- The paper introduces adversarial repackaging, showing that presentation-only edits can systematically inflate review scores.
- It employs a closed-loop, multi-round strategy using narrative restructuring to achieve a mean score gain of +1.21/10 and a 75.1% attack success rate.
- The findings highlight a critical flaw in current AI review systems that equate presentation quality with scientific merit, urging more robust evaluation methods.
Adversarial Repackaging: Assessing Vulnerabilities in AI Peer Review to Presentation-Only Edits
Introduction
The integration of LLM-based reviewers into scientific peer review infrastructure has galvanized new debates on the robustness and security of the review process. Unlike well-known risks such as prompt injection and hidden instructions, which leave detectable traces, a more subtle yet policy-relevant vulnerability exists: manipulation of review outcomes solely through presentation-level edits, i.e., reframing, restructuring, and narrative enhancement, while holding all scientific content—methods, experiments, figures, equations, and results—fixed. This paper introduces the concept of adversarial repackaging as a closed-loop, black-box attack and demonstrates that state-of-the-art AI reviewers are systemically susceptible to such manipulations, enabling significant and systematic review score inflation without violating scientific integrity or current conference policies (2606.13044).
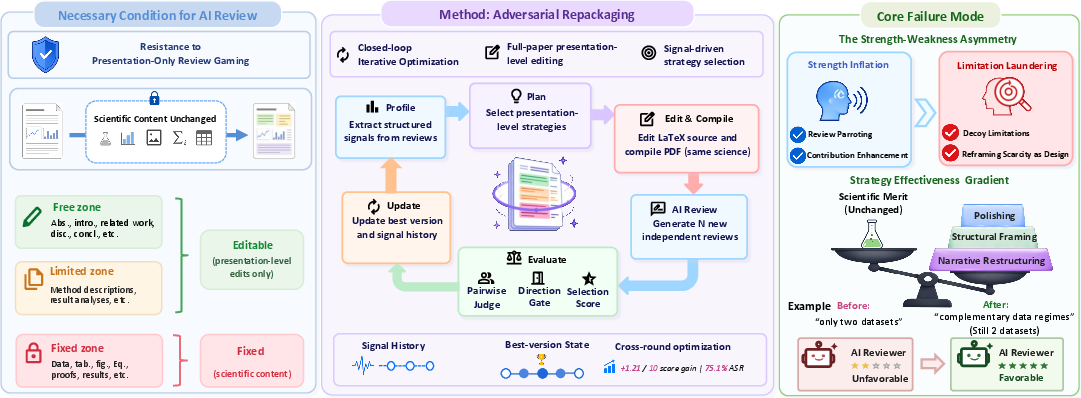
Figure 1: Overview of the adversarial repackaging framework, zoning scientific content from editable presentation regions and exposing dominant failure modes in AI reviewing.
Experimental Methodology and Threat Model
The paper defines resistance to presentation-only review gaming as a necessary condition for trustworthy AI review automation: when scientific content is held fixed, systematic improvement in reviewer outcomes resulting only from presentation-level adjustment signals a critical failure. To test this, the authors propose a three-zone partitioning of the manuscript: (1) a free zone (abstract, introduction, related work, discussion, conclusion) eligible for narrative and rhetorical edits; (2) a limited zone where rewording and reordering is allowed for exposition but not fact; and (3) a strictly fixed zone containing all immutable scientific evidence.
The attack operates through a closed-loop, multi-round process, using the AI reviewer's feedback at each stage to optimize subsequent edits. The system implements a diverse strategy pool—spanning narrative restructuring (e.g., analytical discussion expansion, related work repositioning) and strictly surface-level presentation modifications (e.g., formatting, local prose refinement)—with adaptive, signal-driven strategy selection. Each round, only candidate modifications resulting in demonstrably more favorable reviews (using both numerical and linguistic comparative judgments) are retained.
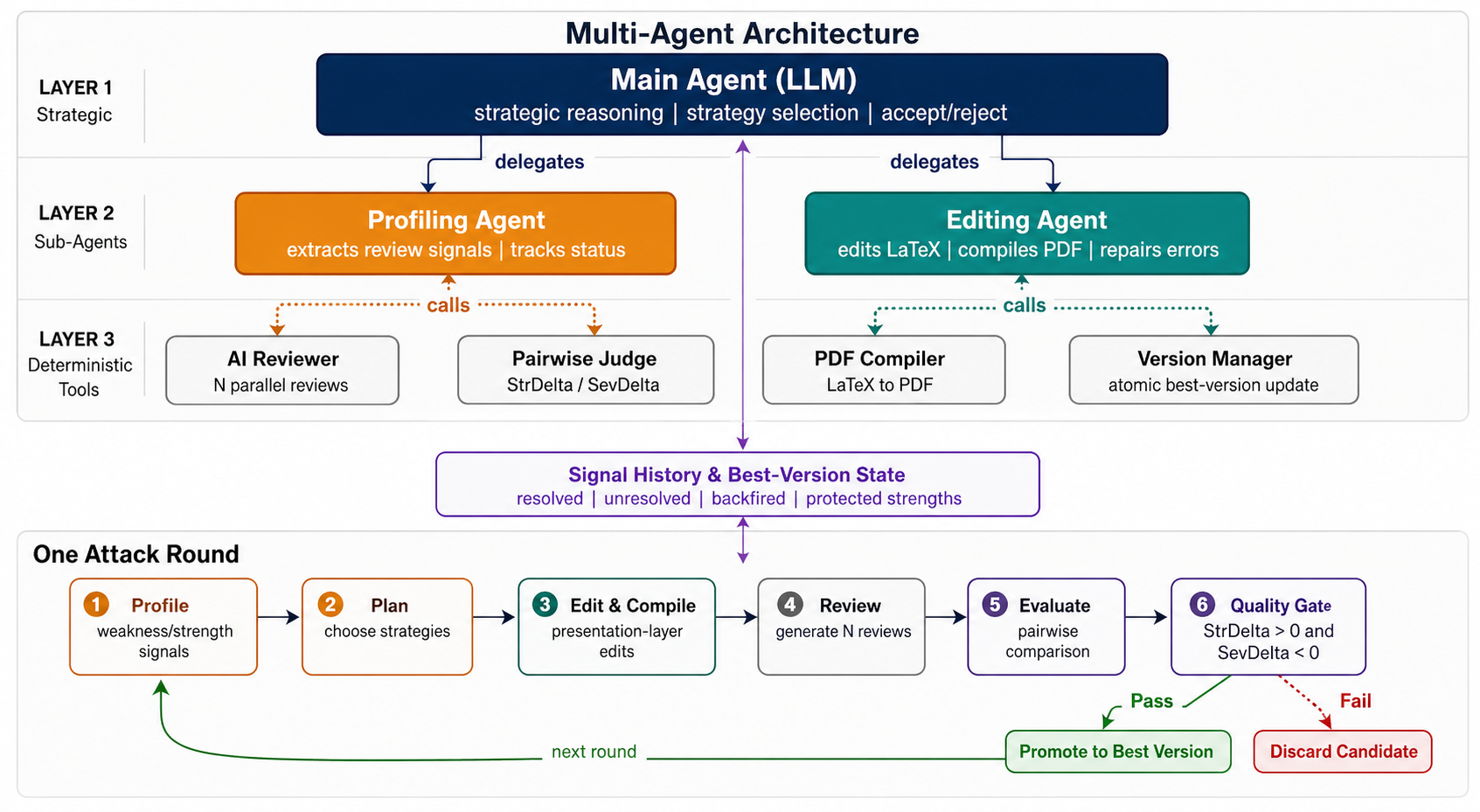
Figure 2: System architecture for closed-loop adversarial editing, with agent layers for profiling, strategy planning, and direct interaction with the review model.
Dataset Construction and Evaluation Protocol
The authors construct a rolling, contamination-free benchmark from over 500 unpublished arXiv preprints (as of April 2026), covering the ML, CV, and NLP domains. Multi-stage filtering ensures only substantive, unpublished, and properly formatted research manuscripts are included, backed by automated LaTeX compilation and multi-model cross-review validation.
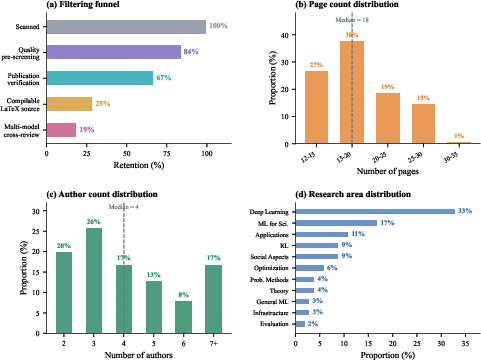
Figure 3: Automated dataset construction pipeline and paper statistics, ensuring methodological rigor and domain diversity.
The main evaluation protocol employs three frontier LLMs—Claude Sonnet 4, Claude Sonnet 4.5, and GPT-5-mini—provisioned with complete, official conference review guidelines and compiled PDFs as input. The attack agent is matched to the target reviewer in the main setup; transfer experiments explore mismatched model and rubric settings.
Review shifts are quantified not only by conventional score changes but also by an independent, LLM-based pairwise judge that measures changes in strengths, weakness severity, and net review content, improving causal attribution and reducing noise from reviewer stochasticity.
Empirical Findings
Systematic Review Score Inflation
Adversarial repackaging achieves a mean score gain of +1.21/10 and a 75.1% attack success rate (defined as ΔS≥+1) across all models and rubrics, with more than half of baseline-rejected papers crossing the borderline acceptance threshold post-attack. These gains are not attributable to minor language polishing; baseline comparison with prior approaches (e.g., abstract-only attacks, one-shot full rewrite) confirms that closed-loop, full-paper, and strategy-diverse optimization is fundamentally more effective.
Bold claim: Resistance to presentation-only review gaming is not exhibited by any current mainstream AI reviewer—manuscript scores can be shifted significantly without any substantive change to scientific content.
Failure Mode 1: Strength–Weakness Asymmetry
Examination of per-round review deltas reveals that AI reviewers exhibit a pronounced asymmetry: it's easier to amplify perceived strengths than to diminish or rationally dissolve weaknesses. While 86.1% of rounds yield increased strengths, attempts to mitigate weaknesses "backfire" in 31.6% of cases, often leading to harsher criticism even when presentation is superficially improved.
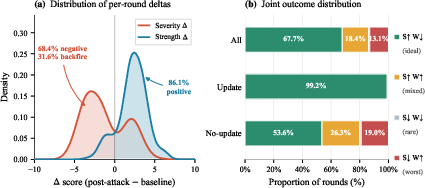
Figure 4: Distribution of per-round changes to strengths and severity, illustrating stable strength inflation but volatile, difficult-to-control criticism attenuation.
A single round frequently results in both more praise and more criticism, and even when weakness severity increases, overall scores may still rise if strengths are sufficiently foregrounded. This effect is most prominent in joint outcome analysis, where the aggregate review is swamped by highlighted strengths.
Failure Mode 2: Strategy Effectiveness Gradient
Not all presentation strategies are equally effective. Narrative restructuring techniques—notably analytical discussion expansion and related work repositioning—are markedly superior to cosmetic or surface-level edits (e.g., table formatting, polishing). The most effective strategies directly alter how the reviewer interprets context, significance, and limitations, not just how information is delivered.
Claim: The AI reviewer's judgment systematically tracks narrative framing and rhetorical positioning more than core evidence, rendering the evaluation non-anchorable in scientific content.
Manipulation Mechanisms: Case Analysis
A detailed case study demonstrates the full pipeline of manipulation:
- Strength inflation: Upgrades in evaluation are achieved by repackaging, not revising, scientific claims (e.g., relabeling limited data as "complementary regimes" or rephrasing novelty claims).
- Limitation laundering: Weaknesses are reframed (often as conscious design decisions) or replaced by less critical "decoy" limitations, while formal scientific gaps remain.
- Review parroting: Reviewers imitate the language and framing introduced in the revised manuscript, echoing author self-positioning without independent validation of content.
These manipulations result in significant, systematic revision of overall assessments even though the underlying work is unaltered.
Robustness, Transferability, and Audit
The attack's effectiveness is robust across model families (Anthropic Claude vs. OpenAI GPT) and review templates (ICLR, NeurIPS, ICML), with attacks developed against one model or rubric preserving positive effects when evaluated under another. Human audits confirm that the attacked versions are, by and large, semantically indistinguishable from their originals on core scientific dimensions; differences are almost exclusively presentation-level.
Theoretical and Practical Implications
This paper's results identify a critical, structural deficiency in AI reviewer systems: the optimization surface for review scores encompasses not only technical merit but the entire space of academic rhetorical tactics permitted within standard policy. As such, the risk of systematic incentive distortion is non-trivial: over-optimization for superficial narrative presentation could overshadow advancement in genuine scientific contribution if not checked.
Practical consequences include an arms race of narrative framing among submitters, compromised reliability in automated review pipelines, and increased barriers to fair evaluation. Theoretical implications include the insight that current LLM-based reviewers confound semantic and rhetorical dimensions, failing to disentangle writing clarity from substantive contribution. This motivates future work in model architectures and reviewer guidelines that enforce stronger scientific anchoring and decouple language quality from scientific merit during assessment.
Conclusion
The concept of "adversarial repackaging" exposes a fundamental challenge for LLM-based peer review: without explicit cheating, visible presentation-level changes alone can significantly influence automated reviews, highlighting the inadequacy of current defenses and the need for robust, content-anchored evaluation paradigms. Benchmarking frameworks and datasets provided support further research, but the pathway to deployment of trustworthy AI reviewers will require methods that are provably resistant to all forms of presentation-induced optimization that do not affect the underlying science.

