PaperDebugger: A Plugin-Based Multi-Agent System for In-Editor Academic Writing, Review, and Editing
Abstract: LLMs are increasingly embedded into academic writing workflows, yet existing assistants remain external to the editor, preventing deep interaction with document state, structure, and revision history. This separation makes it impossible to support agentic, context-aware operations directly within LaTeX editors such as Overleaf. We present PaperDebugger, an in-editor, multi-agent, and plugin-based academic writing assistant that brings LLM-driven reasoning directly into the writing environment. Enabling such in-editor interaction is technically non-trivial: it requires reliable bidirectional synchronization with the editor, fine-grained version control and patching, secure state management, multi-agent scheduling, and extensible communication with external tools. PaperDebugger addresses these challenges through a Chrome-approved extension, a Kubernetes-native orchestration layer, and a Model Context Protocol (MCP) toolchain that integrates literature search, reference lookup, document scoring, and revision pipelines. Our demo showcases a fully integrated workflow, including localized edits, structured reviews, parallel agent execution, and diff-based updates, encapsulated within a minimal-intrusion user interface (UI). Early aggregated analytics demonstrate active user engagement and validate the practicality of an editor-native, agentic writing assistant. More details about this demo and video could be found at https://github.com/PaperDebugger/PaperDebugger.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces PaperDebugger, a smart writing helper that lives inside Overleaf (a popular online editor for scientific papers). Instead of copying text into a separate AI app, PaperDebugger lets you get AI feedback, rewrite sentences, find related research, and apply changes—all directly in your document, with “track-changes”-style previews.
What questions did the researchers ask?
The authors set out to solve a few simple problems:
- How can we bring AI help directly into the writing editor so people don’t have to copy and paste between apps?
- How can we make AI feedback clear, trustworthy, and easy to apply (like showing before/after changes)?
- Can multiple AI “roles” (like a reviewer, editor, and researcher) work together behind the scenes to improve writing?
- Can this system scale to many users and stay fast and reliable?
- Will real users actually use and like this kind of in-editor assistant?
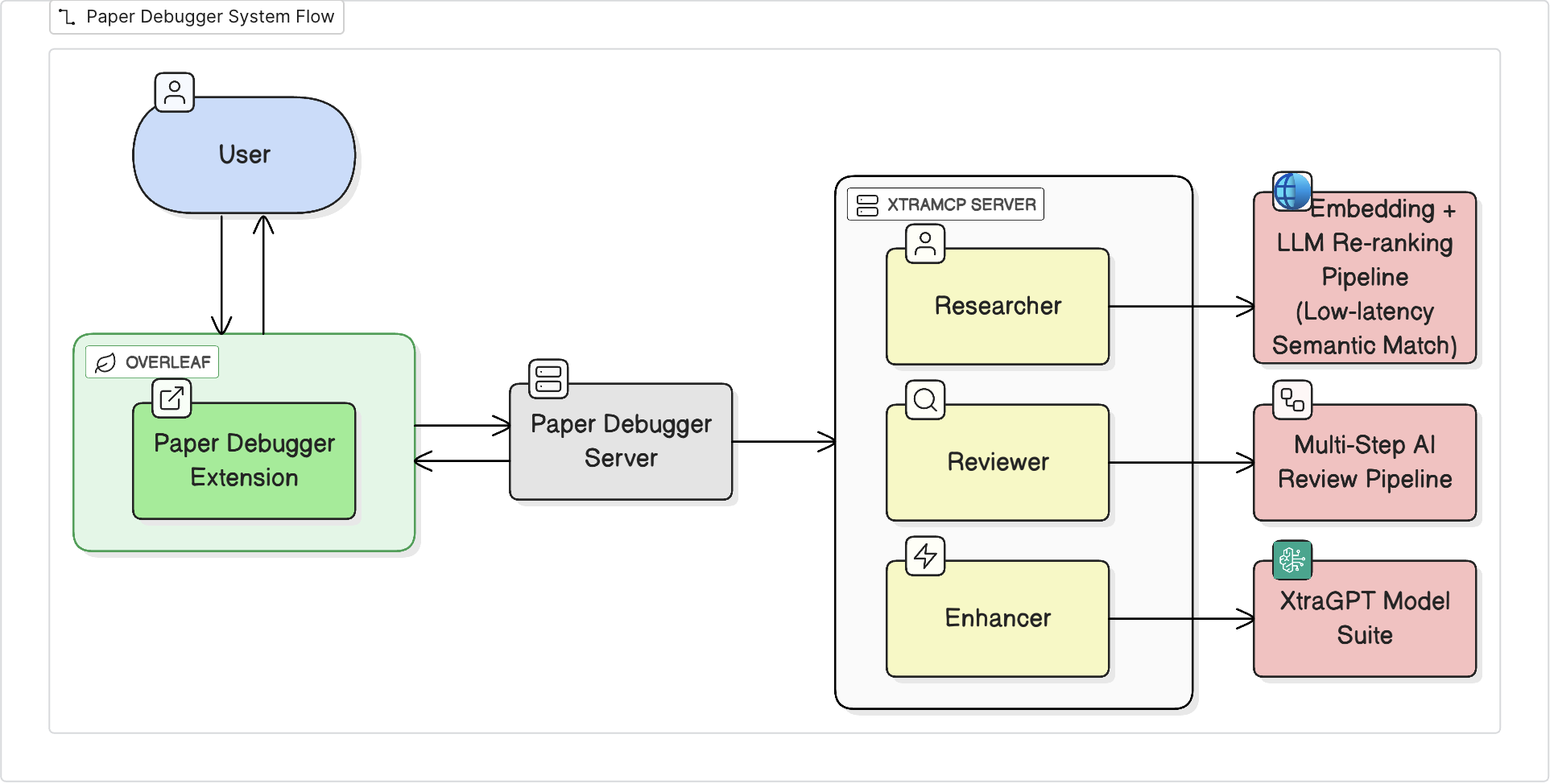
How does PaperDebugger work?
Think of PaperDebugger like a team of AI assistants that sit inside your writing app and coordinate through a control room.
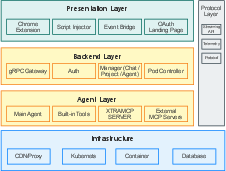
Key parts of the system
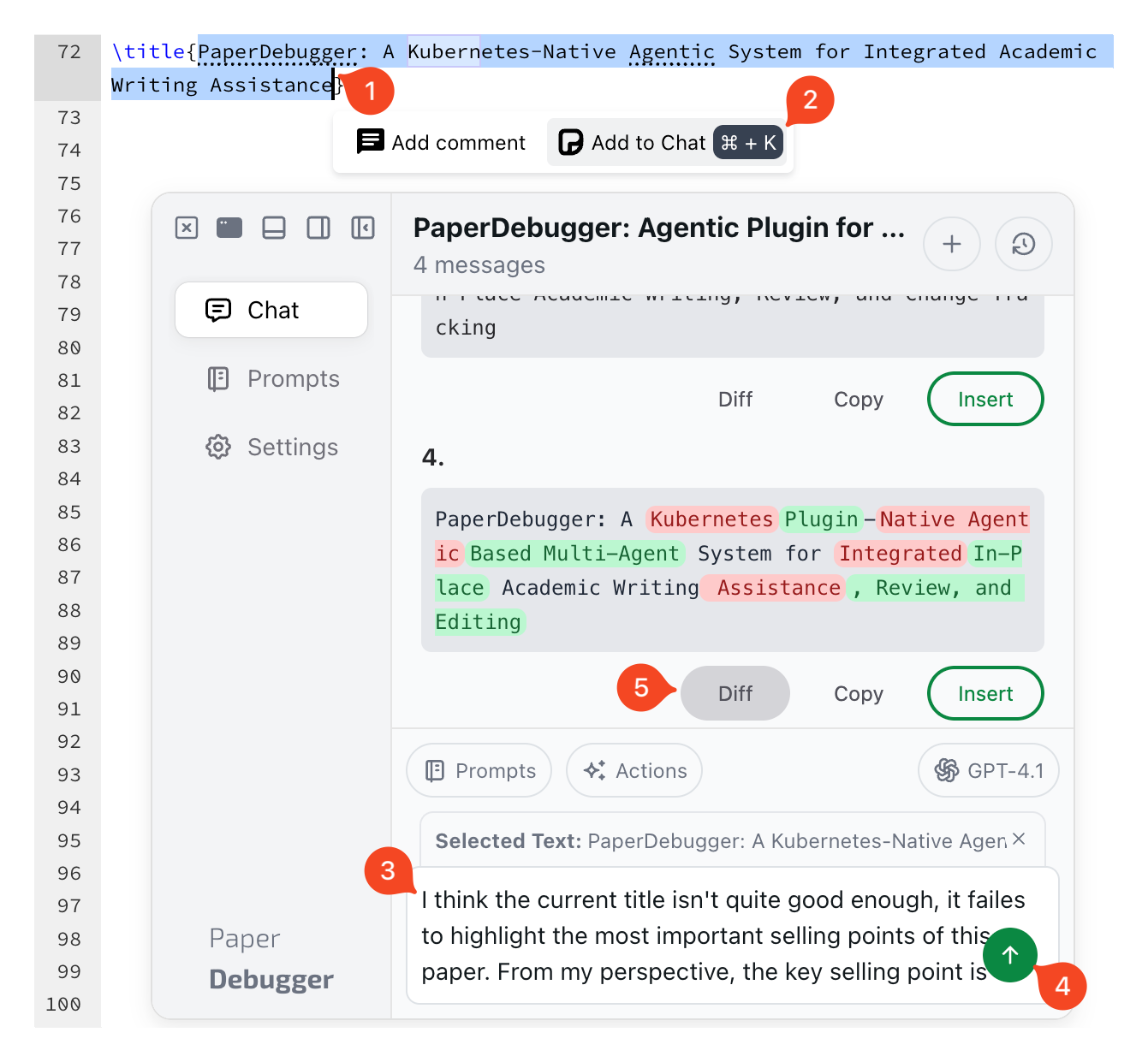
- Presentation layer (the “in-editor” part): A Chrome extension adds buttons and a small panel inside Overleaf. You can select text, ask for a critique or rewrite, preview suggested changes as diffs (before vs. after), and apply them with one click.
- Backend (the “control room”): A server (built in Go) handles your requests, keeps track of sessions, and streams results back in real time—like watching the AI “type” its suggestions.
- Agent layer (the “AI team”): Different AI agents have different jobs:
- Reviewer agent: gives structured feedback.
- Enhancer agent: rewrites and polishes text.
- Scoring agent: checks clarity and coherence.
- Researcher agent: searches for related papers and references.
- Protocol layer (the “common language”): A simple communication standard streams updates to the browser so you see progress as it happens.
- Infrastructure (the “factory floor”): Kubernetes (a system for running lots of little programs at once) launches many small workers (called pods) so multiple tasks can run in parallel and scale to many users.
Helpful tools and terms explained with everyday language
- LLMs: Very advanced autocomplete—AI that predicts and composes useful text.
- Multi-agent system: Instead of one AI doing everything, several specialized AIs (agents) each do a focused job and pass results to each other.
- Diff-based edits: Like “track changes” in word processors—showing what was changed and why.
- MCP (Model Context Protocol): Like a universal plug that lets the AI talk to tools (e.g., literature search) in a consistent, safe way.
- Kubernetes: A smart manager that runs lots of small helper programs so the system stays fast and doesn’t crash when many people use it.
- Streaming responses (gRPC/SSE): Like watching a live chat—results arrive bit by bit instead of all at once.
The system supports quick, single-shot tasks (e.g., grammar polish) and bigger workflows (e.g., deep research and section rewrites) that chain multiple steps together.
What did they find?
The team deployed PaperDebugger through the Chrome Web Store and studied how people used it over several months (with anonymized data). Key signs of real-world use:
- Installation and engagement: 112 installs, 78 sign-ups, and 23 monthly active users—showing steady use across time.
- Projects and activity: 158 projects and 797 writing threads—people used it for real writing, not just quick tests.
- What people used most: Users most often viewed diffs (over 1,000 times), copied suggestions, and applied patches in-editor.
- User feedback: High ratings (4.9/5) and comments like “convenient” and “seamless.” Some users noted limitations, like suggestions sometimes sounding too “computer-science-like” or slower performance on very long documents.
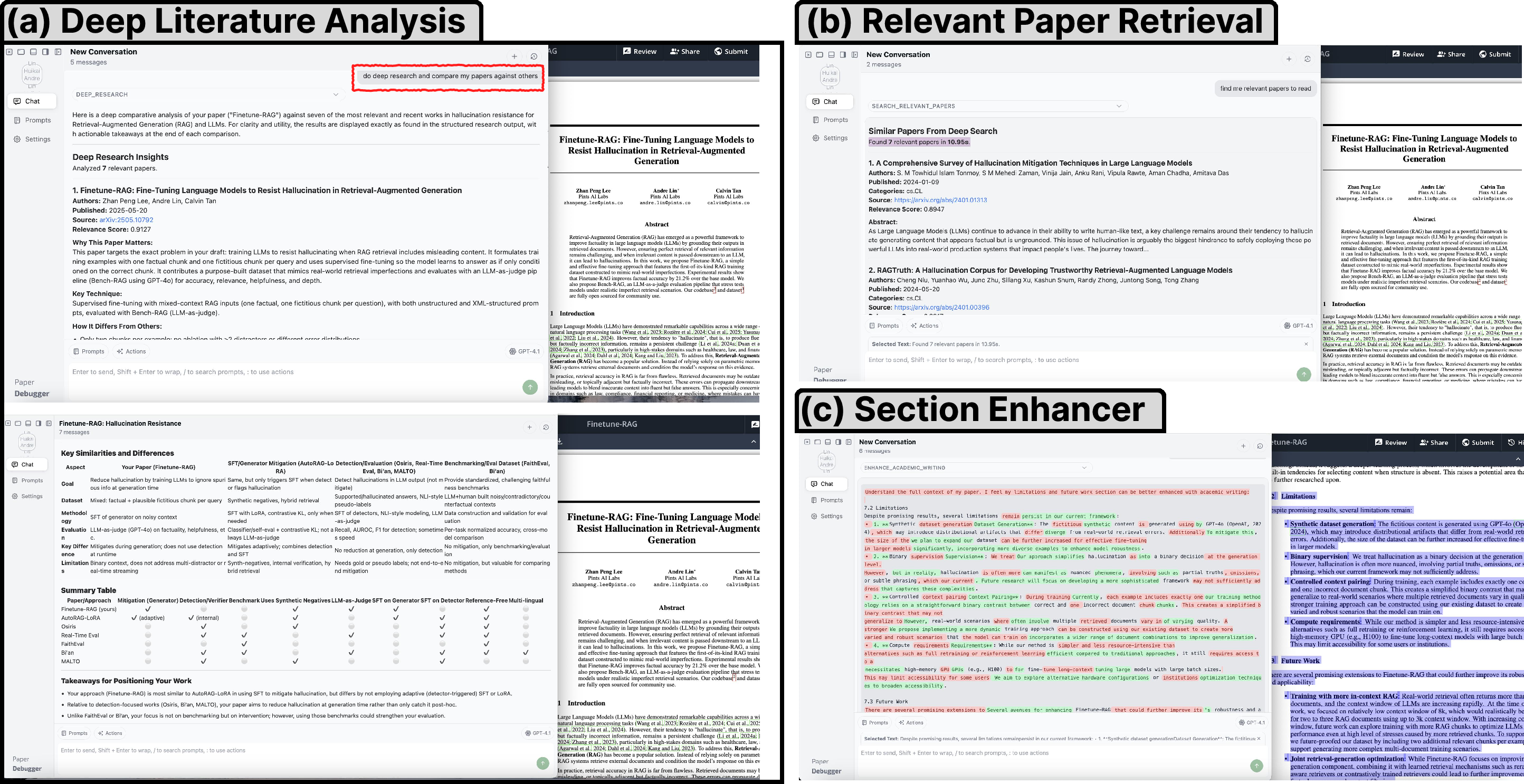
The paper also demonstrates two in-editor workflows:
- In-editor editing: Select a sentence/paragraph, get structured critique and rewrite options, and apply changes with justification shown.
- Deep research: Search related papers, get relevance explanations, compare your work with others side-by-side, and insert citation-ready summaries—without leaving Overleaf.
Why does this matter?
Putting AI directly inside the writing editor saves time, keeps your focus, and keeps a clear history of what changed and why. Instead of juggling different apps, writers can:
- Improve clarity and tone with transparent, controlled edits.
- Get reviewer-style feedback while they write.
- Find and compare related research without leaving the document.
- Work faster while keeping academic style and structure intact.
In short, PaperDebugger shows that an “editor-native” AI assistant—built from multiple cooperating agents and connected to research tools—can make academic writing smoother, clearer, and more reliable. As these systems evolve, they could help students, researchers, and professionals write better papers, faster, while keeping control over every change.
Knowledge Gaps
Below is a focused list of the paper’s unresolved knowledge gaps, limitations, and open questions that future researchers could address:
- Lack of controlled user studies quantifying impact on writing outcomes (e.g., time-to-revise, quality gains judged by expert raters, acceptance rates of submissions).
- No A/B comparisons against baseline tools (e.g., Overleaf Copilot, Writefull, external LLM assistants) to substantiate claims of in-editor advantages.
- Absence of formal evaluation of agent outputs (e.g., patch correctness, grammar/style improvements, coherence scores, hallucination rates) with reproducible metrics.
- Retrieval and citation quality in the MCP/XtraMCP pipeline is unvalidated (precision/recall, coverage across disciplines, rate of incorrect or fabricated citations, DOI accuracy).
- Domain bias noted (“CS-like” tone) but no method or evaluation for robust domain adaptation (e.g., style calibration for humanities, biomedical, social sciences; multilingual support).
- Scalability and performance on long documents are reported as problematic; no measured tail latencies, throughput, memory footprint, or degradation curves under realistic workloads.
- No analysis of reliability and failure modes in patching (e.g., misapplied diffs, merge conflicts, concurrency issues with multi-author edits, introduced LaTeX compilation errors).
- Determinism claims for diff-based editing are not backed by technical guarantees (e.g., temperature control, seeding, version locking) or empirical reproducibility tests across runs.
- Limited details on LaTeX structure-awareness (e.g., handling macros, environments, math mode, custom commands, cross-file edits in multi-file projects, .bib manipulation) and robustness across edge cases.
- Missing evaluation of the AI Reviewer/Scoring pipeline’s validity and calibration relative to human reviewers (e.g., inter-rater reliability, rubric alignment, bias analysis).
- No human factors assessment of UI/UX (cognitive load, discoverability, diff comprehension, acceptance rates of suggestions, accessibility for screen readers and color vision deficiencies).
- Security and privacy are asserted but not specified (data flows, encryption, storage retention, Overleaf project access scopes, GDPR/IRB compliance, opt-in telemetry details, institutional policies).
- Kubernetes orchestration claims lack operational metrics (autoscaling behavior, queueing delays, pod scheduling fairness, resource utilization, fault tolerance).
- Absent cost analysis (per-user/server costs, model inference expenses, cost–latency trade-offs, sustainability/carbon footprint) under typical academic usage.
- Unclear handling of multi-author real-time collaboration on Overleaf (conflict resolution, locking, provenance tracking, attribution of agent-applied changes).
- No framework for ethical guardrails (plagiarism detection, ghostwriting boundaries, transparency of AI contributions, citation integrity checks) beyond a brief usage statement.
- Generalization beyond Overleaf/Chrome is not explored (Firefox/Safari support, other LaTeX or Markdown editors, desktop clients, air-gapped or enterprise environments).
- No longitudinal outcomes (retention, habit formation, changes in writing practices, effects on novice vs. expert authors, cross-discipline adoption patterns).
- Lack of robustness testing for tool failures (LLM timeouts, rate limits, retrieval outages) and user-facing recovery strategies.
- Limited transparency about XtraGPT (training data, tuning objectives, evaluation benchmarks, licensing, update cadence) and its implications for reproducibility and bias.
- Unspecified plugin/API governance (third-party tool onboarding, sandboxing, permissioning, security reviews, versioning and deprecation policies).
- Streaming protocol reliability is not assessed (SSE behavior under poor networks, backpressure, reconnection strategies, cross-browser compatibility).
- No study of how persistent interaction history affects collaboration, accountability, and revision provenance (e.g., auditability for peer review or compliance).
- Missing benchmarks for deep research workflows (speed-to-insight, correctness of extracted “compare my work” dimensions, user trust in synthesis outputs).
- Telemetry analysis is preliminary and small-scale; sampling bias, representativeness, and statistical rigor are not discussed.
- Open question on integration with Overleaf’s native version control and Git sync (commit semantics for agent patches, diffs across branches, rollback strategies).
- No evaluation of cognitive impact of multi-agent parallel outputs (overload, inconsistency between agents, aggregation quality, user confidence).
- Unclear internationalization and multilingual capabilities (non-English manuscripts, locale-specific scholarly styles, mixed-language documents).
- Absence of mechanisms to prevent or detect LaTeX-breaking edits before application (preflight validation, compile checks, automated rollback on errors).
- No clear pathway for discipline-specific “style packs” or controllable rhetorical strategies aligned with journal/conference guidelines.
Practical Applications
Immediate Applications
The following applications are deployable now, leveraging PaperDebugger’s in-editor, multi-agent architecture, Kubernetes orchestration, MCP toolchain, and diff-based patching as described in the paper.
- In-editor AI-assisted academic writing on Overleaf (education, publishing, software)
- Use cases: inline critique, grammar polishing, clarity rewrites, and deterministic diff-based patch application without copy–paste.
- Tools/workflows: Reviewer agent, Enhancer agent, Scoring agent; “patch-verified editing” with before–after diffs.
- Assumptions/dependencies: Chrome-based browsers, Overleaf DOM stability, LLM API access, Kubernetes backend availability, network connectivity, institutional AI-use policies permitting.
- Pre-submission self-review and quality gating (academia, publishers)
- Use cases: structured critique against conference-style rubrics, clarity/coherence scoring, section-by-section review prior to submission.
- Tools/workflows: Multi-step AI review pipeline; Scoring dashboards for clarity, coherence, and structure; “Reviewer agent” simulating peer feedback.
- Assumptions/dependencies: Validity of domain-tuned models (XtraGPT), acceptance of AI-aided pre-review by institutions, proper telemetry anonymization.
- Literature retrieval and comparison within the editor (research, education)
- Use cases: related-work synthesis, side-by-side comparisons of methods/datasets, citation-ready summary tables, insertion of references.
- Tools/workflows: XtraMCP retrieval pipeline (embedding + re-ranking), “Compare My Work,” citation-ready tables, curated corpora access.
- Assumptions/dependencies: Access to arXiv/curated corpora and reliable metadata, robust re-ranking quality, avoidance of hallucinations via schemas and validation.
- Thesis, dissertation, and course assignment support with audit-friendly revisions (education)
- Use cases: students iterating with patch diffs, instructors reviewing transparent AI-assisted changes, writing labs improving ESL and clarity.
- Tools/workflows: In-editor diff history, persistent interaction threads, “teaching mode” for guided refinements.
- Assumptions/dependencies: Institutional policies on AI writing assistance, need for auditable provenance, consent for anonymized telemetry in educational settings.
- Collaborative lab and multi-author Overleaf workflows (research, software)
- Use cases: teams reviewing patches, agreeing on revisions with minimal intrusion, maintaining revision provenance for transparency.
- Tools/workflows: “Team patch ledger,” session threads per section, gRPC streaming of intermediate outputs to reduce context-switching.
- Assumptions/dependencies: Multi-user Overleaf projects, consistent patch application without conflicts, stable backend scaling.
- Grant proposal drafting and prior-art positioning (academia, funding, public sector)
- Use cases: rapid synthesis of related work, gap analysis, alignment with calls for proposals, improved narrative clarity.
- Tools/workflows: MCP retrieval + structured comparison outputs; Enhancer agent for tone and structure appropriate to funding documents.
- Assumptions/dependencies: Coverage of domain literature relevant to the grant area, institutional acceptance of AI-assisted drafting with disclosure.
- Enterprise whitepaper and technical report preparation (industry: software, energy, healthcare)
- Use cases: internal reports with in-editor AI revisions, provenance-tracked edits for compliance, baseline technical literature reviews.
- Tools/workflows: PaperDebugger SaaS workspace, SSO integration, role-based permissions, patch-based acceptance gates.
- Assumptions/dependencies: Data privacy policies, secure state management, internal toolchain integration; potential need for on-prem orchestration.
- ESL and accessibility enhancements for scholarly writing (education, research)
- Use cases: tone adaptation to scholarly style, fluency improvements, controlled terminology suggestions.
- Tools/workflows: XtraGPT style tuning, schema-checked suggestions to curb hallucinations.
- Assumptions/dependencies: Quality of domain-style tuning, user control over scope of edits, cross-language considerations.
- Author-side compliance checks before submission (publishers, academia)
- Use cases: formatting conformance to templates, required sections presence, reference integrity checks performed by authors in-editor.
- Tools/workflows: Workflow-based agents with schema validation, checklists mapped to specific venue requirements.
- Assumptions/dependencies: Mapping of venue rules into agent schemas, evolving template support per journal/conference.
Long-Term Applications
These applications build on the paper’s methods and architecture but require further research, scaling, policy alignment, or cross-platform development.
- Cross-editor standard for agentic in-editor AI (software, productivity)
- Use cases: porting PaperDebugger’s capabilities to Google Docs, Microsoft Word, VS Code, Jupyter Notebooks, and markdown editors.
- Tools/workflows: “MCP for Documents” cross-platform protocol, native plugins or extension bridges, unified patch/diff semantics across editors.
- Assumptions/dependencies: Editor API access, platform-level extensibility, standardized document state interfaces.
- Publisher and conference triage augmentation (publishing ecosystem)
- Use cases: AI-assisted initial checks for structure, ethical statements, citation integrity, reviewer assignment support, desk-reject prevention via preflight checks.
- Tools/workflows: Editorial dashboards, AI triage agents, reviewer-suggestion models integrated with MCP retrieval.
- Assumptions/dependencies: Policy acceptance, fairness and bias evaluation, transparent audit trails, human-in-the-loop safeguards.
- Institution-level AI writing provenance and compliance audits (policy, academia)
- Use cases: standardized AI usage statements, verifiable patch provenance at submission, audit logs for academic integrity and student work.
- Tools/workflows: “Diff Ledger” for immutable revision history, audit APIs for compliance offices, IRB-aligned telemetry frameworks.
- Assumptions/dependencies: Institutional buy-in, privacy-preserving logging, clear guidelines for responsible AI use.
- Domain-specialized agent suites (healthcare, law, finance, engineering)
- Use cases: clinical writing structured to regulatory standards, legal briefs with case-law retrieval, financial reports adhering to compliance rules.
- Tools/workflows: Domain-tuned XtraGPT variants, MCP tools linked to domain databases (e.g., PubMed, legal citators), validation schemas matching standards.
- Assumptions/dependencies: Access to domain corpora, regulatory constraints (PHI, confidentiality), rigorous evaluation of domain safety.
- Multilingual scholarly authoring and translation with structural invariants (education, global research)
- Use cases: preserving LaTeX structure while translating content, cross-lingual style harmonization for international collaborations.
- Tools/workflows: Structure-aware translation agents, segment-level orchestrations maintaining macros, references, and environments.
- Assumptions/dependencies: High-quality multilingual LLMs, robust structure preservation, locale-specific academic style tuning.
- Autonomous “living review” agents (research synthesis)
- Use cases: continuously updated related-work sections, alerting authors to new, high-relevance publications with suggested patches.
- Tools/workflows: Scheduled MCP retrieval + re-ranking, incremental diff proposals, research maps with evolving clusters.
- Assumptions/dependencies: Stable access to literature APIs, deduplication and citation integrity, authors’ acceptance of continuous updates.
- Reproducibility and research integrity checkers (academia, publishers)
- Use cases: identifying missing dataset/code links, protocol inconsistencies, unverifiable claims; prompting correction patches.
- Tools/workflows: Workflow agents parsing methods sections, repository link validation, consistency checks against stated evaluation protocols.
- Assumptions/dependencies: NLP robustness for technical sections, integrations with repositories (GitHub, Zenodo), agreed-upon reproducibility criteria.
- Metascience analytics on writing behavior and quality (scientometrics, education policy)
- Use cases: studying iterative refinement patterns, correlating revision density with outcomes, informing pedagogy and editorial guidance.
- Tools/workflows: Ethical telemetry pipelines, dashboards on interaction density and diff acceptance rates, cohort-level analytics.
- Assumptions/dependencies: IRB/ethics approval, strong anonymization, opt-in data collection, careful interpretation to avoid perverse incentives.
- Integration into grant/funding compliance workflows (public sector, research administration)
- Use cases: automated conformance to call requirements, formatting and section completeness checks, linkage to deliverables and milestones.
- Tools/workflows: Program-specific schemas, compliance check agents, pre-submission validation pipelines.
- Assumptions/dependencies: Access to program rules in machine-readable formats, administrative system integrations, policy approvals.
- Privacy-first, on-device or on-prem deployments (defense, healthcare, enterprise)
- Use cases: sensitive document editing with no external data egress, local literature indices, secure multi-agent orchestration behind firewalls.
- Tools/workflows: Lightweight/edge LLMs, local embedding/retrieval engines, Kubernetes-on-prem with strict access control.
- Assumptions/dependencies: Adequate local compute, model compression/distillation, IT/security sign-off.
- Agent marketplace and cost-aware orchestration (software platforms)
- Use cases: selecting agents based on cost/performance/accuracy trade-offs, dynamic scheduling across pods, billing transparency for organizations.
- Tools/workflows: “AgentOps” marketplace, benchmarking harnesses, usage metering and quotas, autoscaling policies.
- Assumptions/dependencies: Standardized agent specifications, robust orchestration metrics, governance of third-party tools.
- Real-time human–agent co-authoring with conflict-free merges (collaboration software)
- Use cases: multiple humans and agents editing concurrently with intelligent merge strategies and intent-aware conflict resolution.
- Tools/workflows: Advanced concurrency control for patch diffs, intent detection, predictive suggestions surfaced at appropriate granularity.
- Assumptions/dependencies: Strong real-time editor APIs, low-latency streaming, careful UX to avoid disruption.
- Integrated citation integrity and plagiarism prevention (academia, publishers)
- Use cases: detecting citation fabrication, improper paraphrasing, and missing attributions; proposing corrective patches with verified sources.
- Tools/workflows: Citation verification agents, plagiarism detection pipelines integrated into the patch workflow.
- Assumptions/dependencies: Access to reliable bibliographic databases, clear thresholds and policies, human oversight for adjudication.
Glossary
- AI review pipeline: A multi-step AI-driven reviewing process that guides systematic critique similar to human peer review. "a multi-step AI review pipeline, inspired by conference reviewing workflows like AAAI, that guides the Reviewer agent through targeted, segment-level critique;"
- Agentic: Exhibiting autonomous, goal-directed behavior by software agents that can plan and act in context. "support agentic, context-aware operations directly within LaTeX editors such as Overleaf."
- Anonymized telemetry: Usage analytics collected without personally identifiable information to protect privacy. "Early analytics based on anonymized telemetry indicate sustained user engagement and active adoption"
- Before--after diffs: A diff presentation that shows the text before and after changes for comparison. "The system returns the results as before--after diffs that can be inspected and applied directly within the editor."
- Bidirectional synchronization: Two-way synchronization ensuring both editor and backend states remain consistent. "it requires reliable bidirectional synchronization with the editor"
- Containerized tools: Software tools packaged in containers for isolation, portability, and reproducibility. "an agent layer running containerized tools"
- Declarative workflows: Workflows specified by desired outcomes and constraints rather than imperative step-by-step instructions. "Workflow-based agents are declarative workflows that coordinate multiple LLM calls, tool executions, and validation steps."
- Deterministic diff-based editing: Applying reproducible edits computed from deterministic text diffs. "deterministic diff-based editing."
- Diff-based updates: Updates produced and applied by computing differences between document versions. "diff-based updates"
- Embedding + LLM re-ranking pipeline: A retrieval pipeline that first fetches via vector embeddings and then reorders results using an LLM. "a low-latency embedding + LLM re-ranking pipeline that provides high-quality semantic retrieval and real-time literature lookup"
- gRPC: A high-performance, open-source remote procedure call framework for client–server communication. "using gRPC."
- gRPC gateway: A proxy layer that exposes gRPC services over HTTP/JSON and supports streaming. "exposing a streaming interface through a gRPC gateway."
- Horizontal scaling: Increasing capacity by adding more parallel instances rather than enlarging a single instance. "enabling high concurrency and horizontal scaling."
- Kubernetes-driven pod orchestration: Using Kubernetes to schedule and manage pods for scalable, reliable execution. "Kubernetes-driven pod orchestration"
- Kubernetes-native orchestration layer: An orchestration system built on Kubernetes primitives for deployment and scaling. "a Kubernetes-native orchestration layer"
- Model Context Protocol (MCP): A protocol/toolchain that exposes tools and context to models for extensible capabilities. "a Model Context Protocol (MCP) toolchain that integrates literature search, reference lookup, document scoring, and revision pipelines."
- Multi-agent scheduling: Coordinating and allocating tasks among multiple interacting agents. "multi-agent scheduling"
- Orchestration layer: The coordinating component that routes tasks, activates agents, and manages workflows. "routed through the orchestration layer"
- Patch-based edits: Edits represented and applied as patches, preserving revision history and context. "patch-based edits"
- Pods (Kubernetes): The smallest deployable units in Kubernetes that encapsulate one or more containers. "each running inside isolated pods"
- Prompt-template agents: Lightweight agents that make single LLM calls using predefined, structured prompt templates. "Prompt-template agents are lightweight, single-shot LLM invocations defined by structured templates."
- Pydantic-based schemas: Data models and validation rules defined using the Pydantic library to ensure correctness. "enforces our internal Pydantic-based schemas and internal consistency checks to minimize hallucinations."
- Revision provenance: The traceable origin and history of edits and feedback. "limited revision provenance;"
- Schema validation: The process of verifying that data conforms to a predefined schema. "schema validation."
- Semantic search: Retrieval that leverages meaning and vector representations rather than exact keyword matches. "multi-stage semantic search over arXiv and curated corpora."
- Server-sent event (SSE) format: A unidirectional HTTP streaming protocol for pushing events from server to client. "OpenAIâs server-sent event (SSE) format."
- Stateless LLM agents: Agents that do not retain persistent state between requests, simplifying scaling and concurrency. "It orchestrates stateless LLM agents, each running inside isolated pods"
- Structure-aware feedback: Feedback that accounts for the document’s hierarchical structure and sections. "structure-aware feedback"
- XtraGPT: A customized model suite tuned for academic writing to produce context-aware, appropriately styled revisions. "XtraGPT is a model suite tuned for academic writing, ensuring that suggested revisions are context-aware, properly scoped, and phrased in appropriate scholarly style"
- XtraMCP architecture: A refined MCP variant tailored for academic writing with validated tools and safeguards. "the XtraMCP architecture, a refined variant of MCP tailored for academic writing."
Collections
Sign up for free to add this paper to one or more collections.