LeanMarathon: Toward Reliable AI Co-Mathematicians through Long-Horizon Lean Autoformalization
Abstract: Long-horizon autoformalization of research mathematics fails not only at hard lemmas, but at scale: statements drift, dependencies tangle, context decays, and local repairs corrupt distant work. We present LeanMarathon, a multi-agent harness for reliable research-level Lean autoformalization. Its core abstraction is an evolving blueprint: a Lean file that serves simultaneously as formal proof skeleton, natural-language proof graph, and shared system of record. Four contract-scoped agents construct, audit, prove, and repair this blueprint. These agents are coordinated by a two-stage orchestrator that first stabilizes target fidelity through adversarial review and then discharges the proof directed acyclic graph (DAG) from its dynamic leaves upward in parallel CI-gated rounds. LeanMarathon turns one brittle multi-hour run into many local, recoverable, parallel transactions. We evaluate LeanMarathon on two recent research papers spanning four Erdős problems (#1051, #1196, #164, #1217). Across three autonomous runs, it formalizes all seven target theorems with no sorry, proving 258 lemmas and theorems. These results show that reliable AI co-mathematics requires not only stronger provers, but durable harnesses that preserve target fidelity across long mathematical developments. The code can be found at https://github.com/YuanheZ/LeanMarathon.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
LeanMarathon: a simple explanation
What is this paper about?
This paper is about helping AI work as a reliable teammate for mathematicians. It focuses on a tricky step called autoformalization: turning math written in normal language into precise computer-checked proofs in a system called Lean. The authors build a “harness” (a strong support system) named LeanMarathon that keeps long, complicated formalization projects on track for hours without drifting off target.
Think of formalizing a research paper like building a huge LEGO city:
- You need a good plan that everyone follows.
- Many builders work in parallel.
- Inspectors constantly check that new pieces fit perfectly.
- If a mistake appears, repairs shouldn’t break faraway parts.
LeanMarathon is designed to make that whole process safe, orderly, and recoverable.
What questions do the authors try to answer?
They ask:
- How can we stop long AI runs from “drifting” away from the real math goal?
- How can we split a big proof into many small, safe tasks that different AI agents can handle in parallel?
- How can we make fixes local (so one wrong change doesn’t ruin hours of work)?
- How can we keep the human-readable math and the computer-checked math perfectly in sync?
How does their approach work?
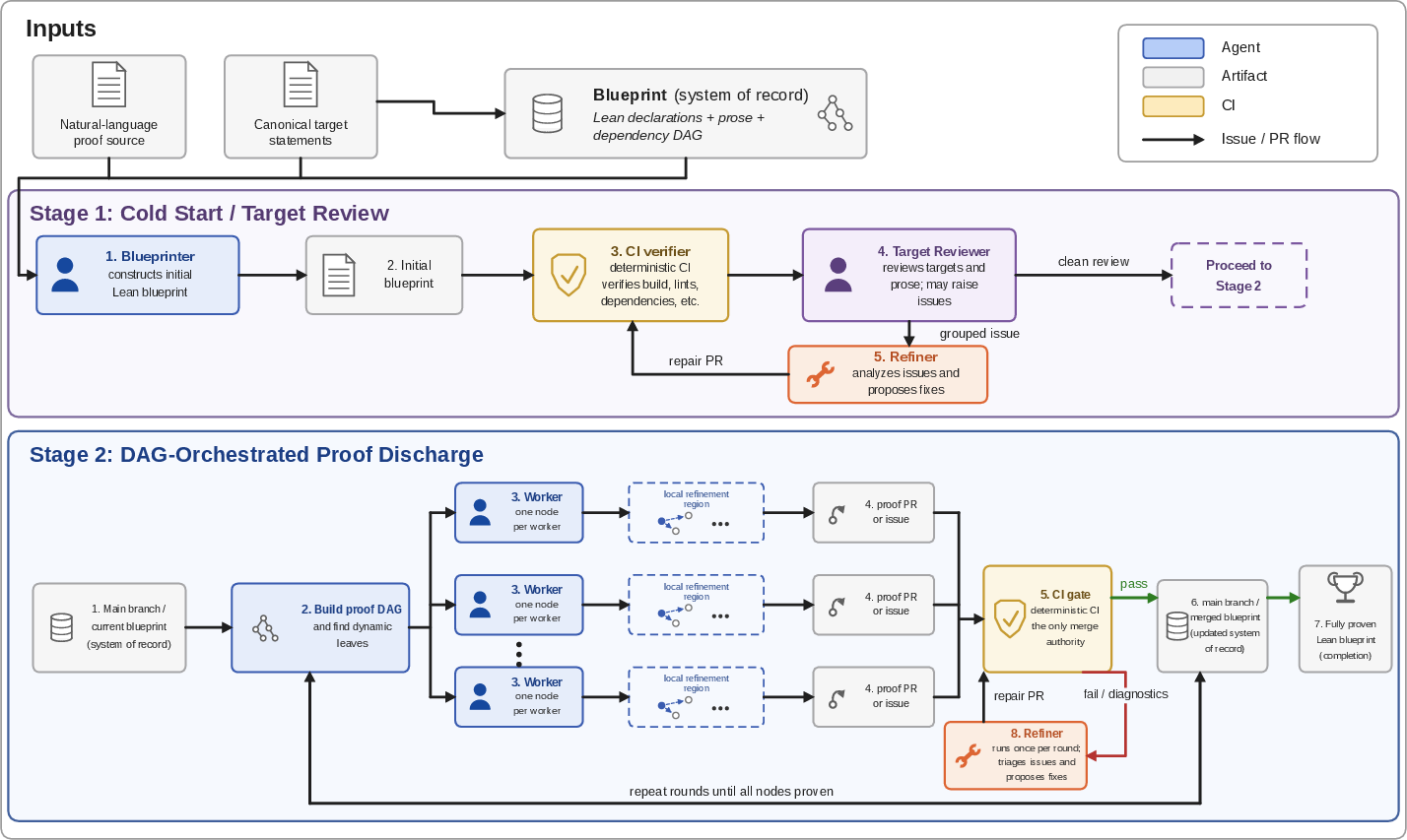
Their main idea is an evolving blueprint: one Lean file that is the single source of truth. It holds:
- The formal statements and proofs (checked by Lean).
- The matching human-readable statements and proof sketches (in LaTeX).
- The proof map (which
lemmadepends on which others), also called a directed acyclic graph (DAG).
This blueprint is always kept consistent. If the human text cites lem:A, then the Lean proof must actually depend on lem:A, and vice versa. If not, the change is rejected.
They organize the work using four specialized “agents,” like a well-run construction crew:
- Blueprinter: reads the source paper and writes the initial plan. It creates the
lemmaandtheoremstatements and putssorryplaceholders where proofs will go. - Target-Reviewer: double-checks that the formal statements match the intended theorems (no hidden changes or missing conditions).
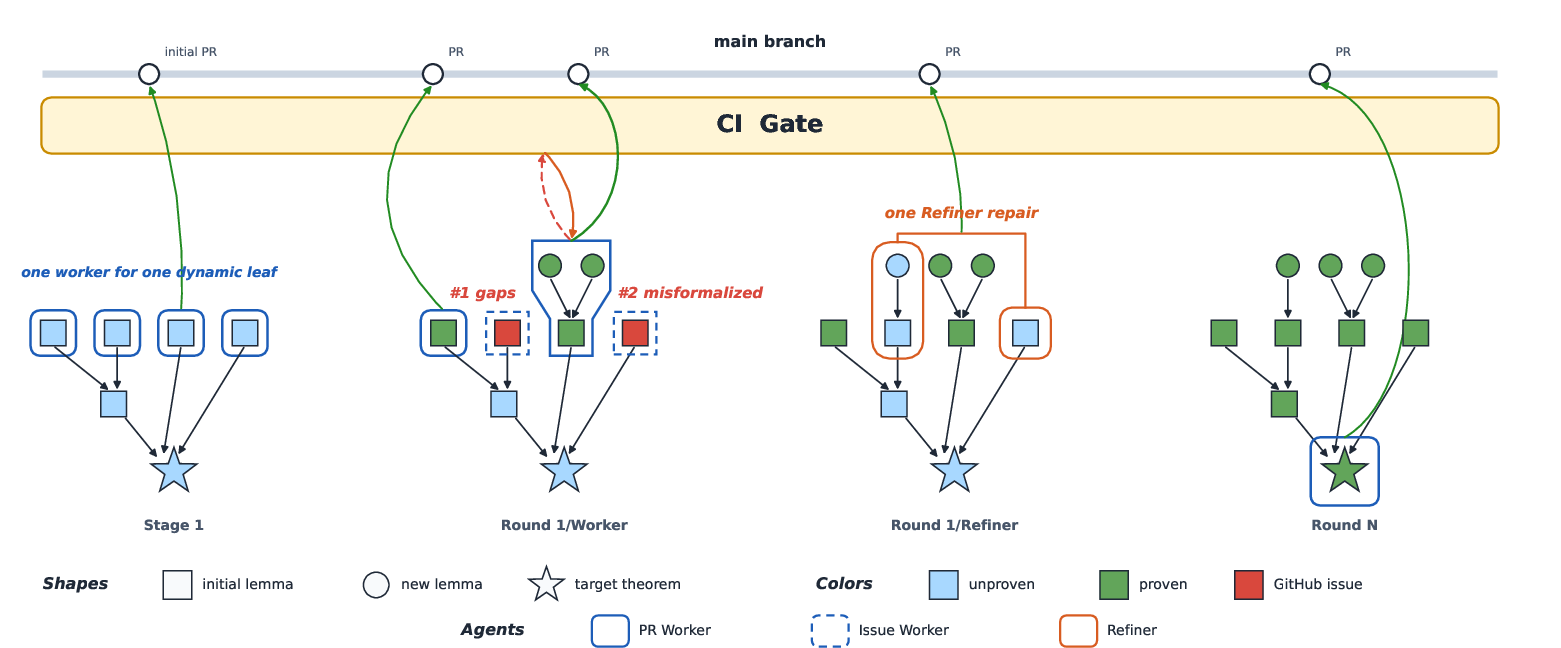
- Worker: proves one small piece at a time. It is allowed to edit only a tiny, local region: the proof body and a small helper area before it. It cannot change the statement itself once set.
- Refiner: fixes broader problems when someone finds a mismatch or a gap. It can edit a connected “illness” area of the proof map, but if it must change a statement, it does not try to patch a half-broken proof—it cleanly resets the broken proof to a placeholder so damage doesn’t spread.
A “two-stage orchestrator” coordinates everything:
- Stage 1: stabilize targets. The Blueprinter drafts; the Target-Reviewer audits. If mismatches are found, the Refiner fixes them. This loop repeats until everyone agrees the targets are faithful to the paper.
- Stage 2: build the proof in rounds. The system finds “leaves” (nodes whose dependencies are already proven) and assigns them to Workers in parallel. Each Worker opens a tiny, safe edit zone and tries to prove the node. All changes go through an automatic test gate (like a referee) called CI. Only passing changes get merged into
main. Issues get sent to the Refiner next round.
Two key safety features make this durable:
- Strict edit boundaries: agents cannot touch parts they don’t own. This prevents one mistake from corrupting others.
- Deterministic checks: agents don’t judge their own work. The Lean compiler and CI checks approve or reject changes, never the agent itself.
To make this more concrete, here are a few friendly analogies and terms:
- Proof DAG: a map of the LEGO city that shows which pieces must be placed before others.
sorryorsorry_using [...]: a placeholder standing in for “we’ll prove this later, and we think we need these helpers.”- CI gate: a set of automatic tests that must pass before anything is accepted.
- Parallel rounds: many Workers build different, non-overlapping rooms at the same time.
What did they find?
They tested LeanMarathon on two recent research papers in number theory, covering four Erdős problems, and set seven precise theorems as targets. In three autonomous runs:
- All seven theorems were fully formalized (no
sorryleft). - 258 lemmas and theorems were proved in total.
- The system handled long, multi-hour progress by breaking it into many small, safe, parallel steps.
- A commercial single-agent baseline failed after tens of hours on these papers, showing the advantage of LeanMarathon’s harness design.
Why is this important? Because it shows that reliability in research-level math needs more than a strong “prover.” It needs a durable workflow that:
- Keeps the goal from drifting,
- Makes fixes local and recoverable,
- Lets many agents work in parallel without stepping on each other,
- Preserves exact agreement between the human text and the machine-checked proof.
What could this change in the future?
- More trustworthy AI co-mathematicians: When AI proposes a proof, having a complete Lean formalization gives very high confidence it’s truly correct.
- Faster research at scale: With safe parallelism and strong guardrails, large math projects can move faster without collapsing under their own complexity.
- Better learning materials: The blueprint holds both the human explanation and the machine proof. That could enable future textbooks where you can smoothly switch between a gentle overview and a fully detailed, computer-checked proof.
- A general lesson: For big, long-running AI tasks (not just math), strong “harness” design—clear roles, strict scopes, automatic checks—can be as important as smarter models.
In short, LeanMarathon shows that to get reliable, large-scale math formalization, you need a sturdy team process and a single, evolving, well-checked blueprint—not just a powerful AI trying to do everything at once.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper; each item suggests a concrete direction for future work.
- External validity and scale
- Generalization beyond two number-theory papers: evaluate across diverse domains (geometry, combinatorics, measure theory, algebraic topology) with different proof styles and heavy typeclass usage.
- Scalability to larger developments: stress-test on projects with thousands of proof nodes, multi-day runs, and cross-file/module dependencies.
- Handling limited library coverage: systematically study cases where Mathlib lacks required lemmas/definitions and define policies for library extension within the harness.
- Reproducibility and model dependence
- Reliance on a closed model (Codex/GPT-5.5-xhigh): replicate with open-source models and report performance deltas and required prompt/tooling adaptations.
- Release exact prompts, MCP tool specs, CI configurations, token/compute budgets, and full PR/issue logs for end-to-end reproducibility.
- Missing ablations and component efficacy
- Isolate the contribution of each mechanism (two-stage orchestrator, edit-scope enforcement, proof-dependency parity, lemma-closeness, stop-hook recovery) via controlled ablations and measure impact on success rate, drift, and cost.
- Compare against simpler orchestration baselines (e.g., monolithic agent; single-stage proof discharge; no CI parity checks) to quantify harness value.
- Metrics and cost reporting
- Report wall-clock time, token/compute consumption, CI pass/fail rates, PR merge rates, and rework due to Refiner downgrades, per node and per run.
- Provide variance across multiple reruns to assess stability and sensitivity to sampling and scheduling seeds.
- Decomposition quality
- The “repair-radius optimization” for the Blueprinter is only conceptual; define a measurable objective and propose algorithms/heuristics to minimize expected repair radius (e.g., learned decomposition policies, graph-edit simulation).
- Quantify over/under-decomposition rates and their downstream costs (e.g., worker failure rates, number of issues filed).
- Target fidelity checking
- Reliability of the Target-Reviewer is unmeasured: evaluate precision/recall on seeded misformalizations and quantify false negatives that slip into Stage 2.
- Explore formal or semi-formal equivalence checks between LaTeX and Lean statements (e.g., normalization of quantifier order, definitional unfolding, alignment of hypothesis sets).
- Dependency parity and graph integrity
- Vulnerability to gaming parity: agents could add spurious citations to satisfy two-way parity; add checks for minimality/necessity of edges (e.g., proof-use instrumentation or dependency slicing).
- Acyclicity is not listed among the seven CI checks; explicitly enforce DAG acyclicity and detect long-range hidden cycles.
- Definitions excluded from the DAG can hide drift in global context; evaluate including definitional dependencies in the graph (with a separate policy to limit explosion).
- Local testing and falsification
- The numeric “cheap falsification” step is ad hoc and domain-limited; specify a principled test harness (e.g., bounded instance generators, SMT-backed counterexample search) and study its utility/false-positive/negative rates.
- Repair policies and proof preservation
- Refiner’s “wholesale downgrade” of broken complete proofs wastes verified work; investigate localized proof repair (e.g., proof-term surgery, tactic-agnostic refactoring) with guarantees on blast radius.
- Define metrics for “repair blast radius” and enforce CI budgets on the size of illness-area edits.
- Parallelism and merge conflicts
- Name/label collisions in local helper lemmas during parallel work lead to PR conflicts; develop deterministic name-mangling and auto-rebase/auto-rerun strategies.
- Study scheduling heuristics for dynamic leaves (critical-path first, difficulty prediction, learned prioritization) and quantify throughput gains.
- Convergence and deadlock
- No theoretical guarantees of convergence or deadlock detection: formalize conditions under which the orchestrator must terminate (or detect impossibility) and propose progress metrics/alerts for stalled runs.
- Human-in-the-loop and prose quality
- Evaluate the “informalize while formalizing” claim with users: measure readability, correctness, and usefulness of the embedded LaTeX (statement/proof) at multiple resolutions.
- Determine when brief human checkpoints improve reliability/cost and design safe insertion points without undermining autonomy.
- Blueprint substrate and project structure
- Single-file blueprint may not scale; investigate multi-file/module blueprints, namespaces, and incremental compilation while preserving CI checks and edit-scope guarantees.
- Define policies for adding/modifying global definitions (currently “global context”) without destabilizing parallel workers.
- CI contract completeness and side effects
- “Lemma closeness” may block legitimate library-building lemmas with no immediate consumers; quantify false positives and consider scoped exemptions.
- Ensure elaborator dependency extraction captures implicit uses (typeclass inference, coercions); test and harden parity checks against these Lean-specific subtleties.
- Source gaps and target preservation
- When repairing source gaps, how is equivalence to the paper’s intended claims ensured? Define an explicit contract for acceptable modifications and a verification step that the top-level targets remain unchanged (or record, justify, and surface any change).
- Baselines and comparative evaluation
- Systematic comparisons against open baselines (e.g., LeanDojo-based provers, RL provers, other public harnesses) on shared targets are missing; establish a benchmark suite and report standardized metrics.
- Operational robustness
- Stop-hook recovery can loop under persistent CI failures; define escalation policies, automated bisection, and failure triage.
- Timeouts and resource limits for tactic/search are unspecified; report policies and their impact on success/failure.
- Tooling availability and portability
- MCP servers (apply-patch, dag-tracker) and Codex patches should be open-sourced, documented, and evaluated for portability to other PA/LLM stacks (Coq, Isabelle, HOL; Llama-family models).
- Error taxonomy and telemetry
- Provide a fine-grained taxonomy of agent failures (misformalization, missing deps, tactic timeouts, CI parity violations) with frequencies, to guide targeted improvements and safety checks.
Practical Applications
Immediate Applications
The following applications can be piloted today using LeanMarathon or by adapting its core ideas (dynamic blueprint as a system of record, multi-agent contracts, CI-gated proofs, DAG-based orchestration, bounded edit scopes, and prose–formal parity checks).
Academia and Scientific Publishing
- AI-verified paper-to-proof pipelines for journals and conferences
- What: Require submissions (especially AI-assisted results) to include a Lean blueprint that type-checks and passes structural CI checks (compilation, well-formed nodes, prose–dependency parity, lemma-closeness).
- Tools/workflows: “Proof CI” GitHub Actions; blueprint metadata attribute; Target-Reviewer role for statement fidelity; dynamic-leaf task queues for community contributors; stop-hook diagnostics.
- Assumptions/dependencies: Sufficient domain libraries (e.g., Mathlib coverage), standardized canonical statements, authors’ consent to share LaTeX sources, access to CI.
- Lab-internal verification of AI-discovered results
- What: Integrate the harness into research workflows to turn AI-generated proofs into machine-checked artifacts; detect source gaps vs. blueprint drift early.
- Tools/workflows: Blueprinter for initial skeleton; Refiner to localize and repair misformalizations; per-node Workers for parallel discharge; DAG tracker for live dependencies.
- Assumptions/dependencies: Access to high-context LLMs; stable Lean toolchain; compute for parallel Workers.
- Courseware and assignments with multi-resolution proofs
- What: Use the blueprint to show side-by-side Lean statements and LaTeX sketches; CI enforces that student edits keep prose–proof parity and avoid orphan lemmas.
- Tools/workflows: Assignment repos with seven-check CI; graded PRs; numeric stress tests as pre-proof checks; constrained edit spans for students.
- Assumptions/dependencies: Students’ Lean environment; curated problem libraries; instructor-provided canonical targets.
Software/DevOps and Documentation
- Spec–code parity enforcement for large codebases
- What: Treat design docs/ADRs as the “prose graph” and code dependencies as the “typed graph”; enforce two-way parity (no undocumented dependencies; no dead doc references).
- Tools/workflows: Prose–code dependency extractor; CI parity check; “orphan function” detector inspired by lemma closeness; Refiner bots to fix drifted modules.
- Assumptions/dependencies: Structured docs (e.g., Markdown with anchors), static analysis to recover dependency DAGs, repo CI integration.
- Safe multi-agent code refactoring harness
- What: Apply Worker/Refiner roles with bounded edit scopes and CI gates for long-running refactors (e.g., API migrations), turning risky changes into local, recoverable transactions.
- Tools/workflows: MCP apply-patch server for span enforcement; PR squash-merge after deterministic checks; stop-hook auto-recovery; DAG-based task scheduling.
- Assumptions/dependencies: Clear code DAGs (build graphs), test suites as verifiers, permissioned repos.
Legal/Compliance/Finance
- Control and risk “proofs” with dependency DAGs
- What: Map policies/controls to executable checks; require that every claim cites upstream evidence (tests, data, audits) and passes CI like a proof DAG; detect “orphan controls.”
- Tools/workflows: Compliance blueprint format; prose–evidence parity checkers; Reviewer role for policy fidelity; Refiner triage of missing or ambiguous controls.
- Assumptions/dependencies: Machine-readable controls, data access governance, regulator acceptance of machine-checked control graphs.
- Contract engineering with testable obligations
- What: Link clauses to formal constraints and automated tests; CI fails when obligations or dependencies drift; localized repair PRs maintain traceability.
- Tools/workflows: Clause labeling and citation; execution/evidence hooks; parity enforcement; constrained per-clause edit spans in PRs.
- Assumptions/dependencies: Contract templates with stable IDs; test harnesses for obligations; organizational buy-in.
Safety-Critical Engineering (Robotics/Automotive/Medical Devices)
- Safety case management with prose–evidence parity
- What: Adapt blueprint to Goal Structuring Notation (GSN): goals (nodes), strategies (prose), evidence (formal artifacts); CI enforces no drift and no orphan arguments.
- Tools/workflows: Safety-case blueprint schema; per-goal Workers producing tests/analyses; CI gate; reviewer role for certification alignment.
- Assumptions/dependencies: Certification standards mapping (e.g., ISO 26262, DO-178C), evidence toolchains, sign-off processes.
Education and Daily Life
- Personal math study assistants with rigorous feedback
- What: Learners build proof skeletons, run quick falsification (sanity checks), and formalize steps with CI feedback on missing hypotheses or misalignments.
- Tools/workflows: “LeanMarathon-Lite” templates; sandboxed PRs; numeric stress-test snippets; guided misformalization audits.
- Assumptions/dependencies: Beginner-friendly Lean tooling; curated exercises; limited compute.
Long-Term Applications
These applications require further research, tooling maturity, domain libraries, or institutional/policy changes before broad deployment.
Cross-Domain Formal Co-Reasoning
- Generalized blueprint harness across provers and specs
- What: Extend to Coq/Isabelle/Agda and to system specs (Dafny, F*, TLA+, Alloy); unify prose–formal parity and DAG orchestration across domains.
- Tools/products: “Blueprint Studio” IDE; doc-to-DAG extractors; multi-prover CI adapters; universal MCP servers (apply-patch/dag-tracker).
- Assumptions/dependencies: Rich domain libraries, standard metadata schemas, interop between formal tools, scalable proof search.
- Enterprise-wide “alignment harness” for agents
- What: A pattern for bounding agent scope, enforcing deterministic gates, and maintaining a shared system of record across documentation, code, data pipelines, and policies.
- Tools/products: Orchestrator SaaS with role templates (Blueprinter/Reviewer/Worker/Refiner); governance dashboards; replayable audit trails.
- Assumptions/dependencies: Organization-wide CI/CD, identity/permissions, cultural adoption of machine-checked workflows.
AI Scientist and Textbook-of-the-Future
- From conjecture to machine-checked paper with layered explanations
- What: Agents generate conjectures, sketches, formalize in Lean, and publish multi-resolution expositions from the same blueprint artifact.
- Tools/products: Reasoning provers integrated as Workers; summarization layers; interactive textbooks with expandable proof DAGs.
- Assumptions/dependencies: Stronger provers for hard mathematics, reliable translation between formal and natural language, editorial standards for formal artifacts.
Regulatory and Policy Frameworks
- Standards for machine-checkable AI claims
- What: Procurement and regulatory requirements that high-stakes AI claims include blueprint-based, CI-verified artifacts (e.g., fairness proofs, safety arguments).
- Tools/products: Certification badges (“No-sorry verified”), reference CI profiles, compliance templates for sectors (healthcare, finance, energy).
- Assumptions/dependencies: Regulator acceptance, agreed benchmarks, legally recognized digital audit trails.
Verification for Control, Robotics, and Energy
- Autoformalization of control and optimization proofs
- What: Stability, safety, and performance proofs mapped to blueprint DAGs; parallel discharge with provers; continuous verification as systems evolve.
- Tools/products: Domain libraries (Lyapunov, hybrid systems, optimization duality), plant-model connectors, evidence collectors.
- Assumptions/dependencies: Mature formal libraries, model fidelity, integration with simulators and HIL.
- Grid reliability and market mechanism proofs
- What: Formal arguments for reliability, incentive compatibility, and robustness in energy markets, continuously checked as rules change.
- Tools/products: Mechanism design libraries; data-backed evidence nodes; parity checks tying regulations to formal claims.
- Assumptions/dependencies: Access to operational data, domain-specific provers, regulatory collaboration.
Open Knowledge Graphs of Mathematics
- Global proof DAGs for discovery and reuse
- What: Publish interoperable blueprints that link results, enabling search, recombination, and automated premise selection without drift.
- Tools/products: Federated DAG indices; lemma-closeness governance to prevent “orphan” contributions; provenance tracking across repos.
- Assumptions/dependencies: Community standards, persistent identifiers, scalable storage and query.
Notes on feasibility and dependencies
- Model and library maturity: Success depends on strong provers (Lean 4 and domain libraries like Mathlib) and capable LLMs for Blueprinter/Worker roles.
- Deterministic verification and CI: The reliability comes from deterministic gates; organizations must adopt CI as the single path to merge.
- Bounded edit scopes and artifacts: Enforcing contracts (apply-patch server, path allowlists) is crucial to prevent drift and context rot.
- Source quality and canonical targets: Target-Reviewer effectiveness assumes accurate canonical statements and accessible source LaTeX.
- Compute and orchestration: Parallel DAG discharge requires sufficient compute and repository automation (PRs, issues, merge policies).
- Culture and incentives: Journals, regulators, and enterprises need incentives/mandates to value machine-checked artifacts alongside prose.
Glossary
- adversarial review: A review process that intentionally pits checking roles against potential errors to expose mismatches before large-scale proving. Example: "first stabilizes target fidelity through adversarial review"
- agent durability: An agent’s ability to remain coherent, recoverable, and resistant to drift over long runs. Example: "We identify agent durability as the central bottleneck in research-level autoformalization,"
- autoformalization: Automatically transforming mathematical statements and proofs into machine-checkable formal proofs (e.g., in Lean). Example: "Long-horizon autoformalization of research mathematics fails not only at hard lemmas, but at scale:"
- blueprint: The single Lean file that is both the formal proof skeleton and the natural-language proof graph, serving as the system of record. Example: "Its core abstraction is an evolving blueprint: a Lean file that serves simultaneously as formal proof skeleton, natural-language proof graph, and shared system of record."
- blueprint drift: A defect where the Lean blueprint diverges from the source proof’s intent. Example: "The \agent{Refiner} classifies each defect as either {\bf blueprint drift} or a {\bf source gap}."
- branch protection: A GitHub setting requiring certain checks to pass before merging a pull request. Example: "Auto-merge requires a pending required check (branch protection) and serialises across parallel PRs"
- CI gate: The mandatory continuous integration checks that must pass before merging changes. Example: "Proof PRs are accepted only by the CI gate."
- continuous integration: An automated verification pipeline that builds, checks, and enforces contracts on every pull request. Example: "CI verifier as continuous integration"
- contract-scoped agent: An agent limited to a narrow interface and bounded edit scope to contain faults. Example: "Four contract-scoped agents construct, audit, prove, and repair this blueprint."
- directed acyclic graph (DAG): A directed graph with no cycles; here, it represents proof dependencies among nodes. Example: "discharges the proof directed acyclic graph (DAG) from its dynamic leaves"
- Dirichlet eta function: A special function from analytic number theory whose monotonicity is used in proofs. Example: "and the monotonicity of the Dirichlet eta function."
- divisibility poset: The partially ordered set where elements are ordered by divisibility. Example: "Markov chains with von Mangoldt weights on the divisibility poset."
- doubly-harmonic weight: A specific weight function used to analyze chains on the divisibility poset. Example: "The proofs use the sub-invariance of the doubly-harmonic weight under the von Mangoldt chain"
- doubly-logarithmic density: A density notion scaled by iterated logarithms, used to state structural results about sets. Example: "produces an infinite divisibility chain inside any set of positive doubly-logarithmic density."
- dynamic leaves: Unproved nodes in the proof DAG whose dependencies are already proved and can be discharged in parallel. Example: "identifies dynamic leaves whose dependencies have already been proved"
- elaborator (Lean): The Lean component that infers types and dependencies during compilation. Example: "the dependency graph and \code{sorry}-status are inferred from Lean's elaborator."
- elaborator metadata: Compiler-emitted data about proof dependencies used for verification parity checks. Example: "via Lean's elaborator metadata"
- Erdős sums: Sums associated with primitive sets introduced by Erdős, used as a benchmark in additive/analytic number theory. Example: "bounds Erd\H{o}s sums of primitive sets"
- illness sub-DAG: The smallest connected region of the proof DAG identified as affected and needing repair. Example: "one connected illness sub-DAG"
- LeanArchitect: A format/tooling for embedding structured blueprint metadata directly in Lean declarations. Example: "in the format of LeanArchitect~\citep{zhu2026leanarchitect}"
- lemma closeness: A structural check requiring each lemma to be used by later results, preventing orphan lemmas. Example: "Lemma closeness: every \code{lemma} must be cited by some later \code{lemma} or \code{theorem};"
- lost-in-the-middle: A failure mode where the agent gets trapped in proliferating subproblems and loses sight of the main target. Example: "The second is lost-in-the-middle, where the agent becomes trapped in an exponentially growing space of unproductive subproblems"
- Mahler's criterion: A criterion from transcendence/irrationality theory used to prove sums are irrational. Example: "proves irrationality of a weighted series via Mahler's criterion"
- MCP server: A tool-serving process (Model Context Protocol) that enforces editing and context constraints for agents. Example: "an editing MCP server built by patching Codex's \code{apply-patch} tool"
- Mertens-type estimates: Analytic number theory estimates analogous to Mertens’ results, used in bounding sums. Example: "Mertens-type estimates"
- natural-language proof graph: The prose representation of the proof’s structure stored alongside formal statements. Example: "a Lean file that serves simultaneously as formal proof skeleton, natural-language proof graph, and shared system of record."
- orchestrator: The controller that coordinates agents and stages of review and proof discharge. Example: "These agents are coordinated by a two-stage orchestrator"
- primitive set: A set of integers with no element dividing another. Example: "asserts for a primitive set "
- proof DAG: The dependency graph formed by lemma and theorem nodes in the blueprint. Example: "The proof DAG is formed only from lemma and theorem declarations."
- proof skeleton: The initial formal structure of statements with placeholder proofs guiding the development. Example: "serves simultaneously as formal proof skeleton, natural-language proof graph, and shared system of record."
- repair radius: The expected scope of downstream changes required when fixing a misformalized declaration. Example: "repair-radius optimization problem"
- source gap: A deficiency, ambiguity, or error in the source proof itself rather than in the formalization. Example: "either {\bf blueprint drift} or a {\bf source gap}"
- squash-merge: A merge strategy that squashes all commits from a PR into a single commit on main. Example: "Passing non-conflicting PRs are squash-merged independently"
- sorry: A Lean placeholder indicating an unproved proof body; forbidden in final results. Example: "with no \code{sorry}, proving 258 lemmas and theorems."
- target fidelity: The faithfulness of formalized targets to the intended mathematical statements. Example: "first stabilizes target fidelity through adversarial review"
- von Mangoldt chain: A Markov chain on the divisibility poset weighted by the von Mangoldt function. Example: "under the von Mangoldt chain"
Collections
Sign up for free to add this paper to one or more collections.

