- The paper introduces a multi-stage system that extracts structured claims, positions them within relevant literature, and verifies them through empirical code execution.
- It employs evidence-aware labels such as Supported and Partially supported to transparently reflect claim validity and reliability.
- Execution benchmarks across different LLM backends highlight that system reliability is deeply dependent on the robustness and quality of the underlying LLM.
FactReview: Evidence-Grounded Peer Review with Literature Positioning and Execution-Based Claim Verification
Introduction
The increasing scale and complexity of ML research have stressed the traditional peer review paradigm, driving attention to AI-based review automation. However, existing LLM-based reviewing systems largely confine their assessments to paper narratives, forgoing external verification via the literature or released code. This paper introduces FactReview, an automated reviewer that augments conventional LLM-based review with structured claim extraction, literature positioning, and rigorous, budget-constrained execution-based claim verification. Unlike prior systems, FactReview delineates the evidentiary status of each major claim through explicit labels and connective evidence reports, encouraging greater transparency and reliability in ML paper reviewing (2604.04074).
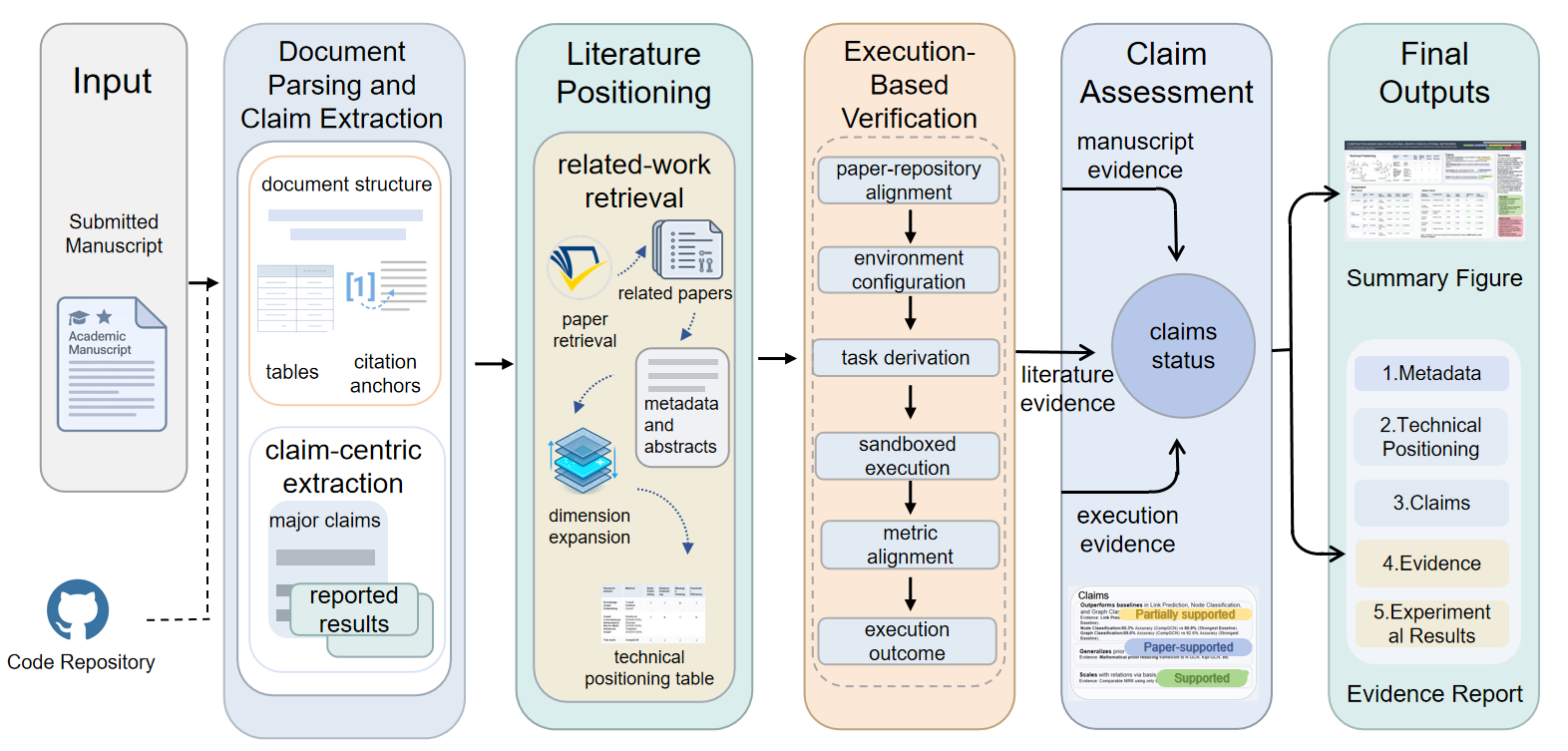
Figure 1: FactReview system overview illustrating stages: parsing submission, claim extraction, literature positioning, code execution for empirical claim verification, and production of claim-linked review and evidence report.
Methodology
FactReview implements a multi-stage review workflow targeting end-to-end evidence tracing for ML submissions. The process comprises:
Structured Document Ingestion and Claim Extraction
Submissions are parsed to preserve structural metadata (sections, tables, equations, figure references). This preserves context critical for downstream claim localization and evidence tracking. Claims are schema-extracted, decomposed into verifiable granular units, and classified by type (empirical, methodological, theoretical, reproducibility). Each claim is tagged with evidence targets, locations, and scope, enabling subsequent, fine-grained verification.
Literature Positioning
FactReview constructs a local neighborhood of relevant literature via cited methods, named baselines, and semantic similarity search. Instead of providing generic novelty scores, it maps the submission's innovations and mechanisms relative to adjacent lines of work, facilitating a precise technical position. This local mapping supports more granular assessments of methodological contribution and empirical performance.
Execution-Based Empirical Verification
When available, released code is sandboxed and executed under strict resource budgets. The workflow explicitly resolves artifacts, reconstructs environments, and orchestrates task execution based on structured cues (README, configuration, repository introspection). Bounded repair covers only minimal, non-invasive code modifications (e.g., dependency fixes, argument correction), eschewing deep changes to model logic or evaluation. Empirical outputs are systematically aligned with extracted claims; misalignment results in Inconclusive judgments rather than unwarranted verdicts.
Claim Labeling and Review Synthesis
Major claims receive one of five evidentiary labels:
- Supported: External evidence from execution or literature.
- Supported by the paper: Plausible but only manuscript-internal evidence.
- Partially supported: Claim decomposition yields partial empirical verification.
- In conflict: External evidence contradicts the claim.
- Inconclusive: Insufficient available evidence.
Review generation is tightly organized around claims and their accompanying evidence, with linked references to manuscript sections, literature, and execution artifacts.
Comparative Analysis with Text-Only LLM Review
A core demonstration involves evidence-grounded review of CompGCN, a multi-relational graph convolutional network paper. FactReview:
- Extracts and decomposes high-impact claims (e.g., empirical superiority across tasks, theoretical generality, and scalability).
- Positions CompGCN between knowledge graph embedding and graph convolutional lines, clarifying the explicit architectural contribution.
Execution-based verification yields:
- High alignment between reproduced and reported results for link prediction and node classification (MRRreproduced=0.352, MRRpaper=0.355; node classification: 84.9% reproduced, 85.3% reported).
- For MUTAG graph classification, the paper’s broad claim is downgraded: 88.4% reproduced versus 89.0% reported, and a baseline remains stronger (92.6%). The claim’s label is thus Partially supported—providing a granular, claim-level distinction that text-only LLM review systems overlook.
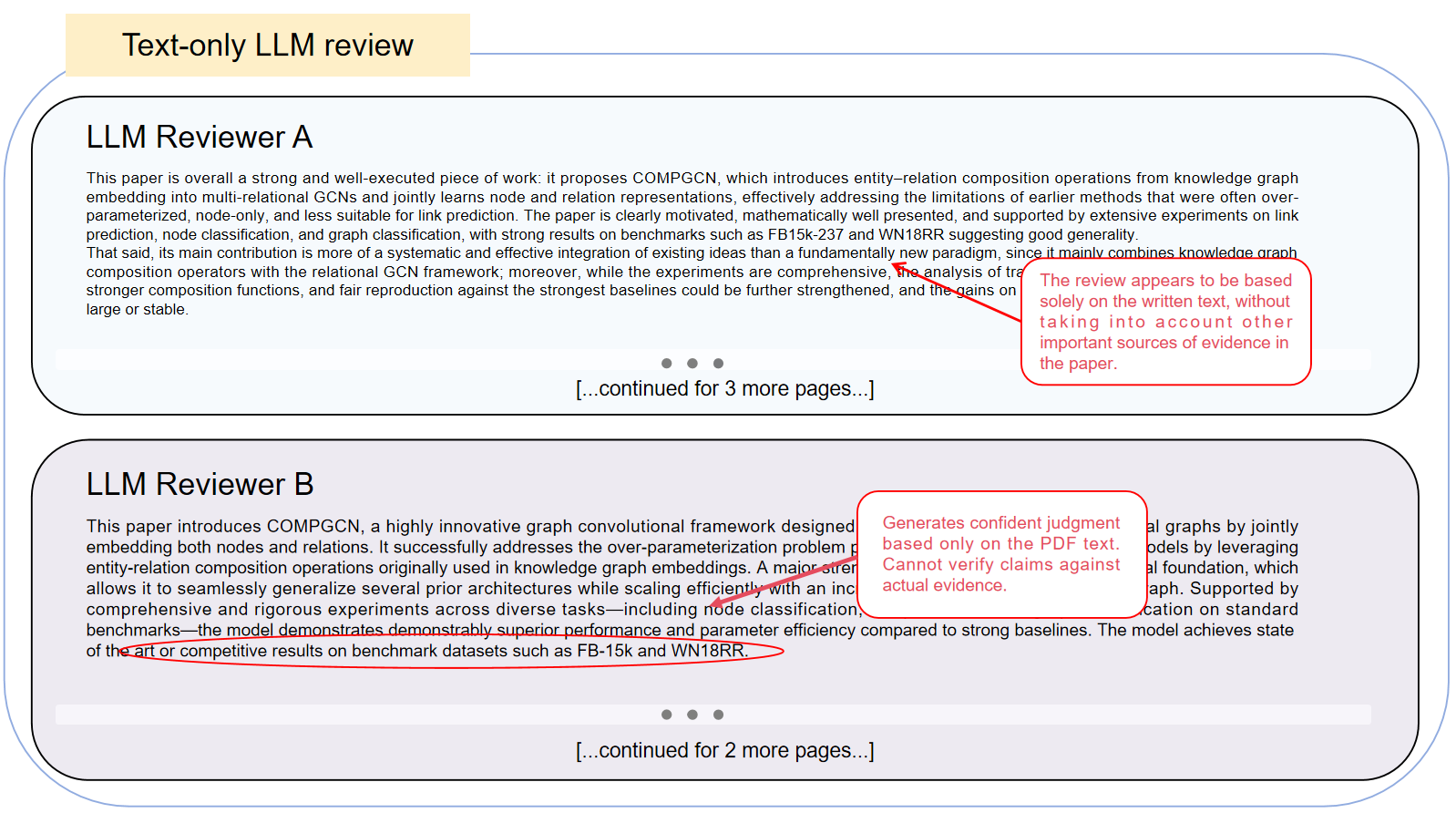
Figure 2: Text-only LLM review on CompGCN accepting the broad empirical claim of the paper without explicit substantiation from external evidence.
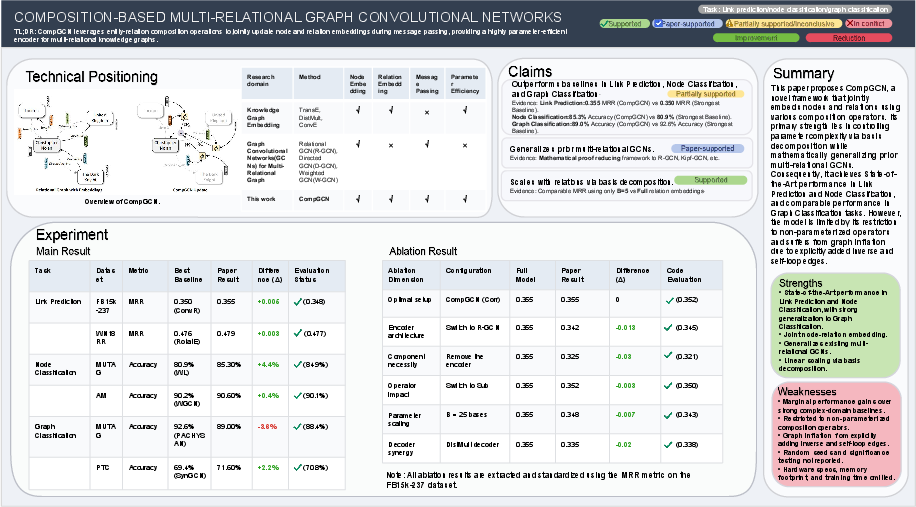
Figure 3: FactReview’s structured output for CompGCN, decomposing claims, integrating literature, and marking the graph classification claim as "Partially supported" based on replicated execution.
This division highlights FactReview’s evidentiary discipline; text-only LLM reviews collapse extraction and validation into undifferentiated generation, inheriting biases and overacceptance from author framing.
Backend Sensitivity in Execution-Based Verification
FactReview’s execution-based assessment module was benchmarked across six LLM backends (Claude Opus 4.6, Sonnet 4.5, Haiku 4.5; GPT-5.4, 4.1, 4o), with identical orchestration and sandboxing. Success rates correlate strongly with model family and scale: Claude Opus 4.6 (83.3%) and GPT-5.4 (75.0%) outperform their smaller or older counterparts (Haiku 4.5 at 41.7%, GPT-4o at 50.0%). The most challenging claims to verify involve complex empirical tasks (graph classification, parameter analysis) rather than standard benchmarks.
This underscores that claim-aligned execution-based review is a compositional task, dependent not only on prompt capability but on robust interpretation and output alignment—capacity currently non-uniform across LLMs.
Failure Analysis
Of 72 total evaluation episodes, failures were dominated by execution-level breakdowns (51.9%), followed by artifact-level (29.6%) and interpretation-level (18.5%). Typical issues:
- Artifact-level: Missing or ambiguous entry points (e.g., incomplete repository setups).
- Execution-level: Dependency drift, data or resource unavailability.
- Interpretation-level: Inability to map outputs to manuscript claims or tables.
This breakdown enables FactReview to express structured uncertainty. Rather than conflating all failed verification with negative evidence, the system distinguishes lack of evidence from genuine empirical conflicts, supporting scientifically conservative review.
Practical and Theoretical Implications
By decoupling claim extraction, technical positioning, and empirical verification, FactReview operationalizes the notion of claim-based review—a refinement over existing LLM-based systems that rely heavily on manuscript narrative. Its evidence-aware labels support downstream human reviewers in efficient, transparent, and falsifiable claim assessment.
From a system design perspective, FactReview parallels recent trends in retrieval-augmented generation and tool-augmented agents but differs in its end-to-end evidence linkage and its conservative adjudication of claim support. The necessity for high-caliber LLMs in repository-grounded claim verification is a significant finding, highlighting persistent gaps in automation for claim alignment and empirical validation.
Practically, FactReview could be integrated into reviewer workflows for initial screening, reproducibility certification, or as an evidence dashboard, reducing reviewer workload and increasing reliability without replacing final human decision-making.
Conclusion
FactReview represents a demonstrable augmentation to AI-driven reviewing systems, integrating structured claim analysis, literature positioning, and bounded empirical validation. Strong evidence shows it can disaggregate and re-label broad empirical claims, provide transparent evidence linkage, and clarify the scope and limits of manuscript assertions. Sensitivity to backend model competence reveals bounds on current automation, with system reliability gating on LLM output quality.
Future research directions include iterative improvement of repository recovery, extension to theoretical and data-driven papers, and real-world deployment with reviewer-in-the-loop evaluations to benchmark impact on reviewer decision quality and time-to-review.