Building Customer Support AI Agents at 100M-User Scale: An Evaluation-Driven Framework
Abstract: The rapid rise in LLM capabilities has made AI agents increasingly viable across a broad range of tasks. Among the most promising applications is building production-ready customer-facing agents, a challenge that demands coordinated excellence in evaluation methodology, context engineering, training, and online measurement. Yet these critical pillars are typically developed in isolation, creating blind spots that only surface after deployment. In this paper, we present a unified framework that bridges offline development with online impact for customer support AI agents at Nubank, a company with 100M+ users. Our approach integrates several key components: (1) structured context engineering tailored to customer support agents, (2) systematic human-in-the-loop prompt iteration, (3) rigorous LLM judge evaluation with measured inter-rater agreement and GEPA optimization for consistency, and (4) ideation-to-production validation. A central insight is that evaluation-pipeline quality directly determines iteration velocity. We present results from five production deployments spanning distinct domains: card delivery, debt management, credit-limit support, card management, and product explanation. These deployments deliver consistent customer-satisfaction gains while substantially accelerating iteration. In our card-delivery deployment, large-scale A/B testing yields a 37 percentage-point improvement in AI transactional Net Promoter Score and a 29 percentage-point gain in self-service rate over prior agent variants, alongside a strong correlation between offline simulation metrics and online outcomes, demonstrating that eval-driven development reliably predicts production impact. On most use cases, AI satisfaction reaches within a few percentage points of expert human agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper explains how a big bank (Nubank, with over 100 million users) builds helpful, safe, and reliable AI helpers for customer support. The main idea is simple: don’t just build an AI and hope it works—build a full “practice and refereeing” system around it so you can measure quality before and after launch, improve fast, and keep customers happy.
What questions were the authors trying to answer?
- How can we design customer support AIs that are accurate, polite, and safe enough for real customers?
- How do we test these AIs quickly and fairly before putting them in front of users?
- Can our test results in the lab predict what will happen with real customers?
- Will the same approach work across very different support tasks (like card delivery, credit limits, and debt help)?
How did they build and test the AI?
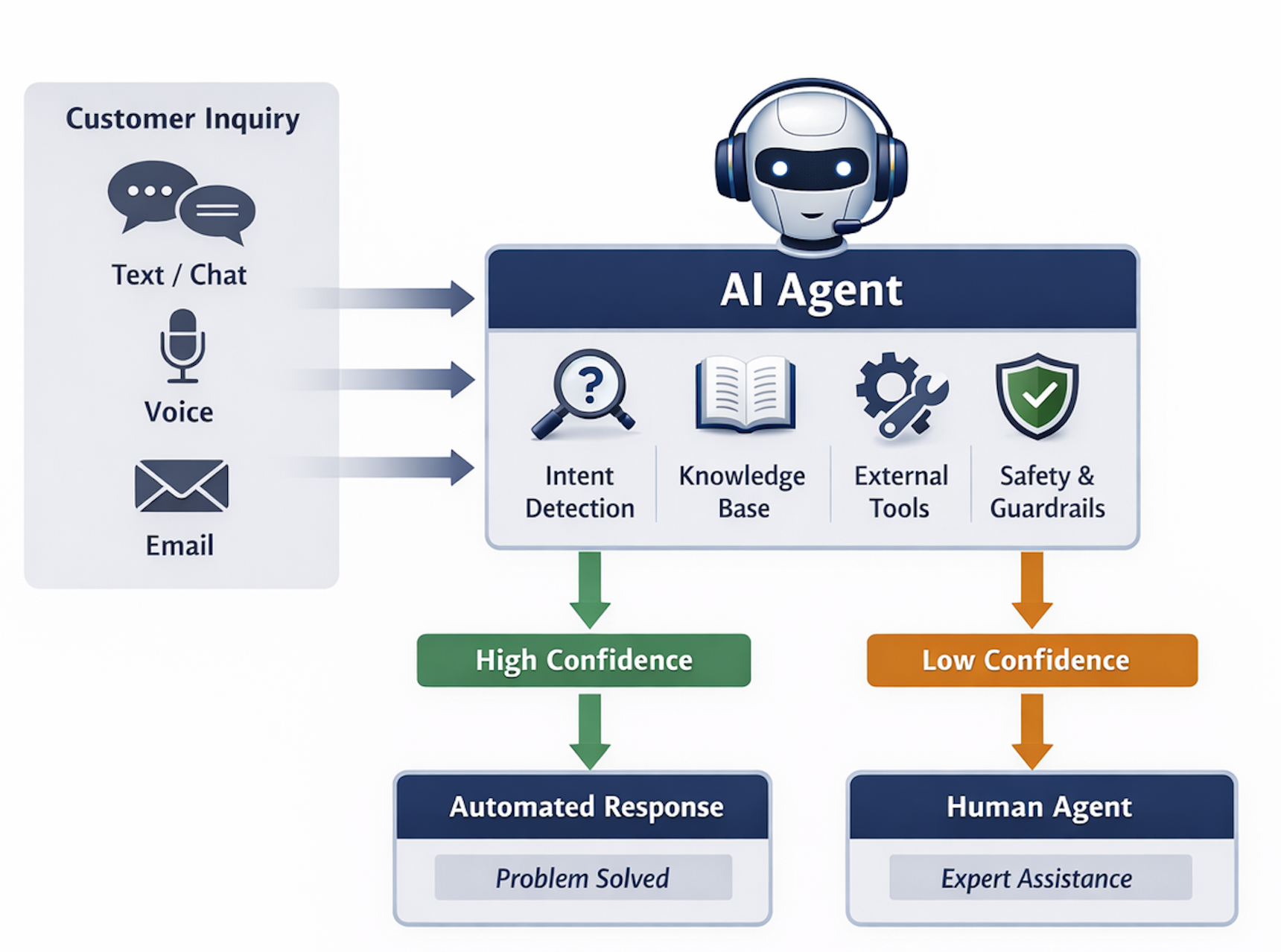
Think of the AI as a smart helper that follows a playbook, can use tools, and knows when to hand off to a human. The authors built both the helper and a whole system to evaluate it.
Building the brain: “context engineering”
Instead of one giant prompt, the AI’s “playbook” is made of clear, swappable parts. This makes it easy to improve one part without breaking everything else. The key parts are:
- Instructions: who the AI is, how it should talk, and what rules it must follow.
- Routines: step-by-step guides based on the company’s standard operating procedures. Example: For “Where is my card?”, steps might include greeting, checking delivery status, asking targeted questions, and offering a reissue if needed.
- Macros: ready-made message templates for common situations that the AI can adapt.
- Tool descriptions: clear, simple “how to use” info for each tool the AI can call, like “check card delivery” or “reissue card.”
- Working memory: the AI’s notes during the conversation so it doesn’t repeat itself or forget details.
Tools and safety rails
The AI can call real company tools to get things done (like checking tracking info or reissuing a card). The team designed these tools to be:
- Safe to retry (so the AI won’t accidentally do the same action twice).
- Simple (only the information the AI needs, not a flood of extra data).
- Clearly described (so the AI knows exactly when and how to use them).
If the AI isn’t confident, or if it hits something unusual, it passes the chat to a human and shares the full context so the user has a smooth experience.
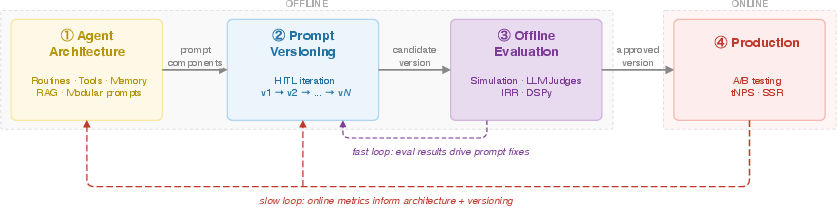
Practicing before the real game: evaluation and A/B tests
Before going live, the AI plays lots of “practice matches.” Its answers are judged in two ways:
- LLM-as-a-judge: A strong AI “referee” scores the helper’s responses using a clear rubric (like correctness, helpfulness, empathy). To avoid bias, the authors:
- Measure agreement between different “referee” AIs. They use an agreement score (like checking how often two referees make the same call beyond chance). Higher agreement means the rubric is clear and fair.
- Improve the rubric automatically with a method called GEPA. Think of GEPA as a coach that watches mistakes, rewrites the judging rules to be clearer, and repeats until referees agree more and match human judgments.
- Human-in-the-loop: Human experts label examples and give explanations, which help train and check the AI referees.
After a version passes offline tests, it goes to a small percentage of real users in an A/B test. Two groups see different versions, and the team compares:
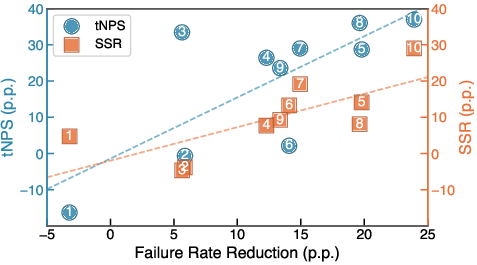
- tNPS (transactional Net Promoter Score): a simple “How happy are you with this support interaction?” score right after the chat.
- SSR (self-service rate): how many people got their problem solved by the AI without needing a human.
If the new version does better, it gets rolled out to more users.
What did they find?
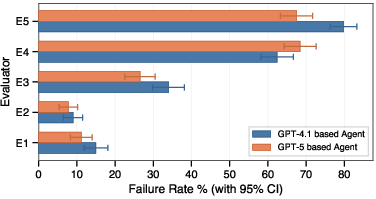
- Big improvements on real customers: In the “Where is my card?” use case, the new AI boosted tNPS by 37 percentage points and raised self-service rate by 29 points compared to older versions. Its customer happiness score came within about 10 points of expert human agents.
- Results across five different support areas: Card delivery, debt management, credit limits, card management, and product explaining all improved, usually getting very close to human-level satisfaction. Debt management is the toughest and still has a bigger gap.
- Lab scores matched real-world results: Versions that scored better in offline tests also performed better with real customers. This means the evaluation pipeline is a reliable predictor, so teams can iterate faster without risking bad live experiments.
- Newer models need clearer instructions: When switching to a newer AI model, the team learned it followed rules more strictly, so they added one clear instruction (“use tools before answering when customer data is needed”), and performance improved.
Why does it matter?
- Faster, safer improvement: Because the offline tests predict real outcomes, teams can make changes quickly and confidently, saving time and avoiding bad user experiences.
- Near-human quality at scale: The AI can handle millions of routine cases well, leaving tricky problems for human experts. This improves customer happiness and reduces costs.
- Works across many tasks: The same build-and-test approach helped in very different support areas, suggesting it’s a general recipe, not a one-off trick.
- Trust and responsibility: The system is designed for secure data handling, clear guardrails, and easy handoff to humans—which is crucial in banking and other sensitive industries.
- A roadmap for others: This paper shows how to connect careful design, solid tools, clear evaluation, and measured rollouts into one loop. The big lesson is that the quality of your evaluation pipeline determines how fast and how well you can improve your AI.
In short, the authors show how to turn customer support AIs from “promising demos” into dependable helpers that make customers happier—by treating evaluation not as an afterthought but as the engine of progress.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved in the paper and could guide future research and engineering work:
- Quantitative scalability: No measurements of latency, throughput, and tail latencies at 100M-user scale, nor their relationship to tNPS/SSR and abandonment rates.
- Cost-performance trade-offs: Absent analysis of inference cost per resolved case, judge-eval costs, and ROI (including sensitivity to model choice, token budgets, and tool-call volume).
- Confidence estimation: The paper references “low confidence” escalation but does not specify how confidence is computed, calibrated, or thresholded, nor how miscalibration impacts case-mix and tNPS.
- Case-mix adjustment: Comparisons between AI and human-agent tNPS lack adjustment for difficulty/acuity; unclear if AI handles easier cases due to confidence-based routing, biasing comparisons.
- Statistical rigor of online results: A/B test sample sizes, confidence intervals, significance tests, and variance over time are not reported for tNPS/SSR gains.
- Offline–online correlation quantification: Correlation coefficients, statistical significance, and confounder controls (e.g., traffic mix shifts, concurrent product changes) are not reported.
- Long-term robustness: No analysis of model/policy drift, seasonality, or product changes on eval reliability and online outcomes; drift detection and continuous revalidation are undefined.
- Multilingual and localization performance: The system serves Brazil and Mexico, yet multilingual accuracy (e.g., PT-BR, ES), code-switching, and locale-specific SOP adaptations are not evaluated.
- Fairness and segment performance: No breakdown by demographics, language, or vulnerable groups; fairness metrics and disparate impact analyses are absent.
- Rare but high-severity failure monitoring: No framework for tracking, analyzing, and preventing low-frequency catastrophic errors (e.g., improper financial actions, privacy leaks).
- Safety and adversarial robustness: Lack of systematic prompt-injection testing, jailbreak resilience, red-teaming protocols, and formal guardrail efficacy metrics.
- Compliance verification: Guardrails are mentioned, but there is no formal verification, policy-checking framework, or compliance incident metrics; obligations under LGPD/GDPR (e.g., purpose limitation, data subject rights) are not operationalized.
- Privacy engineering details: The “privacy by design” section is truncated; specifics on pseudonymization, minimization, retention, consent, and data lineage/auditability are missing.
- Action safety guarantees: No formal methods or transactional safeguards beyond idempotency (e.g., precondition checks, dry runs, compensating actions, or human approval gates for high-risk actions).
- Fault tolerance and resilience: The Product Explainer’s SSR dip due to “transient LLM request failures” reveals a gap in resilience engineering (fallback models, circuit breakers, request hedging, caching) and its evaluation.
- Latency-aware orchestration: No measurements or strategies for batching, parallelization, and tool composition impact on response times and satisfaction.
- Tool correctness and observability: While tool design principles are given, there is no quantitative assessment of tool misuse rates, schema evolution risks, or effectiveness of documentation as “prompts.”
- Memory management and privacy: Working-memory persistence scope, retention policies, and privacy safeguards (e.g., PII redaction across turns/sessions) are unspecified.
- Evaluation dataset scale and coverage: Some evaluators have small datasets (e.g., E2, E5 with 90 samples) and class imbalance; coverage of edge cases and long-tail scenarios is unclear.
- Sample complexity and data efficiency: The claim that “a few hundred labels are enough” is not supported with learning curves or analysis of how label count affects eval reliability and online outcomes.
- LLM-as-judge validity: Agreement is shown across models, but alignment with human judgments (e.g., human–LLM κ/α, calibration curves) is not reported; risk of judges “Goodharting” optimized prompts is not probed.
- Overfitting and eval brittleness: No adversarial/holdout stress tests, rubric-perturbation tests, or cross-domain transfer tests to assess whether GEPA-optimized judges overfit to annotation style or base model idiosyncrasies.
- Minimum reliability thresholds: The paper mentions “minimum human-agreement thresholds” for trusting judges, but specific κ/α cutoffs and enforcement in deployment gates are not disclosed.
- Generalization beyond one enterprise: All deployments are within a single company/vertical; transferability to other domains with different regulations, tools, and customer expectations is untested.
- Vendor dependence: Judge and agent evaluations focus on OpenAI model families; portability to open-source or alternative vendors (and the effect on eval stability) isn’t empirically assessed.
- Modular prompt ablations: The framework claims modular gains (instructions, routines, macros, tool specs, memory) but provides no ablations quantifying each component’s marginal impact on metrics.
- SSR–tNPS trade-off optimization: No principled method (e.g., multi-objective optimization, contextual policies) is provided to tune trade-offs across segments, intents, and risk tiers.
- Human-in-the-loop quality: Handoff quality, human-agent workload impact (AHT, FCR, recontact), and collaboration dynamics (co-pilot efficacy) are not measured.
- Transparency to customers: The paper does not discuss disclosure that users are interacting with an AI agent, perceived trust, or user control mechanisms.
- Security posture: Identity/access controls are mentioned, but there is no analysis of authorization scope creep, lateral movement risk via tools, or runtime policy enforcement beyond docstrings.
- Incident response and auditing: While audit trails are noted, there is no process described for detecting anomalies, triaging incidents, or conducting post-incident root-cause analyses and corrective actions.
- Model upgrade governance: Model migration is treated as prompt changes, but rollback strategies, regression guardrails, and acceptance criteria (including safety) are not formalized.
- Economic sensitivity to outages: No analysis of the business impact of model provider outages, latency spikes, or rate limits, and mitigation strategies at scale.
- Dataset and code availability: Reproducibility is limited—privacy-protected datasets are not released, and GEPA optimization details depend on proprietary models and DPAs.
- Measurement beyond tNPS/SSR: Other critical contact-center KPIs (AHT, resolution time, deflection quality, recontact/return rates, compliance incidents) are not consistently reported across use cases.
- Root-cause analysis of underperforming domains: Debt management shows a larger human–AI gap, but detailed failure taxonomies and targeted remediation strategies are not presented.
Practical Applications
Overview
Based on the paper’s evaluation-driven framework for large-scale customer-support (CS) AI agents—centered on modular context engineering, rigorous LLM-as-judge evaluation with inter-rater reliability, GEPA-optimized rubrics, idempotent action tooling, and progressive rollout—below are concrete applications across industry, academia, policy, and daily life. Each item includes sector links, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
These can be deployed now with current LLMs and standard enterprise infrastructure.
Industry
- Deploy evaluation-driven CS AI agents to increase satisfaction and automation (Finance, Fintech)
- Use cases: card delivery status, card (re)issuance, credit limit explanations, debt management guidance, card management requests, product explanations.
- Tools/products/workflows: SOP-to-routine translation, modular prompt/context versioning (instructions, routines, macros, tool specs, scratchpad), idempotent action APIs (e.g., reissue_card), LLM-judge evals with IRR dashboards, A/B testing, confidence-based escalation, SSR/tNPS analytics.
- Assumptions/dependencies: secure identity/auth (PII access), existing action APIs designed for idempotency and auditability, customer-survey instrumentation for tNPS/CSAT, annotation budget for high-quality eval seeds, data minimization/pseudonymization pipelines.
- Modernize contact centers with agent copilots that draft responses and actions for humans (Telecom, E-commerce, Airlines, Logistics)
- Use cases: plan changes, delivery/return status, baggage claims triage, outage diagnostics, order cancellations.
- Tools/products/workflows: agent copilots integrated into CRMs (e.g., Zendesk/Salesforce), working-memory scratchpad for multi-turn context, macros/templates for consistency, judge-evaluated QA gates before sending responses.
- Assumptions/dependencies: CRM integration, latency budgets for real-time assistance, role-based access and logging, human-in-the-loop workflows.
- Create an EvalOps platform for AI support teams (Software/SaaS, BPOs)
- Use cases: offline eval suites to predict online CSAT/SSR, model/rubric portability checks, inter-model kappa reports, regression gating in CI/CD for agents.
- Tools/products/workflows: LLM-as-judge services with GEPA-optimized rubrics, multi-model agreement monitoring (Cohen’s κ), versioned evaluator library per use case, baseline-to-variant score tracking, offline-online correlation reports.
- Assumptions/dependencies: access to multiple LLMs/vendors, data contracts for processing, standardized rubrics reflecting human policies, organizational buy-in for gates.
- SOP-to-routine compiler and prompt version control (Cross-industry support operations)
- Use cases: codify contact-center SOPs into agent-executable routines with step ordering, branching logic, and guardrails.
- Tools/products/workflows: routine authoring UI, semantic versioning of prompt components, routine-test harnesses, macro libraries, compliance guardrails embedded in instructions.
- Assumptions/dependencies: accurate and up-to-date SOPs, domain experts for review, change-management processes to keep SOPs and routines aligned.
- Safer tool design for LLM agents performing real actions (Payments, Insurance, Utilities)
- Use cases: refunds, claim intake, appointment scheduling, utility plan changes, address updates.
- Tools/products/workflows: composite tools for deterministic sequencing, minimal output schemas, idempotency tokens, explicit tool usage conditions in docstrings, retry logic with clear success signals.
- Assumptions/dependencies: engineering capacity to refactor legacy APIs, legal/compliance sign-off on auditability and retention, observability for tool latency/errors.
- Progressive rollout and governance for agent deployments (Enterprise IT/Operations)
- Use cases: safe 1–5% traffic trials, confidence-based escalation thresholds, automatic rollback on metric regressions.
- Tools/products/workflows: feature flagging, per-variant metric dashboards (tNPS, SSR, escalation rate), guardrails and out-of-scope detection, production evaluation hooks.
- Assumptions/dependencies: experimentation platform, clear SLOs, incident response processes, training for human agents on escalations.
- Model migration playbooks with minimal prompt edits (Any sector using LLM agents)
- Use cases: upgrading from Model A to Model B without breaking behavior (e.g., adding “tool-first” instruction for stricter models).
- Tools/products/workflows: per-model baselines, compatibility tests using offline evals, delta prompts, portability checklists.
- Assumptions/dependencies: model access parity (APIs, rate limits), cost/latency analysis, contract terms for data handling.
- Targeted debt-support flows with empathy and compliance (Finance, Collections)
- Use cases: overdue detection, payment-plan simulation and explanation, hardship flows, context-sensitive messaging.
- Tools/products/workflows: numerical-reasoning evaluators, empathy/clarity rubrics, regulated-language macros, dynamic plan simulators.
- Assumptions/dependencies: regulatory/legal guardrails, accurate simulation engines, policy-aligned phrasing, escalation rules for sensitive cases.
Academia
- Benchmarks and studies on LLM-judge reliability and IRR
- Use cases: measuring cross-model agreement, bias mitigation via rubric optimization, offline-online metric correlation in real CS tasks.
- Tools/products/workflows: open-source evaluator templates (with anonymized task descriptions), κ/α agreement tooling, GEPA recipes, ablation on rubric wording.
- Assumptions/dependencies: access to de-identified datasets or synthetic proxies, IRB/ethics approvals, model access for replication.
- Methodological research on eval-driven development velocity
- Use cases: quantifying how evaluation pipeline quality impacts iteration speed and real-world outcomes.
- Tools/products/workflows: controlled studies comparing manual vs. optimized rubrics, instrumentation for dev-cycle timings, cost-quality-speed trade-off analyses.
- Assumptions/dependencies: collaboration with industry partners, transparent metric definitions, reproducible pipelines.
Policy and Governance
- Enterprise governance templates for AI support agents
- Use cases: IRR thresholds for automated evaluators, required audit trails, idempotency for action tools, human escalation mandates.
- Tools/products/workflows: policy checklists, audit schemas, escalation policies, model migration risk assessments.
- Assumptions/dependencies: cross-functional governance councils, regulator-aligned documentation, training for compliance and operations teams.
- Procurement standards for AI agents in regulated industries
- Use cases: requiring evaluation artifacts (rubrics, IRR scores), offline-online correlation evidence, privacy-by-design controls before purchase/deployment.
- Tools/products/workflows: RFP templates, third-party audits of eval pipelines, conformance testing suites.
- Assumptions/dependencies: vendor cooperation, standardized reporting formats, legal frameworks recognizing such standards.
Daily Life
- Smarter self-service in consumer apps and chat (Banking, Shopping, Telco)
- Use cases: track delivery, replace cards/devices, change plans, dispute charges, schedule installations—resolved without calling support.
- Tools/products/workflows: in-app chat agents with tool-backed actions, empathetic macros, persistent context, clear handoff to humans when needed.
- Assumptions/dependencies: users authenticated in apps, channel availability (mobile/web), robust back-end APIs to enact changes.
- Faster, clearer post-interaction experiences
- Use cases: concise summaries of what was done and next steps; consistent tone and reduced verbosity.
- Tools/products/workflows: conciseness evaluators, response-structure macros, summary delivery via push/email.
- Assumptions/dependencies: notification infrastructure, opt-in preferences, localized language support.
Long-Term Applications
These require further research, scaling, cross-organizational standardization, or regulatory evolution.
Industry
- Cross-domain, generalist support agents with shared routines and tool registries (Retail, Travel, Financial Services)
- Use cases: a single agent handling diverse intents across products and brands with dynamic routine selection and tool orchestration.
- Tools/products/workflows: routine registry/marketplace, automatic routine selection policies, capability discovery, standardized tool schemas.
- Assumptions/dependencies: API standardization across business units, governance for capability exposure, scalable context allocation, robust out-of-scope detection.
- End-to-end operational agents beyond CS (Insurance, Healthcare admin, Government services)
- Use cases: claims pre-adjudication, benefits enrollment, permit applications, KYC remediation—executed with auditable autonomy.
- Tools/products/workflows: multi-step composite tools with transactional guarantees, strong compliance guards, outcome-verification evaluators.
- Assumptions/dependencies: tight integration with core systems, formal verification or deterministic checks, regulatory acceptance of automated decisions.
- Multimodal support (voice + image/video) for troubleshooting and verification (Consumer electronics, Utilities)
- Use cases: diagnosing device issues from photos/videos, reading meters or labels, voice-first support with real-time tool actions.
- Tools/products/workflows: multimodal LLMs, low-latency speech pipelines, photo-based tool triggers, visual-grounding evaluators.
- Assumptions/dependencies: high-quality on-device capture, privacy-aware media handling, bias and safety controls for vision/voice.
- On-device or edge AI agents for privacy and latency (Finance, Healthcare)
- Use cases: sensitive interactions processed locally, with only action intents sent to servers.
- Tools/products/workflows: compact LLMs, federated evaluation updates, encrypted state sync, offline failover routines.
- Assumptions/dependencies: hardware capability on client devices, secure key management, mature on-device model lifecycle.
- Self-healing agents that auto-diagnose and repair failure modes (Any sector)
- Use cases: agents use evaluator feedback to adjust routines/macros, or propose tool/interface changes when failures recur.
- Tools/products/workflows: continuous evaluation streams, automated “reflection” proposals, human-in-the-loop approval pipelines, safe sandboxes.
- Assumptions/dependencies: strong guardrails on autonomous changes, change-management governance, robust rollback mechanisms.
Academia
- Standards and benchmarks for agent evaluation with certified judges
- Use cases: community rubrics for correctness/helpfulness/safety/adherence; cross-model, cross-language IRR baselines.
- Tools/products/workflows: public leaderboards for judge agreement, meta-evaluation datasets, standardized κ/α reporting.
- Assumptions/dependencies: open datasets or high-fidelity synthetic corpora, multi-vendor model access, funding for maintenance.
- Learning routines from interaction logs and SOPs (Program synthesis for agents)
- Use cases: automatically induce routines and macros from successful human-agent transcripts and outcome data.
- Tools/products/workflows: sequence-to-routine compilers, weak supervision from outcomes, counterfactual evaluation.
- Assumptions/dependencies: labeled outcomes at scale, privacy-preserving log access, methods to prevent propagation of bad practices.
Policy and Governance
- Regulatory frameworks specifying minimum evaluation quality for deployed agents
- Use cases: mandated IRR thresholds for automated evaluators, auditability of tool calls, explicit handoff requirements, transparency reports.
- Tools/products/workflows: certification programs, standardized audit artifacts (e.g., tool-call logs with masked PII), regulator-accessible dashboards.
- Assumptions/dependencies: consensus among regulators and standards bodies, harmonization across jurisdictions, industry compliance costs.
- Third-party evaluation and certification ecosystems (“JudgeOps” audits)
- Use cases: independent bodies certify agents’ rubrics, judge stability, and offline-online predictiveness before large-scale deployment.
- Tools/products/workflows: audit protocols, reproducibility kits, red-teaming evaluations for long-horizon reliability.
- Assumptions/dependencies: accredited auditors, legal authority for pre-deployment checks, secure data-sharing frameworks.
Daily Life
- Unified personal support assistants spanning providers
- Use cases: one assistant managing banking, telco, retail returns, travel changes end-to-end, preserving context and preferences.
- Tools/products/workflows: standards for cross-provider routines and consents, wallet for capabilities/permissions, privacy-preserving identity linking.
- Assumptions/dependencies: cross-enterprise interoperability, user-consent UX, liability frameworks for multi-party actions.
- Highly personalized, longitudinal support with proactive guidance
- Use cases: tailored reminders and offers (e.g., debt plan changes, delivery options), empathy calibrated to user history and preferences.
- Tools/products/workflows: long-term working memory with consent, personalization evaluators (satisfaction vs. intrusion), adaptive macros.
- Assumptions/dependencies: clear consent and revocation mechanisms, data-retention policies, fairness and bias monitoring.
Notes on feasibility across applications:
- Data access and privacy-by-design are foundational; consent, minimization, and pseudonymization pipelines are prerequisites in regulated sectors.
- Tooling quality (idempotent action APIs, composite tools, minimized outputs) materially affects reliability and safety.
- Evaluation credibility hinges on IRR thresholds, rubric optimization (e.g., GEPA), and cross-model stability; without this, offline metrics may not predict online impact.
- Experimentation infrastructure (A/B testing, survey instruments like tNPS/CSAT) is needed to close the offline-online loop.
- Cost and latency constraints must be balanced with model choice and prompt design; portability plans reduce vendor lock-in and migration risk.
Glossary
- A/B testing: A randomized online experiment to compare two system variants by splitting traffic and measuring metrics. "In our card-delivery deployment, large-scale A/B testing yields a 37 percentage-point improvement in AI transactional Net Promoter Score and a 29 percentage-point gain in self-service rate over prior agent variants"
- BLEU: A reference-based metric for evaluating generated text by n-gram overlap with references. "Traditional evaluation of natural language generation often relied on reference-based metrics such as {BLEU}~\cite{papineni-etal-2002-bleu} and {ROUGE}~\cite{lin-2004-rouge}, which approximate quality via surface-level overlap with references."
- Chain-of-thought reasoning: An LLM prompting technique that elicits intermediate reasoning steps. "ReACT stands for Reason + Act, where an LLM interleaves chain-of-thought reasoning~\cite{wei2022chain} with tool use"
- Cohen's kappa: A statistic measuring inter-rater agreement beyond chance for two raters on categorical labels. "Cohen's ~\cite{cohen1960coefficient} assesses pairwise agreement on categorical labels:"
- CSAT (Customer Satisfaction): A survey-based measure of user satisfaction after an interaction. "Many teams track CSAT (Customer Satisfaction), typically collected via post-interaction surveys on a Likert scale"
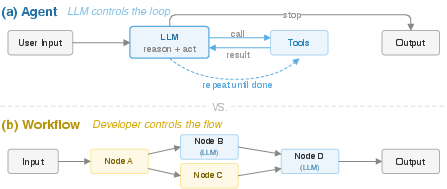
- DAG (Directed Acyclic Graph): A graph with directed edges and no cycles, often used to define fixed workflows. "we define workflows as predefined computation graphs or DAGs where the developer - and not the LLM - controls the execution flow."
- Data minimization: A privacy principle that limits collected or processed data to what is necessary. "privacy-preserving datasets derived from real customer-support conversations through the data-minimization and pseudonymization pipeline"
- DSPy: A framework that treats LLM pipelines as modular programs and compiles them into optimized prompts. "DSPy~\cite{khattab2024dspy} provides a programmatic abstraction where LLM pipelines are defined as modular programs with typed signatures and compiled into optimized prompts."
- Fleiss's kappa: A generalization of Cohen’s kappa for measuring agreement among more than two raters. "Fleiss's generalizes this to any number of raters~\cite{fleiss1971measuring}"
- GEPA: A reflection-based automated prompt optimization method that uses Pareto analysis to select improved prompts. "Within DSPy, GEPA~\cite{gepa2025} implements a reflection-based loop: a strong model critiques errors, synthesizes revisions, and selects candidates via Pareto-based trade-off analysis, optionally incorporating free-text human feedback."
- Human-in-the-loop: A design where humans remain part of the workflow for oversight, fallback, or escalation. "CS agents work within a human-in-the-loop workflow."
- Idempotency: A property of operations that can be repeated without changing the outcome beyond the initial effect. "Idempotency is critical: because LLMs may retry tool calls on transient failures or ambiguous results."
- Inter-rater reliability (IRR): A measure of consistency among different raters assessing the same items. "Inter-rater reliability (IRR) quantifies agreement among independent raters beyond chance."
- Judge ensembles: Using multiple LLM judges or prompts to reduce individual judge biases in evaluations. "judge ensembles â using multiple models or prompts â can mitigate individual biases"
- Krippendorff's alpha: An agreement coefficient applicable to various data types and missing data scenarios. "Krippendorff's extends it to various data types and missing data~\cite{krippendorff2004reliability}."
- LangGraph: A framework that mixes deterministic workflow nodes with agentic decision-making nodes. "Frameworks like LangGraph~\cite{langgraph2024} blur the boundaries between workflows and agents"
- Likert scale: A psychometric scale (e.g., 1–5 or 1–7) used to measure attitudes or perceptions in surveys. "post-interaction surveys on a Likert scale (e.g., ``Were you satisfied with the help you received?'')"
- LLM-as-a-judge: An evaluation approach where a strong LLM scores or ranks outputs according to a rubric. "The LLM-as-a-judge paradigm instead uses a strong LLM to score or rank outputs against an explicit rubric."
- Macros (prompting): Reusable response templates that the agent adapts for common scenarios. "Macros. Pre-written response templates for common scenarios â serve as modular building blocks that the agent adapts and condenses"
- Majority-class baseline: A simple classifier that always predicts the most frequent class in the dataset. "We compared against (i) a majority-class baseline that always predicts the most frequent label"
- Net Promoter Score (NPS): A metric estimating the likelihood of users recommending a service. "Another widely used measure is Net Promoter Score (NPS), which estimates how likely a user is to recommend the service"
- Pareto-based candidate selection: Choosing among candidate prompts by balancing trade-offs across multiple objectives without a single optimal solution. "We ran GEPA with auto=light (approximately 500 iterations) ... and Pareto-based candidate selection to balance trade-offs across optimization criteria."
- Pseudonymization: A privacy technique replacing identifying data with surrogate identifiers to protect personal information. "privacy-preserving datasets derived from real customer-support conversations through the data-minimization and pseudonymization pipeline"
- ReACT: An agent pattern where an LLM alternates between reasoning and acting (tool use) to solve tasks. "ReACT stands for Reason + Act, where an LLM interleaves chain-of-thought reasoning ... with tool use"
- Rubric (evaluation): A structured set of criteria guiding how outputs should be judged. "Given a rubric, the judge model assesses whether a response meets quality dimensions such as correctness, helpfulness, safety, or adherence to instructions."
- Self-service rate (SSR): The proportion of support issues resolved without human escalation. "Self-service rate (SSR) measures the fraction of support needs resolved via automated or self-serve channels without human escalation."
- Standard operating procedure (SOP): Codified step-by-step instructions that define how tasks should be performed. "Most customer support units within organizations issue standard operating procedures (SOPs) for human agents"
- Tool-first principle: An instruction strategy that requires calling tools to fetch customer-specific data before drafting responses. "we introduced a tool-first principle in the Instructions component"
- Transactional Net Promoter Score (tNPS): An NPS variant asked immediately after a specific support interaction. "For CS, organizations often use Transactional NPS (tNPS) - an NPS variant asked immediately after a support interaction."
- Working memory (scratchpad): The agent’s persistent state for tracking conversation context, tool outputs, and parameters across turns. "Working memory (scratchpad). A persistent state object that tracks information gathered across the conversation"
Collections
Sign up for free to add this paper to one or more collections.