- The paper introduces ReviewGrounder, a rubric-guided, multi-agent review system that significantly enhances evidence-based peer critique.
- It employs specialized agents for literature search, insight mining, and result analysis to ground critiques with verifiable evidence.
- Experimental results demonstrate marked improvements in review quality metrics and robustness against adversarial attacks.
Motivation and Challenges in LLM-Based Peer Review
Recent scale-up in AI conference submissions has necessitated scalable and substantive peer review support. While LLM-driven systems have been deployed for review drafting and assessment, existing approaches exhibit salient deficiencies: they frequently yield superficial, formulaic, and insufficiently substantiated critiques. The lack of explicit adherence to reviewer rubrics and insufficient grounding in related literature lead to critical failures—such as unverified novelty claims, insufficient evidence-based criticism, and poor actionable recommendations. Conventional approaches, including both single-pass LLM generation and retrieval-augmented frameworks, are unable to systematically address these shortcomings.
ReviewBench: A Rubric-Driven Benchmark for Review Quality
The authors propose ReviewBench, addressing the gap in evaluation methodologies for LLM-based peer review. ReviewBench instantiates paper-specific rubrics by synthesizing official peer review meta-rubrics with the target paper's content and aggregated human review summaries.
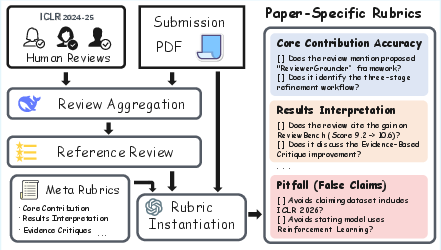
Figure 1: Overview of the ReviewBench construction pipeline: paper-specific rubrics are instantiated using aggregated reference reviews, original submissions, and meta-rubrics.
ReviewBench employs eight evaluation dimensions, closely aligned with practices at top machine learning venues:
- Core Contribution Accuracy
- Results Interpretation
- Comparative Analysis
- Evidence-Based Critique
- Critique Clarity
- Completeness Coverage
- Constructive Tone
- False or Contradictory Claims (pitfall)
Evaluation is performed by an LLM-based evaluator, assigning an 8-dimensional score vector per review, enabling fine-grained and instance-specific assessment of review quality.
ReviewGrounder is a staged, rubric-guided, multi-agent system for review generation, addressing identified deficiencies in both review substance and evidence integration.
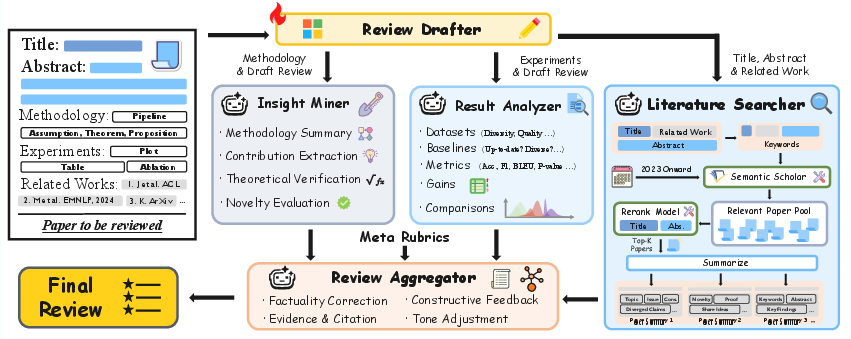
Figure 2: Overview of the ReviewGrounder system: review drafting is separated from grounding by multi-agent collaboration—literature search, insight mining, result analysis, and final aggregation.
Stage I: A supervised fine-tuned LLM (Phi-4-14B) generates a structural review draft, capturing only shallow patterning.
Stage II: Three specialized agent modules operate in parallel:
- Literature Searcher: Retrieves and summarizes recent related work by querying scientific paper APIs and reranking with domain-specific models.
- Insight Miner: Extracts and verifies the technical/methodological core, connecting assertions to concrete evidence in the paper.
- Result Analyzer: Scrutinizes experimental sections, extracting datasets, baselines, and quantitative results, and correcting spurious or unsupported claims.
Stage III: The Aggregator module synthesizes the draft and all collected evidence—anchoring every critique, claim, and suggestion in specific, verifiable sources.
This modularity ensures that final reviews are not only structured according to explicit reviewer guidelines, but also grounded in both the submission and the broader literature context—without access to evaluation rubrics at generation time, thus preventing leakage.
Experimental Results and Ablation Analyses
Rubric-Based and Numeric-Field Evaluation
On ReviewBench, ReviewGrounder demonstrates numerically strong performance across all eight review dimensions. Using a relatively modest backbone compared to baselines (Phi-4-14B / GPT-OSS-120B versus GPT-4.1, DeepSeek-R1-670B), the system achieves superior overall rubric scores (+38% over Qwen3-32B, +36% over DeepReviewer-14B, and +135% over GPT-4o). Particularly, in dimensions requiring evidence-based critique and comparative analysis, ReviewGrounder produces strong, consistently high scores.
Ablation experiments confirm that every agent module contributes materially to the system's effectiveness (Figure 3):
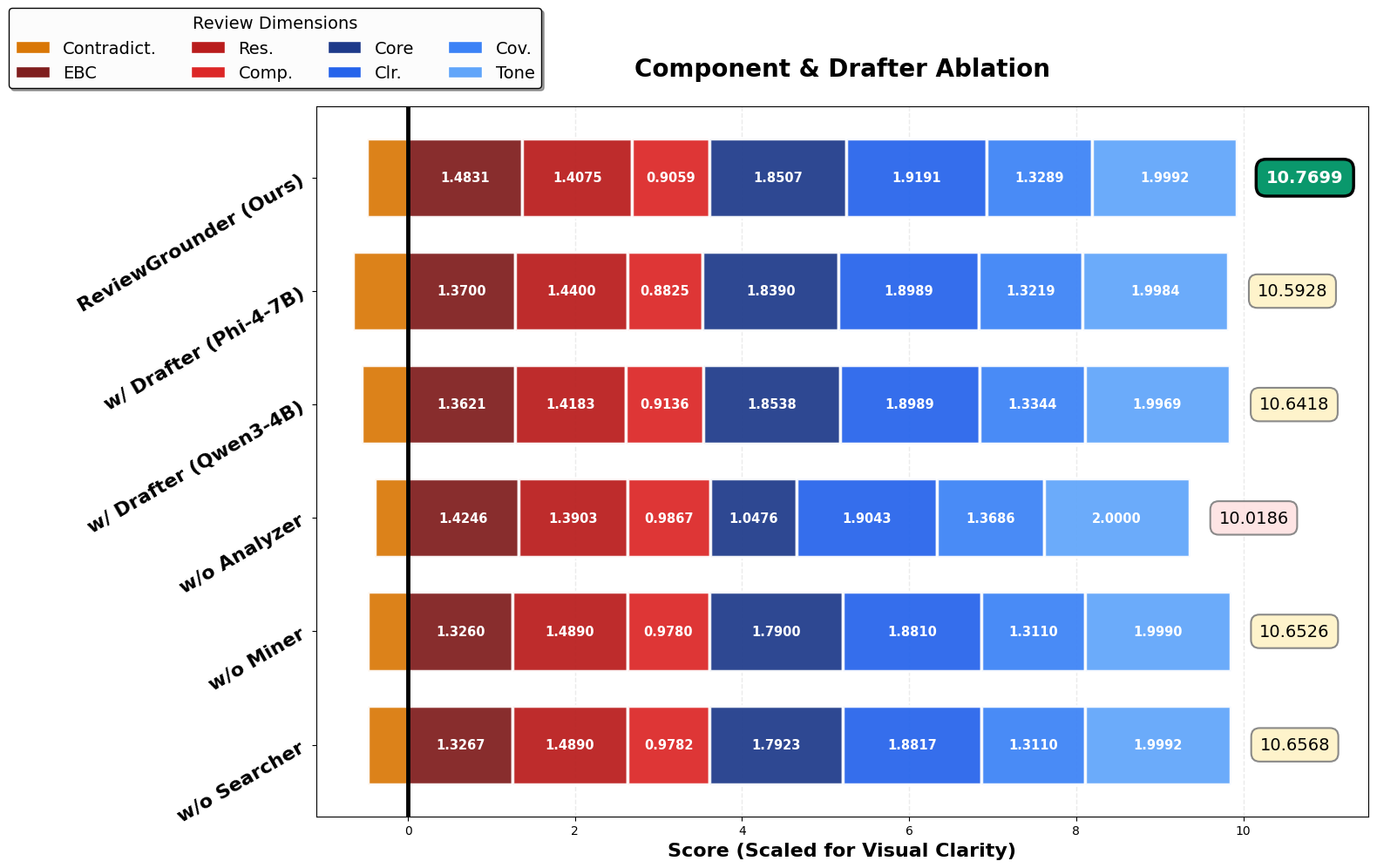
Figure 3: Fine-grained score breakdown shows ablation of each system component (Result Analyzer, Insight Miner, Literature Searcher) leads to significant degradation.
Literature Search Optimization
Hyperparameter studies show that performance is sensitive to literature retrieval quality. Employing a domain-specific reranker (OpenScholar) and optimal candidate set size (N=10) outperforms baseline retrievers, particularly in evidence integration and comparative context.
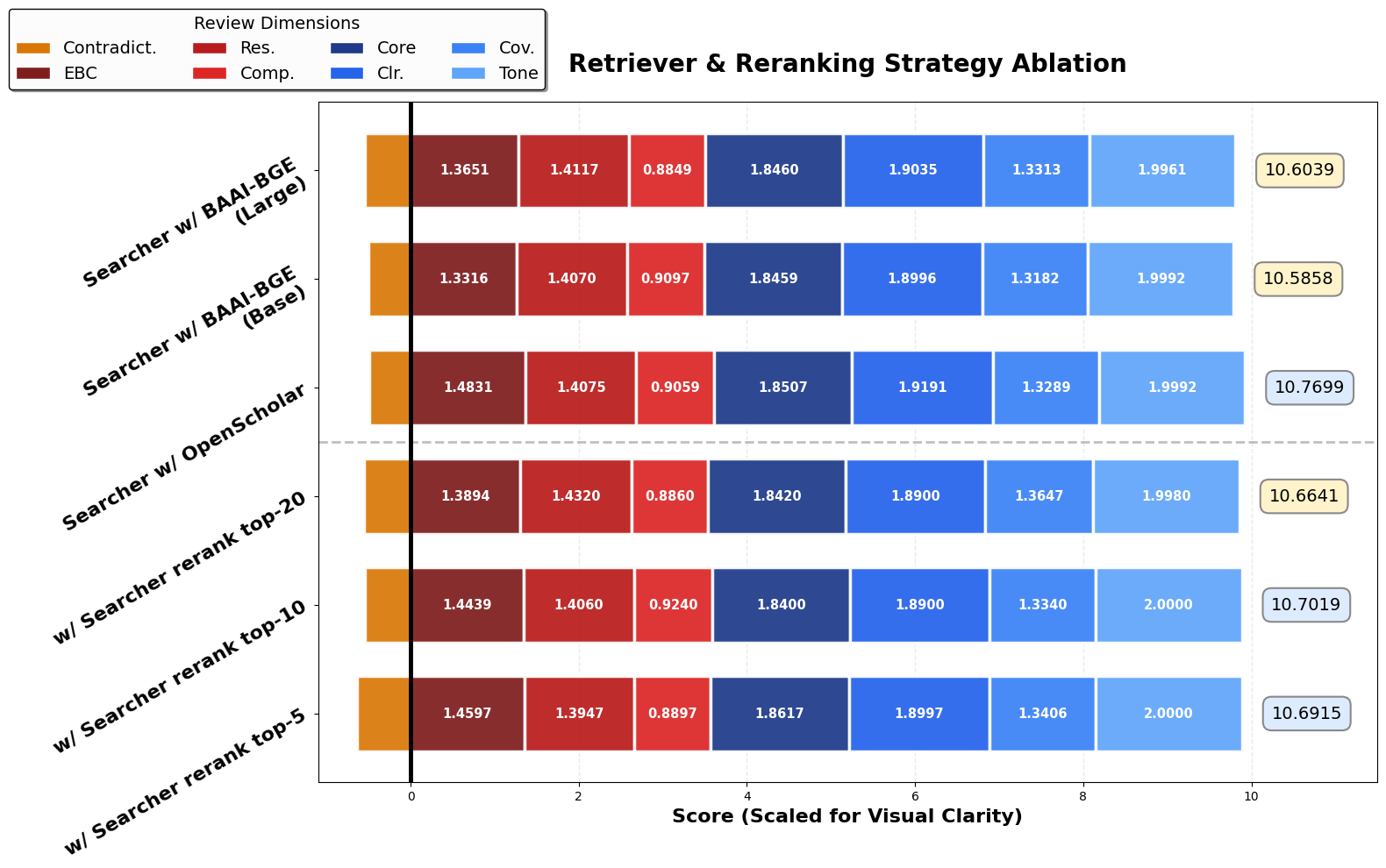
Figure 4: Performance across retrieval/reranking strategies and candidate set sizes for the Literature Searcher.
Robustness to Adversarial Attacks
Under adversarial attack—where malicious instructions are injected into papers—ReviewGrounder demonstrates minimal degradation (~0.05 drop compared to 0.4+ for strong baselines), highlighting its robustness against semantic corruption attacks.
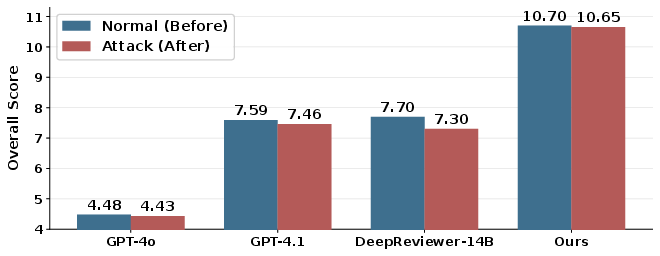
Figure 5: Comparison with baselines under both normal and attack scenarios; ReviewGrounder maintains high rubric-based review quality.
Human Expert Alignment
Human studies involving domain experts reveal strong alignment between rubric-based automated scores and expert ratings (Pearson r=0.8954), validating the practical effectiveness of the paper-specific rubric design and evaluation protocol.
Implications for AI-Assisted Scientific Evaluation
ReviewGrounder's results indicate that rubric-guided, multi-agent, tool-assisted LLM review is both necessary and effective for substantive, evidence-aligned peer review at scale. The modular architecture enables integration of domain retrieval, document-level grounding, and critical evaluation in ways single-LLM or naive retrieval-augmented schemes cannot.
Practical implications include:
- Reliable LLM augmentation for human reviewers, improving breadth and rigor without replacing expert judgment.
- Defenses against score inflation or adversarial attacks amid mass-submission settings.
- Generalizability to other scientific domains and venues, as shown by robust cross-domain experiments.
Theoretical implications point to explicit rubric- and tool-structured decomposition as a necessary evolution in agentic LLM protocols for complex, ill-defined evaluative tasks.
Future Directions
Unaddressed challenges remain, including end-to-end, in-the-flow training for agent coordination, integration of meta-reviewer modules for iterative, multistage feedback, and extension to broader venue and dataset coverage. Robustness to more diverse adversarial attacks and the prevention of subtle reviewer biases in rubric instantiation merit further investigation.
Conclusion
ReviewGrounder establishes a rigorous, reproducible, and modular approach to LLM-assisted peer review. It demonstrates that only through explicit rubric-driven, tool-integrated, and multi-agent review architectures can current LLMs achieve substantive, evidence-grounded critique and actionable recommendations—a requirement for credible AI-augmented scientific evaluation in the age of conference-scale publication.