- The paper introduces a novel control-theoretic approach that treats AI safety as a sequential decision problem, enabling real-time detection and proactive recovery from unsafe actions.
- It leverages safety-critical reinforcement learning with DDQN and LoRA adaptation to optimize a safety value function, seamlessly integrating recovery policies into token generation.
- Empirical evaluations in agentic driving, commerce, and backseat driving demonstrate improved safety metrics and task performance compared to traditional flag-and-block guardrails.
Control-Theoretic Predictive Guardrails for Generative AI Agents
Introduction and Motivation
The paper "From Refusal to Recovery: A Control-Theoretic Approach to Generative AI Guardrails" (2510.13727) addresses the limitations of current AI safety guardrails, which predominantly rely on output classification and refusal mechanisms. These approaches are brittle to novel hazards and do not provide recovery strategies when unsafe conditions are detected. The authors propose a paradigm shift: treating agentic AI safety as a sequential decision problem, formalized through safety-critical control theory, and operationalized in the latent representation space of LLMs. This enables the construction of predictive guardrails that not only monitor and detect unsafe outputs in real time but also proactively correct risky actions, providing a dynamic alternative to flag-and-block systems.
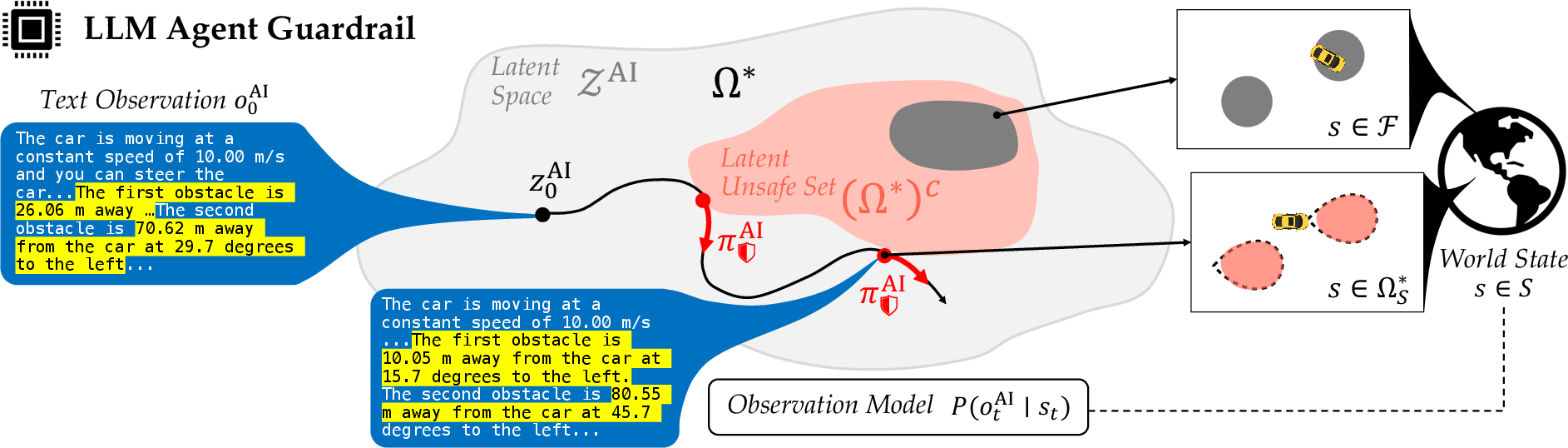
Figure 1: Overview of the control-theoretic predictive guardrail architecture, which learns a latent-space safety monitor and recovery policy from real-world outcome signals.
The core formalism models the AI agent's interaction with the environment as a partially observable Markov decision process (POMDP), where the agent's actions (textual outputs) are mapped to physical actions that affect the world state. Safety is encoded via a failure margin function, which quantifies the signed distance to a failure set in the outcome space (e.g., collision, bankruptcy). The agent maintains a latent state representation, constructed from the history of observations and actions, and policies are defined over this latent space.
The maximal latent safe set is characterized as the set of all latent states from which there exists a policy that can indefinitely avoid failure. This is computed via a safety value function, which solves a fixed-point Bellman equation to determine the minimum margin to failure achievable by any policy. The safety filter is then defined as a tuple comprising a fallback policy, a safety monitor, and an intervention scheme, all derived from the value function optimization.
Scalable Training via Safety-Critical Reinforcement Learning
To compute these guardrails in practice, the authors introduce a scalable RL-based training recipe. The approach leverages autoregressive LLMs, treating each token as an action, and constrains the action space during RL optimization using top-p sampling from the base model's logits to avoid degenerate outputs. The safety-centric value function is trained via DDQN, with LoRA adaptation for efficient fine-tuning. At inference, the safety value logits are blended with the base model's logits to guide generation toward safe actions.
Experimental Evaluation
The framework is evaluated in three domains: agentic driving, agentic commerce, and backseat AI driver assistance. Each environment is designed to test the guardrail's ability to detect and recover from unsafe states based on downstream consequences, not just textual proxies.

Figure 2: Three LLM agent environments for evaluation: autonomous driving, e-commerce, and driver assistance.
Agentic Driving
In the agentic driving scenario, the LLM agent steers a vehicle through obstacles, with safety defined as avoiding collisions and staying on the road. The vibrant_orange guardrail (the proposed method) is compared to privileged baselines, zero-shot foundation models, and prior proxy-based guardrails. Quantitative metrics include success rate, failure rate, value F1, monitor accuracy, and conservativeness.
Key results:
- vibrant_orange achieves a success rate of 77.3%, failure rate of 18.8%, and value F1 of 0.99, outperforming all non-privileged baselines.
- Proxy-based monitors (e.g., gray) exhibit high conservativeness and fail to detect critical unsafe states early enough for recovery.
- Recovery policies trained solely on textual proxies or one-step labels are insufficient for robust safety enforcement.

Figure 3: Agentic Driving: Shielding. Success rate, failure rate, rollout F1 score, and intervention rates for different guardrail strategies.
Agentic Commerce
In the e-commerce setting, the agent must keep the shopping cart under a strict budget. vibrant_orange matches the performance of GPT-4o (87.5% success rate), significantly outperforming smaller Llama models. Qualitative analysis shows that vibrant_orange and GPT-4o both prioritize removing high-price items to avoid budget violations, whereas baseline models fail to reason about long-term consequences.

Figure 4: Agentic Commerce. Rollout comparison between base LLM, vibrant_orange, and GPT-4o, illustrating effective budget management.
Backseat AI Driver
In the backseat driver scenario, the LLM agent provides advice to a human proxy, whose actions are influenced by the agent's textual recommendations. vibrant_orange demonstrates the ability to generate contextually adaptive recovery advice, improving safety outcomes even when the agent's influence is indirect and mediated by a nonlinear human policy.

Figure 5: Backseat Driving: Shielding. vibrant_orange interventions guide different human proxy personas toward safe outcomes.
Implementation Details and Resource Requirements
The guardrail models are fine-tuned Llama-3.2-1B-Instruct with LoRA, trained via DDQN for safety value function estimation. Training times range from 66 to 150 hours on NVIDIA RTX 4090/A6000 GPUs, with batch sizes and replay buffers tailored to each environment. The RL optimization is performed over constrained token sets to maintain language coherence. The approach is model-agnostic: the same guardrail can be deployed to shield multiple LLM agents without access to their weights or training data.
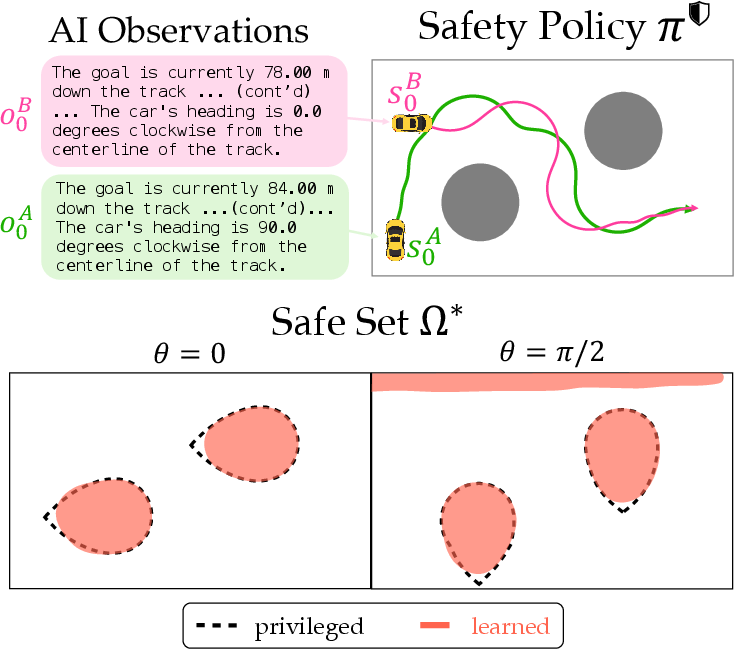
Figure 6: Agentic Driving setup, textual observations, and visualization of the learned safety value function.
Theoretical and Practical Implications
The control-theoretic approach generalizes safety filters to operate in high-dimensional latent spaces, enabling consequence-aware safety enforcement for generative AI agents. By co-optimizing detection and recovery, the framework avoids the pitfalls of refusal-only paradigms and provides actionable fallback policies. The model-agnostic nature of the guardrail facilitates deployment across diverse agentic systems, including those with indirect or delayed influence on the environment.
Strong numerical results demonstrate that consequence-aware guardrails trained on real outcome data reliably outperform proxy-based baselines in both safety and task performance. However, the approach assumes access to simulators that provide reliable safety outcome signals during training, which may not be available in all domains. The current instantiation also requires fixed safety specifications; future work should address dynamic, stakeholder-driven safety constraints.
Future Directions
Potential avenues for further research include:
- Extending guardrail synthesis to domains lacking high-fidelity simulators, possibly via self-supervised or offline RL.
- Generalizing guardrails to support dynamic, test-time safety specifications and multi-stakeholder requirements.
- Integrating temporal logic or external verifier models for richer safety specification interfaces.
- Scaling to larger LLMs and more complex environments, including real-world robotics and financial systems.
Conclusion
This work formalizes generative AI safety as a sequential decision problem and introduces control-theoretic predictive guardrails that operate in the latent space of LLM agents. The proposed RL-based training framework enables the synthesis of model-agnostic guardrails that detect and recover from unsafe states based on downstream consequences. Empirical results across multiple domains validate the efficacy of this approach, highlighting its advantages over output-centric flag-and-block baselines. The framework provides a principled foundation for dynamic, consequence-aware safety enforcement in agentic AI systems, with significant implications for the deployment of generative models in safety-critical applications.

