Toward Generalist Autonomous Research via Hypothesis-Tree Refinement
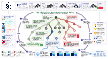
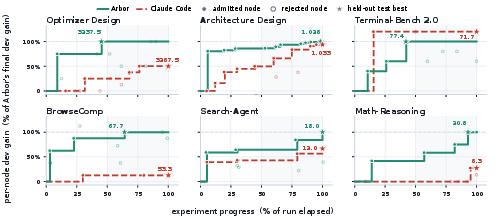
Abstract: Scientific progress depends on a repeated loop of exploration, experimentation, and abstraction. Researchers test candidate directions, interpret the evidence, and carry the resulting lessons into later attempts. We study how an AI agent can run this loop autonomously over long horizons. We introduce Arbor, a general framework for autonomous research that combines a long-lived coordinator, short-lived executors, and Hypothesis Tree Refinement (HTR), a persistent tree that links hypotheses, artifacts, evidence, and distilled insights across time. The coordinator manages global research strategy over the tree, while executors implement and test individual hypotheses in isolated worktrees. As results return, Arbor updates the tree, propagates reusable lessons, refines the search frontier, and admits verified improvements. This design turns autonomous research from a sequence of local attempts into a cumulative process in which strategy, execution, and evidence are carried across time. We evaluate Arbor under Autonomous Optimization (AO), an operational setting where an agent improves an initial research artifact through iterative experimentation without step-level human supervision. Across six real research tasks in model training, harness engineering, and data synthesis, Arbor achieves the best held-out result on all six tasks, attaining more than 2.5x the average relative held-out gain of Codex and Claude Code under the same task interface and resource budget. On MLE-Bench Lite, Arbor reaches 86.36% Any Medal with GPT-5.5, the strongest result in our comparison.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching an AI to do research more like a careful scientist, not just a quick problem-solver. The authors built a system called Arbor that can keep track of ideas, run experiments, learn from what happens, and steadily improve “the thing it’s working on” (like a code project or a data pipeline) over a long time, without a human telling it what to do at every step.
Instead of trying one idea after another and forgetting, Arbor keeps a living “tree” of hypotheses (ideas), results, and lessons learned, so progress builds up over time.
What questions were the researchers trying to answer?
- How can an AI keep many competing ideas organized and make steady progress, even when experiments are slow, costly, or sometimes fail?
- How can it turn lots of small tries into reliable improvements on the actual goal?
- How can it avoid “overfitting” to practice feedback (doing great on practice but failing on fresh tests)?
- Can one approach work across different kinds of real tasks, like training models, improving tool code, or creating better data?
How does Arbor work? (Simple explanation of the method)
Think of research like exploring a branching trail system:
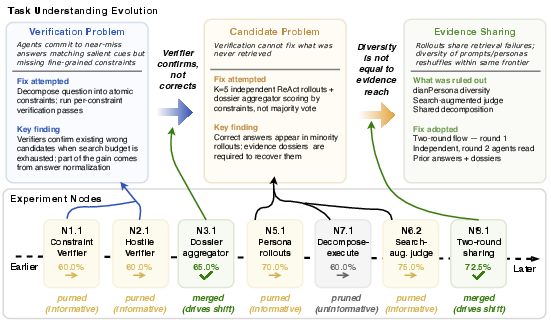
- The “hypothesis tree”: Imagine a map where each branch is an idea to try. Each node in this tree stores:
- The hypothesis: a clear, testable idea (what to change and why it might help).
- The insight: the lesson learned after trying it (what worked, what didn’t, and why).
- The metadata: links to the exact code version, scores, and experiment facts (so anyone can verify what happened).
- Two roles, like a coach and players:
- Coordinator (the coach): Keeps the big picture, decides which ideas to explore next, and updates the tree with what was learned.
- Executors (the players): Each one takes a single idea, creates a separate “sandbox” copy of the project (so they can’t break the main one), makes the needed changes, runs tests, and reports back results and lessons.
- A clear research loop (in everyday terms):
- Observe: Look at the current tree and see what’s known and unknown.
- Ideate: Propose a few next ideas (new branches).
- Select: Pick the most useful ideas to try now.
- Dispatch: Send those ideas to executors to implement and test in isolation.
- Backpropagate: Write results and lessons into the tree; generalize the lessons so they can help with future ideas.
- Decide: Keep promising directions, prune bad ones, and, only if an idea truly helps, merge it into the main project.
Practice vs real game (dev/test split):
- Development (dev) is like practice: the AI can use this feedback to explore ideas.
- Test is like the real game: it’s held back and only used to confirm that an improvement is real and not just a “practice trick.”
- Arbor only merges changes into the main project if they also improve the held-out test. This “merge gate” prevents overfitting.
- The overall setting (Autonomous Optimization, or AO):
- Start with an initial thing (for example, a codebase) and a goal (for example, higher accuracy).
- Let the AI repeatedly edit, run, learn, and improve—without humans choosing each step.
What did they find?
Across six real research tasks, Arbor got the best final (held-out) results every time, beating strong coding agents under the same rules and resource limits. The tasks covered three categories:
- Model training:
- Optimizer design (make training reach target faster)
- Architecture/training changes (lower final loss)
- Harness engineering (improving the control code around an agent):
- Terminal tasks (Terminal-Bench 2.0)
- Web-browsing questions (BrowseComp)
- Data synthesis (making better data so downstream models perform better):
- Search-agent question generation
- Math-reasoning problem generation
Key takeaways:
- Arbor consistently turned practice gains into test gains, which means its improvements were real, not just lucky or overfit.
- On average, it achieved more than 2.5× the relative improvement of the strong single-agent coding baselines.
- On the MLE-Bench Lite benchmark (a standard testbed for long engineering tasks), Arbor reached 86.36% “Any Medal” with a strong AI model, matching or beating top systems.
Why this matters: Arbor’s tree-based method helped it learn reusable lessons from both successes and failures, making later decisions smarter and more reliable.
Why is this important?
- Cumulative learning: Arbor makes AI research build on itself. Ideas, evidence, and insights don’t get lost; they drive smarter exploration.
- Reliability: By separating practice (dev) from final judging (test), Arbor reduces the chance of overfitting and makes improvements trustworthy.
- Generality: The same approach works across very different tasks—training models, engineering agent tools, and generating data—suggesting a broadly useful research “engine.”
- Transparency: Because each change is tied to a hypothesis and evidence in the tree, you can audit what was tried and why it was merged.
What could this lead to?
If refined and scaled, systems like Arbor could:
- Speed up machine learning engineering and other research areas, reducing the need for constant human guidance.
- Produce more reliable, explainable progress, since each improvement comes with a clear paper trail of evidence and reasoning.
- Help build generalist “AI researchers” that can tackle longer, more complex projects while staying organized, careful, and test-driven.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to guide concrete follow-up work.
- Unspecified policies for tree control:
- The paper leaves the Ideate, Select, Abstract (insight propagation), and Prune policies largely unspecified (e.g., no concrete heuristics or learning rules, no tie to bandit/BO/PUCT-style strategies). Future work should define, implement, and ablate concrete policies (e.g., UCB on dev score uncertainty, information gain–based selection, learned value/priority models) and report their impact.
- Limited tree depth and branching analysis:
- Experiments fix a shallow tree (max depth 2) with unspecified branching factor k; there is no scaling study on deeper trees, dynamic branching, or adaptive frontier sizing under fixed budgets. Evaluate performance/compute trade-offs as a function of depth, branching, and parallelism, and propose budget-aware scheduling.
- Risk of test-set overuse via the merge gate:
- The system repeatedly queries the held-out evaluator E_test to “gate” merges, which can create feedback loops and implicit overfitting to the test set. Establish strict protocols (e.g., quotas or nested holdouts), study how many E_test calls are made per run, quantify test leakage risk, and compare with single-shot final testing.
- Robustness to evaluator noise and non-determinism:
- Some tasks average only two seeds or rely on stochastic evaluators (e.g., ReAct-based graders). Quantify sensitivity to evaluator noise, increase seeds, apply statistical tests, and add uncertainty-aware selection/merging (e.g., confidence intervals or bootstrap tests).
- Insight representation and verification:
- “Insights” are natural-language artifacts with no formal representation, quality checks, or consistency verification. Investigate structured schemas (schemas/ontologies), citation of evidence (links to logs/commits/tests), validation of insight correctness, and mechanisms to detect hallucinated or stale insights.
- Credit assignment and minimality of interventions:
- Executors may apply multiple edits within a node; the framework lacks instrumentation to ensure that the specific hypothesis h_n (and not incidental changes) explains the gains. Add minimal-change constraints, code coverage/path activation checks, edit diffs with unit tests tied to h_n, and ablate incidental edits.
- When to relax “hypothesis-bound” execution:
- For mis-specified hypotheses, strictly binding executors to h_n may waste budget. Explore principled “pivot” mechanisms (e.g., constrained reformulations, sub-hypothesis factorization, or automatic splitting into sub-nodes) and criteria for safe deviation.
- Generality beyond ML engineering and text-based tasks:
- All tasks are ML code/harness/data pipelines. Evaluate Arbor in domains with different latencies and failure modes (e.g., simulation-heavy RL, compilers, theorem proving, software verification), and especially in non-text domains (hardware, wet labs, robotics) where evaluators are slower, noisy, or partially observed.
- Comparability and fairness of baselines:
- Arbor and baselines use different backbone models and scaffolds (e.g., Claude Opus 4.6, GPT-5.5, Gemini-3-Flash). Provide same-backbone comparisons, report prompt/tooling parity, and include strong tree-search/BO baselines with identical resource budgets.
- Cost, efficiency, and overhead accounting:
- Claims mention cost analyses, but the excerpt lacks detailed token/runtime/evaluator-call breakdowns and overhead attributable to tree maintenance vs. execution. Publish full budgets, per-step costs (Observe/Ideate/Select/Dispatch/Backpropagate/Decide), and cost–performance curves.
- Dev/test discipline and drift:
- Only one dev/test split is used per task; there is no cross-validation or split-robustness study. Assess sensitivity to split choice, add multiple randomized splits, and evaluate transfer from dev to multiple held-out tests to measure drift.
- Evaluation metrics and external validity:
- Data-synthesis tasks use “mean pass gap” with an LLM-based evaluator; the link to downstream utility (e.g., training improvements on real models) is untested. Validate that metric improvements causally translate to downstream gains, and assess robustness to evaluator choice.
- Theoretical underpinnings and guarantees:
- No formal analysis of HTR sample efficiency, regret, or convergence. Develop theoretical characterizations (e.g., under noisy evaluators, bounded branching) and relate HTR to hierarchical Bayesian optimization or Monte Carlo tree search with delayed rewards.
- Failure modes and negative results:
- The paper does not present failure analyses (e.g., when Arbor underperforms on dev or wastes budget on dead branches). Provide error taxonomies, counterexamples, and diagnostics for misdirected insights, premature pruning, or executor dead-ends.
- Persistence across runs and knowledge transfer:
- Although HTR is “persistent,” it is unclear whether insights/trees are reused across separate runs or tasks. Study cross-run memory (e.g., a global insight library), retrieval for new tasks, and mechanisms to prevent negative transfer.
- Conflict resolution and merge safety:
- Git-based merging is mentioned but not detailed for conflicting multi-branch edits. Define automated merge policies, conflict resolution protocols, regression testing suites, and rollbacks tied to hypothesis provenance.
- Safety, security, and governance:
- Running code in executors and web browsing raises security risks; data synthesis may introduce biased or unsafe content. Specify sandboxing, dependency isolation, secret management, policy filters, and provenance tracking; add governance controls for insight reuse.
- Observability and context compression:
- “Structured projection” of the tree is the coordinator’s state, but compression fidelity and information loss are unquantified. Compare projection strategies (summaries vs. retrieval vs. learned state encoders) and measure decision quality vs. tree size.
- Parallelism and resource scheduling:
- The paper does not detail how sibling hypotheses are scheduled under limited compute, or how to balance depth vs. breadth. Develop scheduling algorithms (e.g., asynchronous bandits, speculative execution), and study contention on shared evaluators.
- Reproducibility with closed models:
- Many results rely on proprietary backbones; exact prompts, toolchains, seeds, and environment configs are not fully specified in the excerpt. Release full configs, seeds, code and tree snapshots, and open-weight replications where possible.
- Benchmark design choices:
- Some tasks use custom splits (e.g., Terminal-Bench 2.0 stratification) or hand-designed pipelines. Quantify how such choices affect difficulty and generality; provide public, immutable splits and release generation seeds for data-synthesis tasks.
- Insight aggregation across hierarchy:
- How insights aggregate from leaves to internal nodes (e.g., conflict resolution, weighting, recency vs. reliability) is unspecified. Propose algorithms for hierarchical belief updating (e.g., Bayesian pooling, truth maintenance systems) and evaluate their impact.
- Stopping criteria and termination:
- There is no principled stopping rule beyond a fixed budget. Develop adaptive stopping based on marginal value of information, convergence diagnostics, or posterior uncertainty on best-branch superiority.
- Alternative memory/state structures:
- The choice of a tree is motivated qualitatively; comparisons to other persistent state forms (graphs, DAGs, knowledge bases, replay buffers) are missing. Benchmark HTR against these alternatives under identical conditions.
- Coverage and hypothesis diversity:
- No measurement of hypothesis diversity, novelty, or coverage of the intervention space. Add diversity metrics and diversity-aware selection to reduce redundant exploration.
- Instrumentation for “path exercised” checks:
- Executors aim to ensure the h_n path is actually executed, but the method (coverage, tracing, test hooks) is unspecified. Add reliable instrumentation and report rates of “hypothesis not exercised” detections.
- Ethical and legal compliance in browsing:
- For BrowseComp and web tools, terms-of-service compliance, robots.txt respect, and content licensing are not discussed. Define and enforce compliant browsing policies during autonomous runs.
Practical Applications
Immediate Applications
The following applications can be deployed now using Arbor’s Hypothesis-Tree Refinement (HTR), coordinator–executor architecture, held-out merge gating, and isolated worktrees. Each item lists likely sectors and concrete tools/workflows, plus key assumptions.
- Autonomous ML pipeline optimizer
- Sectors: Software/ML, Cloud, Enterprise IT
- What: A “research copilot” that continuously proposes and tests optimizer, architecture, and training changes (hyperparameters, data pre-processing, regularization) on a dev split and auto-merges only when held-out improves.
- Tools/workflows: Git/GitHub worktrees; CI/CD with gated tests; MLflow/W&B for metrics; cluster schedulers (K8s, SLURM); adapters for benchmarks (e.g., NanoGPT-Bench, MLE-Bench).
- Assumptions/dependencies: Reliable dev/test split; executable evaluators; sufficient compute; access to a capable LLM backbone; sandboxing for code execution.
- Agent harness auto-engineer
- Sectors: Software, Robotics/RPA, Customer Service, DevTools
- What: Automatically refactors and tunes agent control logic (prompting, retries, tool strategies) using Arbor’s executor isolation; merges harness improvements only if test tasks improve (e.g., Terminal-Bench-style workflows).
- Tools/workflows: ReAct-style harnesses; A/B testing; regression suites; git branching and rollbacks; telemetry collection for agents.
- Assumptions/dependencies: Stable task suites for dev/test; robust error handling; safe tool invocation policies.
- Synthetic data factory for targeted model gains
- Sectors: Education, Search, Finance (document QA), Software QA
- What: Autonomous pipelines that synthesize new evaluation and training data (e.g., search-agent tasks, math reasoning items) and track downstream model improvements via the held-out gate.
- Tools/workflows: Data catalogs; data validation (Great Expectations); downstream evaluators (pass@k); data versioning (DVC/LakeFS); prompt libraries.
- Assumptions/dependencies: Clear downstream metrics; safeguards against data leakage; curation/review loops for safety.
- Audit-ready research memory and governance
- Sectors: Regulated industries (Healthcare, Finance), Enterprise R&D
- What: Use HTR as an auditable “research state” linking each change to hypotheses, evidence, and “insight” summaries; supports compliance reviews and reproducible science.
- Tools/workflows: Git-linked hypothesis trees; evidence dashboards; export to experiment-tracking systems; immutable artifact registry.
- Assumptions/dependencies: Organizational policy to treat the tree as the source of truth; traceable evaluators; access controls.
- Model CI/CD with held-out merge gates
- Sectors: MLOps, SaaS, Cloud Platforms
- What: Add a “merge gate” to model deployments—dev improvements explored freely, but production models update only if held-out/regression tests improve.
- Tools/workflows: CI pipelines that call Arbor’s coordinator; blue–green or canary deploys; monitoring for drift; rollback hooks.
- Assumptions/dependencies: High-fidelity staging/held-out; clear SLOs; cost-aware evaluation policies.
- Quant research loop with out-of-sample discipline
- Sectors: Finance
- What: Encode trading hypotheses (signals, risk models) as tree nodes; executors run backtests on dev periods; promotion requires out-of-sample (held-out) gains—reduces overfitting and p-hacking.
- Tools/workflows: Backtest engines; data partitions; risk dashboards; compliance logging.
- Assumptions/dependencies: Non-leaky split; stable data pipelines; risk controls; human-in-the-loop review for deployment.
- Search and recommendation tuning
- Sectors: E-commerce, Media, SaaS
- What: Iterative ranking/prompt/harness improvements that only roll out if A/B test or holdout improves; track failed hypotheses as reusable constraints.
- Tools/workflows: A/B test platforms; offline evaluators (NDCG, CTR models); feature flags; hypothesis tree to guide next experiments.
- Assumptions/dependencies: Statistically powered A/B tests; guardrails for user impact.
- Academic lab “autonomous RA”
- Sectors: Academia, Nonprofits
- What: Continuous experiment runner that records competing directions, ablations, and reusable insights; helps with reproduction and long-horizon studies.
- Tools/workflows: HPC schedulers; lab Git repos; paper-ready evidence exports; preregistration via hypothesis nodes.
- Assumptions/dependencies: Clear experiment APIs; compute quotas; data-use approvals.
- Government digital-service A/B testing assistant
- Sectors: Public Sector/Policy
- What: Hypothesis-driven iteration on service flows (form layouts, prompts) with held-out gating on citizen outcome metrics; improves transparency.
- Tools/workflows: Analytics platforms; privacy-compliant data collection; tree-based audit trail for decisions.
- Assumptions/dependencies: Ethical review; privacy constraints; non-manipulative optimization objectives.
- Personal workflow and automation optimizer
- Sectors: Daily Life/Prosumer
- What: Improve personal scripts, spreadsheets, and automations (e.g., budgeting macros, task sorting rules) with dev/test checks and rollback safety.
- Tools/workflows: Local git; task runners; sandboxed editors; small unit-test suites as evaluators.
- Assumptions/dependencies: Minimal evaluators/unit tests; user comfort with version control; local safety.
- Open-source “performance PR bot”
- Sectors: Software, OSS
- What: Bot proposes performance or reliability PRs with evidence (benchmarks, tests) and an attached hypothesis tree; maintainers review with full context.
- Tools/workflows: GitHub Apps; CI benchmarking; PR templates with dev/test results; issue-to-hypothesis linking.
- Assumptions/dependencies: Maintainer consent; reliable benchmarks; resource limits for CI.
Long-Term Applications
These applications extend Arbor’s methods to broader domains and scales, requiring further R&D, integration, or governance.
- Autonomous interdisciplinary “AI Scientist” with instrument control
- Sectors: Materials, Chemistry, Bio, Robotics
- What: HTR orchestrates wet-lab or fabrication experiments via lab robots; executors implement protocols; merge gate requires independent replications.
- Tools/workflows: Lab automation (SiLA/OPC-UA), ELNs, robotic platforms, LIMS integration.
- Assumptions/dependencies: Safe, robust instrument control; physical-world evaluators; biosafety/ethics approvals.
- Continual self-improving agent platforms with safety gating
- Sectors: Software, Customer Support, DevOps
- What: Production agents evolve harnesses, tools, and policies on shadow traffic; only adopt changes passing held-out or canary gates.
- Tools/workflows: Shadow deployments; safety evaluators; incident response links; red-team corpora as held-out.
- Assumptions/dependencies: Robust sandboxing; monitoring; strong safety tests; rollback discipline.
- Autonomous product R&D loops
- Sectors: SaaS, Consumer Apps, Gaming
- What: End-to-end iteration on features, prompts/UI, and backend models driven by a persistent research state and gated releases.
- Tools/workflows: Feature flag platforms; experimentation frameworks; user-segmentation logic in evaluators.
- Assumptions/dependencies: Consent, fairness, and privacy considerations; governance for automated experimentation.
- Data/compute systems autopilot
- Sectors: Databases, Compilers, Cloud
- What: AO tasks optimize query planners, storage layouts, or compiler passes; promote only if end-to-end latency/throughput improves on held-out corpora.
- Tools/workflows: Microbench suites; real-world traces; reproducible infra snapshots; performance regressions as evidence.
- Assumptions/dependencies: Non-flaky benchmarks; isolation from noisy neighbors; cost controls.
- Healthcare ML and pathway optimization
- Sectors: Healthcare
- What: HTR structures hypotheses over preprocessing, feature engineering, model choices, and clinical workflow nudges; promotion requires external validation.
- Tools/workflows: EHR connectors; de-identified sandboxes; IRB-governed evaluators; bias/fairness tests.
- Assumptions/dependencies: Regulatory compliance; clinical oversight; strong privacy guarantees; generalizable metrics.
- Grid and energy-operation tuning
- Sectors: Energy/Utilities
- What: Optimize forecasting, dispatch heuristics, and maintenance schedules; use seasonal/temporal holdout to avoid overfitting.
- Tools/workflows: Digital twins; scenario simulators; time-based evaluation splits.
- Assumptions/dependencies: High-fidelity simulators; safety margins; regulator approval.
- Robotics policies and sim-to-real pipelines
- Sectors: Robotics, Manufacturing, Logistics
- What: Arbor manages competing control policies and sim configurations; merge gate requires real-world validation batches.
- Tools/workflows: Simulators (Isaac, MuJoCo); deployment sandboxes; safety checks.
- Assumptions/dependencies: Sim-real gap; safe trial protocols; wear-and-tear costs.
- Federated and privacy-preserving AO
- Sectors: Finance, Healthcare, Public Sector
- What: Distributed HTR across sites; nodes share distilled insights without raw data, promoting generalizable improvements.
- Tools/workflows: Secure aggregation; differential privacy; site-specific evaluators.
- Assumptions/dependencies: Interop standards; legal agreements; robust privacy tech.
- Cross-team knowledge graphs of hypotheses and evidence
- Sectors: Enterprise R&D, Academia
- What: Aggregate hypothesis trees across projects to form an institutional memory; surface reusable lessons and negative results.
- Tools/workflows: Knowledge graphs; ontology for hypotheses/evidence; retrieval-augmented planning.
- Assumptions/dependencies: Standardized schemas; incentives for sharing; curation.
- Regulatory and standards frameworks for autonomous research
- Sectors: Policy/Regulation
- What: Define audit/traceability standards around HTR artifacts; require held-out gates for high-stakes automated changes.
- Tools/workflows: Compliance toolkits; certification processes; reproducibility checklists.
- Assumptions/dependencies: Policymaker–industry collaboration; enforcement mechanisms; measurement standards.
- Curated education and training platforms
- Sectors: Education/EdTech
- What: Course modules where students or AIs build hypothesis trees over lab tasks; auto-graded dev/test splits teach scientific method.
- Tools/workflows: LMS integrations; sandboxed evaluators; portfolio exports.
- Assumptions/dependencies: Safe content generation; instructor oversight.
- Marketplace/platform for “Autonomous Research as a Service”
- Sectors: Cloud/DevTools
- What: Managed Arbor instances with adapters for common domains; pay-per-experiment with governance dashboards.
- Tools/workflows: Multi-tenant orchestration; cost/usage quotas; API for evaluators.
- Assumptions/dependencies: Strong isolation; billing transparency; domain adapters.
Notes on Feasibility and Dependencies
- Strong LLM backbone: Many benefits rely on high-capability models for ideation, code edits, and insight distillation; performance degrades with weaker backbones.
- Evaluator quality: Success hinges on faithful, executable evaluators and non-leaky dev/test splits; for real-world systems, A/B tests or out-of-sample validation are essential.
- Compute and cost: Long-horizon runs require budgeting for experiments and tokens; scheduling and early-stopping policies matter.
- Security and safety: Executors run code—enforce sandboxing, dependency pinning, and network egress controls.
- Organizational adoption: Treating the hypothesis tree as the research source of truth requires process changes and tool integration.
- Generalization to non-ML domains: Feasible where hypotheses can be tested via programmatic or instrumented evaluators; harder for purely qualitative objectives without proxy metrics.
Glossary
- Ablations: Controlled removals or variations of system components to assess their contribution to performance. "Ablations, backbone studies, transfer experiments, and cost analyses show that these gains come from Arbor's evidence-structured research process"
- Any Medal: An aggregate benchmark metric indicating that a submission earned at least one medal (bronze/silver/gold) across tasks. "On MLE-Bench Lite, Arbor reaches 86.36% Any Medal with GPT-5.5, the strongest result in our comparison."
- Architecture Design: A task setting where the agent modifies model-training code (e.g., architecture or training pipeline) to improve final loss. "In Architecture Design, we use the autoresearch benchmark"
- Autonomous Optimization (AO): An operational setting where an agent iteratively improves an initial artifact toward a fixed objective, using development feedback but without step-level human supervision. "We formalize this problem as Autonomous Optimization (AO), which captures the core operational form of autonomous research."
- Backpropagate: In Arbor, the step where distilled insights from executed leaves are propagated up the hypothesis tree to update ancestor nodes (distinct from gradient backpropagation). "Backpropagate. When executor reports return, the coordinator writes their evidence into the corresponding leaf nodes and updates insights along the path to the root."
- BrowseComp: A benchmark/task suite focused on web-browsing question answering. "In BrowseComp, the initial material is our standard minimal ReAct-style search harness"
- Coordinator: The long-lived controller that owns the global research state, manages the hypothesis tree, and makes decisions about exploration, pruning, and merging. "A persistent coordinator maintains the research state as a hypothesis tree, iteratively exploring ideas, dispatching executors to implement them, and using evaluation feedback to refine the tree and update the current best artifact."
- Data synthesis: Automated generation of training or evaluation data guided by downstream performance or evaluator signals. "Across six real research tasks in model training, harness engineering, and data synthesis"
- Dev/test split: The separation between development (used for exploration and tuning) and held-out test (used only for validation) to prevent overfitting. "some lack a clear dev/test split, making iterative search prone to overfitting,"
- Development evaluator (E_dev): The executable evaluator used during exploration to provide feedback and guide search. "an executable development evaluator , a held-out test evaluator ,"
- Executor: A short-lived worker that implements a specific hypothesis in an isolated workspace, runs the development evaluator, and returns structured evidence. "Short-lived executors test selected hypotheses in isolated worktrees and return compact reports containing scores, factual results, distilled insights, and artifact references."
- Fitness signals: Executable, quantitative signals used to score candidate programs or artifacts for selection or evolution. "treated LLMs as program mutation operators selected by executable fitness signals"
- Frontier control: The selection policy that manages which pending hypotheses to execute next under partial and delayed feedback. "Thus selection is not merely score maximization; it is frontier control under partial and delayed feedback."
- Git worktree: A Git feature allowing multiple working directories linked to the same repository; used to isolate experiments per hypothesis. "short-lived executors implement individual hypotheses in isolated git worktrees."
- Harness engineering: Improving the control logic and tooling around an agent (e.g., prompting, tool use, evaluation harnesses) to boost task performance. "Across six real research tasks in model training, harness engineering, and data synthesis"
- Held-out admission: The policy of promoting changes to the current best artifact only when they demonstrate improvement on the held-out evaluator. "Exploration with held-out admission."
- Held-out evaluator (E_test): The test evaluator used only for final validation to verify that development gains transfer beyond exploration. "the held-out measures whether the dev-driven improvement transfers beyond the feedback used for exploration."
- Held-out merge gate: A validation gate that requires an improvement on the held-out evaluator before merging a candidate branch into the current best artifact. "Promotion is guarded by a held-out merge gate"
- Hypothesis Tree Refinement (HTR): Arbor’s core method that represents research as a persistent tree linking hypotheses, artifacts, evidence, and insights, refined over time. "Arbor addresses these requirements through Hypothesis Tree Refinement (HTR)"
- Hypothesis tree: The persistent tree-structured research state whose nodes bind a hypothesis, distilled insight, and executable metadata. "the hypothesis tree that serves as Arbor's persistent research state."
- Hypothesis-bound: A constraint that executors must implement and evaluate only the assigned hypothesis (not change it mid-run), preserving the meaning of evidence. "By keeping executors hypothesis-bound, Arbor keeps local engineering flexibility while preserving the semantic meaning of tree updates."
- Insight: A distilled, reusable interpretation of experimental evidence that summarizes what was tried, what happened, and why it matters for future decisions. "The insight stores the reusable interpretation of evidence associated with the hypothesis."
- MLE-Bench Lite: A benchmark for long-horizon ML engineering with standardized scoring and medal thresholds. "On MLE-Bench Lite, Arbor reaches 86.36% Any Medal with GPT-5.5"
- Muon optimizer: A specific optimizer used as a tuned baseline in NanoGPT-Bench experiments. "the official tuned Muon optimizer baseline distributed with NanoGPT-Bench"
- NanoGPT-Bench: A benchmark designed to evaluate and accelerate NanoGPT training. "we use NanoGPT-Bench, a benchmark for accelerating NanoGPT training."
- Pass@k: A metric measuring solution success within k attempts; the paper uses the difference between pass@4 and pass@1 as a difficulty/quality indicator. "mean gap"
- ReAct: A prompting/execution pattern that interleaves reasoning and acting (tool use), here used to build a search harness. "Minimal ReAct-style search harness"
- Research artifact: The concrete, modifiable material (e.g., codebase and data) that the agent improves under a fixed objective. "an agent improves an initial research artifact through iterative experimentation"
- Search frontier: The current set of active directions (nodes/leaves) in the hypothesis tree that are candidates for expansion or execution. "refines the search frontier, and admits verified improvements."
- Terminal-Bench 2.0: A benchmark of terminal-based tasks for evaluating terminal agents/harnesses. "In Terminal-Bench 2.0, the initial material is the standard official terminal-agent codebase for Terminal-Bench 2.0"
- Worktree: An isolated working copy of the repository state used by executors to implement and test a single hypothesis. "It then creates an isolated worktree, applies the minimal intervention needed to realize , runs the evaluator, ..."
Collections
Sign up for free to add this paper to one or more collections.

