- The paper presents a dual-stage approach that first optimizes action selection using VOI-based estimates to efficiently allocate inference budgets.
- It integrates a conservative finalizer to judiciously refine answers based on evidence, ensuring safe resource expenditure.
- Empirical analysis on multi-hop QA benchmarks shows enhanced performance, especially under low and medium budget conditions.
Inference-Time Budget Control for LLM Search Agents: A Technical Assessment
The paper "Inference-Time Budget Control for LLM Search Agents" (2605.05701) addresses the problem of how LLM search agents should allocate inference resources—specifically, tool-call and output-token budgets—when engaged in multi-hop question answering (QA). The central challenge is the necessity for fine-grained, explicit control over action selection at each step of the search process given explicit resource constraints. The research identifies that naïve agentic reasoning or simple token budget tracking is insufficient, as different search actions (retrieval, decomposition, answer commitment) have heterogeneous costs and returns, and over-searching or premature answering is detrimental under hard budgets.
The authors formulate this as a two-stage constrained inference control problem:
- During Search: Allocate the next budget unit across retrieval, decomposition, or answer commitment based on an operational estimate of marginal task value per unit budget.
- After Search: Decide whether to preserve the initial trajectory answer or to rewrite it, accepting intervention risk only when the expected gain in answer exactness justifies it.
This dual-stage principle is fundamental, as it separates online action selection from post-hoc answer refinement, each respecting explicit dual-budget constraints and risk.
Methodology: Task-Level VOI Controller and Conservative Finalizer
The approach is instantiated via two lightweight, training-free layers on a generic tree-search backbone:
Stage 1: Task-Level VOI-Based Search-Time Control
At each step, the agent uses a controller that assigns a task-level Value-of-Information (VOI) score to each feasible action, calculated as the estimated marginal utility per unit budget in the current trajectory and remaining budget context. The utility function is composed of:
- A progress signal grounded in critic-derived evaluation,
- Structural signals sensitive to question compositionality and evidence support,
- A budget-dependent penalty that becomes more severe as resource constraints approach exhaustion,
- Conservative guards (e.g., to avoid premature answer commitment or suppress unnecessary decomposition for factoid queries).
Action selection is performed by ranking VOI scores and then applying guard-based gating. This enables explicit, stepwise expenditure of budget—deciding at each frontier which operation maximizes expected downstream reward per cost.
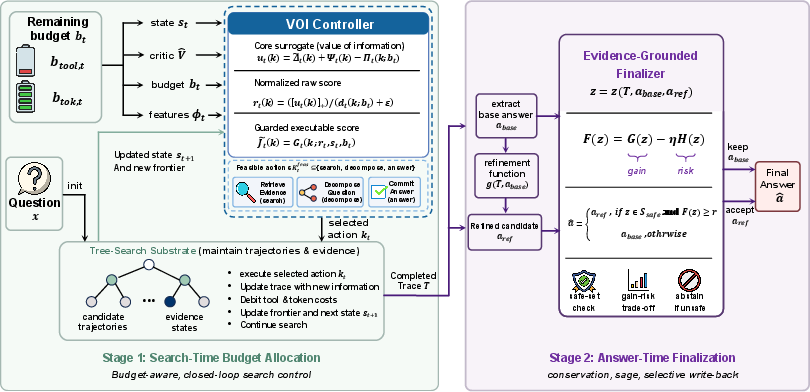
Figure 1: Two-stage budget control with task-level VOI. Stage 1 uses a controller based on the task-level VOI score to choose whether the next step should retrieve, decompose, or answer under the remaining dual budget. Stage 2 finalizes the answer conservatively, rewriting only when the case is safe and the expected gain outweighs rewrite risk.
Stage 2: Conservative, Evidence-Grounded Finalizer
Upon search completion, a deterministic, feature-based answer-time selector is applied. It compares the base answer extracted from the trajectory with a refined candidate generated from the same evidence. Update (rewrite) is made only if all of the following hold:
- The case is classified as structurally safe (e.g., no unresolved bridge or comparative reasoning);
- Expected gain in answer exactness (e.g., slot-type or binary-choice correction) outweighs the estimated risk of erasing bridge structure or altering semantics;
- All rules are deterministic; there is no additional LLM call.
This module ensures resource-neutral, post-hoc calibration of answer exactness while hedging against semantic degradation.
Empirical Analysis and Ablation
The method is benchmarked on four multi-hop QA datasets (HotpotQA, 2WikiMultihopQA, MuSiQue, Bamboogle) across three LLM backbones (Qwen3-32B, Qwen3.5-122B, GPT-5.4-Mini) and four explicit dual budget levels. The evaluation setup uses strict, example-level enforcement of tool-call and output-token caps, and all methods are subject to the same hard budget audits.
Budget Scaling Results
VOI-based control yields aggregate gains over BAVT, BATS, Search-o1, and AFlow in the majority of dataset-budget cells (with best-F1 in 7/16 and tied best in 2/16 for Qwen3-32B). Gains are pronounced at low and medium budgets, where careful action allocation is crucial. As model backbone strength increases (notably with Qwen3.5-122B and GPT-5.4-Mini), the marginal advantage of the controller is reduced but remains competitive, especially for tight budgets.
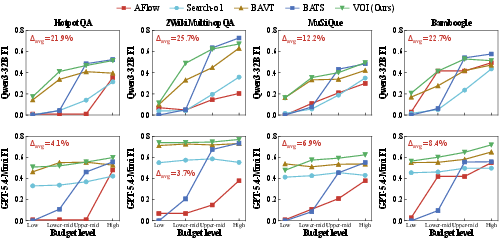
Figure 2: Cross-model budget scaling curves across four datasets. Rows: Qwen3-32B and GPT-5.4-Mini; columns: four multi-hop QA benchmarks.
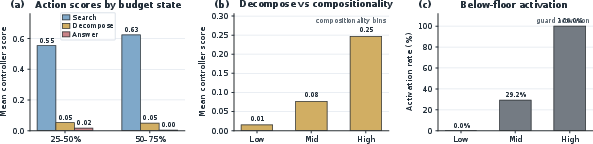
Controller Dynamics
Empirical analyses confirm that the controller dynamically adjusts VOI scores:
Finalizer Impact
The answer-time finalizer repairs residual answer-form errors, with strongest effects on Bamboogle and 2WikiMultihopQA (e.g., F1 gains of +0.027–0.056). Its influence is negligible on QA tasks where errors are primarily due to incorrect search paths rather than output form, consistent with its conservative scope.
Ablation Studies
Component ablations demonstrate that the budget-dependent penalty is the dominant contributor to performance gain. Removing normalization, structural signals, or guards also consistently degrades scores, verifying that the holistic, multi-component design of the controller is essential for optimal budget utility.
Theoretical and Practical Implications
The main theoretical implication is that optimal inference under dual-budget constraints for agentic, tool-augmented LLMs is not achieved by generic token-level scaling or beam search. Instead, it requires explicitly modeling task-level value over heterogeneous actions, making search adaptive to both problem structure and the changing budget landscape.
Practically, the technique enables better budget utilization and predictable, inspectable behavior, which is critical for real-world deployment scenarios with tight latency, cost, or external API quotas. The explicit, two-stage approach exposes action selection and answer commitment decisions, reducing opaque failure modes and escalating accountability for how resources are spent.
Broader impacts include the potential for improved deployability and efficiency in multi-hop QA agents, as well as making agentic search processes more auditable. The authors explicitly note the importance of budgeting for safety—tightening control does not only drive efficiency but also provides transparency and guardrails for undesirable behaviors.
Limitations and Future Work
The method’s gains diminish as LLM backbones become more capable because base models correct more errors autonomously, reducing the marginal value of explicit budget-aware control. Also, the answer-time module operates only at the level of exactness and cannot salvage fundamentally misguided search paths. The system uses deterministic, hand-crafted scoring and selection rules; further advances could exploit learned policies or finer resource modeling across action types and evidence chains.
Extensions may include richer retrieval and query rewriting, adaptive controller calibration based on backbone feedback, integration with dynamic environment-grounded tools, or adaptation to federated and distributed agent scenarios, as seen in recent work on mobile edge AI deployment [qu2025mobile, wu2026lifecycle, ding2026application].
Conclusion
This work provides a rigorous, resource-aware framework for inference-time control in agentic, tool-augmented LLMs. By integrating a task-level VOI controller for stepwise search action allocation with a conservative, evidence-grounded finalizer for answer selection, the approach achieves superior budget efficiency and answer quality on multi-hop QA—in particular, when resources are limited and decisions must be audited stepwise. The findings establish that explicit action budgeting, not just model improvement or token scaling, is central to effective LLM agent deployment under realistic constraints.