tuning: Since it reuses pre-trained models, it requires much less paired “action + video” data to get good results.
Why is this important?
- For robotics: Robots need to predict what will happen when they act. A reliable, action-aware video predictor helps with planning, safety, and smoother control, both for moving around and manipulating objects.
- For scalability: Collecting huge robot datasets for every new robot or setting is expensive. Reusing internet-trained models makes world modeling more accessible and flexible.
- For evaluation: The new SCS metric helps the community measure physical correctness, not just visual quality—nudging future research toward models that truly understand how actions change the world.
- For creativity and simulation: The ability to “walk through paintings” hints at broader uses in simulation, education, games, and creative tools—models that respect both style and motion.
In short, this work shows a simple, powerful way to turn general video generators into action-following world models that are fast, flexible, and accurate—bringing us closer to robots and tools that can plan and act safely in many kinds of worlds.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps, limitations, and open questions that remain unresolved, intended to guide future research.
- Closed-loop control and planning: The paper does not evaluate using EgoWM in feedback loops (e.g., MPC or RL) to control real robots; measure task success rates, stability, and sample efficiency when the model informs action selection.
- Long-horizon stability: Results are limited to 16–64 frames; quantify error accumulation, drift, and recovery strategies for 100–1000+ frame horizons, including curriculum training and trajectory stitching.
- Data efficiency and scaling laws: The amount of paired action–video data required is not reported; run controlled studies varying data size and diversity to derive scaling laws for SCS, LPIPS, and DreamSim across embodiments.
- Generality across architectures: Claims of architecture-agnostic conditioning are tested only on SVD (U-Net) and Cosmos (DiT); validate on additional backbones (e.g., Wan, CogVideoX, VideoCrafter2 variants, flow-matching models) and report consistent conditioning APIs and performance.
- Conditioning design ablations: No comparison of additive timestep modulation versus alternatives (cross-attention control tokens, FiLM at specific layers, adapter blocks, LoRA); systematically evaluate injection locations (early vs. late, temporal blocks) and parameterizations.
- Temporal compression effects: Cosmos’s temporal downsampling degrades action following; quantify how compression factor k affects SCS, and explore remedies (e.g., learned temporal upsampling, hierarchical latents, multi-rate conditioning).
- Catastrophic forgetting and retention: Fine-tuning may erode internet priors; measure unconditional/text-conditioned generation quality pre/post fine-tuning and test strategies (partial freezing, regularization, rehearsal) to preserve generalization.
- Action-space coverage: Only 3-DoF SE(2) navigation and 25-DoF joint-angle commands are evaluated; extend to torque/velocity controls, hybrid discrete-continuous actions, variable-rate commands, and multi-modal inputs (e.g., force/ tactile).
- Partial observability and occlusions: Humanoid joints not visible in egocentric view are inferred via initial state embedding; study robustness to state noise/missing joints and the benefit of fusing proprioception (IMU, encoders) or learned state estimators.
- Dynamic scenes and moving objects: SCS targets static structures; evaluate action alignment when obstacles, people, and manipulands move, and develop metrics that handle dynamic entities and interactions.
- Contact and physics fidelity in manipulation: Current metrics do not assess contact stability, object pose changes, or compliance; introduce evaluations for grasp stability, contact duration, slip, and object trajectory consistency versus ground truth.
- Pose-aware evaluation: SCS avoids direct camera pose comparison; add pose-based metrics (e.g., monocular SLAM/VO to estimate egomotion error, trajectory deviation, rotational drift) to complement mask IoU.
- Automation and reliability of SCS: SCS requires manual object selection and relies on SAM2/trackers; quantify sensitivity to segmentation/tracking errors, reduce annotation via auto-selection of stable structures, and validate correlation with downstream control success.
- Out-of-domain generalization beyond appearance: “Walk through paintings” demonstrates stylistic generalization but not physics; evaluate in unusual yet physically plausible domains (fog, low light, novel layouts) and measure action-following under sensor noise.
- Real-world deployment constraints: Latency is reported but not on embedded hardware; profile memory/compute on edge devices, test streaming inference, and optimize for power/latency constraints in closed-loop control.
- Safety and failure modes: Characterize common failure patterns (hallucinations, sudden drift, unstable body configurations) and develop detectors/guards (e.g., uncertainty thresholds) to ensure safe operation.
- Uncertainty and multi-modality: The approach does not estimate predictive uncertainty; add calibrated uncertainty, diverse rollouts conditioned on identical actions, and evaluate coverage versus ground-truth futures.
- Goal-conditioned control: The framework does not integrate high-level goals (text, waypoints, object targets); investigate multi-modal goal conditioning and alignment between action sequences and task objectives.
- Multi-agent and social navigation: SCAND contains structured environments, but social interactions are not explicitly evaluated; test navigation around humans with social norms and dynamic avoidance metrics.
- Multi-view and 3D consistency: Only egocentric single-view is considered; extend to multi-camera or third-person views and evaluate 3D consistency (e.g., scene flow, depth, neural radiance field alignment).
- Embodiment transfer: Generalization is shown for 3-DoF and humanoids but not across qualitatively different platforms (quadrupeds, aerial drones, mobile manipulators); test cross-embodiment transfer with minimal fine-tuning and report adaptation costs.
- Training recipes and reproducibility: “Modest fine-tuning” is not quantified; report training time, compute budget, hyperparameters, and failure cases to enable reproducible adoption.
- Integration with policies learned from video generators: Connections to recent works using generators as policies are not explored; benchmark EgoWM as a policy backbone versus baselines, and study joint training of world model and policy.
- Action alignment under irregular timing: The method assumes fixed-rate alignment between action embeddings and video latents; handle variable action rates, delays, and asynchronous sensing/actuation, and report sensitivity analyses.
- Benchmark breadth: Quantitative results emphasize RECON val and 1X; add held-out test sets for SCAND/TartanDrive, cross-scene splits, and standardized benchmarks to support fair, comprehensive comparison with concurrent methods (e.g., GrndCtrl, Ctrl-World).
Practical Applications
Immediate Applications
Below are concrete, deployable uses enabled by the paper’s findings and method. Each item names the sector, a specific use case, the likely tool/product/workflow, and key assumptions/dependencies that impact feasibility.
- Robotics (navigation/manipulation) — Drop-in egocentric world model for action preview and planning
- Use case: Predict egocentric future frames given a candidate action sequence to score plans, detect likely collisions, or choose safer maneuvers in mobile and humanoid robots.
- Tools/products/workflows: EgoWM adapter that fine-tunes an off-the-shelf video diffusion model (e.g., SVD, Cosmos) with a lightweight action-projection module; ROS2 node that exposes “predict rollout(X0, A1:T)” for use in MPC/trajectory optimization; batched rollout service for sampling and plan selection.
- Assumptions/dependencies: Small but well-synchronized action–observation logs for the target robot; availability and licensing of a base video diffusion model; GPU for real-time or near-real-time inference; action-space calibration (e.g., 3-DoF SE(2) vs. 25-DoF joint angles) and correct initial state embedding.
- Teleoperation and operator decision support — Real-time visual “what-if” previews
- Use case: During teleop or shared autonomy, preview the egocentric outcome of joystick inputs before executing them to reduce operator error and improve safety.
- Tools/products/workflows: Side-by-side preview panel in operator UI that renders 0.5–2 s egocentric futures conditioned on pending inputs; rollout ranking by SCS-like proxy (e.g., consistency of stable landmarks).
- Assumptions/dependencies: Low-latency inference (Cosmos variant provides lower latency); robust time alignment between control inputs and camera stream; appropriate safety interlocks (previews inform but do not automatically actuate).
- Data augmentation for policy and perception training — Action-aligned synthetic videos
- Use case: Generate action-conditioned egocentric clips to augment scarce real data for navigation/manipulation policy learning or perception tasks (segmentation, tracking, depth).
- Tools/products/workflows: Offline rollout generator that samples diverse action sequences and synthesizes training clips; curriculum that mixes real and synthetic data; quality gates using SCS thresholds to filter poor rollouts.
- Assumptions/dependencies: Synthetic videos are visually and structurally plausible for the target domain; avoid overfitting to generative artifacts; maintain label/action fidelity.
- Benchmarking and model selection — Structural Consistency Score (SCS) for action-following evaluation
- Use case: Evaluate competing world models on whether stable scene structures evolve consistently with provided actions, disentangling action fidelity from mere visual sharpness.
- Tools/products/workflows: Reproducible SCS pipeline using AllTracker (dense point tracking) to trim sequences and SAM2 for object masks; CI checklists that track LPIPS/DreamSim alongside SCS; per-horizon SCS dashboards.
- Assumptions/dependencies: Access to sequence pairs (prediction vs. ground truth) with consistent field-of-view overlap; robustness of segmentation/tracking in generated videos; annotated or auto-selected stable objects.
- Creative industries (XR/museums/galleries) — “Walk through paintings” and immersive navigation in stylized worlds
- Use case: Interactive exhibits where visitors navigate inside artworks or stylized scenes with physically coherent camera motion driven by user inputs.
- Tools/products/workflows: Unity/Unreal plugin wrapping EgoWM inference to render egocentric rollouts from static imagery/artwork; museum installation or VR app with user-driven navigation (turn/forward/rotate).
- Assumptions/dependencies: Runtime GPU (local or edge); model tuned for the specific visual domain; content licensing for artwork; clear user guidance on non-physical but coherent motion expectations.
- Media, cinematography, and game previsualization — Camera-move previews from egocentric inputs
- Use case: Previsualize dolly/steadicam/FPV-like camera moves in a location scan or plate shot by “scrubbing” candidate motion inputs and inspecting predicted egocentric futures.
- Tools/products/workflows: DCC or NLE plugin that takes a reference frame/clip and motion curves and renders egocentric predictions; storyboard iteration tool for directors/level designers.
- Assumptions/dependencies: Domain adaptation to the scene style; expectation management (appearance plausibility vs. exact physics); compute budget in creative pipelines.
- Industrial operations and training (warehousing, inspection) — Operator training and route rehearsal
- Use case: Train operators or evaluate robot routes in realistic sites by previewing egocentric futures along candidate paths (e.g., narrow aisles, clutter).
- Tools/products/workflows: Digital-twin alignment with on-site video; route library with predictive previews; SCS-based checks to flag drifts or poor action alignment in new environments.
- Assumptions/dependencies: Up-to-date site visuals; adaptation with small amounts of in-domain data; clear SOPs that previews inform training rather than replace safety testing.
- Academic teaching and research — General, architecture-agnostic recipe for world modeling
- Use case: Rapidly turn any pre-trained video diffusion model into an action-conditioned world model for coursework, ablation studies, and new embodiment research.
- Tools/products/workflows: Open-source reference implementing action/timestep modulation with MLP projection and 1D temporal downsampling; teaching labs comparing training from scratch vs. fine-tuning.
- Assumptions/dependencies: Access to pretrained models and datasets (RECON, SCAND, TartanDrive, 1X Humanoid); compute availability for modest fine-tuning.
Long-Term Applications
These opportunities require more research, scaling, validation, or integration before dependable deployment.
- General-purpose embodied foundation models — Unified navigation and manipulation across embodiments
- Use case: A single world model that generalizes across mobile bases, arms, and humanoids with minimal additional data, supporting household and enterprise robots.
- Tools/products/workflows: Multi-embodiment action adapters, self-supervised continual learning on on-robot video, joint training with language and proprioception.
- Assumptions/dependencies: Larger, more diverse action–observation corpora; standardized action spaces and calibration; robust handling of occlusions and long-horizon dynamics.
- Model-based control and planning at scale — Closed-loop deployment with safety guarantees
- Use case: Use EgoWM rollouts as the predictive model inside MPC/planners for real-time control, with uncertainty estimates and guardrails.
- Tools/products/workflows: Uncertainty-aware scoring (e.g., ensembles, diffusion posterior diagnostics), safety filters, and fallback policies; tight hardware acceleration and batching.
- Assumptions/dependencies: Reliable uncertainty quantification; fail-safe architectures; regulatory acceptance for safety-critical tasks.
- Autonomous driving and field robotics — Action-aligned egocentric world models for planning and validation
- Use case: Predict future ego-view under planned trajectories for route scoring, scenario generation, and validation of planning stacks.
- Tools/products/workflows: Driving-specific adapters (ego-motion, controls, map context); large-scale SCS-like evaluations for certification test suites; integration with simulation/digital twins.
- Assumptions/dependencies: High-stakes safety and liability requirements; need for strong physical realism and multi-agent interaction modeling; extensive in-domain fine-tuning.
- Controllable synthetic data engines — Scalable generation of long-tail, action-aligned training corpora
- Use case: Produce targeted datasets for rare edge cases (lighting, weather, clutter, social navigation) to train policies and perception models.
- Tools/products/workflows: Programmatic scenario specification that outputs action sequences and EgoWM rollouts; automatic SCS gating and bias audits; dataset versioning and provenance.
- Assumptions/dependencies: Mitigating domain gap from generated videos; robust metrics beyond SCS for contact-rich physics; governance for synthetic data use.
- Multimodal instruction following — Language-conditioned planning with egocentric video predictions
- Use case: Given natural language goals, sample and evaluate candidate action sequences by their predicted egocentric futures (video-checking “did the instruction get satisfied?”).
- Tools/products/workflows: Joint language–action encoders; video-language reward models; instruction-to-action samplers scored by SCS-like structural alignment and goal satisfaction.
- Assumptions/dependencies: Large-scale language-action-video datasets; reliable grounding; avoidance of spurious correlations from web pretraining.
- Human–robot interaction and assistive technologies — Predictive visualization for shared autonomy
- Use case: Assistive robots preview actions to users (e.g., in homes or clinics) to improve transparency and trust; users modify plans by “seeing the future.”
- Tools/products/workflows: UX patterns for preview/confirm loops; risk-aware explanations over predicted rollouts; personalization via small on-device fine-tuning.
- Assumptions/dependencies: Strong privacy guarantees; rigorous user studies; clinical and safety validations in sensitive settings.
- Standardization and policy — Metrics and certification for action-following fidelity
- Use case: Industry-wide benchmarks and minimum SCS thresholds for embodied generative models used in commercial robots; procurement standards and third-party audits.
- Tools/products/workflows: Open SCS suites with reference sequences, object annotations, and protocols; conformance testing services; guidance on dataset licensing and bias audits for internet-scale pretraining.
- Assumptions/dependencies: Community adoption; extensions of SCS to multi-agent, deformable, and contact-rich scenarios; alignment with regulators and insurers.
- AR navigation assistance — Predictive overlays for wearables
- Use case: For pedestrians or workers, see a predictive egocentric overlay of the next steps (turns, path choices) blended with the live view.
- Tools/products/workflows: On-device or edge inference with temporal chunking; confidence gating; UI for low-latency visualization.
- Assumptions/dependencies: Mobile inference efficiency; robust localization; safety UX (overlays must not distract or mislead).
- Robot design and embodiment transfer — Fast “visual-in-the-loop” design iteration
- Use case: Preview the egocentric experience of new robot morphologies or sensor placements before building prototypes; evaluate visibility, occlusions, and maneuverability.
- Tools/products/workflows: CAD-to-action-space adapter; synthetic initial frames from scans or renders; comparative SCS across candidate designs during virtual trials.
- Assumptions/dependencies: Accurate mapping from design to action kinematics; domain bridging from rendered to real visuals.
- Surgical and industrial manipulation — Predictive video guidance in contact-rich tasks
- Use case: Anticipate egocentric outcomes of tool trajectories to assist precision tasks (e.g., minimally invasive surgery, micro-assembly).
- Tools/products/workflows: High-resolution, latency-optimized models with domain-specific fine-tuning; integration with haptics and safety constraints.
- Assumptions/dependencies: Extremely strict reliability and validation; domain-adapted data at scale; regulatory approval.
Cross-cutting assumptions and limitations to consider
- Pretrained model availability and licensing: Commercial deployment may require rights to fine-tune and deploy large video models (e.g., SVD, Cosmos).
- Data and calibration: Even modest fine-tuning needs synchronized action–observation data and accurate action-space definitions (including initial state embedding).
- Compute and latency: Real-time loops demand GPU acceleration and careful batching/chunking; performance varies by backbone (Cosmos faster than autoregressive baselines).
- Physical realism vs. visual plausibility: The approach prioritizes structurally coherent visuals; contact dynamics and fine-grained physics may require complementary models or safeguards.
- Safety and reliability: Use for advisory/preview first; safety-critical actuation requires uncertainty estimation, monitoring, and rigorous validation beyond SCS.
- Bias and generalization: Internet-scale priors can encode biases; domain audits and on-site adaptation remain necessary.
Glossary
- 3D ConvNet: A convolutional neural network that processes spatiotemporal data with 3D kernels to capture motion across time in videos. Example: "3D ConvNet"
- Action-conditioned world model: A generative model that predicts future observations while being explicitly controlled by action inputs from an agent. Example: "transforms any pre-trained video diffusion model into an action-conditioned world model"
- Action embedding module: A component that encodes action sequences into learned vectors used to modulate the generative model. Example: "We introduce an action embedding module"
- Architecture-agnostic: Designed to work across different neural network architectures without requiring structural changes. Example: "a simple, architecture-agnostic method"
- Autoregressive: A generation scheme where outputs are produced sequentially, with each step conditioned on previously generated outputs. Example: "evaluated autoregressively over two 8-frame chunks"
- Backbone architectures: The core network structures that provide feature extraction capacity for the overall model. Example: "backbone architectures"
- Closed-loop deployment: Running a model online in control scenarios where outputs affect subsequent inputs through feedback. Example: "real-time, closed-loop deployment"
- Conditioning pathway: The internal route by which external signals (e.g., time, actions) influence the model’s activations. Example: "timestep-conditioning pathway"
- Denoising timestep embedding: A learned vector representing the diffusion step, used to control denoising in diffusion models. Example: "denoising timestep embedding"
- DiT (Diffusion Transformer): A transformer-based architecture for diffusion models that replaces convolutional U-Nets. Example: "a DiT-based (Diffusion Transformer) model"
- DoF (Degrees of Freedom): The number of independent control variables (e.g., joints or motion components) in an embodiment. Example: "25-DoF humanoids"
- DreamSim: A perceptual metric for evaluating visual similarity in generated images/videos using learned representations. Example: "DreamSim"
- Egocentric: A first-person viewpoint aligned with the agent’s sensor (e.g., camera) perspective. Example: "egocentric videos"
- Embodiment: The physical form and actuation capabilities of an agent (e.g., mobile robot vs. humanoid). Example: "embodiments and action spaces"
- Flow matching: A training objective related to matching probability flows in generative modeling, used as an alternative to denoising. Example: "denoising or flow matching"
- Fréchet Video Distance (FVD): A distribution-level metric for video quality based on feature statistics from a pretrained video network. Example: "Fréchet Video Distance (FVD)"
- Intersection over Union (IoU): A measure of overlap between predicted and ground-truth masks used in segmentation evaluation. Example: "mask IoU"
- Joint-angle space: The vector space of joint positions/angles used to control articulated agents. Example: "joint-angle space of the robot or humanoid"
- Latency: The time delay between input and model output, critical for real-time performance. Example: "inference latency"
- Latent space: A compressed representation space where diffusion models operate for efficiency. Example: "low-dimensional latent space"
- LPIPS: A learned perceptual metric that compares deep features to assess visual similarity. Example: "LPIPS"
- Model-predictive control: A control strategy that plans actions by predicting future states under a learned or known model. Example: "model-predictive control"
- Navigation World Models (NWM): A large-scale diffusion-based baseline trained for egocentric navigation tasks. Example: "Navigation World Models (NWM)"
- Perceptual similarity metrics: Measures based on human-like visual perception rather than exact pixel matching. Example: "perceptual similarity metrics"
- Reverse denoising process: The iterative procedure in diffusion models that removes noise to reconstruct data. Example: "reverse denoising process"
- Scale-and-shift transformations: Feature-wise affine modulations used to inject conditioning signals into model activations. Example: "scale-and-shift transformations"
- SE(3): The group of 3D rigid-body transformations (rotations and translations) describing camera or body motion. Example: "SE(3) camera motion"
- Segmentation tracker: A model or pipeline that propagates object masks across video frames for tracking. Example: "segmentation tracker"
- Spatio-temporal VAE: A variational autoencoder that compresses both spatial and temporal dimensions of video. Example: "spatio-temporal VAE"
- Structural Consistency Score (SCS): A metric that evaluates whether generated scene structures evolve consistently with actions, independent of appearance. Example: "Structural Consistency Score (SCS)"
- Temporal downsampling: Reducing the frame rate or temporal resolution within a model to save computation. Example: "temporal downsampling"
- Temporal latent compression: Compressing the temporal dimension of inputs within the latent space to align rates and reduce cost. Example: "temporal latent compression"
- Timestep-dependent modulation: Adjusting network activations based on the diffusion timestep embedding. Example: "timestep-dependent modulation"
- U-Net: A convolutional encoder–decoder architecture with skip connections widely used in diffusion models. Example: "U-Net backbone"
- VAE (Variational Autoencoder): A probabilistic generative model that learns latent representations via a reconstruction and regularization objective. Example: "VAE"
- Video diffusion model: A generative model that synthesizes videos by iteratively denoising latent variables. Example: "video diffusion model"
- Visual fidelity: The perceived realism and sharpness of generated frames. Example: "visual fidelity"
- World model: A model that predicts how observations evolve in response to actions, enabling planning and control. Example: "world model"
- World priors: Broad, learned knowledge about physics and appearances derived from large-scale data. Example: "rich world priors"
Collections
Sign up for free to add this paper to one or more collections.