Paper2Rebuttal: A Multi-Agent Framework for Transparent Author Response Assistance
Abstract: Writing effective rebuttals is a high-stakes task that demands more than linguistic fluency, as it requires precise alignment between reviewer intent and manuscript details. Current solutions typically treat this as a direct-to-text generation problem, suffering from hallucination, overlooked critiques, and a lack of verifiable grounding. To address these limitations, we introduce $\textbf{RebuttalAgent}$, the first multi-agents framework that reframes rebuttal generation as an evidence-centric planning task. Our system decomposes complex feedback into atomic concerns and dynamically constructs hybrid contexts by synthesizing compressed summaries with high-fidelity text while integrating an autonomous and on-demand external search module to resolve concerns requiring outside literature. By generating an inspectable response plan before drafting, $\textbf{RebuttalAgent}$ ensures that every argument is explicitly anchored in internal or external evidence. We validate our approach on the proposed $\textbf{RebuttalBench}$ and demonstrate that our pipeline outperforms strong baselines in coverage, faithfulness, and strategic coherence, offering a transparent and controllable assistant for the peer review process. Code will be released.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
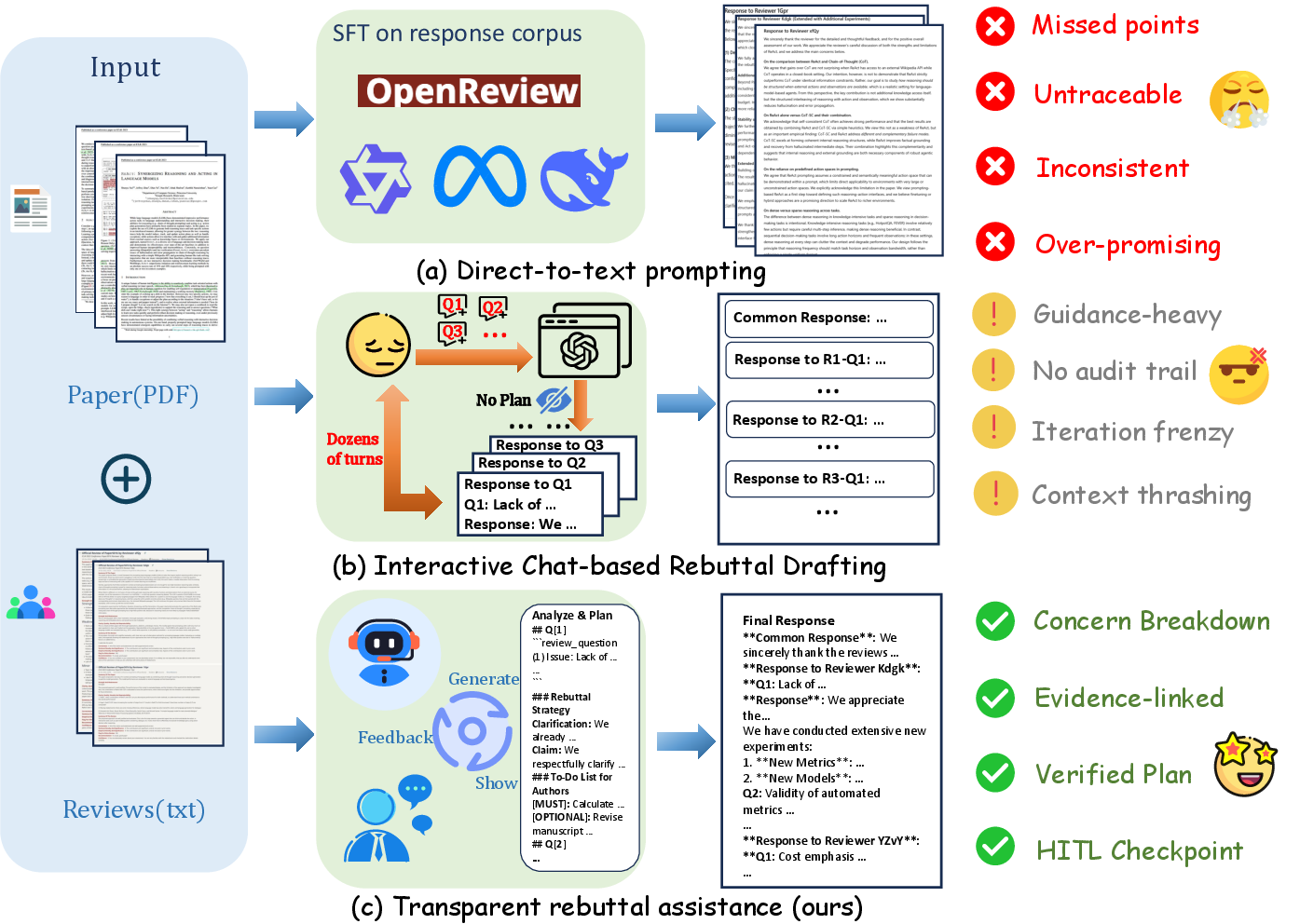
Scientists often have to write “rebuttals” — short responses to reviewers who judged their paper. Good rebuttals must be accurate, polite, and backed by real evidence from the paper or other research. Many AI tools try to write these rebuttals directly, but they sometimes make things up (hallucinate) or miss important points.
This paper introduces RebuttalAgent, an AI “team of helpers” that doesn’t jump straight into writing. Instead, it first makes a plan and gathers proof. The goal is to help authors write clear, trustworthy rebuttals that cover every reviewer concern and are easy to check.
The main goals and questions
The authors ask: How can we build an AI assistant that
- covers all reviewer concerns,
- stays faithful to the actual paper (no made-up results),
- links every claim to real evidence,
- stays consistent across the whole response?
They also ask whether their system can beat standard “just write the text” AI approaches, and they create a special test set to measure that.
How the system works (step by step, with plain-language analogies)
Think of RebuttalAgent like a team of specialists working together. Instead of a single AI writing everything at once, different “agents” handle different tasks, with checkpoints for quality.
Here’s the three-stage process:
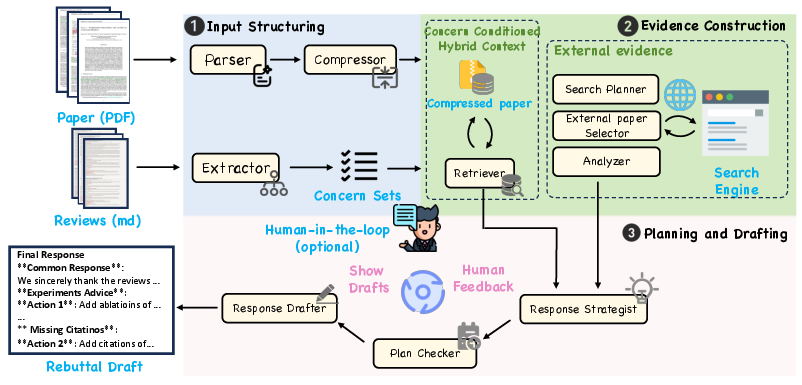
- Step 1: Organize the inputs (paper + reviews)
- The system turns the paper PDF into a structured format (like paragraphs with labels), then makes a short, careful summary that keeps the important facts. A checker makes sure nothing important was lost.
- It breaks each long reviewer comment into “atomic concerns” — small, specific questions or issues. Another checker ensures it didn’t miss anything or split things too much.
- Step 2: Build evidence for each concern
- The system creates a “hybrid context” for each concern: most of the paper stays summarized (to save space), but the parts that matter are expanded back into exact original text, so quotes and details are accurate.
- If a concern needs outside proof (like comparing with other papers), the system searches research sites, picks relevant papers, and makes short “evidence briefs” that are ready to cite.
- Step 3: Plan first, then draft
- A Strategist Agent makes a response plan for each concern, linking every point to internal (your paper) or external (other papers) evidence.
- If a reviewer asks for new experiments, the system does not invent results. Instead, it creates “action items” (a to-do list) with clear placeholders like [TBD] for later.
- The plan is shown to the author (human-in-the-loop) to approve or edit. Only then does a Drafter Agent turn the plan into a polished rebuttal.
Key ideas explained:
- Multi-agent: multiple specialized AI helpers instead of one all-purpose model.
- Hallucination: when an AI makes up facts or results that aren’t real.
- Evidence grounding: linking claims directly to text in the paper or to outside references.
- Human-in-the-loop: the author checks and approves plans before the AI writes.
What they built to test it
The team created RebuttalBench, a benchmark from real ICLR OpenReview discussions. Each example includes:
- the reviewer’s initial critique,
- the author’s rebuttal,
- and the reviewer’s follow-up (did the reviewer feel satisfied or not?).
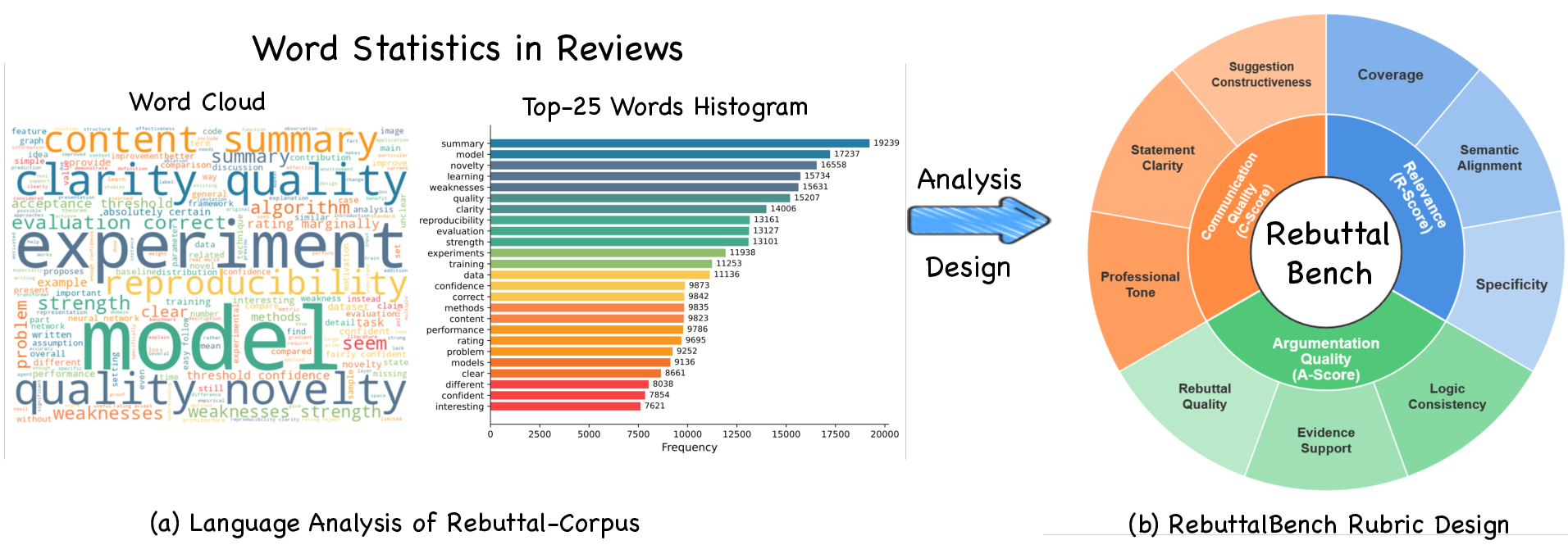
They evaluate responses using three main scores:
- Relevance: Does the rebuttal actually address the reviewer’s points, fully and specifically?
- Argumentation Quality: Are the claims logical and backed by proper evidence?
- Communication Quality: Is the tone professional and the writing clear and constructive?
They use an “AI-as-judge” rubric to score these, like a digital referee trained to grade based on a checklist.
Main findings and why they matter
- RebuttalAgent beats strong AI baselines that write directly from the prompt.
- It scores higher in Relevance (covers more points and is more specific) and Argumentation Quality (better logic and evidence).
- It also improves Communication Quality a bit (clearer and more professional).
- The advantage is bigger when the base AI model is weaker.
- In other words, the smart process (plan + evidence + checks) helps even small models perform much better.
- The biggest key to success is the evidence step.
- When they removed the external evidence briefs in tests, coverage and constructive suggestions dropped the most. This shows that gathering and summarizing outside papers is crucial for convincing, concrete rebuttals.
- Balanced improvements across the whole pipeline.
- The system helps not just with facts, but also with organizing responses and keeping a consistent stance across all reviewer points.
Why this matters: Rebuttals can affect whether a paper gets accepted. A tool that makes responses more accurate, complete, and transparent can help authors save time and avoid risky mistakes like inventing results.
What this could change in the future
- More trustworthy scientific communication: By forcing a “verify-then-write” workflow, the system reduces hallucinations and overpromising.
- Better author control: Authors see the plan and evidence first, then decide what to commit to. This keeps humans in charge.
- Wider use beyond rebuttals: The same idea (plan first, gather evidence, then write) can help with grant applications, literature reviews, and other evidence-heavy writing tasks.
- Fairer and faster review cycles: If rebuttals are clearer and better grounded, reviewers can make decisions more efficiently, potentially speeding up the whole process.
In short, RebuttalAgent turns rebuttal writing from a black box into a transparent, step-by-step teamwork process, helping authors respond accurately, politely, and with solid proof.
Knowledge Gaps
Below is a focused list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each point is phrased to be concrete and actionable for future research.
- Lack of human-centered evaluation: no user studies quantifying time saved, cognitive load reduction, usability, or author satisfaction when using RebuttalAgent versus standard workflows.
- Ecological validity not demonstrated: no evidence that system-generated rebuttals improve real outcomes (e.g., reviewer follow-up satisfaction, score changes, acceptance rates) compared to human-written rebuttals.
- Single-domain benchmark: RebuttalBench derives solely from ICLR/OpenReview in ML; generalization to other disciplines, venues, and review cultures (journals, double-blind processes, different rubrics) is untested.
- Positive/negative follow-up labeling is under-specified: the heuristics for classifying “resolved” vs “unresolved” concerns are not described or validated (e.g., manual annotation, inter-annotator agreement), risking noisy labels.
- Global consistency and commitment safety are not operationalized: no formal definition, algorithms, or quantitative metrics to detect cross-point contradictions, over-commitments, or strategy drift.
- Evidence-grounding evaluation is incomplete: no explicit metrics for passage-level citation correctness, traceability precision/recall, or link verification beyond LLM judge scores.
- Reliance on a single LLM-as-judge (Gemini-3-Flash): potential judge bias and style preferences; no triangulation with multiple judges, human experts, or alternative evaluation protocols; no calibration or agreement analysis.
- Baseline coverage is limited: no comparison against specialized rebuttal systems (e.g., SFT models trained on review–response pairs, retrieval-augmented baselines, structured-prompt monolithic pipelines) that could challenge the proposed approach more rigorously.
- External evidence retrieval scope and quality unknown: restricted to arXiv API; recall, precision, timeliness, venue legitimacy, and criteria for screening relevance/utility are not measured; risk of cherry-picking favorable sources.
- Ethical and policy compliance unaddressed: implications for double-blind review, confidentiality of manuscripts, permissible use of AI in rebuttals, and whether citing unreviewed preprints during rebuttal aligns with venue policies.
- Privacy and security risks: sending manuscript content to external tools/LLMs may leak confidential information; no discussion of data handling, storage, access controls, or compliance (e.g., GDPR, institutional policies).
- Robustness to adversarial inputs and noise: no stress tests for misleading, hostile, or content-free reviews; no analysis of resilience to PDF parsing errors, malformed references, or extremely long/complex documents.
- Compression fidelity and loss detection: the “consistency checker” for compressed manuscript representations is not specified; no quantitative measurement of information loss or misrepresentation rates during compression.
- Detection of “concerns requiring outside literature” is opaque: criteria and accuracy for deciding when external retrieval is necessary are not described; false positives/negatives not measured.
- Plan-level verification methods are unspecified: checker agents’ algorithms, error profiles, and performance (precision/recall for coverage and inconsistency detection) are not reported.
- Hallucination control not quantified: beyond qualitative claims and placeholders [TBD], there is no metric or audit of hallucination rates, fabricated results, or unverifiable claims in outputs.
- Cost, latency, and scalability unreported: token usage, wall-clock time, API/tool-call counts, and monetary cost per rebuttal are absent; throughput under real submission deadlines is unknown.
- Human-in-the-loop efficacy not evaluated: the effect of author checkpoints on quality, trust, and speed, and optimal points of intervention are not studied; UI/UX design is not presented.
- Multilingual and cross-cultural support missing: performance on non-English manuscripts/reviews, domain-specific terminology, and cultural differences in tone and argumentation are not evaluated.
- Reproducibility concerns: prompts, agent orchestration details, memory/state sharing, and decision policies are insufficiently documented; code is not yet released; results rely on closed-source models.
- Table and reporting clarity issues: numerical tables contain unresolved macros (e.g., “#1{…}”) and formatting errors, hindering replication and interpretability; no statistical significance or variance reported.
- Dataset construction and sampling bias: “top 20 papers with over 100 reviewers” is unclear/unlikely; selection criteria, representativeness, and potential biases in RebuttalBench-Challenge are not justified.
- Safety in external tool use: no analysis of prompt injection, malicious content from retrieved sources, or defenses (content sanitization, provenance checks, trust scoring).
- Fairness and equity implications: potential to advantage well-resourced authors; impact on review fairness and community norms is not examined.
- Scope and nomenclature ambiguity: inconsistent naming (“ResponseAgent” vs “RebuttalAgent”) and unclear boundaries of applicability (e.g., meta-review response, revision letters, camera-ready edits) leave extension pathways unspecified.
Glossary
- Ablation study: A controlled experiment where components of a system are removed to assess their individual contributions. "we perform controlled ablations by removing one module at a time from the full ebuttalAgent pipeline"
- Action items: Concrete, verifiable tasks proposed instead of fabricating results when new work is required. "and instead produces concrete Action Items framed as recommendations"
- AgentBench: A benchmark suite used to evaluate agentic LLMs on real-world tool use and task success. "benchmarks such as AgentBench~\cite{liu2025agentbenchevaluatingllmsagents}, WebArena~\cite{zhou2024webarenarealisticwebenvironment}, and GAIA~\cite{mialon2023gaiabenchmarkgeneralai} evaluate real-world tool use and end-to-end task success"
- Atomic concern: A minimally scoped, addressable unit of a reviewer’s critique extracted for precise handling. "extracting atomic reviewer concerns with coverage checks"
- Backbone (model backbone): The underlying LLM that powers a system, held constant to isolate pipeline effects. "instantiate RebuttalAgent with the same model as its foundation backbone"
- Bifurcated reasoning: A strategy that separates argumentation using existing evidence from proposals requiring new work. "our system overcomes this by implementing a bifurcated reasoning strategy"
- Chat-LLMs: Conversational LLMs used via interactive prompting interfaces. "The second paradigm relies on interactive sessions with proprietary chat-LLMs such as GPT or Gemini"
- Citation-ready briefs: Summaries of external literature structured for direct citation in rebuttals. "retrieving and summarizing external literature into citation-ready briefs"
- Commitment safety: Ensuring planned responses avoid contradictory or unverified promises across points. "checked for consistency and commitment safety"
- Compressor agent: An agent that condenses manuscript content into a compact representation while preserving key details. "A compressor agent subsequently distills these paragraphs into a concise representation"
- Consistency checker: A verifier that detects omissions or meaning changes when compressing or transforming text. "a consistency checker verifies each condensed unit against its source and automatically triggers reprocessing if it detects missing claims or semantic drift"
- Coverage checker: A verifier that ensures all substantive reviewer points are captured at appropriate granularity. "A coverage checker subsequently validates the output for intent preservation and appropriate granularity"
- Decision-and-evidence organization problem: Framing rebuttal writing as structuring decisions and linking them to evidence rather than pure generation. "We formulate rebuttal assistance as a decision-and-evidence organization problem"
- Dual-source evidence construction: Building evidence from both the manuscript and external literature to ground claims. "followed by a dual-source evidence construction phase"
- Evidence brief: A structured summary of retrieved works highlighting claims and comparisons for citation. "a structured evidence brief that highlights key claims and experimental comparisons"
- Evidence-centric planning: Planning responses around verifiable evidence before drafting text. "reframes rebuttal generation as an evidence-centric planning task"
- Extractor agent: An agent that parses reviews to identify and structure discrete concerns. "an extractor agent parses raw feedback into discrete and addressable atomic concerns"
- Fidelity check: A procedure ensuring that compressed or transformed content remains faithful to the original. "parsing and compressing the paper with fidelity checks"
- Global consistency: Maintaining a unified stance across all responses without contradictions. "Global Consistency, maintaining a unified stance and avoiding conflicting commitments across different responses"
- Hallucination: An LLM’s tendency to fabricate unsupported facts or results. "suffering from hallucination, overlooked critiques, and a lack of verifiable grounding"
- High-fidelity text: Original, precise manuscript passages used to avoid loss of detail during compression. "synthesizing compressed summaries with high-fidelity text"
- Human-in-the-loop: Involving authors to inspect, edit, and approve intermediate plans or artifacts. "with human-in-the-loop checkpoints before drafting the final response"
- Hybrid context: A mix of compressed summary and selected original text tailored to a specific concern. "This approach yields an atomic concern conditioned hybrid context"
- Inspectable response plan: A pre-drafting plan explicitly linking arguments to evidence for auditability. "By generating an inspectable response plan before drafting"
- Intent preservation: Retaining the reviewer’s original meaning when decomposing or regrouping critiques. "validates the output for intent preservation"
- LLM-as-judge: Using an LLM with a rubric to evaluate system outputs along defined dimensions. "we use an LLM-as-judge~\cite{zheng2023judging,lin2023llm} rubric"
- Long-context reasoning: Reasoning that operates over extended text inputs while maintaining coherence and relevance. "to enable stable long-context reasoning"
- Long-horizon tasks: Tasks requiring multi-step planning and tool use over extended sequences. "improves robustness in long-horizon tasks and reduces hallucinations"
- Multi-agent system: A system where specialized agents collaborate to decompose and solve complex tasks. "we propose RebuttalAgent, a multi-agent system"
- On-demand external evidence: Retrieving outside literature only when internal content is insufficient. "On-Demand External Evidence. While the hybrid context effectively grounds responses in the authors' own work, certain reviewer critiques necessitate evidence beyond the manuscript boundaries"
- OpenReview: A public peer-review platform from which real discussion threads are curated. "from the publicly available ICLR OpenReview forum"
- Opacity: The lack of transparency in intermediate reasoning steps of direct prompting workflows. "our agent system ... enforces a novel 'verify-then-write' workflow to overcome the opacity of previous two paradigms"
- Paragraph-indexed format: A representation that indexes manuscript paragraphs to enable targeted retrieval. "converts the manuscript PDF into a paragraph-indexed format"
- Parametric generation: Producing outputs solely from model parameters without external tools or retrieval. "purely parametric generation can accumulate errors and hallucinations"
- RebuttalBench: A benchmark dataset and protocol for evaluating rebuttal assistance systems. "We validate our approach on the proposed RebuttalBench"
- Rubric-based evaluation: Assessing outputs with a structured scoring rubric across multiple dimensions. "a rubric-based evaluation that measures relevance, global coherence, and argumentation quality"
- Screening agent: An agent that filters retrieved papers for relevance and usefulness. "A screening agent then filters these candidates for relevance and utility"
- Search planner: A component that formulates targeted search strategies for external retrieval. "A search planner initiates this expansion by formulating a targeted search strategy"
- Semantic drift: Unintended change in meaning introduced during compression or transformation. "missing claims or semantic drift"
- SFT (supervised fine-tuning): Training an LLM on labeled examples to specialize it for a task. "models that are supervised fine-tuned (SFT) on paper-response pairs"
- Token overhead: The additional context length consumed by representations, affecting efficiency limits. "Our compact format minimizes token overhead"
- Traceability: The ability to link each claim to specific internal passages or external citations. "traceability of evidence sources"
- Verify-then-write workflow: A process that verifies evidence and plans arguments before drafting text. "a novel 'verify-then-write' workflow"
Practical Applications
Below are actionable, real-world applications derived from the paper’s verify-then-write, multi-agent framework (concern decomposition, hybrid evidence construction, plan/checkers, and human-in-the-loop) and the RebuttalBench evaluation protocol.
Immediate Applications
- Author rebuttal assistant for conferences/journals (academia, publishing)
- Automatically decomposes reviews into atomic concerns, builds evidence-linked response plans, suggests citation-ready external briefs, and drafts rebuttals with placeholders for unrun experiments (to avoid hallucinations).
- Potential tools/products/workflows: Overleaf/OpenReview/arXiv plugins; a “RebuttalPlanner” SaaS with plan/evidence dashboards; MS Word/LaTeX add-ins.
- Assumptions/dependencies: Reliable PDF parsing; access to manuscript/source data; scholarly search APIs; privacy controls for confidential submissions; human review of commitments.
- Editorial triage and reviewer coaching (publishing, academia)
- Checks authors’ rebuttals for coverage, evidence linkage, tone, and commitment safety; highlights unresolved items for editors/reviewers.
- Potential tools/products/workflows: “Editor Dashboard” with coverage/consistency checkers; template-based feedback suggestions.
- Assumptions/dependencies: Editorial workflow integration; agreement on rubric criteria; policy on AI-assisted moderation.
- Internal design/code review response assistant (software, enterprise R&D)
- Structures reviewer feedback on design docs/PRs into atomic concerns, links to code/docs, creates action items; avoids overpromising with TBD placeholders.
- Potential tools/products/workflows: GitHub/GitLab/Bitbucket apps; RFC response generator; CI task tickets from action items.
- Assumptions/dependencies: Repo/doc access; embedding/search on code/docs; security/compliance for source access; developer oversight.
- Compliance and audit response drafting (finance, energy, telecom, manufacturing)
- Produces evidence-grounded responses to audit findings, maps controls/policies to each point, generates action plans.
- Potential tools/products/workflows: Integrations with GRC platforms (ServiceNow, Archer); “Commitment Safety Checker” for regulatory language.
- Assumptions/dependencies: Access to policies/logs; strict data governance; legal/compliance review; regulator-specific templates.
- Regulatory Q&A packages (healthcare/biotech/med-devices)
- Organizes agency questions into atomic concerns, links to dossier sections and literature, and prepares verifiable response plans.
- Potential tools/products/workflows: eCTD-aware evidence linker; “EvidenceBrief” generator for clinical/preclinical literature.
- Assumptions/dependencies: Dossier access; paywalled literature access; validation by regulatory affairs; jurisdictional requirements.
- Patent office action response aid (legal, IP)
- Decomposes objections, maps claims to spec, retrieves prior art, creates evidence-linked argument plans before drafting.
- Potential tools/products/workflows: Patent prosecution copilot integrated with patent databases; claim-to-spec mapper.
- Assumptions/dependencies: Patent DB access (USPTO/EPO/paid); attorney oversight; privilege/confidentiality safeguards.
- Customer support escalation and trust/safety replies (software, platforms)
- Creates transparent, evidence-linked plans referencing KB articles/logs, clearly flags items needing investigation without overpromising.
- Potential tools/products/workflows: CRM integrations (Zendesk, Salesforce); KB-aware response generator.
- Assumptions/dependencies: Access to logs/KB; PII handling; human approval for high-risk communications.
- Grant resubmission and panel-response drafting (academia, nonprofit)
- Converts reviewer critiques into coverage-checked plans; drafts responses with citations and concrete revision items.
- Potential tools/products/workflows: Integration with grants management systems; plan-to-revision task export.
- Assumptions/dependencies: Access to proposal materials; PI sign-off; sponsor-specific format compliance.
- Public comment response matrices (government, policy, energy/environmental consulting)
- Breaks public comments into atomic issues, generates evidence-linked responses, builds matrices showing coverage and consistency.
- Potential tools/products/workflows: “ResponseMatrix” builder for EIR/EIS/NEPA processes; document section linker.
- Assumptions/dependencies: Policy/legal review; open-records constraints; integration with document repositories.
- Teaching and writing pedagogy (education)
- Trains students in evidence-backed argumentation using the rubric (relevance, argumentation, communication), with explicit plans and sources.
- Potential tools/products/workflows: LMS plugin; teaching assistant mode with checklists and exemplars; peer-feedback structurer.
- Assumptions/dependencies: Academic integrity policies; disclosure of AI assistance; instructor oversight.
- Standalone components for knowledge work (cross-sector)
- EvidenceBrief generator for literature/KB searches; PDF compressor with fidelity checks for long-doc reasoning; Concern Extractor for emails/threads; Coverage/consistency checkers for any long-form response.
- Potential tools/products/workflows: Browser extensions; Zotero/ReadCube plugin; email/Slack add-ons.
- Assumptions/dependencies: API access to sources; robust OCR/structure extraction; logging for auditability.
- Benchmarking and evaluation (industry R&D, academia)
- RebuttalBench used to measure coverage, evidence support, and communication quality for argument-grounded systems; supports model selection and cost-performance tradeoffs.
- Potential tools/products/workflows: Internal eval suites; LLM-judge pipelines with guardrails.
- Assumptions/dependencies: Alignment with internal tasks; LLM-as-judge bias mitigation; reproducibility controls.
- Cost-efficient agentic writing with mid-tier models (software, enterprise)
- Deploy the multi-agent pipeline with smaller/cheaper LLMs to realize gains in coverage and evidence support without top-tier model costs.
- Potential tools/products/workflows: Hybrid routing (small LLM + tool-use); token budgeting with hybrid contexts.
- Assumptions/dependencies: Tool reliability; latency tradeoffs; careful prompt engineering and monitoring.
Long-Term Applications
- End-to-end regulatory and safety case assistants (healthcare, aviation, energy, robotics)
- Apply verify-then-write pipelines across full safety/efficacy dossiers; automatically propose experiments/analyses as action items and orchestrate follow-up.
- Potential tools/products/workflows: Integrated evidence graphs; ELN/LIMS connections that convert action items into lab protocols.
- Assumptions/dependencies: Deep systems integration; rigorous validation; multi-stakeholder sign-offs; high assurance requirements.
- Real-time meeting-to-action assistants (enterprise, software, operations)
- Capture live feedback in design reviews or audits, decompose concerns, link evidence in situ, and generate tracked action items with commitment safety checks.
- Potential tools/products/workflows: Zoom/Teams apps; bidirectional links to issue trackers and CI/CD.
- Assumptions/dependencies: Accurate speech-to-text; secure access to artifacts; cultural adoption of structured workflows.
- Autonomous research co-pilots (academia, industrial labs)
- Combine literature search, plan generation, and experiment scheduling; maintain transparent, auditable reasoning traces for peer communication and reproducibility.
- Potential tools/products/workflows: “AI Lab Manager” integrating lab hardware, schedulers, and notebooks.
- Assumptions/dependencies: Reliable autonomy for routine experiments; strict provenance tracking; human governance.
- Standardized, machine-readable rebuttal and response artifacts (publishing, government)
- Community norms and platforms adopt structured plans/evidence links as first-class artifacts for transparency and auditability.
- Potential tools/products/workflows: OpenReview schema extensions; agency portals consuming machine-readable response matrices.
- Assumptions/dependencies: Standards adoption; incentives for authors/agencies; interoperability across tools.
- Commitment safety guardrails in enterprise communications (cross-industry)
- System-wide deployment of consistency and commitment safety checkers to prevent overpromising in sales, support, and compliance communications.
- Potential tools/products/workflows: Email/CRM/PR integrations; enterprise policy enforcement rules.
- Assumptions/dependencies: Policy codification; exception handling; change management.
- Auto-execution of action items (software, DevOps, data science)
- From plan to execution: map action items to pipelines (e.g., run new benchmarks/tests), collect results, and update responses automatically.
- Potential tools/products/workflows: Orchestrators that trigger CI jobs, ML experiments, or data audits; closed-loop reporting.
- Assumptions/dependencies: Reliable automation; sandboxing; clear human approval checkpoints.
- Domain-specific legal and IP copilots (legal)
- Deep integration for patent prosecution and litigation workflows: argument templates tied to statutes/case law/claims, systematic prior-art and spec mapping.
- Potential tools/products/workflows: Case-law retrieval with explainable mappings; courtroom-safe audit trails.
- Assumptions/dependencies: Legal acceptance; admissibility standards; continual updates to legal corpora.
- Public policy response platforms (government, NGOs)
- At scale, process mass public comments and watchdog reports with transparent evidence links; track coverage and resolve contradictions across agencies.
- Potential tools/products/workflows: Cross-agency knowledge graphs; public-facing transparency dashboards.
- Assumptions/dependencies: Open data; procurement and security compliance; guardrails for fairness and bias.
- Education: argumentation tutors and grading assistants (education)
- Tutors teach evidence-grounded writing with structured plans; graders use rubric-aligned, explainable assessments.
- Potential tools/products/workflows: Classroom assistants with formative feedback loops; portfolio-level progress analytics.
- Assumptions/dependencies: Policy alignment on AI use; bias management; curricular integration.
- Procurement and RFP response copilots (enterprise, governments)
- Decompose RFP requirements, map to capabilities and evidence, draft verifiable responses and risk-aware commitments.
- Potential tools/products/workflows: Proposal assembly pipelines; repository of evidence briefs and past performance.
- Assumptions/dependencies: Access to internal artifacts; legal review; change control across versions.
- Environmental impact and permitting responses (energy, infrastructure)
- Produce evidence-linked response matrices for permitting/public engagement; coordinate technical appendices and mitigation action plans.
- Potential tools/products/workflows: GIS and modeling tool integrations; regulatory checklists.
- Assumptions/dependencies: High-quality environmental data; stakeholder coordination; long review cycles.
- Safety case construction for robots/autonomous systems (robotics)
- Structurally link requirements, test results, and mitigations; produce audit-ready evidence packages responding to assessor feedback.
- Potential tools/products/workflows: Safety-case knowledge bases; simulation/test harness integrations.
- Assumptions/dependencies: Robust verification data; standards mapping (e.g., ISO, UL); safety culture maturity.
Key cross-cutting assumptions and dependencies for feasibility:
- Document access and quality: robust PDF/OCR parsing and accurate structure extraction are critical; poor scans degrade grounding.
- Tooling access: scholarly/enterprise search APIs and potential paywall/subscription constraints.
- Data governance and privacy: strict controls for sensitive or confidential documents; on-prem or VPC deployment may be required.
- Human-in-the-loop oversight: essential for legal/regulatory contexts and to validate action items before commitments.
- LLM capacity and cost: pipeline benefits are larger with weaker models but depend on reliable tool-use and retrieval; latency/cost tradeoffs apply.
- Evaluation reliability: LLM-as-judge bias must be managed; rubrics may need domain tuning.
- Organizational adoption: process changes to embrace structured plans, placeholders, and explicit evidence links.
Collections
Sign up for free to add this paper to one or more collections.

