- The paper presents a novel CSC framework that converts multi-agent debate outputs into calibrated act-escalate decisions via conformal prediction.
- It aggregates verbalized probability distributions from diverse LLM agents using a linear opinion pool, ensuring marginal coverage through split conformal calibration.
- Empirical results on MMLU-Pro show that CSC intercepts 81.9% of wrong-consensus errors while achieving high accuracy on automated decisions in low-ambiguity domains.
Motivation and Problem Statement
Multi-agent debate protocols for LLM ensembles yield accuracy gains through iterative reasoning and information aggregation. However, consensus among agents is not indicative of correctness—agents may converge to confident but incorrect answers via social reinforcement, leading to wrong-consensus failures. Standard consensus-based or majority-vote deployment pipelines commit to automated action once agents agree, with no mechanism to flag such errors or escalate uncertain cases for human review.
The primary operational gap addressed in "From Debate to Decision: Conformal Social Choice for Safe Multi-Agent Deliberation" (2604.07667) is the absence of a calibrated refusal mechanism: distinguishing when to act (automation) versus when to escalate (human-in-the-loop) using only aggregate debate outputs, without model retraining or internal access.
Pipeline Architecture and Theoretical Guarantees
The Conformal Social Choice (CSC) framework formalizes act-versus-escalate decisions as a post-hoc, black-box layer atop multi-agent debate:
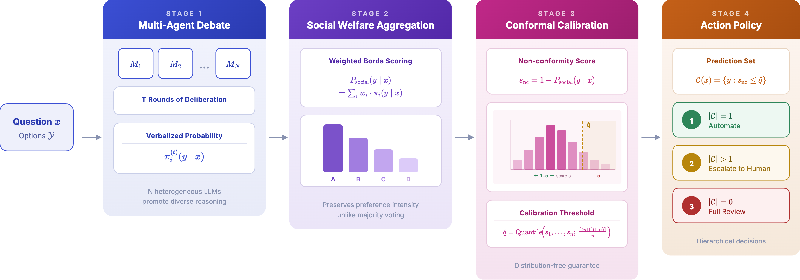
Figure 1: The CSC pipeline transforms multi-agent debate outputs into operational decisions, guaranteeing marginal coverage via conformal calibration.
- Verbalized Probability Elicitation: Heterogeneous LLM agents engage in T-round debate, outputting explicit option-wise probability distributions via structured prompts. These verbalized scores are subject to parsing and normalization, enabling downstream probabilistic aggregation.
- Social Probability Aggregation: Agent forecasts are combined via the linear opinion pool—uniformly weighted unless otherwise specified—resulting in a normalized ensemble probability over all answer options. This aggregation preserves the intensity of agent preferences beyond simple majority voting.
- Conformal Calibration (Split Conformal Prediction): Given a held-out calibration set, the ensemble output is converted to nonconformity scores (s(x,y)=1−Psocial(y∣x)). The conformal threshold q is set to the (1−α) quantile of calibration scores, guaranteeing that prediction sets C(x) achieve coverage Pr[y∗∈C(x)]≥1−α under exchangeability without requiring per-model calibration.
- Hierarchical Action Policy: Prediction sets are mapped to operational actions:
- Singleton (∣C(x)∣=1): automated decision.
- Larger set (∣C(x)∣>1): escalate to human review, restricting the candidate pool.
- Empty set: anomaly flagging.
The procedure reframes multi-agent debate from a point-estimate task to a calibrated-decision problem, aligning operational automation with risk control.
Empirical Analysis on MMLU-Pro
The authors evaluate CSC on MMLU-Pro, a challenging 10-option, 8-domain professional benchmark. The agent ensemble includes Claude Haiku, DeepSeek-R1, and Qwen-3 32B, ensuring model diversity.
Coverage Calibration and Uncertainty Quantification
Empirical coverage closely tracks the user-specified rate (e.g., operating at α=0.05, realized coverage is within 1–2% of 95% across domains), validating theoretical guarantees in practice.
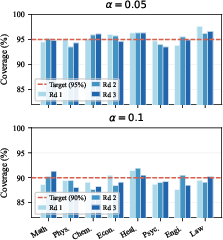
Figure 2: CSC maintains calibrated coverage across rounds and domains, with average set size adapting to domain difficulty.
Crucially, the average prediction set size adapts to task hardness: in unambiguous domains (Math), singleton rates approach 98.2%, enabling nearly full automation; ambiguous domains (Law) yield set sizes ≈7, prompting high rates of human escalation. This reflects genuine epistemic uncertainty, not system conservatism.
Debate as an iterative process reduces uncertainty: more rounds monotonically decrease the average prediction set size while preserving population coverage.
Failure Modes of Consensus-Based Stopping
Consensus-based stopping is fast but fundamentally unreliable. In the test set, 23.9% of initially-disputed cases converge to unanimous but incorrect consensus. Within high-stakes domains (e.g., Law, Psychology), this convergent error rate exceeds 33%.
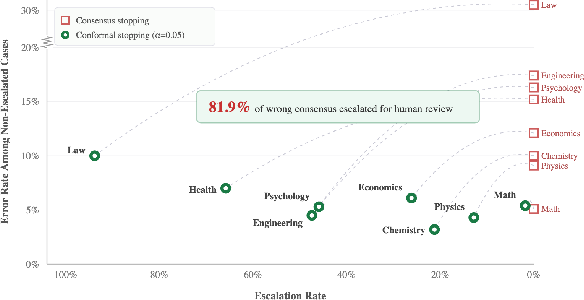
Figure 3: Without calibrated refusal, consensus stopping commits to high error rates. CSC dramatically reduces error at the cost of automation, with the trade-off adjustable via α.
This exposes a systemic vulnerability: uncalibrated automation driven by superficial agent agreement yields substantial unflagged errors in deployment.
CSC as a Safety Filter: Selective Automation
The most striking result is that CSC's conformal refusal mechanism intercepts 81.9% of wrong-consensus errors at s(x,y)=1−Psocial(y∣x)0. The remaining automatically resolved instances (conformal singletons) achieve 90.0–96.8% accuracy, a strong positive selection effect. Singleton accuracy gains reach 22.1 percentage points over consensus stopping in high-risk domains (e.g., Law), but this is a statistical filtering effect—CSC is not improving underlying agent reasoning.
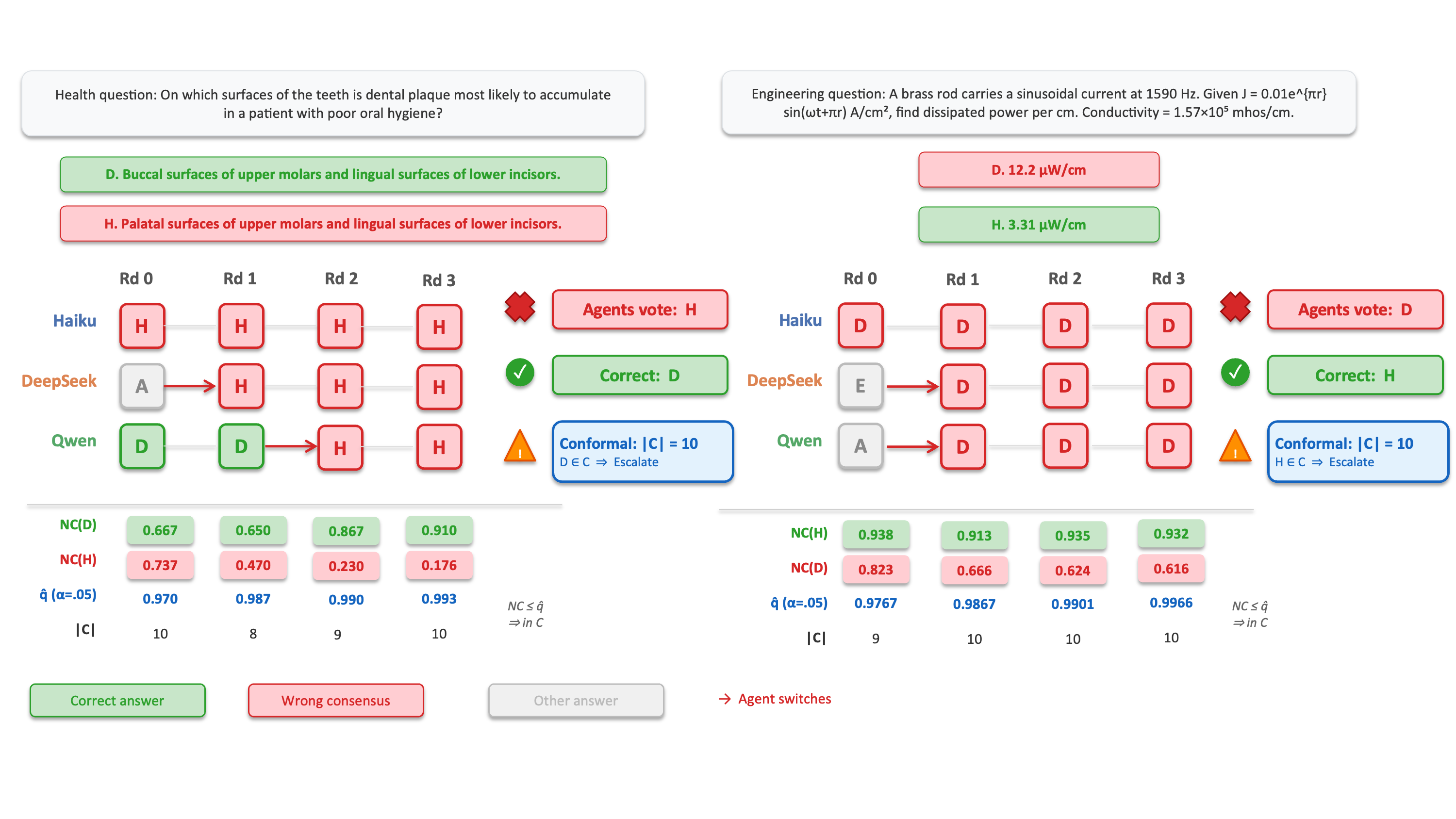
Figure 4: In practice, CSC forces escalation of cases where debate reaches confident but incorrect consensus, preventing silent failures.
The trade-off is a decrease in the automation rate, particularly in ambiguous domains. This is both principled and operationally adjustable via the s(x,y)=1−Psocial(y∣x)1 parameter.
Error Analysis
Failures introduced by CSC (i.e., incorrectly automated singletons not present under consensus-based stopping) are extremely rare (0.05% of cases at s(x,y)=1−Psocial(y∣x)2), yielding a net error-prevention ratio of 240:1. This underscores CSC's selectivity: over-rejection of correct-consensus cases (abstaining when unnecessary) is the principal source of inefficiency, not risk.
Implications and Future Directions
Practically, CSC provides a rigorous and domain-adaptive mechanism for triaging LLM ensemble outputs in safety- and cost-sensitive applications, reducing the operational risk of over-automation. The method is black-box and post-hoc, requiring only predicted probabilities and a calibration split.
The theoretical guarantee is marginal, not conditional; it calibrates risk over the population rather than per-instance or per-subgroup. Conditional coverage, adaptation to non-stationary environments (e.g., via online conformal methods), or extension to open-ended generation remain open.
Theoretically, CSC formalizes a robust operational contract for multi-agent deliberation, unifying social choice, uncertainty quantification, and calibrated refusal in a single deployable pipeline. Its abstraction as a meta-layer atop ensemble outputs suggests broad applicability across models, agent aggregation schemes, and task settings.
Conclusion
CSC robustly mitigates the risks of automated pipeline deployment for multi-agent LLM ensembles by converting model consensus into distribution-free, coverage-controlled act-escalate decisions. By intercepting the majority of wrong-consensus cases while preserving high accuracy on automatically resolved instances, CSC offers operationally tunable safety as a default deployment layer. Future work should address conditional guarantees, continuous adaptation, and broader task families, but CSC establishes a strong baseline for reliable large-scale automated reasoning.

