Hunyuan-GameCraft-2: Instruction-following Interactive Game World Model
Abstract: Recent advances in generative world models have enabled remarkable progress in creating open-ended game environments, evolving from static scene synthesis toward dynamic, interactive simulation. However, current approaches remain limited by rigid action schemas and high annotation costs, restricting their ability to model diverse in-game interactions and player-driven dynamics. To address these challenges, we introduce Hunyuan-GameCraft-2, a new paradigm of instruction-driven interaction for generative game world modeling. Instead of relying on fixed keyboard inputs, our model allows users to control game video contents through natural language prompts, keyboard, or mouse signals, enabling flexible and semantically rich interaction within generated worlds. We formally defined the concept of interactive video data and developed an automated process to transform large-scale, unstructured text-video pairs into causally aligned interactive datasets. Built upon a 14B image-to-video Mixture-of-Experts(MoE) foundation model, our model incorporates a text-driven interaction injection mechanism for fine-grained control over camera motion, character behavior, and environment dynamics. We introduce an interaction-focused benchmark, InterBench, to evaluate interaction performance comprehensively. Extensive experiments demonstrate that our model generates temporally coherent and causally grounded interactive game videos that faithfully respond to diverse and free-form user instructions such as "open the door", "draw a torch", or "trigger an explosion".






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (quick overview)
This paper introduces Hunyuan-GameCraft-2, an AI system that can create short, game-like videos that react to what you tell it to do. Instead of only pressing keys like W/A/S/D, you can also type instructions in natural language (for example, “open the door” or “draw a torch”), and the video changes in a way that matches your request. The system focuses on making the video look good, stay consistent over time, and clearly show cause-and-effect from your actions.
What the researchers wanted to figure out
In simple terms, they set out to answer three big questions:
- How can we make AI-created game videos react to free-form instructions, not just fixed key presses?
- How can we build huge training datasets that actually teach the AI cause-and-effect (so the video changes make sense after an action), without spending tons of time on manual labels?
- How can we make long, multi-step interactions (several actions in a row) run smoothly and fast enough to feel real-time?
How they did it (methods explained simply)
Think of the system as a smart “director + camera operator” for a virtual world:
- The “director” understands your instructions (like “open the door”).
- The “camera operator” turns key or mouse inputs into smooth camera moves.
- The “editor” keeps the video consistent over time so things don’t randomly change or fall apart.
Here are the main parts of their approach, with everyday analogies:
- Defining interactive videos: They first define what counts as an “interactive” video: there must be a clear action and a clear change in the world caused by that action (for example, before: door closed; after: door open). This is important because the AI needs to learn cause-and-effect, not just pretty scenes.
- Building data at scale:
- Synthetic pipeline (making new training clips automatically):
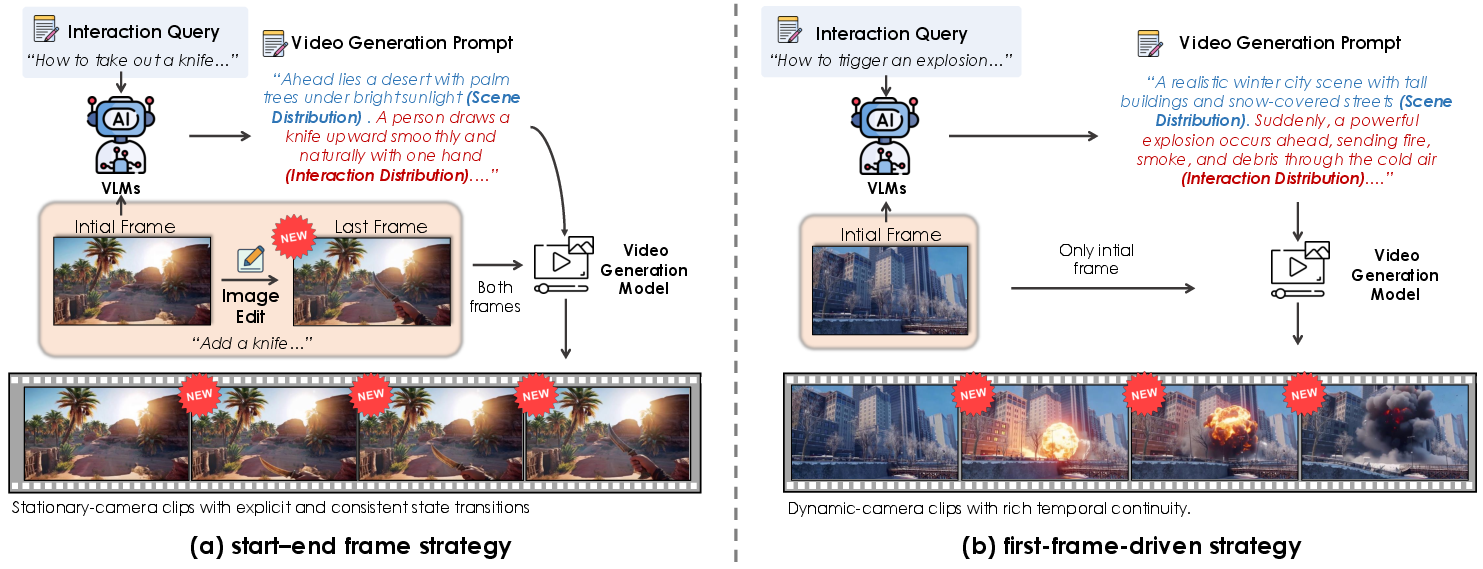
- Start–End frame strategy: For scenes where the camera is still (like turning rain on or off), they generate a start frame and an edited end frame to show the change.
- First-frame-driven strategy: For more dynamic actions (like opening a door while walking), they start from the first frame and let the model create the motion so the camera feels natural.
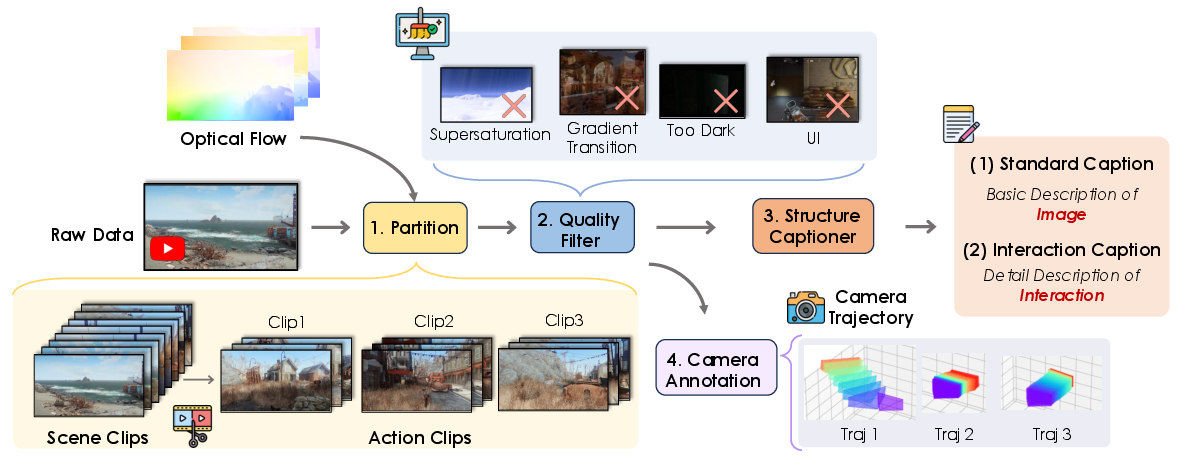
- Curating real gameplay clips (from 150+ big-name games): They chop long videos into shorter clips, filter out bad frames, auto-generate captions (descriptions), and reconstruct camera motion data. This gives the model clean, labeled examples with both visuals and camera paths.
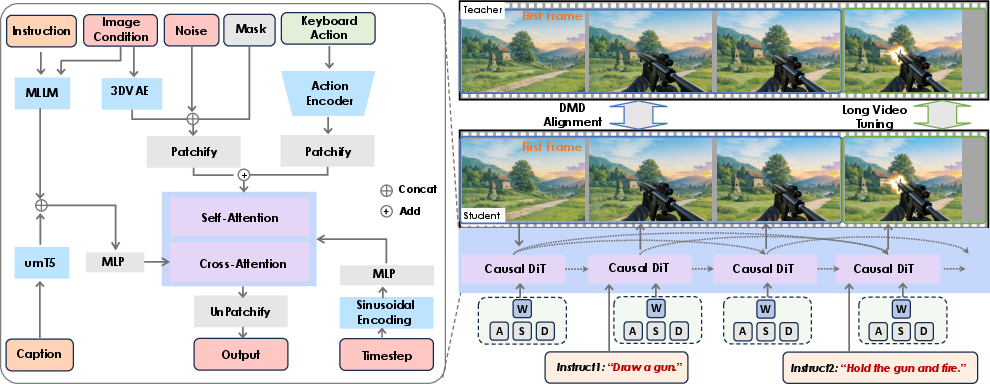
- Unifying controls: The model accepts three types of input during generation:
- A starting image (the “scene” you begin with).
- Keyboard/mouse signals (W/A/S/D, arrow-like look controls).
- Natural language instructions (“draw a torch”, “trigger an explosion”).
- It translates keys/mouse into precise camera moves and uses a vision-LLM (an AI that understands pictures and text) to interpret and inject the meaning of your instruction so the change happens in the right part of the scene.
- Training the model to handle long, interactive videos:
- Stage 1: Action-injected training. The model learns to tie actions (keys/mouse) to believable world and camera changes.
- Stage 2: Instruction fine-tuning. It learns to carry out natural language instructions accurately.
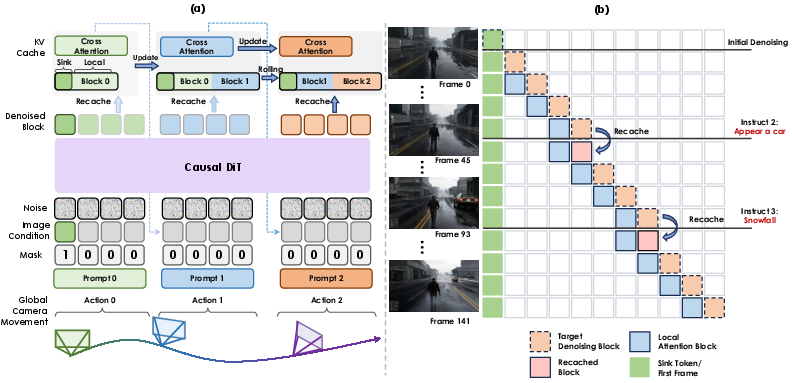
- Stage 3: “Teacher-student” training for long videos. Imagine a coach showing the student how to keep going step-by-step without losing quality. The model learns to generate videos in chunks, remembering what happened before, and keeping the first frame as a “compass” so the scene doesn’t drift.
- Stage 4: Randomized long-video tuning. The model practices making longer and longer videos, at random lengths, so it gets robust to different durations and doesn’t break down over time.
- Memory and responsiveness during use:
- The system uses a small “working memory” (a cache) to remember recent frames and always keeps the very first frame in memory as a reference point. This prevents the scene from gradually warping or forgetting where things started.
- When you give a new instruction mid-video, it briefly refreshes that memory so the next part of the video responds more accurately to your new request.
- Speed-ups to feel real-time:
- They compress certain calculations, run parts in parallel, and use efficient transformer attention, boosting speed to about 16 frames per second. That makes interactions feel responsive.
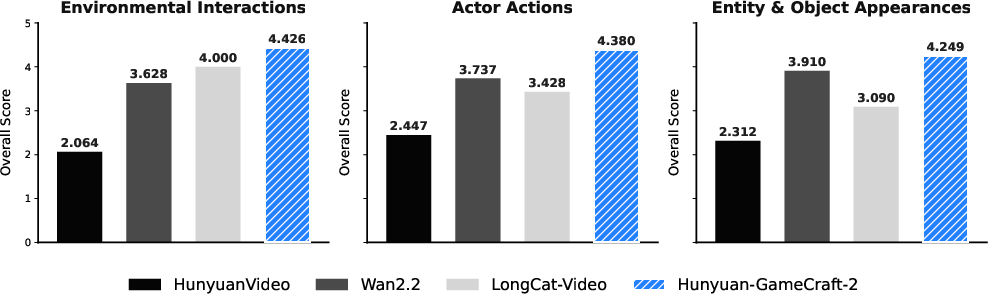
What they found (main results and why they matter)
- Clear, responsive interactions: The model reliably follows a wide range of instructions like “open the door,” “draw a torch,” or “trigger an explosion,” and the video changes in a way that clearly matches the request.
- Cause-and-effect preserved: Actions lead to expected results, not random changes. For example, pressing forward moves the camera forward consistently; telling it to take out a gun shows a gun appearing, and “fire” produces the right effect.
- Smooth, consistent videos: The visuals look clean, the style stays consistent, and motion is stable over time (no sudden artifacts or “drift” away from the scene).
- Multi-turn control: You can chain several actions in a row, and the system stays coherent, remembering previous steps.
- Real-time performance: Thanks to engineering tricks, the system reaches about 16 FPS, which is fast enough to feel interactive.
- New benchmark (InterBench): They built a test to score interactive behavior, checking things like:
- Did the system actually complete the requested interaction?
- Did the action have the intended effect?
- Is the cause-and-effect logical?
- Does it obey basic physical rules (no nonsense motions)?
- On these measures and general video quality, their system performs strongly.
Why this is important (implications and impact)
- More natural control: Letting people use both plain language and keys/mouse to control a generated world makes AI-made experiences feel closer to real gameplay and much easier to direct.
- Faster content creation: Game artists and designers could quickly prototype scenes and interactions without building full 3D assets first, saving time and cost.
- Better training data, less manual labeling: Their automated pipelines turn messy internet videos and images into usable training data that focuses on cause-and-effect—a big step toward smarter interactive models.
- Toward “playable worlds”: This moves video generation from passive clips to active, instruction-following simulations. It’s a foundation for future AI systems that could power interactive storytelling, virtual training, education, and eventually more advanced, playable AI-driven environments.
In short, Hunyuan-GameCraft-2 shows how to teach an AI to follow your instructions inside a virtual world, react in believable ways, keep videos smooth and consistent over time, and run fast enough to feel interactive—all built on top of large-scale data, clever training, and smart engineering.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues, missing analyses, and open questions that future work could address:
- Data causal fidelity is not quantified: how often do the synthetic and curated clips actually exhibit clear action–outcome causality (vs. coincidental correlation), and what is the measured correctness rate of interaction labels across the dataset?
- The “interaction caption” defined as a semantic difference between consecutive clips lacks validation: what is the accuracy, robustness, and failure profile of this captioning under occlusion, subtle transitions, or multi-actor scenes?
- VIPE-derived 6-DoF camera annotations are assumed accurate; no error analysis is provided. What are the camera trajectory reconstruction errors and their downstream impact on training and control?
- The synthetic pipeline’s reliance on VLMs and image editing introduces potential hallucinations and biases; there is no audit of bias, diversity, or realism versus real gameplay distributions.
- No ablation on synthetic vs. real gameplay data: what fraction and composition of synthetic data is optimal, and how does synthetic-to-real ratio affect interaction quality and generalization?
- Action supervision remains implicit for many non-camera interactions. How can explicit action labels (e.g., object affordances, interaction primitives) be integrated to reduce ambiguity and improve controllability?
- The text-based instruction injection via MLLM is under-specified: what embedding alignment, attention routing, and loss functions are used to map verbs to spatiotemporal control, and how do these choices affect object-level localization and outcomes?
- Ambiguous or conflicting multi-modal inputs (keyboard/mouse vs. language prompts) are not resolved. What arbitration policy (priority, blending, fallback) best maintains responsiveness and causal correctness?
- Object-centric control (e.g., “open the door” on the correct door) is not explicitly grounded. How can explicit object detection, segmentation, tracking, or scene graphs be incorporated to ensure targeted, reliable interactions?
- Physical plausibility is claimed but not rigorously measured. Can physics-consistency metrics (e.g., collision, momentum, gravity conformity) or learned simulators be integrated to detect and penalize implausible dynamics?
- Causal grounding is asserted without counterfactual testing. Can intervention-based evaluations (e.g., same context with and without action, action variants) quantify causal effect sizes and spurious correlations?
- Long-horizon robustness is not characterized beyond short/medium clips. How does interaction accuracy, drift, and visual quality behave over multi-minute, multi-turn sessions with frequent prompt changes?
- The sink-token anchoring to the initial frame may hinder large scene transitions or teleports; how should origin re-anchoring, recache policies, or dynamic coordinate frames be handled for major scene changes?
- KV-recache improves responsiveness, but latency–accuracy tradeoffs are not reported. What are the end-to-end interaction latencies under different cache sizes, window lengths, and hardware settings?
- The long-video tuning algorithm (randomized windows + self-/teacher-forcing) lacks sensitivity analyses. How do window size K, rollout length N, and sampled timestep distributions affect stability and error accumulation?
- Resolution scalability is unexamined. What happens at 720p/1080p generation regarding FPS, memory, temporal stability, and camera-control accuracy (RPE)?
- 3D consistency is claimed but not measured with geometry-aware metrics (e.g., monocular depth consistency, camera/ego-motion alignment, multi-view coherence); can such metrics be added to InterBench?
- InterBench is introduced but not fully specified. Are metric definitions, scoring protocols, and datasets open-sourced, and how do scores correlate with human judgments of interactivity, responsiveness, and fun/playability?
- Comparisons emphasize general video metrics (FVD, aesthetics) over interaction-specific performance; results on InterBench dimensions (e.g., interaction completeness, action effectiveness) are missing or incomplete.
- User studies are absent. How do real users rate responsiveness, control accuracy, and perceived causality across diverse prompts and action sequences?
- Multi-agent/NPC interactions are not addressed. Can the model handle multiple interacting entities with independent behaviors and resolve competing goals or collisions?
- Language generalization is unclear. Does instruction-following work across languages, dialects, and colloquial phrasing, and what multilingual training or alignment is required?
- Safety, ethics, and IP concerns are not covered. How are copyrighted AAA assets handled, and what safeguards mitigate generation of harmful/violent content (e.g., “trigger an explosion”) or biased outputs?
- Training compute and accessibility are not discussed. What are the training/inference resource requirements, and can smaller models or distillation targets achieve similar interaction quality?
- Domain transfer beyond games is unexplored. How well does the approach generalize to non-game environments (e.g., robotics videos, real-world instruction-following) and what adaptations are needed?
- Failure mode taxonomy is missing. What are the common errors (e.g., object mis-localization, camera over-rotation, action non-execution), their frequencies, and mitigation strategies?
- Curriculum choices (45/81/149 frames at 480p) are not justified or ablated. What curricula optimize interaction stability and long-horizon coherence?
- Partitioning via optical flow and scene detection can mis-segment actions; no error rates are reported. How does partition accuracy affect captioning and training quality?
- The integration of keyboard/mouse into continuous camera control may limit non-camera interactions (inventory use, object manipulation). What representation and training signals are needed to expand beyond camera-centric actions?
- Compositional, multi-step plans (e.g., “take out phone, unlock, call”) are handled heuristically; can hierarchical planning or policy learning improve execution of complex, temporally extended tasks?
Practical Applications
Immediate Applications
Below are practical, deployable applications that can be built today using Hunyuan-GameCraft-2’s capabilities (instruction-following, keyboard/mouse control, and real-time interactive video generation at ~16 FPS), data pipelines, and evaluation tools.
- Gaming industry — interactive previsualization and prototyping
- Use case: Rapidly turn a single concept image into an instruction-driven, interactive gameplay preview (e.g., “open the door,” “draw a torch,” “walk forward”).
- Potential tools/products/workflows:
- “Prompt-to-Previz” plugin for Unreal/Unity/DCC tools to generate interactive storyboards and camera tests from art boards.
- “Designer-in-the-loop” previz sessions where natural-language instructions update the scene on the fly (multi-turn KV-recache).
- Automated trailer/teaser generator that responds to creative prompts and camera cues in real time.
- Assumptions/dependencies: GPU availability for ~16 FPS at 480p; content and style are biased toward AAA game domains seen in training; rights management for any training assets.
- Gaming QA and automated playtesting
- Use case: Language-driven scripted “player” that exercises critical paths (e.g., opening objects, triggering interactions) to create reproducible, interactive videos for bug triage.
- Potential tools/products/workflows:
- “AI QA Bot” that takes test plans in natural language and produces interactive video traces; integrates InterBench metrics for regression checks (causal coherence, action effectiveness).
- Assumptions/dependencies: Accuracy depends on alignment of actions to in-game semantics; may require domain-finetuning for specific titles/mechanics.
- Media, VFX, and advertising — interactive shot ideation
- Use case: Director-style iteration on scenes via voice or text instructions to explore camera moves, effects (e.g., “trigger an explosion”), and pacing before committing to full production.
- Potential tools/products/workflows:
- “Interactive Storyboarder” and “Director Console” that accept prompts and key/mouse cues to update shots live.
- Real-time pitch/preview sessions with clients to co-create variants.
- Assumptions/dependencies: Visual plausibility is high, but physical realism is not guaranteed; resolution constraints (typically ≤720p) may require upscale pipelines.
- EdTech and training content — scenario videos on demand
- Use case: Generate interactive scenario videos for classroom demos (e.g., environmental changes, simple causal chains like “turn on lights, open door, walk outside”).
- Potential tools/products/workflows:
- “Prompt-to-Scenario” tool for instructors to produce variations for different contexts and languages.
- Assumptions/dependencies: Not a physics simulator; suitable for demonstration and storytelling rather than precise scientific fidelity.
- Synthetic interactive data generation for model training
- Use case: Produce large volumes of interaction-rich clips to train downstream models (e.g., action detection, captioning, causal reasoning).
- Potential tools/products/workflows:
- “Interactive Dataset Factory” built on the synthetic video pipeline (start–end frame or first-frame-driven strategies), structured captioning, and camera annotation (VIPE) to export labeled data.
- Assumptions/dependencies: Distribution is game-like; VLM-based captions and interaction labels should be validated for domain shift.
- Benchmarking and evaluation services
- Use case: Apply InterBench to evaluate controllable/interactive video models on interaction completeness, causal coherence, physical plausibility, etc.
- Potential tools/products/workflows:
- “InterBench-as-a-Service” for internal model QA, vendor comparison, or academic leaderboards.
- Assumptions/dependencies: Requires standardizing prompts and test sets; metrics emphasize interactive behavior beyond conventional video fidelity scores.
- Live streaming and creator tools
- Use case: Chat- or voice-driven interactive video segments for streamers (e.g., audience triggers “switch to torch,” “look left,” “cause lightning”).
- Potential tools/products/workflows:
- Streamer overlay plugin with chat-to-action mapping and KV-recache for multi-turn responsiveness.
- Assumptions/dependencies: Latency and GPU constraints on consumer rigs; content moderation policies for interactive effects.
- Academic research — world models, causality, and long video generation
- Use case: Study action–outcome causality, instruction grounding, and long-horizon generation with a reproducible pipeline (autoregressive distillation, sink tokens, block-sparse attention).
- Potential tools/products/workflows:
- Open experiments on Self-Forcing, randomized long-video tuning, and KV cache management; ablations on interaction injection via MLLM.
- Assumptions/dependencies: Access to multi-GPU compute for MoE models; reliance on third-party libraries (PySceneDetect, RAFT, VIPE, SageAttention).
- E-commerce and product demos (limited scope)
- Use case: Produce quick, instruction-driven product interaction videos (e.g., “open the car door,” “turn on the screen”) from catalog images to augment listings or social posts.
- Potential tools/products/workflows:
- “Prompt-to-Product-Demo” for rapid marketing creative at low cost.
- Assumptions/dependencies: Requires product-specific finetuning for realism; ensure compliance with advertising truth-in-representation rules.
Long-Term Applications
These opportunities require further research and engineering (e.g., higher resolution, better physics, broader domain coverage, 3D consistency, and integration into interactive systems beyond video).
- Generative game engines and dynamic content systems
- Use case: Replace parts of scripted pipelines with instruction-following world models that generate cutscenes, ambient events, or side-content on the fly.
- Potential tools/products/workflows:
- “Generative Director” inside game engines orchestrating interactive cinematics and events based on player intent/LLM-driven narratives.
- Assumptions/dependencies: Stronger memory persistence, world state management, and safety constraints for live games; tighter coupling with physics and gameplay logic.
- Playable AI-driven worlds
- Use case: Move from interactive videos to truly playable experiences where language and controls drive evolving, persistent worlds.
- Potential tools/products/workflows:
- Hybrid 2.5D/3D systems that align video-based world models with scene graphs and physics engines for gameplay loops.
- Assumptions/dependencies: Beyond-video representations (3D geometry, object permanence, physical consistency), robust multi-turn control, and efficient rendering at >60 FPS.
- Robotics and embodied AI pretraining
- Use case: Pretrain policies or perception models with instruction-conditioned, causally structured visual worlds before sim-to-real transfer.
- Potential tools/products/workflows:
- “Instructional Video World Pretraining” for agents to learn action–effect priors and grounding, followed by physics-accurate sims and real-world fine-tuning.
- Assumptions/dependencies: Requires higher physical fidelity and domain-aligned sensor models; careful transfer learning and validation to avoid unsafe policies.
- Enterprise training, safety, and crisis simulation
- Use case: Generate interactive scenario videos for safety drills (e.g., evacuation, hazard responses) that can be adjusted in real time by instructors.
- Potential tools/products/workflows:
- “Scenario Composer” integrating scripted policies with instruction-following visualizations and branching narratives.
- Assumptions/dependencies: Verification for regulatory compliance; augmented with physics-based simulators for critical accuracy.
- Healthcare education and rehabilitation
- Use case: Language-driven interactive visualizations for surgical training, patient education, or gamified rehab tasks.
- Potential tools/products/workflows:
- “Interactive Med-Previz” for procedure steps; “Home Rehab Coach” for motivating patient engagement with responsive scenes.
- Assumptions/dependencies: Requires medical-grade validation; significantly higher realism, domain data, and strict safety/ethics oversight.
- Education and virtual labs (VR/AR)
- Use case: Immersive, instruction-controlled labs and explorable environments for STEM, language learning, and history.
- Potential tools/products/workflows:
- “Prompt-to-Lab” module in VR headsets generating interactive walkthroughs; AI tutors that adapt scene evolution to learning goals.
- Assumptions/dependencies: Higher resolution/latency targets for HMDs; consistent long-horizon memory; integration with 3D assets and interaction APIs.
- Product design and UX research
- Use case: Early-stage, instruction-driven simulations of user flows and interactions within conceptual environments or interfaces.
- Potential tools/products/workflows:
- “Interactive Concept Simulator” for rapid UX hypothesis testing with stakeholders giving natural-language instructions.
- Assumptions/dependencies: Domain adaptation to non-game interfaces; alignment between visualized flows and actual product constraints.
- Digital twins and operations
- Use case: Instruction-driven scenario planning in digital twins for smart cities, facilities, or logistics (e.g., “simulate rainfall and observe effects”).
- Potential tools/products/workflows:
- “Narrative Twin Viewer” for stakeholders to explore what-if narratives before deploying changes.
- Assumptions/dependencies: Needs multi-modal fusion with real telemetry, physics-based models, and 3D GIS to ensure actionable fidelity.
- Standards, audit, and policy tooling for interactive AI
- Use case: Employ interaction-focused benchmarks to certify, audit, and red-team instruction-following generative systems.
- Potential tools/products/workflows:
- “Interactive AI Safety Bench” extending InterBench with harmful instruction detection, causal misalignment scoring, and provenance/watermarking hooks.
- Assumptions/dependencies: Multi-stakeholder agreement on metrics, adoption by standards bodies, and traceability infrastructure.
Cross-cutting assumptions and dependencies
- Compute and infrastructure: Running a 14B MoE video model with KV cache and real-time decoding requires high-end GPUs, optimized attention kernels (e.g., SageAttention), quantization (FP8), and sequence parallelism.
- Data and domain bias: Current training is heavy on AAA game footage and synthetic pipelines; generalization to real-world domains may require substantial finetuning and new data collection.
- Physical realism and safety: Video-based models are not physics simulators; outputs must be validated for domains where realism and safety are critical (e.g., robotics, healthcare).
- Legal and ethical considerations: Rights for training footage, disclosure and watermarking of synthetic media, and guardrails for interactive content creation.
- Integration effort: Real products need APIs, SDKs, and UI bridges for engines (Unreal/Unity), live streaming software, learning platforms, or enterprise systems.
Glossary
- 6-DoF (Six Degrees of Freedom): A camera motion representation covering 3D translation and rotation. "We reconstruct 6-DoF camera trajectories for each clip using VIPE~\cite{huang2025vipe}."
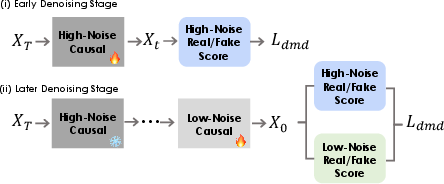
- Autoregressive distillation: A teacher–student training strategy that converts a bidirectional generator into a causal, stepwise model. "we employ a comprehensive autoregressive distillation strategy that transfers the bidirectional video generator into a causal autoregressive model."
- Block Sparse Attention: An attention pattern that restricts attention to local blocks to improve efficiency and stability. "Additionally, we employ Block Sparse Attention~\cite{guo2024blocksparse} for local attention, better suited for our autoregressive, block-wise generation process."
- Block-wise autoregressive inference: Generating long videos in sequential blocks while updating attention caches. "Figure 1.(a) illustrates our block-wise autoregressive inference pipeline for long video generation, along with the corresponding KV cache updating mechanism."
- Causal autoregressive model: A generator that conditions only on past context to produce future frames. "transfers the bidirectional video generator into a causal autoregressive model."
- Classifier-Free Guidance (CFG): A diffusion guidance technique mixing conditional and unconditional predictions to control strength. "using a dual-stage CFG with scales of (3.5, 3.5) for both noise regimes."
- Distributional Moment Distance (DMD): A loss aligning predicted and target distributions by matching statistical moments. "apply distributional moment distance (DMD)~\cite{dmd,dmd2} alignment on the extended frames."
- Flow-matching objective: A training objective that learns a vector field to transform noise into data, used in diffusion/flow models. "we load the pre-trained weights and finetune the model with the flow-matching objective for architectural adaptation."
- FP8 Quantization: Using 8-bit floating-point precision to accelerate inference and reduce memory while maintaining quality. "FP8 Quantization reduces memory bandwidth and leverages GPU acceleration while preserving visual quality;"
- KV cache: Cached key/value tensors for attention that enable efficient autoregressive generation. "The complete KV cache is composed of these sink tokens and the local attention component, which is implemented using block sparse attention."
- KV-recache mechanism: Recomputing attention caches upon new inputs to improve multi-turn interaction accuracy. "we following LongLive~\cite{yang2025longliverealtimeinteractivelong} to employ a KV-recache mechanism to enhance the accuracy and stability of multi-turn interactions"
- Mixture-of-Experts (MoE): A model architecture with multiple expert subnetworks routed per input for scalability and specialization. "Built upon a 14B image-to-video Mixture-of-Experts (MoE) foundation model, our model incorporates a text-driven interaction injection mechanism"
- Multimodal LLM (MLLM): A LLM that processes and reasons over multiple modalities such as text and images. "we leverage a multimodal LLM (MLLM)~\cite{wang2024qwen2} to extract, reason and inject interaction information to the main model"
- Plücker embeddings: A representation of camera rays/lines in projective geometry used to encode camera parameters. "annotated camera parameters are encoded as Plücker embeddings~\cite{he2024cameractrl} and integrated into the model through token addition."
- RAFT-based optical flow: Dense motion estimation using the RAFT architecture to detect fine-grained action boundaries. "Subsequently, we use RAFT-based optical flow~\cite{teed2020raft} to localize fine-grained action boundaries, ensuring each clip preserves temporal integrity for training."
- SageAttention: An optimized quantized attention kernel that accelerates transformer computation. "SageAttention~\cite{zhang2025sageattentionaccurate8bitattention} replaces FlashAttention with an optimized quantized attention kernel for faster transformer computation;"
- Self-attention KV cache: The key/value cache specifically for self-attention used to maintain context efficiently. "our inference process employs a fixed-length self-attention KV cache with a rolling update mechanism"
- Self-Forcing: Training the model on its own predictions to simulate and learn to correct error accumulation. "Methods such as Self-Forcing~\citep{huang2025selfforcingbridgingtraintest} condition the model on its own predictions to simulate error accumulation"
- Sequence parallelism: Distributing sequence tokens across GPUs to support long-context generation efficiently. "Sequence parallelism distributes video tokens across multiple GPUs, supporting efficient long-context generation."
- Sink token: A persistent conditioning token (e.g., the first frame) retained in the attention cache to stabilize generation. "we designate the initial frame as a sink token, which is always retained in the KV cache."
- UniPC sampler: A fast ODE/PDE sampler for diffusion models balancing speed and quality. "We use the UniPC sampler, setting sample_shift=5.0, sample_steps=40, boundary=0.900, and using a dual-stage CFG with scales of (3.5, 3.5) for both noise regimes."
- VAE decoding: Reconstructing pixel frames from latent representations using a Variational Autoencoder. "Parallelized VAE decoding enables simultaneous latent-frame reconstruction, mitigating bottlenecks in long-sequence decoding;"
- Vision-LLM (VLM): A model that jointly understands images and text to produce grounded descriptions or plans. "we first employ a Vision-LLM (VLM) to analyze and, guided by a high-level instruction (e.g., ``taking out a torch''), generate a customized, scene-specific prompt."
- VIPE: A system used to estimate per-frame camera motion and trajectory in videos. "We reconstruct 6-DoF camera trajectories for each clip using VIPE~\cite{huang2025vipe}."
Collections
Sign up for free to add this paper to one or more collections.

