- The paper introduces a statistical framework for adaptive sampling in multi-agent LLM pipelines, ensuring safe self-harm risk screening with formal reliability guarantees.
- It leverages a directed acyclic graph architecture that mirrors clinical workflows, significantly reducing false positives and optimizing computational resources.
- Empirical evaluations on behavioral health datasets validate its theoretical claims, demonstrating lower system-level regret and efficient resource allocation.
Adaptive Multi-Agent LLM Pipelines for Reliable Self-Harm Risk Screening
Motivation and Problem Statement
Self-harm risk screening in behavioral health settings, such as psychiatric intake and crisis response, demands high standards for reliability, safety, and resource efficiency. Existing LLM-based screening systems, including those deployed in hospital settings, often rely on single-agent architectures or heuristic voting over stochastic LLM outputs. These approaches lack formal mechanisms to gauge decision reliability or to control error propagation across multi-agent workflows—a critical gap in safety-critical environments with asymmetric error costs. Specifically, missing actual crisis signals (false negatives) incurs substantial risks, while excessive escalation of benign cases (false positives) overburdens clinicians and induces alert fatigue.
This paper presents a statistical framework for evaluating and deploying multi-agent LLM pipelines, structured as directed acyclic graphs (DAGs), that operationalize clinical SOPs for self-harm risk assessment. Principled adaptive sampling, rather than fixed-sample voting, is introduced to quantify uncertainty and allocate computational resources based on input complexity. Empirical and theoretical results demonstrate substantial reductions in unnecessary escalations, formal guarantees on routing correctness, and favorable system-level regret bounds that scale efficiently with patient volume.
System Architecture and Methodology
The architectural backbone is a DAG pipeline consisting of three specialized agent nodes: Worker, Risk, and Legal. Each node models a distinct stage in clinical triage, mirroring real-world workflow escalation chains. Agents output one of three categorical labels: safe, unsafe, or escalate, as grounded in the Columbia Suicide Severity Rating Scale (C-SSRS) definitions. An input is processed by the Worker node for first-pass screening. If unresolved, escalation proceeds to Risk and potentially to Legal; only intractable cases after all stages are referred to a human clinician for review.
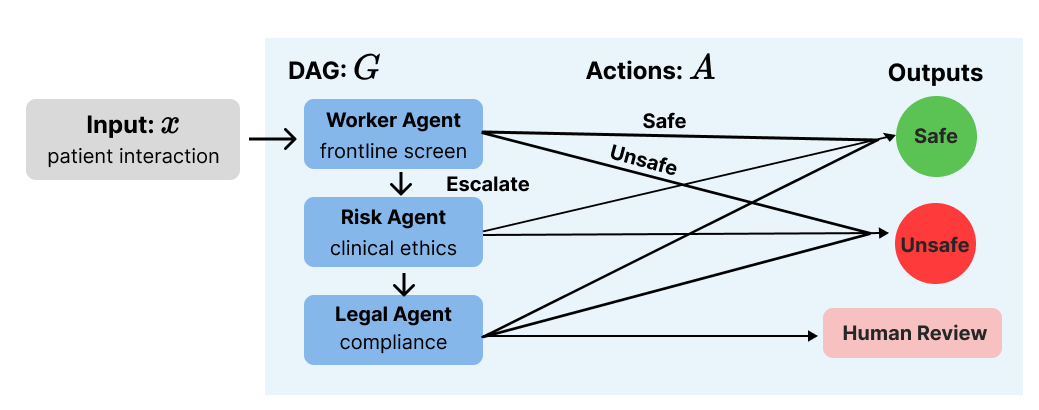
Figure 1: DAG architecture of the multi-agent evaluation pipeline; unresolved inputs are escalated sequentially until a confident decision or human review.
The adaptive sampling algorithm replaces majority voting at each node. Each input is treated as a K-armed bandit problem, where each arm corresponds to a label. LLM API calls provide stochastic samples from each arm. The algorithm eliminates arms as soon as sufficient confidence is obtained, halting early to minimize computation. If budget is exhausted without resolution, escalation occurs to guarantee clinical safety, never forcing a decision when uncertainty remains high.
Theoretical Guarantees
The rigorous statistical treatment utilizes the Dvoretzky-Kiefer-Wolfowitz (DKW) inequality to provide tight confidence bounds across categorical distributions, reducing unnecessary union-bound penalties. Under this formulation:
- Node-level correctness: With probability 1−δ, the adaptive algorithm never commits to a wrong label; escalation is triggered in any remaining uncertainty rather than making a potentially unsafe classification.
- Sample complexity: The required number of pulls depends on the input’s probability gap Δs(x); ambiguous cases require more pulls, with complexity O(ln(1/δ)/Δs(x)2).
- Cumulative regret: System-level regret grows as O(logT) over T deployment episodes, contrasting sharply with linear growth under majority voting. This logarithmic scaling ensures that errors do not accumulate proportionally with patient volume, a crucial property for real-world deployment.
Experiments and Empirical Results
Evaluation spans two datasets: the AEGIS 2.0 behavioral health benchmark and the stratified SWMH Reddit mental health posts, providing broad coverage across clinical and user-generated contexts. Ten system conditions are compared—single-agent, majority vote (various n), and adaptive sampling with varying budgets (B).
Empirical findings highlight:
- False Positive Reduction: Adaptive sampling with B=100 yields a false positive rate (FPR) of 0.095 on AEGIS 2.0, reducing incorrect flagging of safe content by 40% relative to single-agent baselines (FPR=0.159), without increasing false negatives.
- Accuracy: All conditions show similar overall accuracy; adaptive sampling edges out heuristic voting, but improvements are most pronounced in precision (false positive reduction) rather than recall.
- Escalation and Compute Cost: Lower budgets (1−δ0) result in default escalation of all cases, incurring high compute costs with no valid classifications. Adaptive sampling conditions (1−δ1) cluster at 80–90 pulls per input, reflecting the predicted sample complexity thresholds.
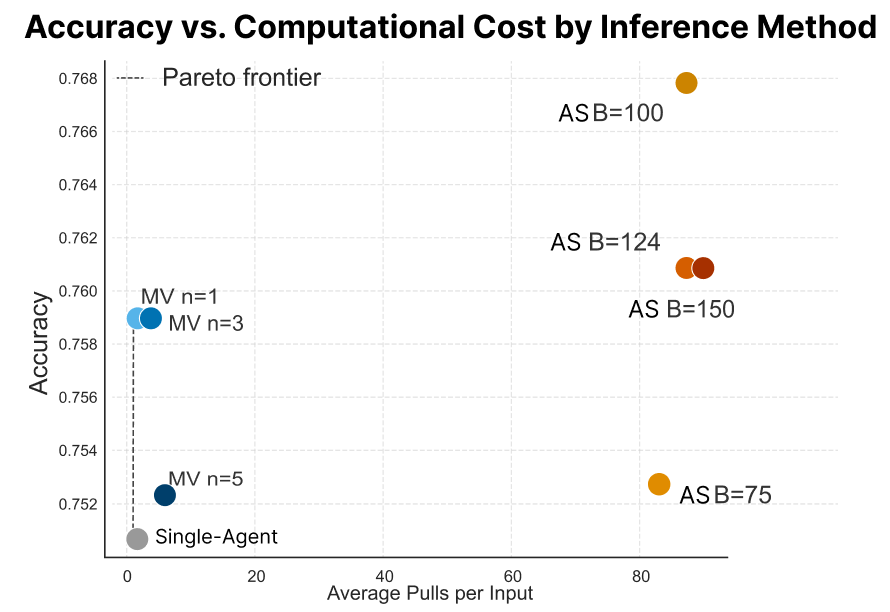
Figure 2: Accuracy versus average pulls per input; adaptive sampling achieves higher accuracy but at substantial compute cost, with the tradeoff being a marked reduction in false positives.
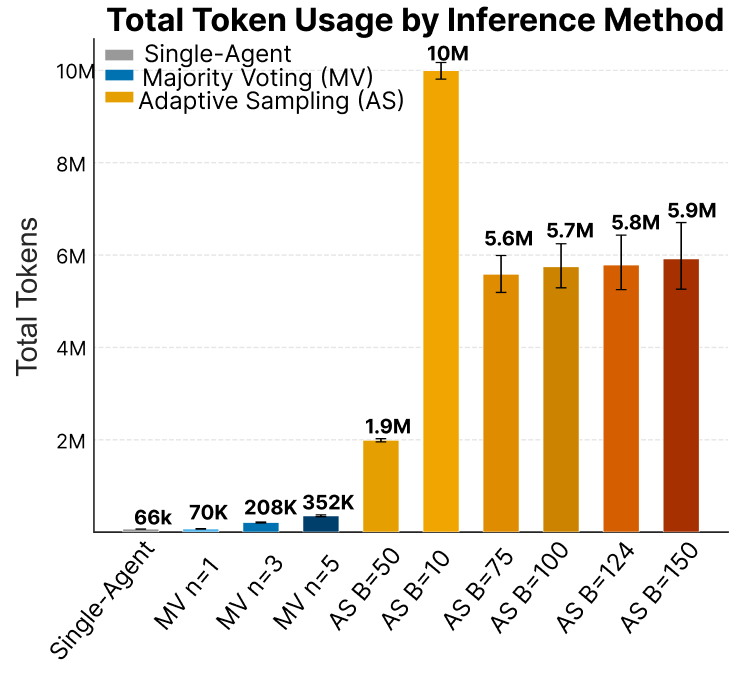
Figure 3: Total token usage by condition; suboptimal budgets exhaust compute resources without producing classified outputs, underscoring architectural inefficiencies when convergence fails.
On the SWMH dataset, adaptive sampling again achieves the lowest false positive rate, though overall FNR is flat, reflecting label ambiguity and annotation noise rather than algorithmic limitations. The false negative floor across all conditions is traced to explicit denials of suicidal intent and posts outside the scope of C-SSRS.
Practical and Theoretical Implications
This work provides actionable design principles for safety-critical clinical AI:
- Explicit quantitative confidence thresholds inform routing and escalation decisions, obviating reliance on fixed heuristics.
- The adaptive approach balances compute resources against input ambiguity, ascending to human review only when automation is unsafe.
- System-level guarantees support accountability and auditing, facilitating regulatory compliance and operational risk management.
Theoretically, the approach demonstrates that adaptive sampling confers logarithmic regret bounds while majority voting remains stuck at linear scaling—implications extend to any multi-agent decision pipeline with categorical action spaces.
Limitations and Future Directions
Key limitations include the compute cost differential: adaptive sampling uses substantially more API calls per input compared to fixed voting, demanding operational trade-offs in real-world deployment. The routing protocol presently passes unresolved cases through subsequent nodes, incurring high computation for ambiguous inputs; early termination would mitigate this inefficiency. Additionally, ground truth annotation remains imperfect, constraining measurement of false negative performance. Future work should refine early stopping mechanisms, distinguish escalation types, and ground benchmarks in clinician-validated standards.
Conclusion
Adaptive multi-agent LLM pipelines, structured as clinical DAGs with principled adaptive sampling, reliably reduce false positives in self-harm risk screening without sacrificing detection of genuine crises. Formal guarantees ensure correct routing and controlled error accumulation. Empirical results and theoretical analysis promise practical improvements for safety-critical AI in behavioral health, though operational cost and annotation quality persist as ongoing challenges. The core insight—that knowing when not to decide is as important as deciding accurately—sets the foundation for both future research and clinical deployment.

