- The paper introduces TRUST, an uncertainty-aligned RL framework that recalibrates agentic tool-calling decisions to reduce overconfident errors.
- TRUST employs turn-level uncertainty margins and unified post-training to achieve up to 11% accuracy improvements on key benchmarks.
- Empirical results highlight significant gains in multi-turn tasks and reduced hallucination rates, enhancing reliability in LLM agent deployments.
Motivation and Problem Statement
LLM-based agents increasingly rely on dynamic tool use for extended reasoning and real-world interactions. However, these agents often make erroneous tool-use decisions—including unsupported tool invocation and hallucinated direct responses—undermining intermediate agent states and triggering error propagation in complex tasks. Existing RL fine-tuning paradigms typically optimize action correctness through coarse reward structures but neglect the policy’s underlying uncertainty landscape. As a result, reinforcement learning (RL) tends to collapse the predictive uncertainty gap between correct and incorrect tool-calling actions, leading to overconfident but wrong decisions and diminished exploratory signals. This overconfidence, especially when combined with multi-step trajectories, exacerbates error propagation and system unreliability.
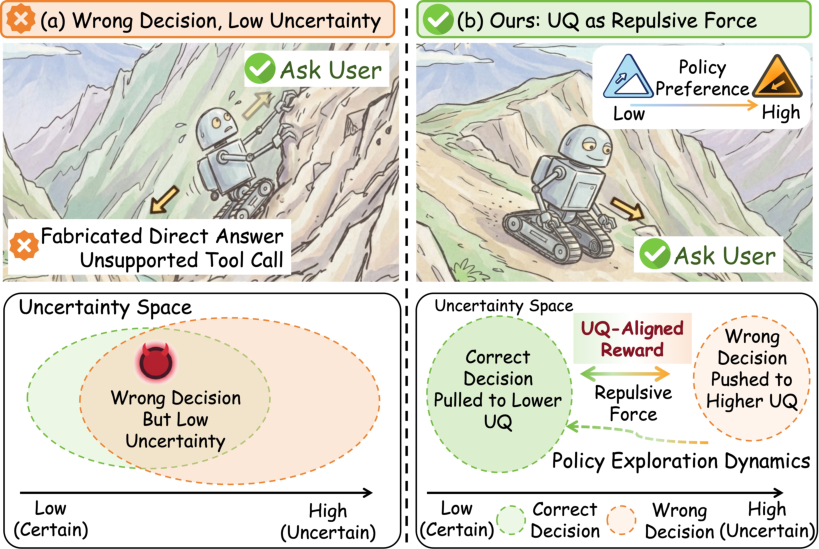
Figure 1: Comparison between tool-calling decision failure in wrong decision but low uncertainty, and the TRUST solution.
The TRUST Framework: Uncertainty-Aligned Reward and Unified Post-Training
TRUST (Tool-calling decision Reward with Uncertainty-Separated post-Training) introduces an uncertainty-aligned reinforcement learning framework to recalibrate the certainty structure of agentic tool-calling policies. The method’s core is a turn-level reward design that incorporates a repulsive UQ (uncertainty quantification) signal—specifically, the margin between the uncertainty (proxied by PPL) of the correct action and negative/counterfactual decisions. This margin drives the RL policy to maximize both correctness and separation in model confidence between correct and incorrect turns.
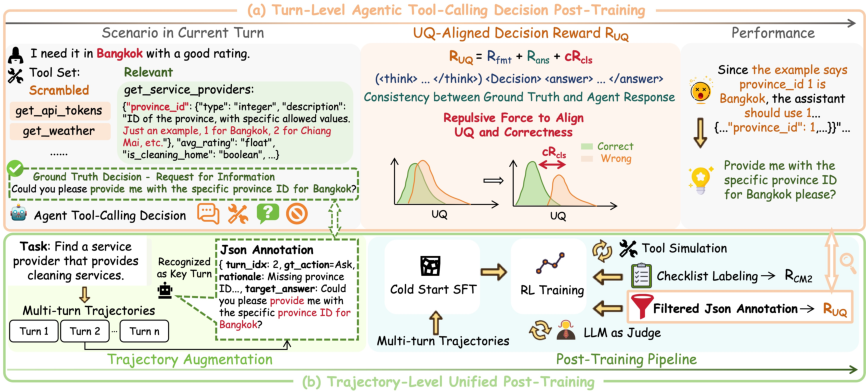
Figure 2: Overview of TRUST—(a) turn-level UQ-aligned reward aligns correctness and confidence; (b) trajectory-level post-training augments critical turns and integrates RUQ for unified optimization.
Concretely, the agent’s four-way decision space includes: Direct, Tool, Ask, and Unable. At each decision point, sequence-level perplexity serves as a certainty estimator. The uncertainty margin computes the expected perplexity gap between sampled ground-truth and negative actions, feeding into a bounded certainty coefficient after a temperature-controlled sigmoid transformation. The reward formulation unifies (1) output format validity, (2) answer quality, (3) action classification correctness, and (4) the uncertainty-based repulsive force.
To extend from isolated decision points to realistic agentic trajectories, TRUST annotates lightweight key-turns—conservatively chosen informative states for action supervision—rather than exhaustively relabeling full rollouts. This design enables trajectory-level unified reinforcement learning, jointly supervising both global task success (CM2 checklist rewards) and targeted improvements to tool-calling policy calibration.
Empirical Results
TRUST consistently yields significant improvements on critical tool-use evaluation benchmarks such as When2Call, ToolSandbox, and BFCL-V4. Quantitatively, TRUST achieves:
- +11.47% accuracy improvement on turn-level tool-calling decisions (When2Call task, absolute gain over base model).
- +8.37% versus turn-level GRPO on accuracy, and substantial reductions in hallucination metrics (Tool Hallucination plus False Direct Answer Rate).
- +6.33% trajectory-level gain on BFCL-V4 and +7.07% on ToolSandbox over the unified post-training CM2 baseline.
These benefits are particularly pronounced in multi-turn, long-context, and distraction-rich scenarios, with TRUST demonstrating both precision in timely tool invocation and robustness against unsupported tool-use.
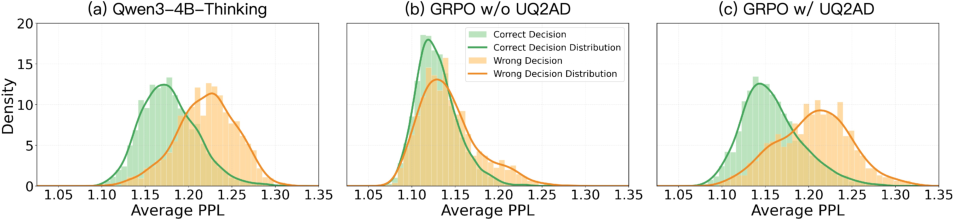
Figure 3: Uncertainty calibration; TRUST maintains separation between correct (low PPL) and wrong (high PPL) decisions, unlike standard RL.
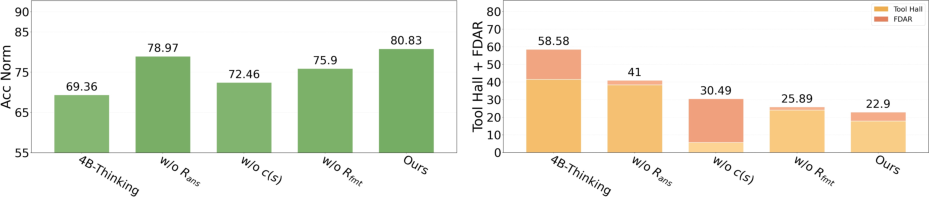
Figure 4: Ablation study of RUQ—removing the uncertainty repulsive term sharply degrades accuracy and increases hallucination rates.
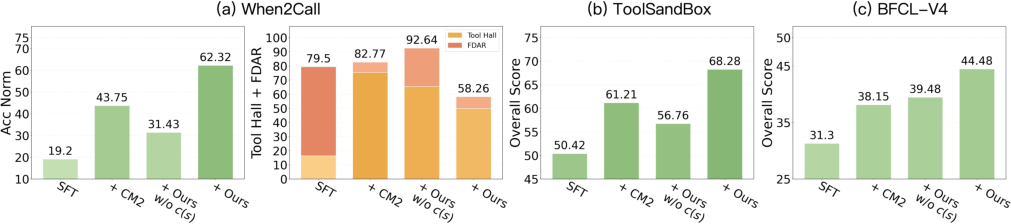
Figure 5: Unified post-training ablation on benchmark suite, highlighting additive effects of format, answer, and UQ-aware reward terms.
Qualitative Analysis and Illustrative Cases
Fine-grained analysis reveals failure modes in standard RL—such as confidently using the wrong tool argument or omitting essential tool interactions, leading to irreversible downstream errors. TRUST’s uncertainty-aware reward both penalizes overconfident mistakes and encourages agent behavior to defer or request missing information instead of speculative tool use.
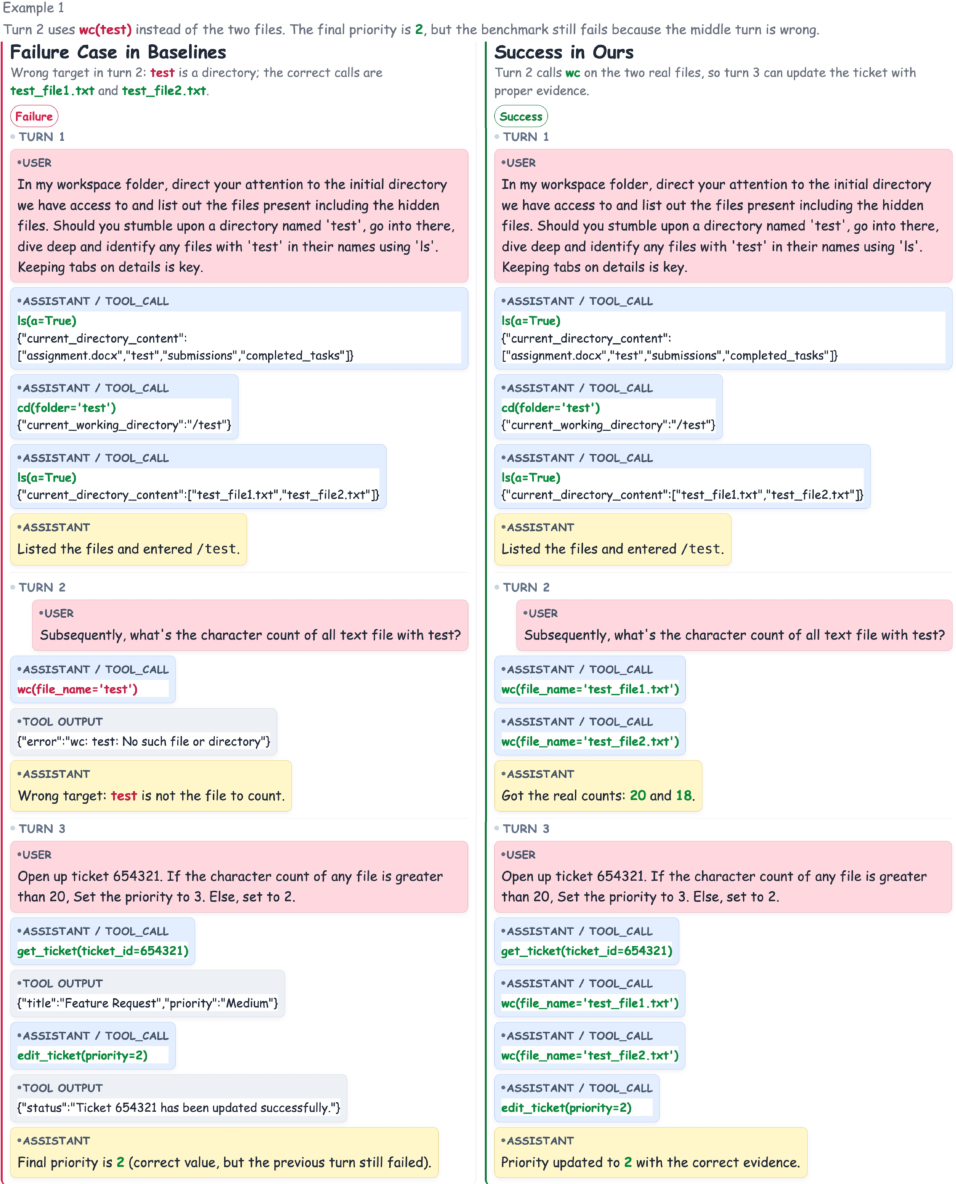
Figure 6: Example—baseline model misapplies a tool on a directory; TRUST ensures file-level tool use is grounded in available evidence.
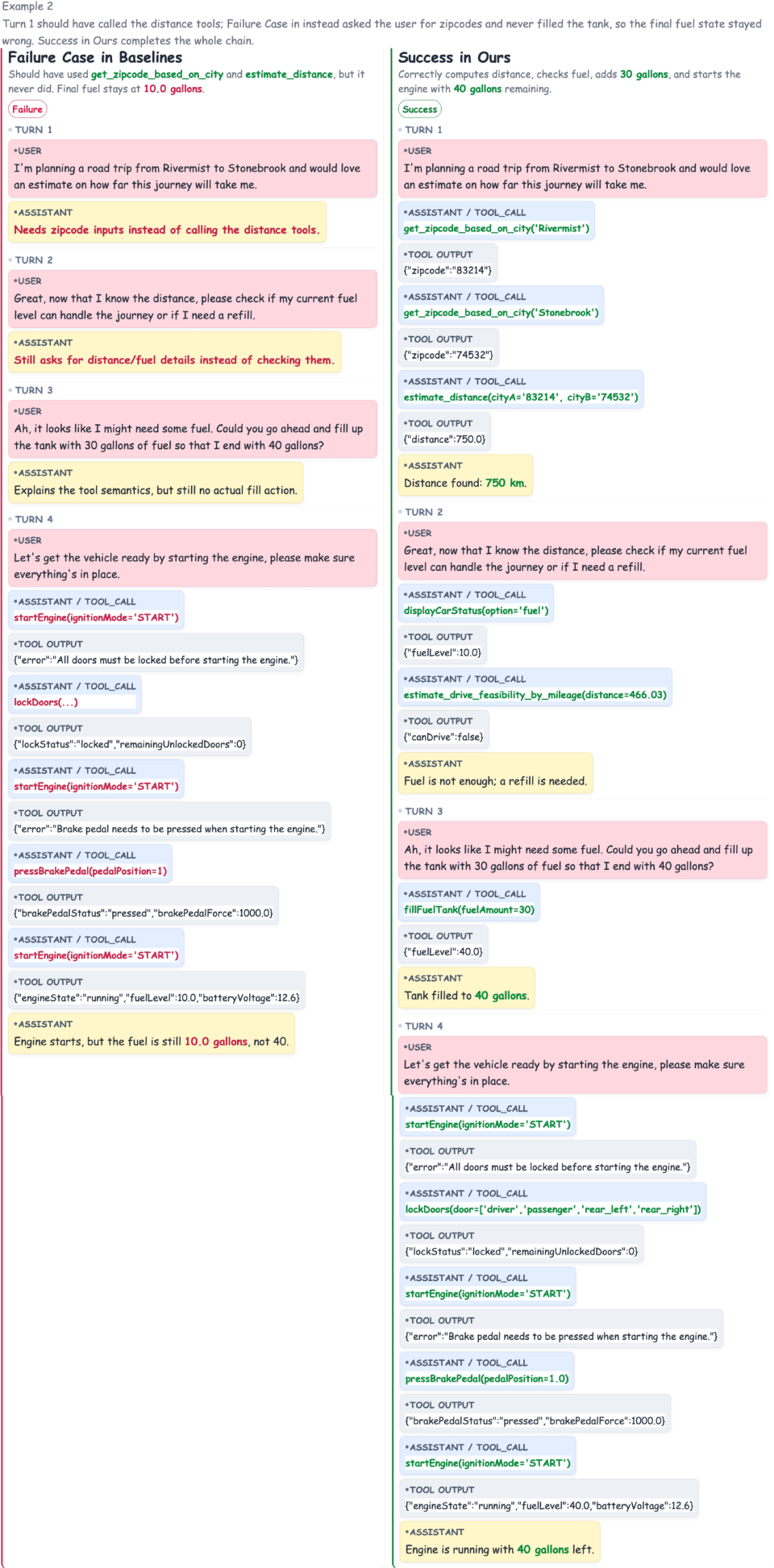
Figure 7: Example—baseline skips required tool invocation, causing overall task failure; TRUST executes required actions at proper turns.

Figure 8: Example—baseline hallucinates an unwarranted tool use under information insufficiency; TRUST abstains until proper specification is available.
Implications and Future Prospects
The work demonstrates that aligning internal model uncertainty with decision correctness is critical for reliable agent operation, particularly in open-ended, multi-step, or dynamically perturbed environments. TRUST’s approach stands in contrast to training-free calibration and uncertainty-checking methods, as it integrates separation of uncertainty into the RL optimization routine itself, delivering policy improvements without incurring inference-time latencies or prompting overhead.
Practical Implications
- Scalability: TRUST enables lightweight annotation of supervision signals, facilitating incremental application to large dialogue datasets.
- Deployment: The method does not increase inference-time computational cost and can be deployed in production-grade LLM agentic tool-use systems.
- Error Control: The explicit uncertainty repulsion suppresses overconfident, unsupported tool use—a critical property for safety and robustness in real-world agent deployments.
Theoretical Implications and Future Directions
While TRUST leverages sequence-level perplexity, further advances could arise from semantic, action-level, or trajectory-distributional uncertainty measures. Application of TRUST principles to embodied or open-world agentic domains, as well as adaptation for richer, non-discrete action spaces, remain promising research directions. Additional integration of risk-aware decision policies could complement the current uncertainty-oriented formulation.
Conclusion
TRUST introduces a theoretically principled and empirically validated RL framework that explicitly leverages uncertainty quantification to refine agentic tool-calling decisions. By simultaneously optimizing for correctness, action calibration, and preservation/separation of agentic uncertainty, TRUST delivers robust gains in multi-turn task performance, tool-use reliability, and calibration. The approach offers a template for advancing reinforcement learning in agentic LLM systems, highlighting the necessity of manipulating uncertainty structures directly within the policy optimization process for safe and efficient real-world deployment.
Reference: "Exploring Agentic Tool-Calling Decisions via Uncertainty-Aligned Reinforcement Learning" (2606.06976)