WorldCam: Interactive Autoregressive 3D Gaming Worlds with Camera Pose as a Unifying Geometric Representation
Abstract: Recent advances in video diffusion transformers have enabled interactive gaming world models that allow users to explore generated environments over extended horizons. However, existing approaches struggle with precise action control and long-horizon 3D consistency. Most prior works treat user actions as abstract conditioning signals, overlooking the fundamental geometric coupling between actions and the 3D world, whereby actions induce relative camera motions that accumulate into a global camera pose within a 3D world. In this paper, we establish camera pose as a unifying geometric representation to jointly ground immediate action control and long-term 3D consistency. First, we define a physics-based continuous action space and represent user inputs in the Lie algebra to derive precise 6-DoF camera poses, which are injected into the generative model via a camera embedder to ensure accurate action alignment. Second, we use global camera poses as spatial indices to retrieve relevant past observations, enabling geometrically consistent revisiting of locations during long-horizon navigation. To support this research, we introduce a large-scale dataset comprising 3,000 minutes of authentic human gameplay annotated with camera trajectories and textual descriptions. Extensive experiments show that our approach substantially outperforms state-of-the-art interactive gaming world models in action controllability, long-horizon visual quality, and 3D spatial consistency.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces WorldCam, an AI system that can “run” a 3D game world and respond to your inputs (like pressing WASD keys or moving a mouse) while keeping the world looking solid and consistent over time. The central idea is simple: use the camera’s position and direction—called the camera pose—as a shared “language” that connects what you do (your actions) to what you see (the video the AI generates).
What questions does the paper ask?
- How can we make a video‑generating AI follow a player’s actions precisely, so that pressing keys and moving the mouse cause the exact camera motion you expect?
- How can we keep the 3D world consistent for a long time—so if you walk away and come back, things are in the same places and look the same from the same angles?
- Can we build a training dataset of real human gameplay to teach the AI the kinds of movements and views that happen in actual games?
How does WorldCam work? (Explained simply)
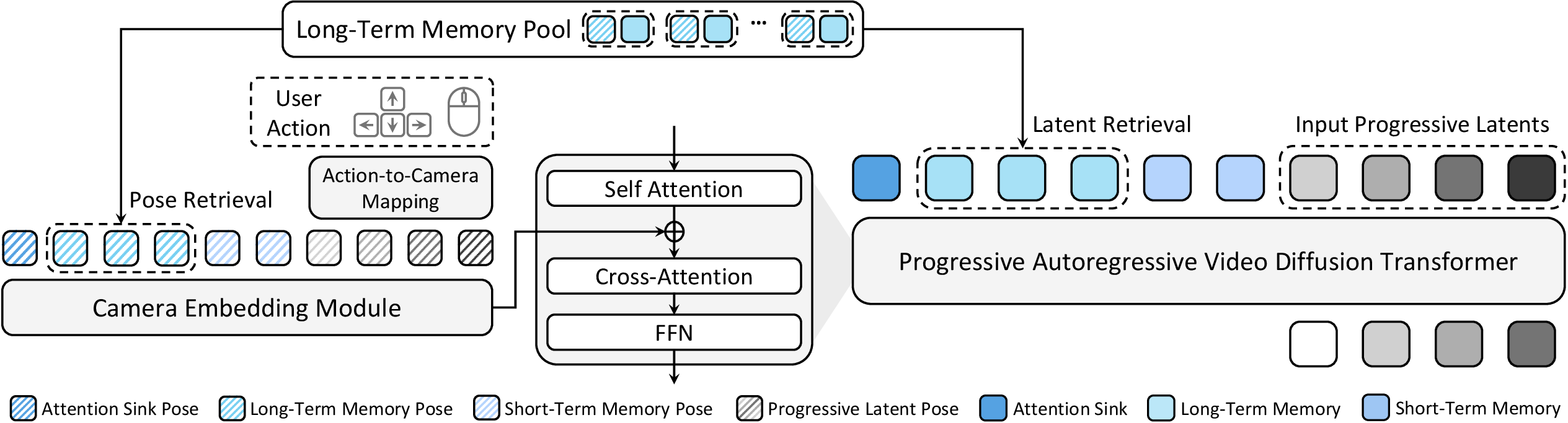
WorldCam builds on a video “diffusion transformer,” a type of AI that starts from noisy, messy video and gradually “cleans” it to produce a clear, realistic sequence that matches given instructions. WorldCam adds several key pieces so the video matches your actions and stays consistent:
- Turning actions into exact camera motion
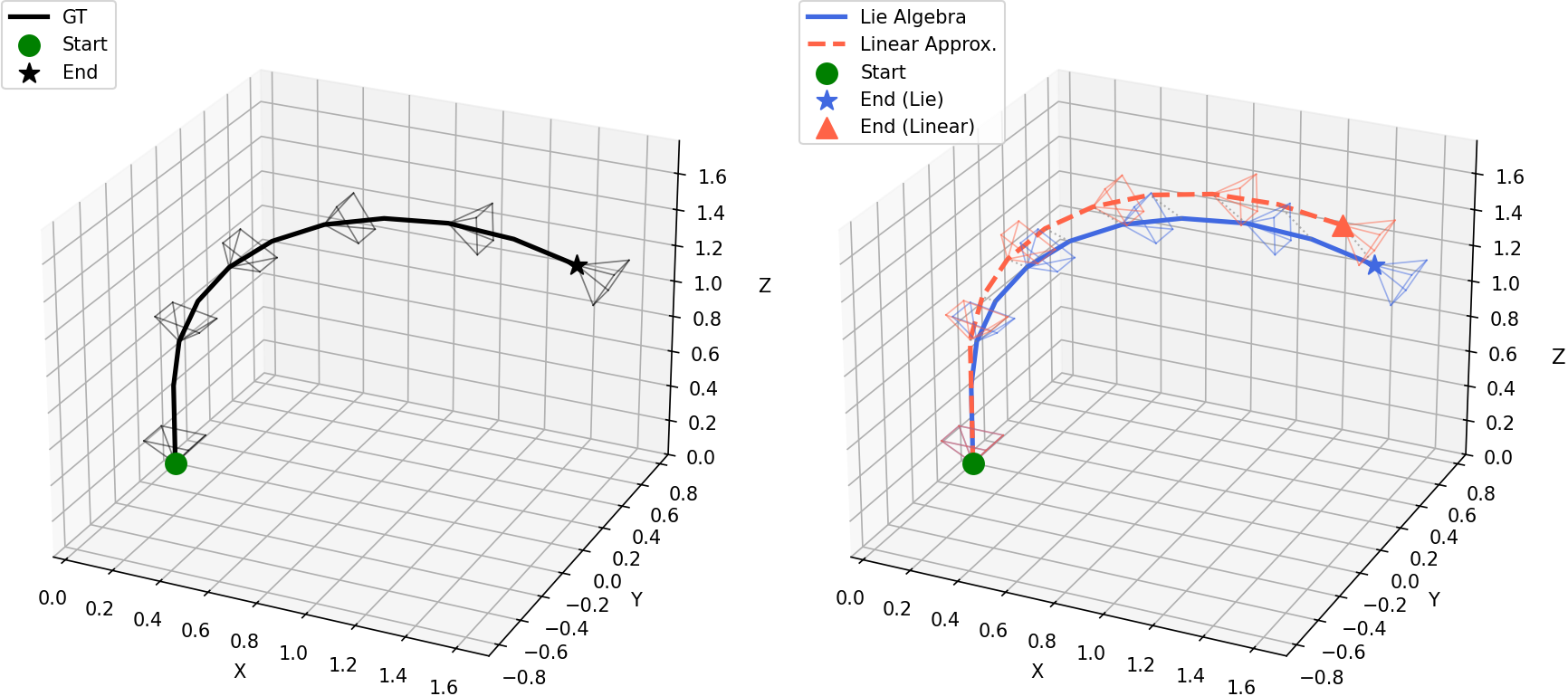
- Idea: Your keyboard and mouse don’t move the 3D world directly—they move the camera through it. WorldCam turns your inputs into a full 3D camera move with 6 degrees of freedom (6‑DoF): moving forward/back, left/right, up/down, and rotating (turning, looking up/down, tilting).
- How: Instead of a simple approximation, WorldCam uses a physics‑friendly math tool (called Lie algebra) that handles combined moves smoothly—like turning and sliding at the same time (imagine the “twist” of a screw: rotate and move together). This gives precise, realistic camera steps from one frame to the next.
- Feeding the camera pose into the video generator
- The camera pose (where the camera is and where it’s pointing) is encoded into numbers the model understands and injected into the video model’s layers.
- This makes the AI “know” exactly how the camera should move, so the video matches your actions frame by frame.
- Long‑term memory anchored by camera pose
- WorldCam keeps a memory of what it generated before, along with the camera poses where those frames were seen—like a scrapbook labeled with “GPS + compass” for each view.
- When you come back near a previous spot or look in a similar direction, WorldCam retrieves those memories and uses them as guidance, so the same walls, doors, and layouts appear consistently.
- Stable long‑sequence generation
- Progressive noise: Within each chunk of frames, earlier frames get less noise (they’re more certain), and later ones get more (so they can be corrected). This reduces errors from piling up over time.
- Attention anchors (“attention sink”): The model keeps a few initial frames as steady references, helping preserve style, UI elements, and overall stability.
- Short‑term memory: It also feeds in the most recent frames to keep motion smooth and avoid drifting off model.
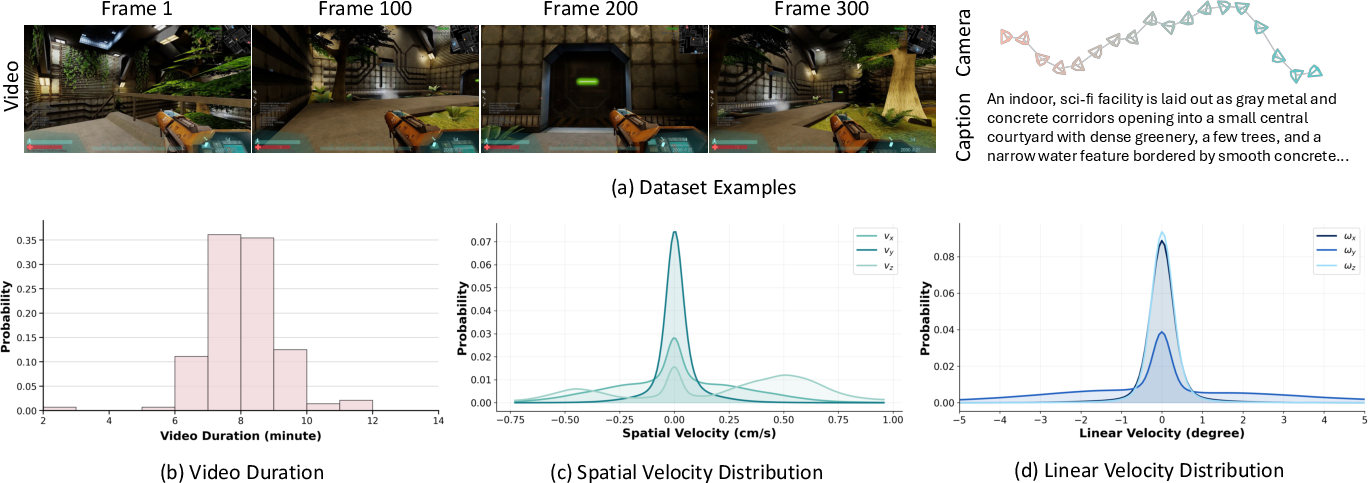
- A new dataset: WorldCam‑50h
- The team built a 50‑hour collection of real human gameplay from three games (including two open‑licensed titles: Xonotic and Unvanquished).
- Each video chunk includes:
- Camera trajectories (where the camera moved and pointed).
- Text descriptions of the scenes (to help the model keep style and layout consistent).
What did they find?
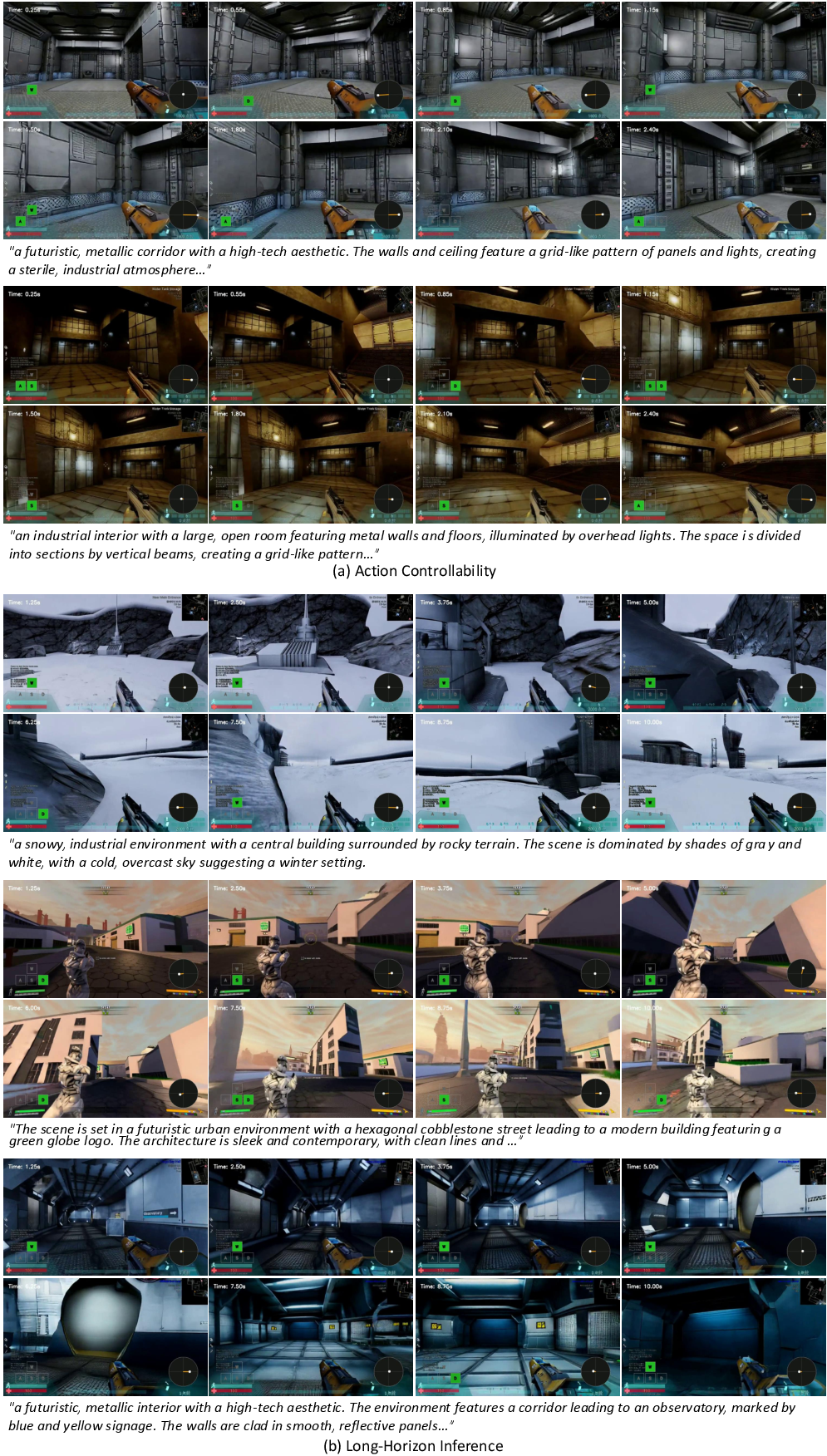
- More accurate control: WorldCam follows the player’s actions more precisely than previous systems. When the user turns or moves, the AI’s camera does the same with lower error.
- Better long‑term quality: Over long videos (hundreds of frames), the visuals stay clearer and more stable. The world doesn’t dissolve into blur or noise as easily.
- Stronger 3D consistency: If you revisit the same spot, the same structures appear in the same layout and look similar from the same angles—like a real 3D game world should.
- Human ratings: In user studies, people rated WorldCam higher than other methods for action control, visual quality, and 3D consistency.
Why this matters: Together, these show that using camera pose as the “common language” for both controlling motion and organizing memory makes a big difference in realism and playability.
Why is this important?
- Toward playable AI worlds: This brings us closer to AI systems that can act like lightweight game engines—interactive, responsive, and visually consistent over time.
- Better training grounds: Stable, controllable 3D video worlds are useful for training robots, testing navigation algorithms, and building VR experiences.
- Reproducible research: The open parts of the WorldCam‑50h dataset give the community shared, realistic data to build on and compare methods fairly.
In short
WorldCam shows that treating the camera pose as the “anchor” for everything—translating your actions into exact camera motion and using that same pose to organize long‑term memory—unlocks precise control and long‑lasting 3D consistency. Paired with a new gameplay dataset, it clearly outperforms previous methods and points the way toward richer, more reliable interactive AI worlds.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
- Dataset scope and dynamics
- Training and evaluation are restricted to static single-player environments without dynamic objects or other agents; no modeling of moving entities, object interactions, or stateful physics is addressed. Future work: incorporate dynamic, interactive objects and multi-agent scenarios with consistent object-level states.
- Genre and camera diversity
- Experiments target first-person shooter–style navigation; generalization to third-person cameras, driving/simulation games, aerial cameras, or non-holonomic systems is untested. Future work: evaluate across diverse genres and camera control schemes.
- Action-to-camera mapping realism
- The Lie algebra mapping assumes a continuous SE(3) control model, but many games impose game-specific constraints (e.g., no roll, head bobbing, camera smoothing, acceleration curves, collision-induced motion limits). Open question: how to learn or adapt action-to-camera mappings that honor game-specific kinematics and constraints without hand-tuned parameters.
- Controller modality coverage
- Only keyboard–mouse input is considered; support for gamepads, touch, motion controllers, or VR HMD/6-DoF inputs is not demonstrated. Future work: extend to multi-modal control inputs and learn cross-device mappings.
- Intrinsics and lens modeling
- Camera conditioning uses pose (extrinsics) via Plücker embeddings; camera intrinsics (e.g., FOV changes, lens distortion, zoom) are not modeled despite being estimated by ViPE. Open question: how to condition on and adapt to time-varying intrinsics.
- Pose accumulation and drift
- Global pose is obtained by accumulating relative motions with no explicit loop-closure or drift correction mechanism; long runs could accumulate error. Future work: integrate SLAM-like consistency (e.g., learned loop closure, pose-graph optimization) or learned drift correction from memory.
- Memory retrieval geometry
- Long-term memory retrieval is pose-only (translation, then orientation), ignoring occlusions, depth, and FOV overlap; retrieval may fetch geometrically visible-inconsistent frames. Future work: add depth- or visibility-aware retrieval (learned or estimated), or learned geometric overlap predictors.
- Memory scaling and policies
- The growth, eviction, and computational cost of the long-term memory pool for horizons beyond 200 frames are not characterized. Open question: what retention and eviction policies (e.g., submodular selection, keyframe summarization) best trade off 3D consistency and efficiency for minutes-long sessions.
- Explicit 3D scene representation
- The model enforces consistency in image space but does not build an explicit, renderable 3D map; novel-view control remains tied to the generative model’s latent memory rather than a persistent scene. Future work: hybridize with explicit 3D representations (e.g., radiance fields, point/mesh maps) for stronger multi-view consistency and free camera control.
- Long-horizon limits
- “Long-horizon” evaluation is capped at 200 frames (~10 s); robustness over minutes or hours, across multiple revisits and large loops, is untested. Future work: benchmark sustained sessions with repeated revisits and complex trajectories.
- Real-time interactivity and latency
- No end-to-end latency, throughput, or memory footprint is reported; feasibility for real-time interaction (e.g., 60 FPS, sub-50 ms response) remains unknown. Future work: profile and optimize inference (distillation, KV caching, sparse attention) for interactive rates on commodity hardware.
- Evaluation with pseudo camera trajectories
- Action controllability is measured by estimating camera trajectories from generated videos via ViPE, which can be brittle on synthetic frames; metric validity under failure cases is not analyzed. Open question: how to devise more reliable controllability metrics (e.g., instrumented renders, control-aware observers).
- Sim(3) alignment in metrics
- RPE is reported after Sim(3) Umeyama alignment, masking absolute scale and drift errors; absolute-scale adherence is not evaluated. Future work: include scale-aware metrics and world-scale stability tests.
- Fairness and breadth of benchmarks
- Evaluation focuses on a new in-house dataset and a few baselines; broader public benchmarks and cross-dataset generalization to other titles/engines are missing. Future work: standardize tasks and release comprehensive, open benchmarks for interactive world models.
- Text–world grounding
- Text captions guide style but there is no mechanism ensuring long-term consistency between textual scene descriptions and the evolving world across sessions. Open question: how to maintain text-conditioned, persistent world semantics and style over long horizons.
- Handling environmental changes
- Lighting changes, time-of-day transitions, or user-induced environment changes (e.g., doors opening) are not considered; the approach assumes static appearance. Future work: model stateful environmental variations and appearance dynamics.
- Training signal for geometry
- There is no explicit geometric self-consistency loss (e.g., depth or reprojection losses); consistency relies on pose conditioning and memory. Future work: incorporate multi-view geometric constraints or self-supervised depth/flow objectives.
- Robustness to OOD actions
- Performance under out-of-distribution control patterns (e.g., extreme mouse flicks, bunny hopping, rapid strafing) or varying frame rates is not analyzed. Future work: stress-test and augment training for extreme and rare action distributions.
- Plücker embedding design choices
- The choice of Plücker embeddings and injection after self-attention is not compared against alternative camera encodings (e.g., quaternions+translation, camera matrices, spherical harmonics) or injection sites. Future work: systematically ablate camera encoding and conditioning strategies.
- Attention sink side effects
- Attention sinks anchor to initial frames; how this impacts rapid scene/style changes, scene resets, or teleports is unclear. Open question: can adaptive or scene-aware anchoring avoid stale-style bias.
- Dataset licensing and reproducibility
- The dataset includes a closed-licensed title (Counter-Strike) and uses pseudo ground-truth poses; it is unclear whether all training data used for reported results will be released. Future work: ensure fully open, reproducible training sets and quantify performance when training on open-only subsets.
- Caption quality and supervision
- Captions are autogenerated (Qwen2.5-VL) without human verification; the impact of caption noise on style and content fidelity is not studied. Future work: assess sensitivity to caption errors and explore better vision–language supervision.
- Generalization to photorealism and diverse visuals
- Results are shown on a limited set of game aesthetics; transfer to photorealistic or highly stylized domains is untested. Future work: evaluate domain adaptation and robustness to diverse visual styles.
Practical Applications
Immediate Applications
These applications can be deployed with the paper’s current methods, codebase, and dataset (or minor engineering), especially in domains that can tolerate the current constraints: static environments, game-like visuals, offline or near–real-time inference, and known 6-DoF camera/control mappings.
- Generative playtesting and level previsualization
- Sectors: gaming, software tools
- What: Rapidly generate long-horizon, first-person walkthroughs from a starting frame and action script to evaluate navigation flow, line-of-sight, and spatial readability of levels before full asset production.
- Tools/products/workflows: “WorldCam for Unreal/Unity” plugin; designer provides a seed image or blockout + action macros; export 200–500 frame loops for review.
- Assumptions/dependencies: Static scenes (no moving NPCs/physics), FPS-like control schemes, GPU resources for windowed autoregressive generation; style/domain match to training games.
- Automated QA for action–camera alignment and regression testing
- Sectors: gaming QA, devops
- What: Drive deterministic action scripts and automatically score camera trajectory adherence with RPE metrics; detect drift, input–response lag, or camera bugs across builds.
- Tools/products/workflows: CI step that replays scripts, runs ViPE (or built-in tracker) to recover camera, compares to ground truth with Umeyama-aligned RPE; alert thresholds.
- Assumptions/dependencies: Stable camera estimation in generated videos; curated action scripts; acceptance that visuals are generative approximations.
- Synthetic data generation for vision tasks (SLAM/VO/pose)
- Sectors: computer vision, robotics, academia
- What: Produce long, 3D-consistent sequences with known 6-DoF to augment training for VO/SLAM, camera pose regression, and multi-view feature learning.
- Tools/products/workflows: Batch generation pipeline using WorldCam-50h prompts and action trajectories; export frames + poses; integrate with DUSt3R/MEt3R-style training.
- Assumptions/dependencies: Domain gap to real or photorealistic data; static scenes; camera intrinsics/extrinsics recorded or inferred.
- Benchmarking long-horizon 3D consistency for generative video
- Sectors: academia, evaluation platforms
- What: Adopt the paper’s metrics (palindrome PSNR/LPIPS, DINO similarity, MEt3R, Sharpness) and protocols to standardize evaluation of 3D-consistent world models.
- Tools/products/workflows: Open benchmark suite + leaderboards; closed-loop trajectories with fixed seeds and starting frames.
- Assumptions/dependencies: Community adoption; consistent inference settings across models; availability of evaluation code.
- Pose-anchored memory retrieval as a drop-in module for video generators
- Sectors: media software, video generation
- What: Use pose-indexed latent retrieval to preserve scene layout and style across shots or revisits in storyboards, tours, or game trailers.
- Tools/products/workflows: “PoseCache” library for DiTs; Plücker-embedded pose keys; TopK by translation then rotation trace.
- Assumptions/dependencies: Availability or estimation of camera poses; latent-space compatibility; static backgrounds or controlled occlusions.
- Creator co-pilot for UGC walkthroughs and map previews
- Sectors: media, streaming, e-sports content
- What: Generate stylized, long, stable walkthroughs from a screenshot + prompt + input macros for teasers, map explainers, or route guides.
- Tools/products/workflows: Web UI: upload seed image, type theme text, paste control macro; render and export.
- Assumptions/dependencies: Copyright-safe inputs; compute cost; content moderation.
- E-sports and skills training visualizations
- Sectors: education/training, e-sports coaching
- What: Visualize pathing, angle holds, or retake routes under precise camera control; rehearse spatial strategies with consistent geometry.
- Tools/products/workflows: Coaching tool that loads seed scenes, scripts angles and peeks, exports consistent replay clips.
- Assumptions/dependencies: Static scenes; stylistic similarity to target title; no enemy behavior modeling.
- Robotics perception prototyping with camera-pose scripts
- Sectors: robotics, autonomy R&D
- What: Stress-test VO/feature tracking under aggressive 6-DoF “screw” motions using Lie algebra action-to-camera mapping; probe failure cases in coupled rotations/translations.
- Tools/products/workflows: Script spatial-velocity twists; generate sequences; evaluate feature persistence and drift.
- Assumptions/dependencies: Visual domain mismatch to real robots; absence of physically grounded dynamics.
- Head-/controller-driven XR video previews
- Sectors: XR/VR
- What: Map 6-DoF headset or controller trajectories to camera poses to preview scene motion or comfort profiles with 3D-consistent frames.
- Tools/products/workflows: Offline “comfort rehearsal” generator; import recorded head pose; export stabilized previews.
- Assumptions/dependencies: Latency not yet suitable for live real-time; reliance on pre-recorded or slow-updated trajectories.
- WorldCam-50h dataset use for research and teaching
- Sectors: academia, open-source
- What: Reproducible experiments on interactive world modeling, 3D-consistent video generation, action-to-camera learning, and memory retrieval.
- Tools/products/workflows: Course assignments; benchmark baselines; ablation studies with open-licensed Xonotic/Unvanquished splits.
- Assumptions/dependencies: Access to GPUs; awareness that part of the collection references a closed-licensed game (Counter-Strike) though open subsets are available.
- Camera-conditioned stabilization and re-timing in video editing
- Sectors: media tools
- What: Inject target camera pose sequences to reframe or stabilize shaky footage while preserving 3D layout cues.
- Tools/products/workflows: Editor plugin taking estimated camera path of source and target path constraints; render via DiT backbone.
- Assumptions/dependencies: Robust pose estimation on user footage; acceptance of generative re-render rather than pure warp.
- Safety and governance sandboxes for AI-generated game content
- Sectors: policy/compliance, platform governance
- What: Pilot review pipelines for licensing (open-licensed assets), watermarking, and disclosure labels for generated playtest clips.
- Tools/products/workflows: Content provenance tags; automated caption scanning; license templates for open-source assets.
- Assumptions/dependencies: Platform policies; adoption of watermarking standards.
Long-Term Applications
These applications require further research for dynamic scenes, physics, real-time inference, broader domain coverage, richer memory/retrieval, and integration with production pipelines and devices.
- Generative game engine components (coexistence with physics and dynamic NPCs)
- Sectors: gaming, engines/tools
- What: Replace parts of the rendering/camera subsystem with pose-conditioned generative modules that remain consistent across long sessions and revisits, while interacting with live gameplay logic.
- Tools/products/workflows: Hybrid rasterization + generative background/skybox; pose-anchored caches; toolchains for author override.
- Assumptions/dependencies: Real-time performance at 60–120 FPS; dynamic object consistency; temporal stability under player interactions; memory budgets.
- Open-world content synthesis with persistent geography
- Sectors: gaming, UGC platforms
- What: Autonomously extend maps beyond authored areas while preserving topological consistency and enabling return-to-location revisits.
- Tools/products/workflows: World “stitcher” using large-scale pose-indexed memory, streaming storage, and retrieval learned beyond translation/rotation (e.g., depth/FOV-aware).
- Assumptions/dependencies: Scalable memory/indexing; depth- or geometry-aware retrieval; content moderation; authoring controls.
- Real-time XR telepresence and comfort-aware rendering
- Sectors: XR/VR, healthcare
- What: Drive generative scenes directly from live 6-DoF head/controller pose with sub-20 ms motion-to-photon, maintaining 3D consistency to reduce discomfort.
- Tools/products/workflows: Low-latency pose encoder, distillation to fast backbones, foveated rendering.
- Assumptions/dependencies: Significant model compression/distillation; hardware acceleration; robust handling of rapid rotations.
- Simulation for autonomous navigation and drones with domain realism
- Sectors: automotive, aerospace, robotics
- What: Train and evaluate planners and perception stacks in pose-consistent generative worlds with controllable motion statistics and environmental diversity.
- Tools/products/workflows: Curriculum of twist trajectories; sensor models (rolling shutter, noise); multi-sensor conditioning.
- Assumptions/dependencies: Photorealism and physically plausible dynamics; dynamic agents; accurate depth and semantics; sim2real validation.
- Generalist embodied agents with pose-grounded world models
- Sectors: AI/AGI research
- What: Use camera pose as a shared space to couple action policies, memory, and perception for long-horizon planning and revisits across tasks.
- Tools/products/workflows: RL/IL training loops with pose-indexed memory; multi-modal conditioning (text+pose+actions).
- Assumptions/dependencies: On-policy training stability; credit assignment over long horizons; broader datasets beyond FPS domains.
- Video-to-3D and inverse rendering co-systems
- Sectors: 3D content, VFX, AEC
- What: Bootstrap consistent multi-view frames for robust 3D reconstruction (NeRF/SDF) from sparse inputs; jointly optimize camera, depth, and appearance.
- Tools/products/workflows: Coupled DiT + neural field optimizers; pose-anchored refinement; geometry-aware memory.
- Assumptions/dependencies: Accurate geometry over long sequences; handling of parallax and occlusions; metric scale recovery.
- Multi-actor, physics-aware generative scenes
- Sectors: gaming, film/media
- What: Extend from static worlds to dynamic scenes with actors, rigid/soft-body physics, and interaction-aware consistency.
- Tools/products/workflows: Action-to-state extensions beyond camera; physics priors; object-centric memory and retrieval.
- Assumptions/dependencies: Robust object tracking and dynamics modeling; scalable autoregression with many entities.
- Facility rehearsal and accessibility navigation previews from floorplans/photos
- Sectors: education/training, public services
- What: Turn architectural inputs into 3D-consistent walkthroughs for emergency egress drills or accessibility route previews.
- Tools/products/workflows: Floorplan-to-seed-image + text; route scripts; policy-compliant content hosting for public use.
- Assumptions/dependencies: Domain adaptation from games to real buildings; accuracy of layout; privacy and safety reviews.
- Standardization and policy for provenance and IP in generative gameplay
- Sectors: policy, standards bodies
- What: Define watermarking, labeling, and dataset licensing norms for generative world content used in marketing, esports, or education.
- Tools/products/workflows: Open standards for pose-conditioned T2V provenance; audit trails for training data.
- Assumptions/dependencies: Cross-industry agreement; detection robustness; legal frameworks.
- Cloud “CameraPose-T2V” platform APIs
- Sectors: software, cloud
- What: Offer SDKs where developers submit seed frames, text, and pose/action scripts to stream long-horizon, consistent videos.
- Tools/products/workflows: Serverless inference with retrieval caches; usage-based billing; developer dashboards.
- Assumptions/dependencies: Cost controls; GPU availability; content safety tooling.
- Retrieval enhanced with depth/semantic overlap
- Sectors: vision/gen video
- What: Improve pose-indexed memory with depth- or FOV-aware overlap measures and semantic keys to handle occlusions and narrow corridors.
- Tools/products/workflows: Lightweight depth prediction in-loop; semantic descriptor banks.
- Assumptions/dependencies: Extra compute; robust depth estimation on generated frames; failure handling.
- Cinematic previs with artist-driven camera paths
- Sectors: film/TV, advertising
- What: Artists sketch camera splines or specify twists; system renders long, consistent previs with stable layout for blocking and scene planning.
- Tools/products/workflows: DCC plugins (Maya/Blender) connecting camera curves to pose embeddings; shot management with pose-aware memory.
- Assumptions/dependencies: Higher photorealism; integration with asset pipelines; legal use of training styles.
Cross-cutting assumptions and dependencies
- Compute: Current model uses a DiT backbone with substantial GPU needs; real-time applications require distillation/acceleration.
- Domain coverage: Trained on FPS-like, static-environment gameplay; broader domains (dynamic scenes, real-world imagery) need data and adaptation.
- Camera pose availability: Best results when 6-DoF poses (or head/controller trajectories) are known or reliably estimated.
- Memory scaling: Long-horizon revisits depend on scalable, efficient, and accurate memory indexing; depth/FOV cues may be needed for complex layouts.
- Licensing and safety: Use open-licensed assets when distributing; adopt watermarking/provenance for generated content; adhere to game IP policies.
- Evaluation: Adopt the paper’s long-horizon metrics and closed-loop protocols to ensure fairness and detect blur-induced metric artifacts.
Glossary
- 6-DoF: Six degrees of freedom describing 3D rigid motion (three for translation, three for rotation). "derive precise 6-DoF camera poses"
- AdaLN: Adaptive Layer Normalization; a conditioning mechanism that modulates network activations with external signals. "AdaLN~\cite{xiao2025worldmem}"
- Attention sink: A set of fixed tokens retained to stabilize attention in long sequences during inference. "attention sink mechanism inspired by StreamingLLM"
- Autoregressive video diffusion: Generating future frames by repeatedly conditioning on previously generated frames within a diffusion framework. "long-horizon autoregressive video diffusion"
- Camera extrinsics: The external camera parameters (rotation and translation) that place the camera in world coordinates. "camera extrinsics"
- Camera intrinsics: The internal parameters of a camera (e.g., focal length, principal point) that map 3D rays to image coordinates. "camera intrinsics"
- Cross-attention: An attention mechanism where one sequence (e.g., video tokens) attends to another (e.g., text or actions) for conditioning. "text cross-attention layers"
- DINO Similarity: A feature-space similarity metric computed using DINO features to assess appearance consistency across views. "DINO Similarity"
- DINOv2: A self-supervised vision model used to extract robust image features for evaluation. "DINOv2~\cite{oquab2023dinov2}"
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion models that denoise latent variables via learned dynamics. "Video Diffusion Transformer (DiT)"
- DUSt3R: A method for reconstructing dense 3D point correspondences from image pairs, used to assess geometric consistency. "DUSt3R~\cite{wang2024dust3r}"
- Field-of-View (FOV) overlap: The shared visible region between two camera views, used for view selection/retrieval. "Field-of-View (FOV) overlap"
- Lie algebra se(3): The algebra of spatial velocities (twists) corresponding to 3D rigid-body motions in SE(3). "the Lie algebra "
- Matrix exponential map: A mapping from Lie algebra elements (twists) to Lie group elements (poses) that integrates velocities into motions. "via the matrix exponential map"
- MEt3R: A metric that evaluates multi-view geometric consistency using 3D reconstructions and feature warping. "MEt3R~\cite{asim2025met3r}"
- Palindromic frame pairs: Pairs of frames along a closed-loop trajectory that revisit the same pose in forward and reverse order. "palindromic frame pairs"
- Plücker embeddings: A 6D representation of 3D lines (rays) used to encode camera geometry for conditioning. "Plücker embeddings"
- Pose composition: The group operation in SE(3) that combines successive relative motions into a global pose. "pose composition:"
- Pose-indexed memory retrieval: Selecting past latent features by indexing a memory bank using current camera poses for geometric consistency. "Pose-indexed memory retrieval."
- Progressive noise scheduling: Assigning increasing noise levels across frames within each denoising window to stabilize long-horizon generation. "a progressive per-frame noise schedule"
- Relative Pose Error (RPE): A metric that measures the discrepancy between estimated and ground-truth camera motions in translation and rotation. "Relative Pose Errors"
- SE(3): The Special Euclidean group of 3D rigid-body transformations (rotations and translations). "on the manifold"
- Sim(3) Umeyama alignment: Alignment under similarity transforms (rotation, translation, uniform scale) using Umeyama’s least-squares method. "Sim(3) Umeyama alignment~\cite{umeyama2002least}"
- Spatio-temporal self-attention: Self-attention applied jointly across spatial and temporal dimensions to model video dependencies. "spatio-temporal self-attention"
- StreamingLLM: A technique for stabilizing attention in long-context LLMs by retaining anchor tokens; adapted here for video generation. "StreamingLLM~\cite{xiao2023efficient}"
- Screw motion: A coupled 3D motion combining rotation about and translation along an axis, arising from simultaneous inputs. "screw motion"
- Trace of the relative rotation matrix: A scalar measure derived from the rotation matrix used to assess angular similarity between views. "measured using the trace of the relative rotation matrix"
- Twist vector: A 6D vector of linear and angular velocities representing an instantaneous rigid-body motion in se(3). "twist vector "
- Variance of the Laplacian: An image sharpness metric measuring the spread of the Laplacian response; higher values indicate sharper images. "variance of the Laplacian"
- Variational Autoencoder (VAE): A latent-variable model that encodes images/videos to and from a lower-dimensional latent space. "the VAE encoder"
- VBench++: A benchmark suite that evaluates multiple aspects of video quality, consistency, and motion. "VBench++~\cite{huang2024vbench++}"
- ViPE: A method for estimating video camera intrinsics and extrinsics used for annotation and evaluation. "ViPE~\cite{huang2025vipe}"
Collections
Sign up for free to add this paper to one or more collections.