Strategic Decision Support for AI Agents
Abstract: Traditionally, decision support studies how humans use machine learning models to make better decisions. In modern agentic systems, this division of roles is increasingly reversed: AI agents act on behalf of users, while humans and tools becomes support mechanisms around them. This role reversal brings reliability concerns to the forefront, since agentic errors can be consequential and agent behavior must remain aligned with human goals and constraints. Departing from the classical view of decision support, we revisit its two basic principles, the cost--value tradeoff of seeking support and the role of uncertainty quantification, in a setting where AI agents are the central actors. We propose a framework for strategic decision support for AI agents through an optimization problem that minimizes support usage subject to controlling a counterfactual missed-support error: the probability that the agent acts alone on instances where support would have materially improved its output. At the population level, we show that the optimal policy is a threshold rule on the value of support. Building on this structure, we develop an online algorithm that adaptively thresholds such a score and uses randomized exploration to control missed-support error without distributional assumptions. We further introduce a calibration-on-the-fly method that reduces unnecessary support calls online. We instantiate this framework across diverse scenarios, including information gathering, human--AI collaboration, and tool use, showing how each can be modeled through the same strategic decision-support lens. Experiments across these settings show that our method reliably controls the target error while substantially reducing support usage in practice.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Strategic Decision Support for AI Agents”
What is this paper about?
This paper is about teaching AI agents when to ask for help. Today, AIs often act on their own (like writing code, answering questions, or planning tasks), but sometimes they need support—from a person, a tool (like a calculator or database), or extra information. The tricky part is deciding when to act alone and when to pause and get help, because asking for help can be slow or costly, but not asking can lead to big mistakes.
The authors build a system that helps an AI make that choice in a smart, reliable, and efficient way.
What questions does the paper try to answer?
- When should an AI act by itself, and when should it ask for help?
- How can we keep the number of help requests low (to save time and cost) while making sure the AI doesn’t skip help in moments when help would have fixed a mistake?
- Can we give guarantees that the AI won’t “miss help” too often, even while it’s learning on the fly?
- Can the same idea work across many situations, like using tools, asking humans questions, or gathering extra information?
How did they do it? (In everyday language)
Think of an AI like a student working on homework:
- Acting alone is like solving a problem without asking anyone.
- “Support” is like asking a teacher, checking a calculator, looking up a fact, or asking a classmate.
Two key ideas:
- Value of support: On a given problem, would asking for help actually make the answer better?
- Missed-support error: How often did the AI choose not to ask for help even though help would have improved the answer? This is the error we want to keep small.
The authors set up a goal:
- Use help as rarely as possible.
- But keep the missed-support error under a target you choose (for example, “at most 10% of the time we skip help that would have helped”).
They prove that the best strategy looks like a simple rule:
- If the “value of support” is above a certain threshold, ask for help; otherwise, go solo.
Of course, the AI doesn’t magically know the exact “value of support.” So the authors design an online (learn-as-you-go) algorithm called SOS:
- It gives each situation a score (a guess of how helpful support would be).
- It sets and updates a threshold for when to ask for help.
- It sometimes asks for help even when the score is low (like flipping a coin) to check if its guess is right. This “random check” is important, because you only learn whether help would have improved the answer when you actually ask for help.
- It keeps adjusting both the threshold and the scoring so that, over time, it becomes better at asking for help only when it’s worth it. They call this “calibration-on-the-fly.”
In short: score the situation, compare to a threshold, sometimes explore, learn from feedback, and keep your “missed-help” rate under control.
What did they find, and why does it matter?
They tested their method on four kinds of tasks, all using real LLMs:
- Information gathering (medical diagnosis): Should the AI ask for more symptoms/tests?
- Human-in-the-loop planning (home robot): Should the AI ask the resident about room details before planning actions?
- Human–AI collaborative reasoning (math): Should the AI ask for a hint on a tricky step?
- Tool use (databases): Should the AI run a SQL query instead of guessing?
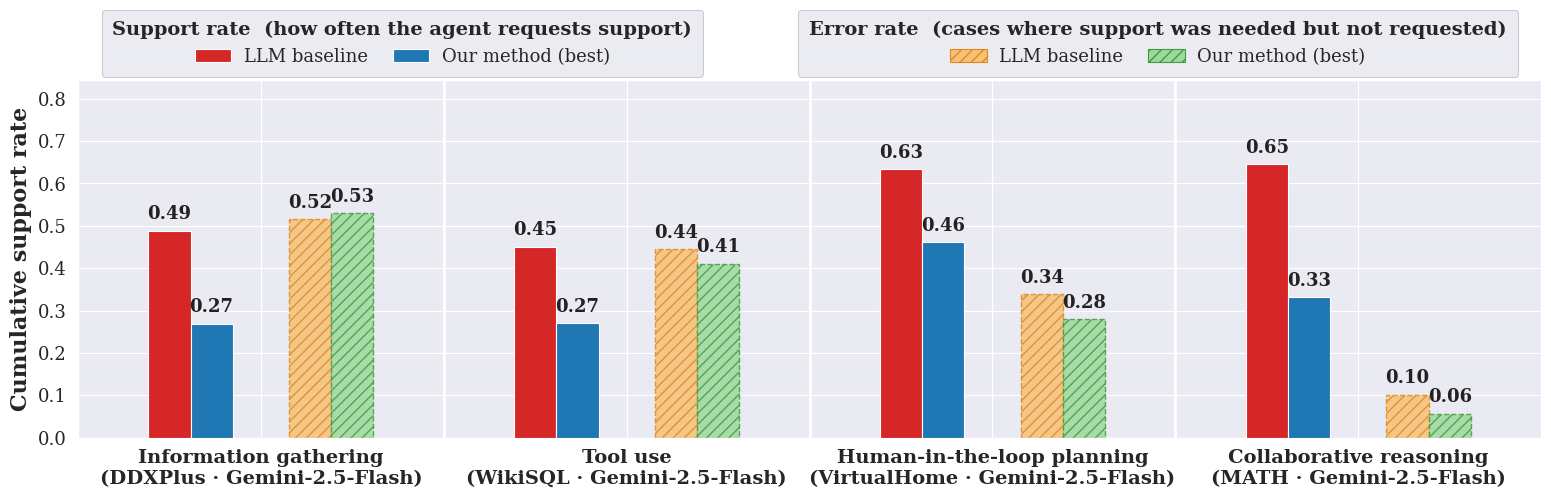
Across these tasks, their algorithm:
- Kept the missed-support error at or below the chosen target (so it rarely skipped help when help mattered).
- Asked for help significantly less often than a strong baseline where the AI decides on its own when to ask. In other words, it saved cost/time without increasing important mistakes.
Why this matters:
- In real life, unnecessary help calls can be expensive (human time, money, latency).
- Missing needed help can cause serious errors (bad medical advice, broken code, wrong financial actions).
- Their method balances these two in a principled, guaranteed way.
What could this change in the real world?
- Safer AI assistants: The AI can stick to acting alone most of the time, but still avoid skipping help in risky moments.
- Lower cost and faster responses: Fewer unnecessary tool calls or human escalations.
- Works across many settings: Asking a person a question, calling a tool, or gathering extra evidence can all be handled with the same “when to ask” strategy.
- Reliable oversight: Teams deploying AI can set a target for how often it’s okay to miss needed help and get a method that respects that target while learning online.
A few helpful terms in plain words
- Support: Any extra help the AI can get—human input, tools, or more data.
- Value of support: How likely it is that asking for help will improve the AI’s answer.
- Missed-support error: Times the AI didn’t ask for help but help would have improved the result. This is the error the method controls.
- Threshold rule: Ask for help if the “value” (or score) is above a line; otherwise, don’t.
- Online algorithm with exploration: Learns while working; occasionally asks for help even when it “thinks” it doesn’t need to, just to keep learning and stay accurate.
- Calibration-on-the-fly: Continuously adjusts its scoring so predictions match reality better over time.
Final takeaway
The paper gives AI agents a smart “ask-for-help” button. It learns when help is truly worth it, guarantees that the AI won’t skip needed help too often, and cuts down on wasteful help requests. That makes AI systems both safer and more efficient in everyday use.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions that remain unresolved by the paper:
- Multiple support modalities and variable costs: Extend SDS-Opt beyond a single binary “seek support” action to handle multiple support options with heterogeneous, instance-dependent costs and benefits; derive the corresponding optimal policy and online guarantees.
- Continuous notions of value: Replace the binary g with a continuous “material improvement” measure and develop algorithms/theory that threshold the expected improvement; prove the analogue of Theorem 3.1 and finite-sample control for continuous outcomes.
- Unreliable or harmful support: Model variability in support quality (e.g., human error, tool failures) and design oversight that accounts for support uncertainty, including safeguards when support can degrade performance.
- Counterfactual identification gap: Bridge the mismatch between the controlled empirical error (computed only on supported rounds) and the true population missed-support error; provide unbiased/low-variance estimators and finite-sample bounds under partial feedback.
- Near-optimality of support usage: Provide guarantees (e.g., regret or optimality gap) that SOS attains near-minimal support rate among all policies satisfying a given missed-support constraint.
- Adaptive exploration with guarantees: Replace fixed μ with principled, data-driven exploration schedules (e.g., annealing or adaptive control) that maintain finite-sample error control while reducing exploration cost.
- Nonstationarity and drift: Analyze and detect distributional drift in P_X, the agent, and the support mechanism; design controllers or change-point methods that preserve error control under nonstationary streams.
- Multi-turn/stepwise support: Generalize from a single binary decision to multi-turn, hierarchical support decisions within tasks (e.g., multiple clarifications), with cumulative error control and budget management across steps.
- Early/partial-generation decisions: Formalize and evaluate when to decide before generating y0 (or after partial generation), incorporating compute/latency costs and their impact on guarantees and performance.
- Score learning theory: Establish convergence and calibration guarantees for the on-the-fly, importance-weighted score updates; study variance reduction, robust losses, and representation learning beyond linear probes.
- Robustness and adversarial inputs: Provide worst-case or adversarial robustness guarantees for missed-support control and support usage; study failure modes under adversarial query distributions.
- Fairness and subgroup guarantees: Measure and constrain missed-support error and support rates across subpopulations (e.g., demographics, task types); develop fairness-aware oversight with formal guarantees.
- Privacy and safety constraints: Incorporate privacy budgets and data leakage risks into the support decision (especially for human-in-the-loop); design oversight that respects privacy/safety constraints while maintaining error control.
- Resource- and latency-aware oversight: Move beyond frequency as cost to include per-instance latency, price, human effort, and queueing effects; develop budgeted or online primal–dual methods with performance guarantees.
- Tool and infrastructure failures: Model and handle intermittent tool outages, API errors, or partial responses; integrate uncertainty about Y1 into g and the decision rule.
- Ground-truth scarcity and subjective “material improvement”: For tasks without verifiable answers, devise label-efficient ways to estimate g (preferences, pairwise judgments, weak supervision) with guarantees under noisy evaluators.
- Broader empirical comparisons: Benchmark against stronger inference-time baselines (e.g., expected value-of-information, verification-triggered policies, retrieval gating) and vary α to produce full cost–error tradeoff curves.
- Hyperparameter self-tuning: Develop principled, automatic selection of η, γ, λ1, and μ with theoretical safety (e.g., anytime bounds) and practical procedures that respect support budgets.
- Population-level guarantees: Strengthen Theorem 4.1 to provide unconditional or PAC-style guarantees not conditioning on N_g(T), and address regimes where beneficial rounds are rare.
- Relaxing α < 1 − μ: Remove or mitigate the requirement α < 1 − μ via alternative update rules or control schemes that allow any user-chosen α ∈ (0,1).
- Fleet-level oversight: Coordinate oversight across multiple agents sharing limited human/tools capacity; design schedulers that maintain global error control under resource constraints.
- Interpretability and transparency: Provide human-understandable explanations for why support was sought or skipped, and study how this affects trust and alignment in real deployments.
- Real-world deployments beyond LLM benchmarks: Validate in robotics, code execution, and live user studies where support is costly, noisy, and time-constrained; measure downstream task outcomes and user satisfaction.
Practical Applications
Immediate Applications
The paper introduces a deployable oversight layer (SOS) that wraps existing AI agents to decide when to seek support (human, tools, retrieval) while controlling a user-chosen “missed-support error” rate. It works with both black-box and white-box models, requires no distributional assumptions, and includes an online calibration mechanism. The following applications can be built now with standard engineering effort.
Healthcare
- Clinical decision support triage
- Use case: A diagnostic assistant decides when to request additional tests, gather history, or escalate to a clinician. The value-of-support estimate is derived from features of the case and the model’s initial draft diagnosis.
- Product/workflow: An EHR-integrated “α-gated” CDS layer that triggers follow-up questions or clinician review only when the expected benefit crosses a learned threshold; dashboards to monitor missed-support error and support rates.
- Dependencies/assumptions: Reliable support channels (clinician availability, test ordering), an operational definition of g (e.g., unsupported wrong vs. supported correct diagnosis), audit logging, HIPAA compliance, and accepted escalation SLAs. Randomized exploration should be sandboxed or simulated for safety-critical contexts.
- Patient-facing symptom triage bots
- Use case: Triage bot determines when to ask clarifying questions (e.g., red-flag symptoms) before advising care level.
- Product/workflow: A “clarify-when-it-helps” module embedded in patient portals or payor apps that targets a missed-support error α agreed with clinical governance.
- Dependencies/assumptions: Clear red-flag definitions and outcome labels, privacy safeguards, and human handoff routes.
Software and Data/Analytics
- Cost-aware tool calling for RAG and SQL agents
- Use case: LLM agents decide when to query vector stores, call search, or execute SQL; trigger only when support is likely to materially change the answer.
- Product/workflow: An SOS “Tool Gate” middleware for LangChain/LlamaIndex that reduces external calls while matching a target missed-support error; telemetry for per-tool α.
- Dependencies/assumptions: Connectors to tools, a proxy for g (e.g., supported answer matches reference; for BI, exact-match or tolerance windows), and API quota monitoring.
- Safe code execution and testing for coding copilots
- Use case: Decide when to run snippets in a sandbox, invoke static analysis, or expand test coverage.
- Product/workflow: A “Safe Exec Gate” GitHub Action that gates code execution/testing and escalates code review for risky changes; α exposed as a policy knob per repo.
- Dependencies/assumptions: Secure sandboxing, compute budgets, test oracles/linters to assess g, and incident/audit logging.
Customer Operations
- Human escalation in customer support bots
- Use case: Bots determine when to transfer to human agents to avoid unresolved or sensitive cases.
- Product/workflow: An “α-Escalation Controller” that reduces overload on agents while maintaining resolution/SAT targets; real-time dashboards for α and support rate.
- Dependencies/assumptions: Clear success metrics to define g (e.g., resolution correctness), workforce routing, and PII handling.
Robotics and IoT
- Ask-the-user protocols for home/warehouse robots
- Use case: Robots request environment-specific constraints (fragile items, restricted areas) only when it likely improves plan quality.
- Product/workflow: A “Resident/Operator Query Gate” that triggers queries to users or teleoperators; plan-quality metric (e.g., LCS overlap) to instantiate g.
- Dependencies/assumptions: Low-latency user interface, teleop availability, plan-quality proxies, and safety interlocks.
Education
- Intelligent tutoring systems with targeted hints
- Use case: A tutor decides when to fetch hints, worked steps, or teacher verification.
- Product/workflow: A “Hint Gate” that minimizes hint usage (cost/time) at fixed learning-quality α; progress analytics per learner.
- Dependencies/assumptions: Ground-truth answers or reliable verifier, pedagogical policy for what counts as “material improvement,” and consent for exploration on formative tasks.
Finance and Risk
- α-gated human-in-the-loop for high-stakes actions
- Use case: Payment/workflow agents escalate wire transfers, contract edits, or policy changes when oversight likely alters the outcome.
- Product/workflow: A “Compliance Gate” sitting before execution systems; α tuned to risk appetite; record of g evaluations for audits.
- Dependencies/assumptions: On-call compliance/legal reviewers, well-scoped action space, clear outcome labels for g, and strict access controls.
Platform and MLOps
- Oversight middleware and dashboards
- Use case: Centralized service wraps multiple agents, controlling α and surfacing support load and missed-support trends.
- Product/workflow: An “SOS Router” SDK and an “Oversight Ops” dashboard; per-agent α; per-support modality statistics; alerting on drift.
- Dependencies/assumptions: Event logging pipeline, feature store for scores, and operational SLOs for support latency.
- Cost optimization for API-heavy agents
- Use case: Reduce external API spend (search, vision, code execution) while holding missed-support error fixed.
- Product/workflow: A procurement-facing report showing savings attributable to SOS and α control.
- Dependencies/assumptions: Cost accounting per tool, stable definition of g, and buy-in on exploration overhead.
Long-Term Applications
The framework naturally extends to richer settings (multiple supports, heterogeneous costs, safety-critical domains) but requires additional research, validation, or infrastructure.
Safety-Critical Autonomy
- Teleoperation gating for AVs, drones, and surgical robots
- Vision: Call human operators when oversight will likely prevent an error; calibrate α by scenario (weather, proximity to hazards).
- Potential tools/workflows: Real-time SOS integrated with perception/planning stacks; event buffers to compute g from near-miss/simulator rollouts.
- Dependencies/assumptions: Ultra-low-latency comms, strong simulators to approximate g, validated risk metrics, regulatory approvals; randomized exploration must be virtualized.
Healthcare Systems
- System-wide α-governed escalation policies
- Vision: Hospital-wide policy that sets different α for triage, imaging, discharge summaries; joint optimization of human workload and risk.
- Potential tools/workflows: Governance cockpit to allocate α-budgets across services; staffing models informed by observed support demand.
- Dependencies/assumptions: Interoperable EHR integration, RCTs or robust observational studies, safety committees, and medico-legal frameworks.
- Continuous value-of-support modeling with outcomes
- Vision: Replace binary g with utility (e.g., expected harm reduction) and optimize under cost/risk constraints.
- Dependencies/assumptions: Longitudinal outcome data, causal adjustment, and ethical review.
Multi-Support and Cost-Aware Optimization
- Portfolio selection among support options
- Vision: Choose among humans, tools, retrieval, or ensembles with different costs and reliabilities; extend SDS-Opt to multi-action cost-sensitive optimization.
- Potential tools/workflows: Bandit/RL extensions; per-option α or global constraints; SLAs with support providers.
- Dependencies/assumptions: Calibrated per-option g estimates and cost models; scheduler for contention.
Policy and Governance
- Certifiable oversight guarantees
- Vision: Regulators require documented α-level missed-support control for consumer-facing AI; standardized audit artifacts and tests.
- Potential tools/workflows: Conformance test suites; signed logs of g-evaluated episodes; third-party certification.
- Dependencies/assumptions: Sector-specific g definitions, privacy-preserving logging, and legal clarity on randomization.
- Fairness-aware oversight
- Vision: Group-conditional α or constraints to ensure equitable support and error control across demographics or regions.
- Potential tools/workflows: Subgroup tracking of MSE, per-group thresholds, fairness-constrained optimization.
- Dependencies/assumptions: Availability and governance of sensitive attributes, fairness definitions, and bias audits.
Enterprise AI Orchestration
- Marketplaces and pricing for “Support-as-a-Service”
- Vision: External support providers (verification APIs, expert markets) priced by marginal improvement; α-bound SLAs.
- Potential tools/workflows: Usage-based billing tied to realized g; broker that optimizes support portfolio under budget.
- Dependencies/assumptions: Standardized interfaces for g reporting, trusted measurement, and billing integration.
- Training-time integration
- Vision: Train agents to produce better value-of-support scores s(x) and align internal uncertainty with SOS thresholds.
- Potential tools/workflows: Joint training with auxiliary losses on g prediction; curriculum that simulates support interventions.
- Dependencies/assumptions: Labeled or weakly-supervised g data, compute budgets, and stability analyses.
Science and Industrial Automation
- Lab automation and process control
- Vision: Robotic labs or industrial processes request expert review or high-fidelity assays only when it changes outcomes materially.
- Potential tools/workflows: SOS gates before costly experiments; continuous g derived from yield/purity/defect rates.
- Dependencies/assumptions: High-quality sensors, delayed feedback handling, and safety gates for exploration.
Content Safety and Moderation
- Escalation to human moderators with certified misses
- Vision: Platforms commit to a maximum missed-escalation rate α for harmful content categories.
- Potential tools/workflows: Category-specific α; human queues sized by observed support rate.
- Dependencies/assumptions: High-quality labels, appeal/audit processes, and transparency reporting.
Personal and Daily-Life Assistants
- Ask-before-commit for high-impact tasks
- Vision: Assistants manage bookings, finances, and smart-home actions; they ask for confirmation or extra context only when it likely averts an error.
- Potential tools/workflows: “Confirm Gate” on sensitive actions; user-adjustable α and preferences.
- Dependencies/assumptions: Clear definitions of material improvement (g) for personal tasks, user consent for data collection, and on-device privacy.
Assumptions and dependencies common across applications:
- Defining “material improvement” g: Needs a task-specific, auditable criterion (ground truth, verifier, or quality metric).
- Availability and reliability of support: Humans, tools, or retrieval must be accessible with known costs/latencies.
- Exploration trade-offs: Online guarantees rely on some randomized exploration; in safety-critical contexts, use simulation, shadow modes, or constrained exploration.
- Instrumentation and logging: To track MSE, support rate, and calibrate scores; required for dashboards, audits, and drift detection.
- Nonstationarity: Score calibration and thresholds must adapt to changing data—SOS supports this via online updates, but monitoring is essential.
- Privacy, security, and compliance: Especially where human support or sensitive data are involved (healthcare, finance, moderation).
Glossary
- Agentic systems: AI setups where agents autonomously act on behalf of users. "In modern agentic systems, this division of roles is increasingly reversed: AI agents act on behalf of users, while humans and tools becomes support mechanisms around them."
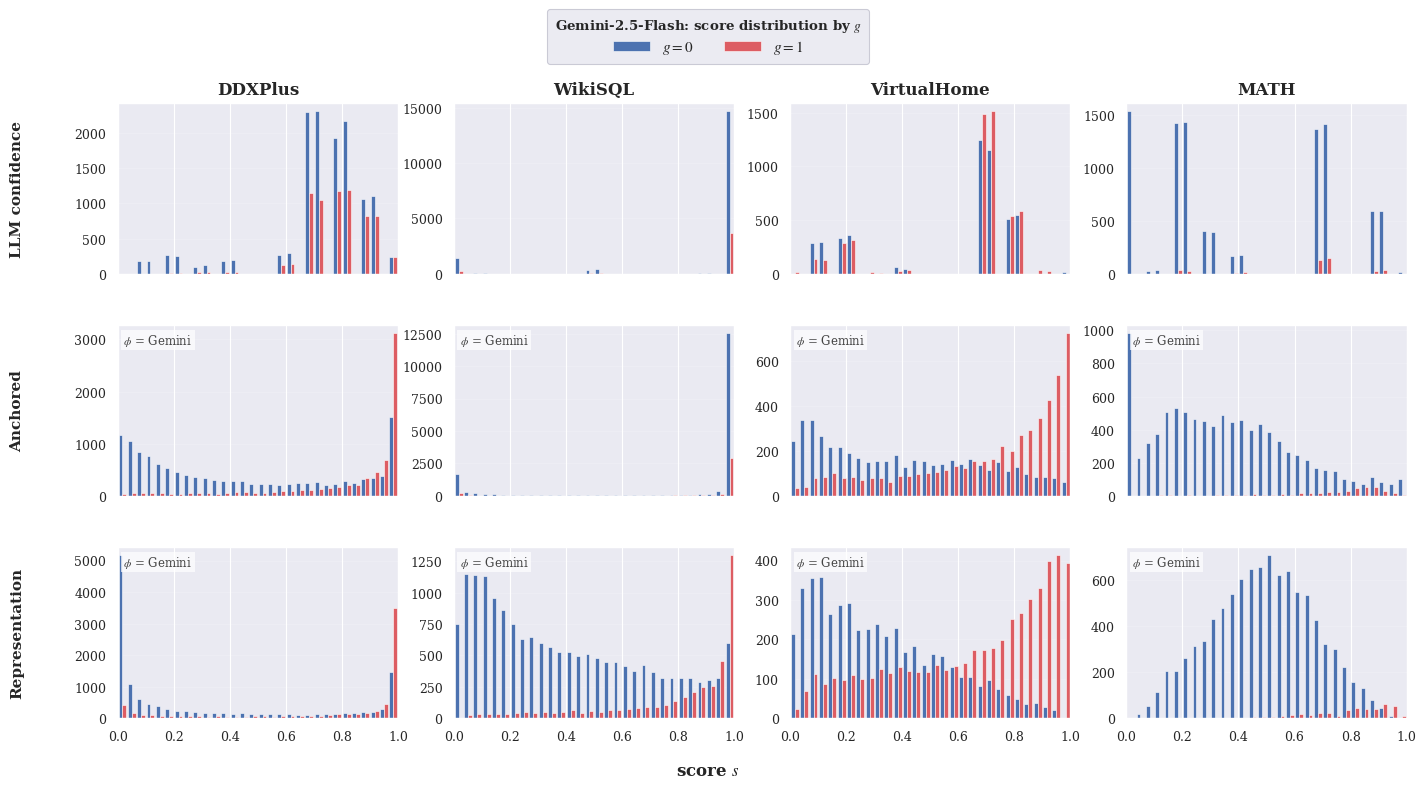
- Anchored score: A scoring method that adds a learned residual to an initial signal (anchor) in logit space. "Anchored score. The final family combines the parameterized linear term with the black-box signal in logit space:"
- Black-box (BB): A setting where model internals are inaccessible; only inputs/outputs are used (here, via a separate frozen encoder). "Black-box (BB) variants apply a separate frozen encoder to the input; the white-box (WB) variant uses the LLM's own hidden state at the final input token."
- Calibration-on-the-fly: An online procedure that updates score parameters using feedback during deployment. "We further introduce a calibration-on-the-fly method that reduces unnecessary support calls online."
- Counterfactual missed-support error: The probability that the agent fails to seek support on instances where support would have improved the output; only observable if support is called. "subject to controlling a counterfactual missed-support error: the probability that the agent acts alone on instances where support would have materially improved its output."
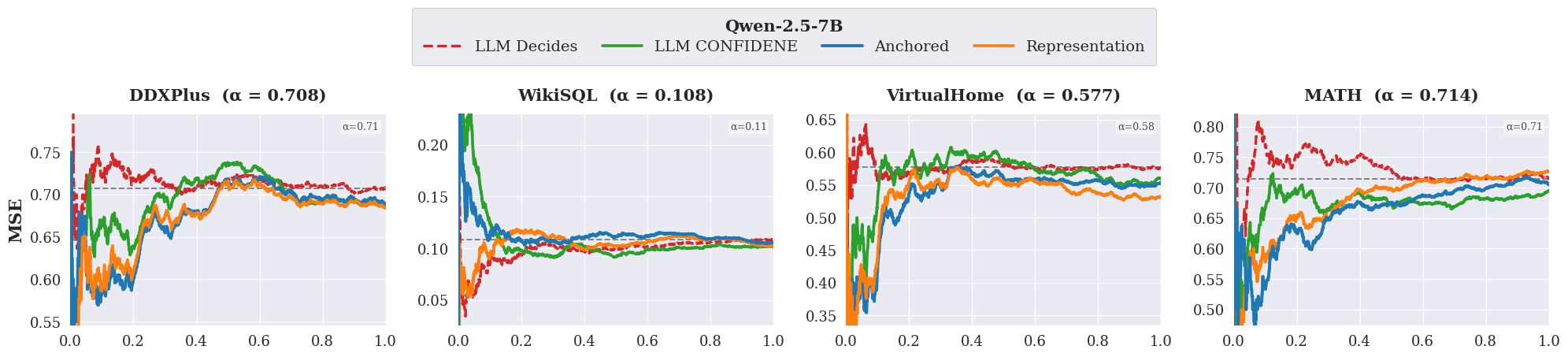
- Distribution-free finite-sample guarantee: A performance bound that holds for finite samples without relying on data distribution assumptions. "The next result shows that the threshold update rule in Algorithm~1 yields a distribution-free finite-sample guarantee for controlling the empirical missed-support error."
- Distributional assumptions: Assumptions about the underlying data-generating distribution. "uses randomized exploration to control missed-support error without distributional assumptions."
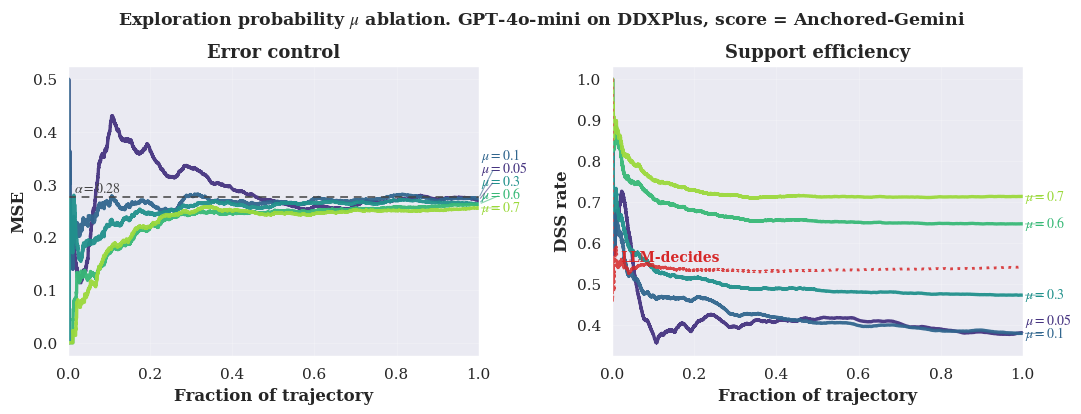
- Exploration parameter: A probability used to randomly seek support below the threshold to gather feedback. "where is a fixed exploration parameter."
- Human–AI collaborative reasoning: A setting where an AI agent and a human (or stronger reasoner) collaborate, with targeted guidance on uncertain steps. "Human-AI collaborative reasoning on Level 4--5 problems from MATH"
- Human-in-the-loop planning: A setting where human input provides context or constraints to improve an agent’s plan. "Human-in-the-loop planning on VirtualHome"
- Importance-weighted correction: An adjustment that accounts for randomized action probabilities to keep updates unbiased. "The prefactor then serves as an importance-weighted correction for the fact that is observed only on rounds where support is sought."
- Linear probe: A simple linear model trained over fixed representations to predict a target property. "This is a linear probe over a representation that summarizes the input; calibration-on-the-fly learns which directions in representation space predict whether support helps."
- Longest-common-subsequence (LCS): A sequence similarity metric used to compare action plans. " when the longest-common-subsequence (LCS) overlap of with the gold action sequence exceeds that of ."
- Logit space: The space of log-odds used to combine probabilistic signals additively. "logit space: ."
- Missed-support error: The error measuring cases where support would have helped but was not sought. "For a strategy , we therefore define the missed-support error as"
- Online algorithm: An algorithm that makes decisions and updates sequentially as data arrives. "we develop an online algorithm that adaptively thresholds such a score and uses randomized exploration to control missed-support error without distributional assumptions."
- Online quantile-tracking: A procedure to adapt a threshold so that a target quantile level is maintained. "This update resembles online quantile-tracking:"
- Oversight layer: A supervisory mechanism that decides when an agent should seek support. "through an oversight layer with rigorous finite-sample error control."
- Population-level formulation: An optimization defined over the underlying distribution rather than individual samples. "we arrive at the following population-level formulation."
- Randomized exploration: Intentional randomization of actions to obtain feedback on otherwise unobserved outcomes. "uses randomized exploration to control missed-support error without distributional assumptions."
- Strategic Decision Support Optimization (SDS-Opt): The paper’s optimization problem balancing support usage with a constraint on missed-support error. "Strategic Decision Support Optimization"
- Strategic Oversight for Support-seeking (SOS): The proposed online algorithm that decides when the agent should seek support. "Strategic Oversight for Support-seeking (SOS), an online algorithm for deciding when an AI agent should seek support."
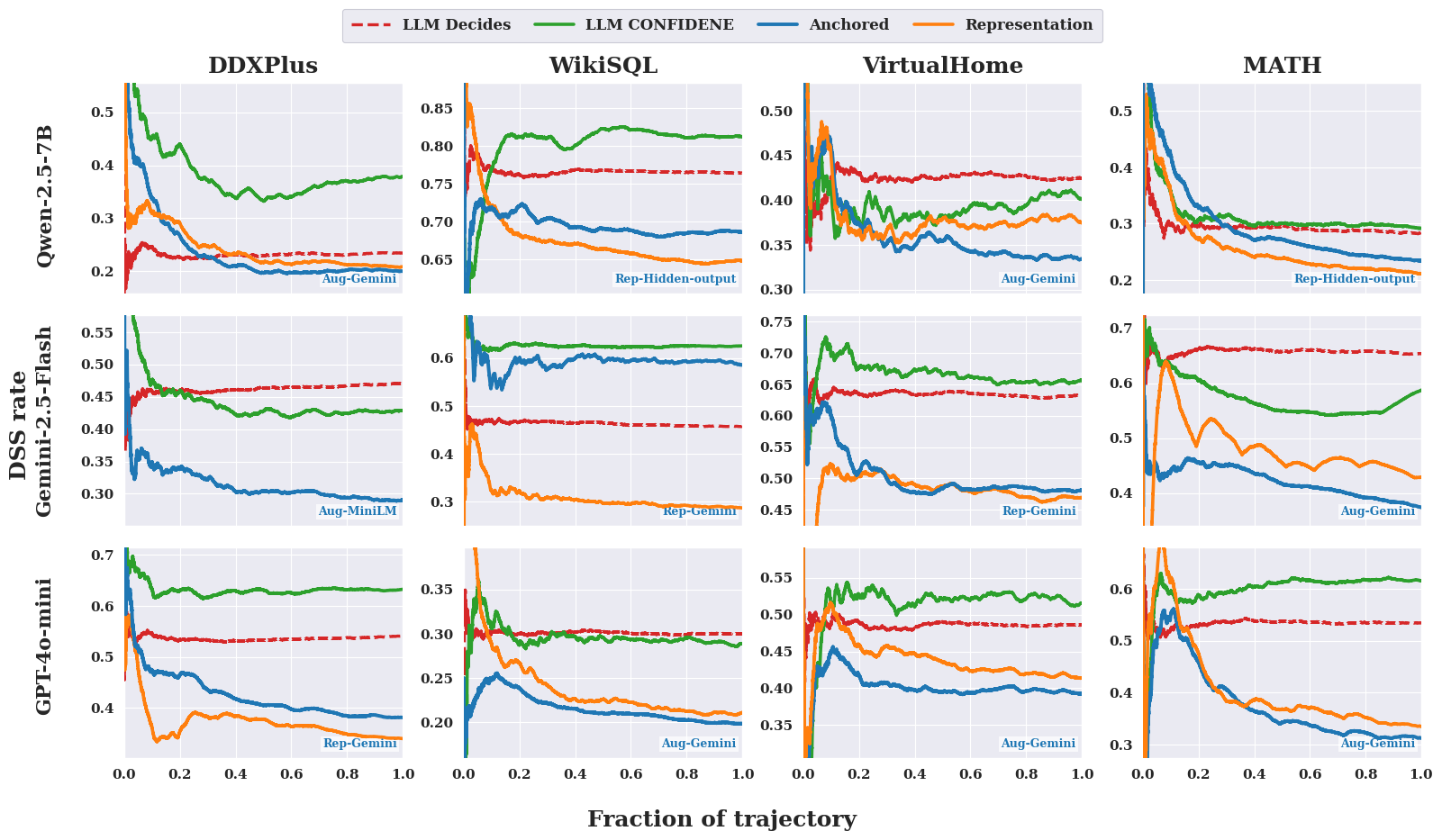
- Support rate: The frequency with which support is invoked; used as a proxy for cost. "we measure the cost of a strategy by its support rate"
- Threshold rule: A policy that seeks support when a score exceeds a chosen threshold. "the optimal policy is a threshold rule on the value of support."
- Value indicator: A binary variable signaling whether the supported output is materially better than the unsupported one. "We begin by introducing a value indicator"
- Value of support: The probability that calling support would materially improve an output on a given instance. "This indicator induces the central population quantity in our framework, the value of support,"
- White-box (WB): A setting where model internals (e.g., hidden states) are accessible and used. "the white-box (WB) variant uses the LLM's own hidden state at the final input token."
Collections
Sign up for free to add this paper to one or more collections.