- The paper presents PaperJury, a deterministic system that replaces open-ended critiques with a due-process review for safe, bounded LaTeX revisions.
- It employs a deterministic-versus-semantic split, confining LLMs to bounded tasks while ensuring edit safety via immutable claim spines and guard chains.
- Experimental results show improved F1, verdict precision, and safety metrics, demonstrating its robust performance for pre-submission manuscript hardening.
PaperJury: Deterministic Orchestration for Reliable Bounded LaTeX Revision
Overview and Motivation
PaperJury addresses the pre-submission hardening of LaTeX-based computer science manuscripts—a task distinct from conventional drafting assistance or local style critique. The core challenge is not simply generating critiques or refining prose but orchestrating a closed adversarial loop: identifying substantive manuscript flaws, governing which critiques lead to action, and safely applying bounded revisions, all under constraints of precision, recall, and computational cost. Existing automated writing assistants or critique generators lack several essential properties for this high-stakes context: persistent issue identity across review rounds, deterministic routing from critique to verdict, and artifact-safe, bounded revision primitives.
System Architecture: Deterministic vs. Semantic Split
PaperJury’s design is based on a deterministic-versus-semantic pipeline separation. Deterministic orchestration manages all critical state transitions, decomposition, routing, and application/reversion of edits, ensuring reproducibility and consistency. Semantic agents (e.g., LLMs) are confined to well-bounded subtasks such as issue generation, judgment, and drafting revisions. This split ensures that safety, completion, and ledger state are governed by code rather than subject to LLM variability.
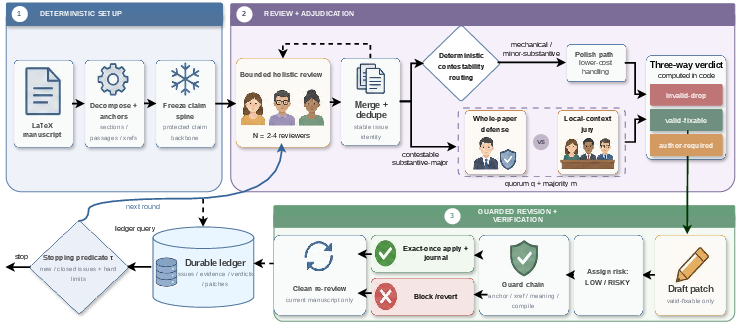
Figure 1: Overview of the PaperJury review-verdict-revise-verify pipeline.
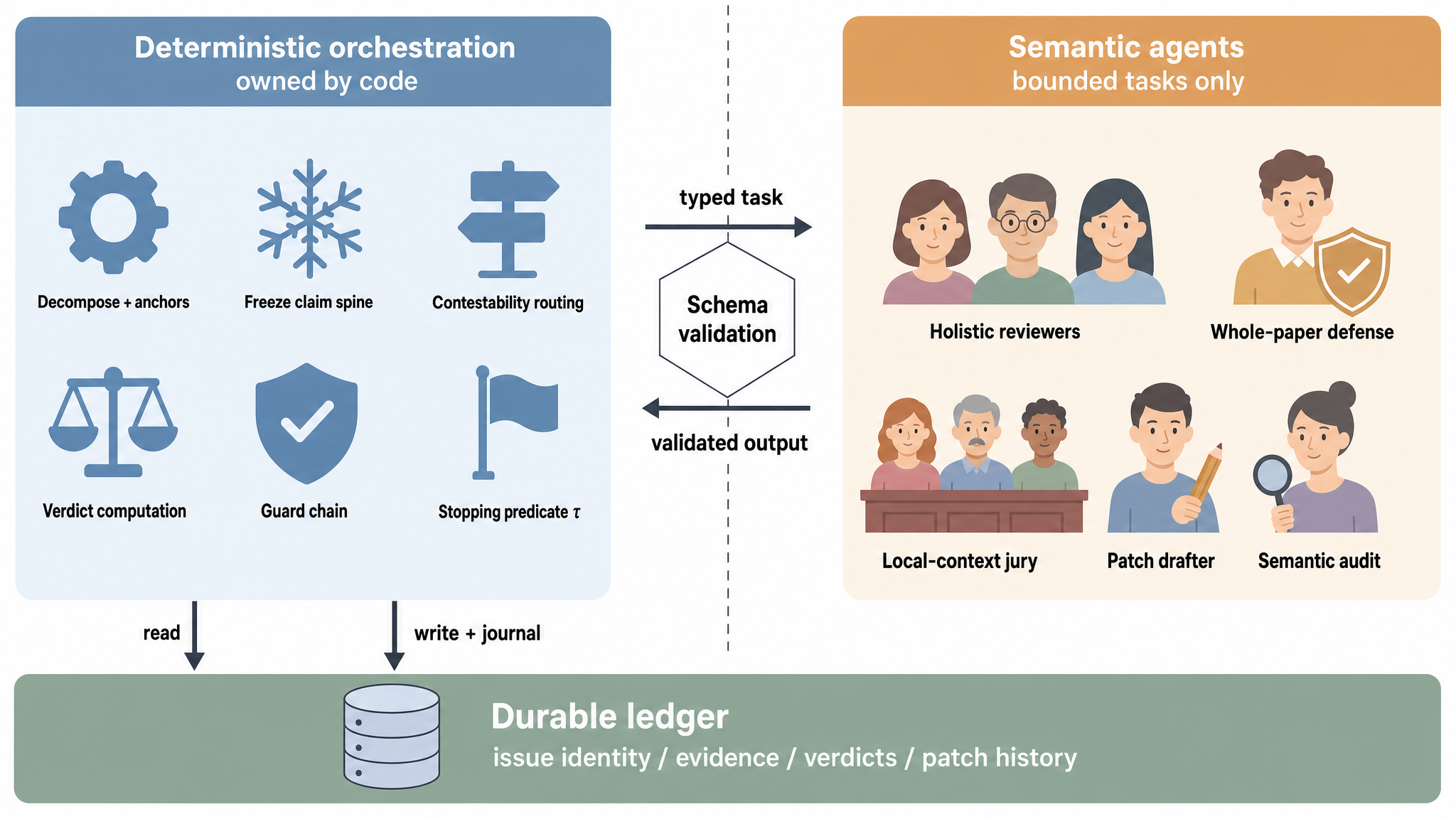
Figure 2: Deterministic-versus-semantic split with ledger-backed control flow.
Manuscript decomposition (D(x)) produces sections, passage anchors, and cross-reference targets, while a frozen claim spine (S) records central assertions. This claim spine, established before review and revision, is immutable under automated edits, mitigating risks of claim drift or silent semantic mutation.
Issues are generated by a small set of bounded holistic reviewers, each providing evidence-grounded weaknesses. These issues are assembled into a durable ledger, retaining provenance and enabling exact-once tracking through multiple review rounds.
Deterministic Routing, Due-Process Trial, and Adjudication
A defining feature is deterministic contestability-based routing. Not all issues are handled identically; only contestable, substantive-major issues proceed to expensive adjudication. Others follow lightweight paths. Contestable issues undergo a due-process trial: a whole-paper defense argues the case, while a decorrelated local-context jury provides localized evaluation.
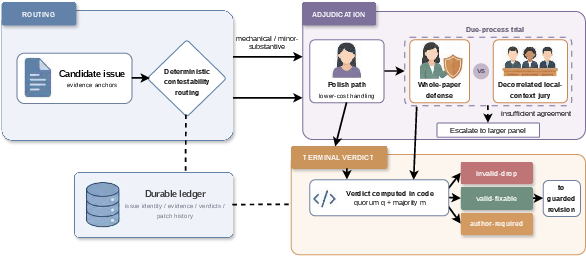
Figure 3: Deterministic routing and due-process adjudication for candidate issues.
Final verdicts for each issue are computed under explicit majority and quorum thresholds—never by a single semantic agent. Each issue attains one of three terminal classes:
- invalid-drop: reject the issue,
- valid-fixable: accept and machine-edit,
- author-required: defer action to the author where revision is unsafe or outside automated scope.
This strict isolation between issue validity and machine editability, paired with deterministic resolution, is instrumental in preserving both artifact safety and reliable process closure.
Anchored, Guarded Revision and Edit Safety
Edits are only drafted and applied for issues labelled valid-fixable. Each draft patch Pi is subject to a guard chain before application, including anchor-bounded diffs, reference and compile checks, and selective semantic audits depending on a risk categorization (ρi). Edits violating the frozen claim spine, cross-reference integrity, or compilation constraints are blocked. All edit actions are exactly-once and journaling ensures reversibility.
Experimental Protocol
The empirical evaluation adopts a two-arm expert-review protocol. One arm benchmarks issue discovery against expert panel ground truth; the second arm audits terminal class assignment accuracy, routing correctness, edit safety (edit-safety violation rate, ESVR), round convergence, and efficiency.
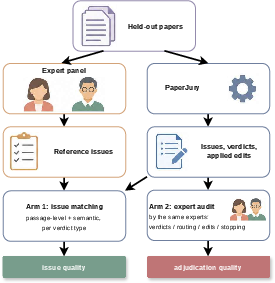
Figure 4: Two-arm expert-review evaluation protocol for PaperJury.
Comparison is made against four baselines:
- Forward-only Rewriter (no critique/issue ledger, direct revision),
- LLM Critic Only (critique without enforced verdict or safe revision),
- LLM-as-Judge Loop (judge-centered loop, relying on model for verdict/stopping),
- Naive Unbounded Generator (exhaustive high-recall critique generation).
Cost, measured as tokens per paper and wall-clock time, is evaluated to highlight practical deployment considerations.
Key Results
PaperJury achieves the best panel-relative F1 (0.656, macro-averaged per paper), the highest audited precision ($0.847$ on expert-audited issues), and the lowest edit-safety violation rate among editing systems (ESVR 0.025). Terminal verdict accuracy (expert agreement) is $0.887$, routing accuracy is $0.913$, and typical completion occurs in 3.08±0.67 rounds, with no executions hitting the five-round cap. Compared to the judge-centered loop, PaperJury achieves statistically significant improvements in F1, verdict precision, and ESVR while operating at moderate cost ($2.47$ hours, $6.76$ million tokens per paper).
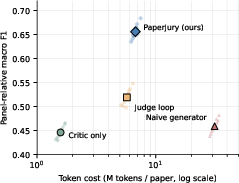
Figure 5: Quality-cost trade-off across issue-producing systems; PaperJury is positioned on the frontier, balancing F1 and efficiency.
Per-domain performance across vision, NLP, and ML papers confirms stability of outcomes (variation <0.03 in key metrics). Pairwise bootstrap comparisons at the paper level show consistent dominance over all baselines.
Ablation studies further analyze system design:
- Removing bounded review, routing, trial, claim spine, or guard chain demonstrably degrades F1, verdict accuracy, and edit safety in accordance with the function of each component.
Implications and Future Directions
PaperJury shifts the paradigm for trustworthy pre-submission revision from open-ended critique generation to closed-loop, governed orchestration. Practice-oriented implications include stricter control over edit traceability, deterministic convergence, and artifact safety—prerequisites for reliable unattended scientific writing assistance. The explicit three-way terminal verdict structure aligns well with real-world editorial workflows, where not all critiques should lead to revision and some issues require qualified author involvement.
Theoretical implications include a new template for agentic scientific workflows: one prioritizing deterministic orchestration, explicit state and verdict tracking, and bounded semantic agent applications. This work suggests that for high-stakes document revision and review, especially in scientific domains, load-bearing decisions and process safety must reside outside the discretion of generative models.
Extensions may target even broader classes of document artifacts, integration with submission or versioning platforms, transfer to multimodal (e.g., visual/textual) workflows, or co-design with further adversarial or human-in-the-loop verification modules. Addressing efficiency/fidelity trade-offs at even larger scale and under more adversarial distribution shifts is an open research challenge.
Conclusion
PaperJury demonstrates that placing critical process authority in deterministic orchestration, with semantic agents confined to bounded, auditable subtasks, produces measurable gains in both manuscript review quality and artifact safety for LaTeX scientific papers. The result is a robust, scalable approach to pre-submission hardening, with broad implications for the design of accountable AI-assisted scientific authoring tools and agentic scientific workflows.
Reference: "PaperJury: Due-Process Review for Bounded LaTeX Revision" (2606.16322)