AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
Abstract: Scientific research proceeds through iterative cycles of hypothesis generation, experiment design, execution, and revision. AI agents can automate parts of this process, but existing approaches typically follow a single research trajectory or coordinate through a central planner with fixed objectives. As a result, they struggle to sustain parallel exploration, adapt as experimental evidence changes, or preserve knowledge of failed directions over long-running experiments. We introduce AutoScientists, a decentralized team of AI agents for long-running computational scientific experimentation. Agents interpret a shared experimental state, self-organize into teams around promising hypotheses, critique proposals before using experimental compute, and share successes and failures to reduce redundant exploration. Under matched experimental budgets, AutoScientists improves over prior AI agents across biomedical machine learning, language-model training optimization, and protein fitness prediction. On BioML-Bench, spanning biomedical imaging, protein engineering, single-cell omics, and drug discovery, AutoScientists achieves a mean leaderboard percentile of 74.4% across 24 tasks, improving over the strongest AI agent by +8.33%. On GPT training optimization, AutoScientists reaches a target validation bits-per-byte 1.9x faster than Autoresearch and continues discovering improvements from a starting champion where the single-agent approach finds none (7 vs. 0 accepted improvements). On ProteinGym fitness prediction, AutoScientists discovers a method for ACE2-Spike binding that improves over the current state-of-the-art model by +12.5% in Spearman correlation. Applied without modification across all 217 ProteinGym assays, the same method improves over the prior state of the art by +6.5% (Spearman correlation).

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
AutoScientists: A simple guide for teens
1. What is this paper about?
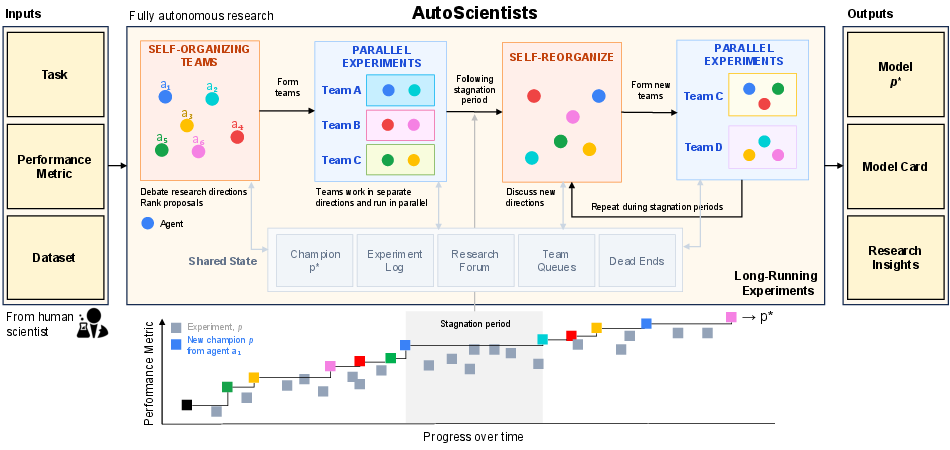
This paper introduces AutoScientists, a team of AI “helpers” that work together like a well-organized science club. Their job is to run long, complicated research projects on computers. Instead of one AI following a single plan, AutoScientists is a group that splits up, tries different ideas at the same time, talks to each other about what’s working, and remembers what failed so they don’t repeat mistakes.
2. What questions are the researchers trying to answer?
The paper asks:
- How can AI keep making progress on long projects where the best ideas change over time?
- Can a group of AI agents explore many ideas in parallel and reorganize themselves as new evidence appears?
- Can they use past failures to avoid wasting time and compute?
- Does this teamwork approach beat strong single-AI systems in areas like biomedical modeling, protein science, and training LLMs?
3. How does AutoScientists work? (With simple analogies)
Think of a school science club tackling a big project:
- There’s no single boss. Instead, everyone sees the same shared “bulletin board” that tracks:
- the current best solution (the “champion”),
- every experiment tried and its outcome (the “experiment log”),
- a forum where people post ideas and critiques,
- and a “dead-end list” of things that didn’t work so they don’t repeat them.
- The work happens in two repeating phases: 1) Discussion: Members propose ideas, critique each other, and form teams around the most promising directions. 2) Execution: Teams run experiments in parallel, write down results, and update the shared board.
- Roles in each team:
- Analyst agents: like idea scouts and librarians. They scan past results, suggest new experiments, and prioritize ideas that haven’t been tried or look promising.
- Experiment agents: like builders and testers. They change code, run the training or analysis, and report back.
- Self-organization: If a team’s direction stops producing improvements, the agents call a new discussion, regroup, and try different directions. Teams can split, merge, or reshuffle members as evidence changes.
- Double-checking improvements: Because some results can be lucky flukes, the system verifies apparent gains by running them more than once before updating the “champion.”
In short, AutoScientists is a self-organizing, long-running group chat plus shared notebook that helps a team of AI researchers explore smarter and faster.
Here are a few key terms in simple words:
- AI agent: a software assistant that can read instructions, write code, run experiments, and summarize results.
- Shared state: the common notebook everyone reads and writes to.
- Champion: the current best method or model found so far.
- Dead-end registry: a “mistakes notebook” so the team doesn’t retry bad ideas.
- Spearman correlation: a score for how well a model ranks things from low to high (higher is better).
- Validation bits-per-byte (bpb): a score for LLM training where lower is better, meaning the model is learning efficiently.
4. What did they find, and why does it matter?
Across different kinds of science and AI tasks, AutoScientists beat strong existing systems that use one agent or a fixed plan.
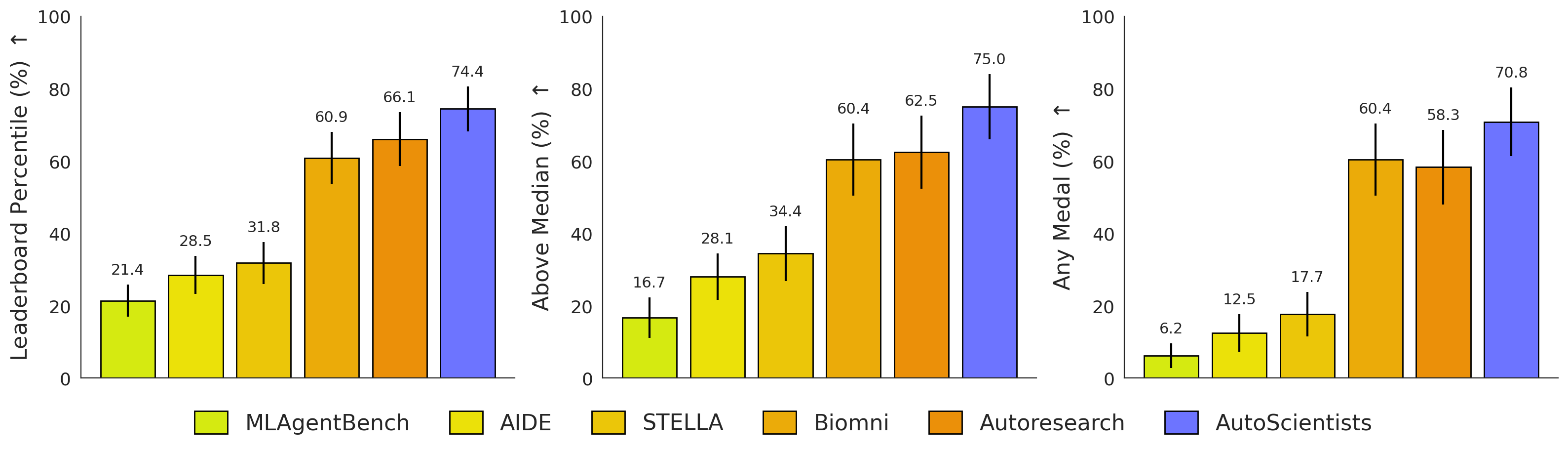
- Biomedical machine learning (24 tasks across imaging, drug discovery, protein engineering, and single-cell data):
- AutoScientists reached an average leaderboard percentile of about 74%, compared to about 66% for a strong single-agent baseline with the same compute budget.
- Biggest gains showed up in drug discovery tasks.
- It completed all 24 tasks and showed better selection of experiments over time.
- Training a small GPT-like model (“nanochat”):
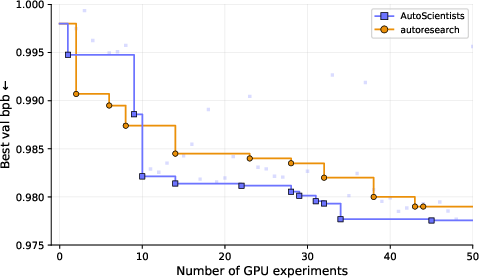
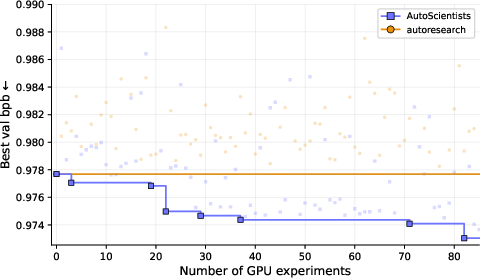
- Starting from the same baseline, AutoScientists got to a target quality almost twice as fast (1.9× fewer experiments).
- Starting from a strong model, AutoScientists found 7 further improvements, while the single-agent system found none in 100 tries. This shows the team explores a wider variety of ideas instead of getting stuck.
- Protein science (ProteinGym benchmark):
- On a tough test of predicting how protein changes affect function, AutoScientists improved a top method (called Kermut).
- On one development task (ACE2–Spike binding), it improved a key ranking score by about 12.5%.
- Using the same discovered recipe on 217 different protein tasks, it improved the overall score by about 6.5% over the previous best.
- What makes the most difference?
- The researchers turned off parts of the system one by one. Different parts mattered more on different tasks:
- Having analyst agents improved idea quality.
- Cross-agent feedback (critiques and sharing near misses) helped when signals were noisy.
- Self-organization (reforming teams) helped when the best direction changed mid-run.
- The shared record prevented duplicated effort and kept everyone aligned.
- No single feature explained all the gains; they worked together.
5. Why is this important? What could it change?
Scientific experiments—especially in areas like drug discovery, protein engineering, and AI training—are expensive and time-consuming. AutoScientists shows a way to:
- Use limited experiment budgets more wisely by filtering weak ideas before running them.
- Keep track of what failed so time isn’t wasted repeating mistakes.
- Adapt as new results arrive, letting the team change direction quickly.
- Continue improving even after strong single-agent methods stall.
This could speed up progress in many fields that rely on computational experiments and help humans and AI collaborate better on long, tricky problems.
A few limitations and future directions:
- It uses more language-model “thinking” (more AI messages) than a single-agent system, which can cost more, though it saves experimental compute by choosing better experiments.
- In their tests, experiments often ran on one GPU at a time, so the system’s full parallel power wasn’t always used. Running on more GPUs could make it even faster.
- The team size is fixed at the start; future versions could scale up or down based on task difficulty.
Overall, AutoScientists suggests that smart teamwork—without a strict boss—can help AI do long, evolving scientific work more effectively.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, prioritized list of concrete gaps the paper leaves unresolved and actionable questions for future work.
- Scalability with parallel hardware: Quantify wall-clock speedups, throughput, and failure rates as the number of GPUs and concurrent experiments increase (e.g., 2→64 GPUs), including contention on shared state, queue latency, and synchronization overhead.
- Cost-efficiency and token budgets: Characterize the performance–cost trade-off by capping or varying LLM-call/token budgets, and report cost-normalized gains versus single-agent baselines.
- LLM-backend dependence: Validate the “LLM-agnostic” claim by replicating results with diverse backends (e.g., GPT-4o, Llama 3.1, Mixtral) and measuring sensitivity to model quality, coding abilities, and context length.
- Dynamic team sizing and resource allocation: Develop and evaluate policies for auto-scaling the number of agents and rebalancing compute across teams (e.g., bandit or Bayesian allocation) based on observed marginal utility.
- Noisy evaluation robustness: Move beyond two-seed confirmation by implementing sequential testing, bootstrap confidence intervals, and FDR control; measure false-positive/false-negative rates of accepted improvements under heteroscedastic noise.
- Dead-end registry risks: Study premature pruning and propose mechanisms to “reopen” dead-end directions when context changes (e.g., conditional dead-ends, timeouts, or re-checks after major champion shifts).
- Proposal filtering efficacy: Quantify the critique gate’s precision/recall (what fraction of rejected/accepted proposals were actually harmful/beneficial), compute saved, and time-to-accept across domains.
- Knowledge management at scale: Evaluate retrieval, summarization, and forgetting strategies as the shared forum/logs grow (e.g., vector search, hierarchical summaries), and measure decision quality versus memory size.
- Orchestration overhead vs. end-to-end time: Report wall-clock timelines including discussion, roster updates, and I/O, not just “experiments-to-target”; isolate orchestration latency from training time.
- Sensitivity to heuristics and triggers: Systematically sweep thresholds (e.g., “no improvement in last 10 runs”) and roster update rules; quantify how these choices affect convergence, diversity, and performance.
- Conflict resolution and code merging: Analyze failure modes when concurrent code edits collide; design and evaluate automated merge, test, and rollback strategies for conflicting experiments.
- Agent composition and diversity: Test heterogeneous teams (different models, toolsets, or “temperaments”) and quantify whether cognitive diversity improves exploration and reduces groupthink.
- Human-in-the-loop integration: Compare fully autonomous runs to hybrid setups with periodic human review; measure added value, safety, and opportunity for scientific insight extraction.
- Multi-objective optimization: Extend to Pareto optimization and constraints (e.g., Spearman’s ρ and MSE in ProteinGym; accuracy, latency, and memory in ML tasks) and evaluate Pareto fronts and trade-off policies.
- Theoretical guarantees and sample efficiency: Formalize the search as decentralized bandits/BO and derive bounds or conditions where self-organization outperforms centralized planners.
- Generalization to wet-lab or hardware-in-the-loop settings: Assess feasibility, scheduling, and safety when experiments have long latencies, batch constraints, and irreversible costs.
- Robustness to distribution shift and leakage: Test stability under dataset shift, cross-benchmark transfer, and repeated validation access (risk of overfitting); adopt nested CV or lockbox validation for long-running search.
- Benchmark breadth and external validity: Go beyond GPT nanochat and ProteinGym supervised substitution to larger LLM training tasks, diverse protein fitness regimes (indels, unsupervised), and harder imaging tasks; include multiple random seeds/runs.
- Fair comparison controls: Report variance across independent runs; normalize for both experimental compute and LLM-token costs; include additional multi-agent baselines (e.g., centralized planners, debate systems) on the same hardware/code.
- Memory/context window limits: Investigate how agents maintain situational awareness as logs/forum grow beyond context; benchmark chunking, retrieval, and summarization policies on decision quality and error rates.
- Exploration–exploitation balance and anti-groupthink mechanisms: Track proposal diversity metrics over time; introduce explicit novelty bonuses or diversity priors and evaluate their effect on sustained improvement.
- Credit assignment and provenance: Implement fine-grained attribution (which agent/idea led to what gains) for auditing, reproducibility, and incentive design; study how attribution affects future proposal quality.
- Safety, security, and compliance: Assess risks from autonomous code execution (sandboxing, dependency pinning, data-access controls), and define guardrails for tool use and external API interaction.
- Interpretability of discovered science: Evaluate whether the generated reports and shared-state artifacts provide causal/mechanistic insight (not just performance gains), and test with expert user studies.
- Imaging domain underperformance: Diagnose bottlenecks (data scale, augmentation, architecture search) and test targeted remedies (e.g., stronger vision backbones, longer runs, curriculum search) under the same framework.
- Transfer and lifelong learning across tasks: Enable reuse of accumulated skills/recipes across tasks and quantify warm-start benefits versus cold starts, including catastrophic interference risks.
- Revisit roster consolidation design: Only the last agent in discussion consolidates the roster—evaluate alternate consolidation protocols (e.g., quorum-based, rotating lead) and their impact on bias, stability, and exploration.
- Policy for noise-floor recalibration: Analyze risks of over-calibrating to noise in GPT optimization; define principled criteria for recalibration triggers and their downstream effects.
- Reproducibility under evolving dependencies: Stress-test runs with strict environment pinning, deterministic seeds, and containerized toolchains; quantify reproducibility drift over long horizons.
Practical Applications
Immediate Applications
The following use cases can be deployed today by leveraging AutoScientists’ decentralized agent teams, shared experimental state, and proposal-critique-before-execution workflow.
- Continuous optimization of ML training pipelines (Software/AI/ML)
- What: Use analyst and experiment agents to propose, critique, and run small, parallel training changes (architecture, optimizer, schedule) and automatically promote confirmed improvements.
- Tools/products/workflows: “Agent-driven MLOps” layer that sits atop MLflow/Weights & Biases; GitHub/GitLab CI bots implementing analyst/experiment roles; noise-gated promotion checks; automatic model-card generation.
- Assumptions/dependencies: Requires GPU budget; reliable coding LLM backend; safe sandboxing for code execution; measurable validation metric; organizational tolerance for higher LLM-token overhead to save experimental compute.
- Faster hyperparameter/architecture search for LLMs and in-house models (Software/AI/ML)
- What: Parallel exploration of optimizer/compile/autotuning schedules to reach target loss with fewer experiments (as shown on GPT nanochat).
- Tools/products/workflows: AutoScientists-as-a-service for training efficiency; hooks into training scripts to read/write champion, logs, and dead-end registry.
- Assumptions/dependencies: Compute availability; trustworthy validation signals; guardrails against overfitting to dev metrics.
- Drug discovery model development and leaderboard advancement (Healthcare/Pharma)
- What: Build and iterate end-to-end QSAR and ADMET predictors (e.g., hERG, plasma protein binding), using shared dead-end registries to avoid repeated failures and discussion phases to redirect exploration.
- Tools/products/workflows: Agent-augmented cheminformatics pipelines (RDKit, TDC, Polaris); “negative-knowledge” registries integrated into ELNs; auto-generated model cards for regulatory files.
- Assumptions/dependencies: High-quality labeled datasets; data-use governance; sandboxed compute; human review for deployment decisions.
- Protein variant-effect prediction upgrades (Healthcare/Biotech)
- What: Apply the discovered AutoScientists-Kermut recipe for supervised substitution fitness prediction to improve variant ranking across assays.
- Tools/products/workflows: Drop-in predictor for DMS-style tasks; integration into protein design and screening platforms; standardized reporting of Spearman’s ρ and MSE.
- Assumptions/dependencies: Assay comparability; acceptable runtime for GP ensembles; validation on target proteins; clear objective prioritization if rank vs. calibration trade off matters.
- Single-cell and imaging ML pipeline refinement (Healthcare/Research)
- What: Use agent teams to select preprocessing, architectures, and training protocols for single-cell omics and imaging tasks under a fixed compute budget.
- Tools/products/workflows: AutoScientists wrappers for Scanpy, MONAI, or custom pipelines; shared forum for mechanistic notes and cross-task transfer of ideas.
- Assumptions/dependencies: Reproducible evaluation protocols; data privacy; compute quota.
- Reproducible experimentation with automatic provenance and model cards (Industry/Academia)
- What: Produce complete artifacts (champion code, hyperparameters, experiment logs, dead-end registry, research narrative) for audit and reproducibility.
- Tools/products/workflows: “Agent ELN” that mirrors the shared forum/logs; model-card generator integrated into CI/CD.
- Assumptions/dependencies: Version-controlled code/data; buy-in to adopt standardized state schemas.
- Competitive data-science support for benchmarks and challenges (Education/Community/Industry)
- What: Deploy agents to explore diverse modeling paradigms in parallel on public tasks (e.g., Kaggle, BioML-Bench) and summarize winning directions.
- Tools/products/workflows: Lightweight orchestration to attach to challenge repos; auto-summaries of what worked/failed to reduce onboarding time.
- Assumptions/dependencies: Clear evaluation metric; permissive competition rules for automation; compute limits.
- Evidence-sharing to reduce duplicate work across teams (Industry R&D)
- What: Use the shared dead-end registry and forum to prevent repeated exploration of failed directions across product lines or teams.
- Tools/products/workflows: Organization-wide “negative results” knowledge base; API to query prior attempts by axis/effect size.
- Assumptions/dependencies: Cultural shift to log and reward negative results; metadata standards for tagging experiments.
- Structured proposal critique before spending compute (All sectors)
- What: Introduce conference-style internal review where agents (and optionally humans) critique experiment proposals to filter weak ideas pre-run.
- Tools/products/workflows: Proposal queues with templated justifications; reviewer agents with domain heuristics; acceptance thresholds linked to effect-size priors.
- Assumptions/dependencies: Calibrated prior beliefs; well-scoped safety policies to avoid blocking novel ideas.
- Teaching the scientific method via agent labs (Education)
- What: Classroom “virtual lab teams” that iterate hypotheses, run code experiments, document dead ends, and write research summaries.
- Tools/products/workflows: Course kits using AutoScientists with sandbox datasets; grading on process artifacts, not just final scores.
- Assumptions/dependencies: Faculty oversight; curated tasks that run on modest compute; safe coding sandboxes.
Long-Term Applications
These use cases are promising but require further research, integration with physical systems, scaling, governance, or standardization before routine deployment.
- Closed-loop wet-lab science with robots (Healthcare/Chemistry/Materials)
- What: Connect AutoScientists to lab automation (e.g., liquid handlers, microscopy) for hypothesis-to-experiment cycles in protein engineering, cell assays, or materials synthesis.
- Tools/products/workflows: Orchestration bridging LIMS/ELN, robotic schedulers, and shared state; safety layers for experiment approval; multi-objective optimization.
- Assumptions/dependencies: Reliable lab hardware integration; biosafety and ethical review; robust uncertainty estimation; real-world noise and failure handling.
- Cross-institution, privacy-preserving collaborative discovery (Healthcare/Public sector)
- What: Federated agent teams that share proposals, effect sizes, and negative knowledge while keeping raw data local (e.g., hospital networks training models on-site).
- Tools/products/workflows: Federated versions of the shared state; secure aggregation; provenance standards.
- Assumptions/dependencies: Privacy regulation compliance (HIPAA/GDPR); secure enclaves; standardized metrics across sites.
- Autonomous discovery engines for early-phase drug programs (Pharma/Biotech)
- What: Persistent agent teams that maintain competing hypotheses across modalities (omics, structure, assays), dynamically reallocate compute, and synthesize evidence over months.
- Tools/products/workflows: Portfolio-level orchestration; assay-selection agents; long-horizon memory and hypothesis lifecycles; integration with IP management.
- Assumptions/dependencies: Reliable cross-modal data pipelines; governance to prevent bias; human-in-the-loop decision gates; validation in prospective studies.
- General-purpose “R&D memory” for organizations (Industry/Academia)
- What: Institutional memory that records hypotheses, attempts, failures, and successes across programs and years, enabling rapid onboarding and avoiding rediscovery.
- Tools/products/workflows: Enterprise knowledge graph of experiments; search over “what’s been tried and why it failed”; retention and access policies.
- Assumptions/dependencies: Metadata interoperability; incentives to document; change management.
- Policy analysis and evidence synthesis with competing hypotheses (Government/Think tanks)
- What: Agents maintain parallel policy hypotheses, run simulations/sensitivity analyses, record dead ends, and produce transparent narratives of why certain options are favored.
- Tools/products/workflows: Integration with econometric and ABM simulators; traceable assumption logs; counterfactual experimentation.
- Assumptions/dependencies: High-quality causal models; data access agreements; oversight to avoid LLM hallucinations driving policy.
- Safety-critical configuration search (Aviation/Medical devices/Robotics)
- What: Certifiable, noise-aware, multi-agent optimization of controller parameters or device configurations with strict verification gates.
- Tools/products/workflows: Formal verification hooks; conservative noise gates; adversarial test generation agents.
- Assumptions/dependencies: Standards compliance (e.g., DO-178C, IEC 62304); traceability; rigorous simulation-to-real validation.
- Materials and energy system design (Energy/Manufacturing)
- What: Long-running, hypothesis-driven search for catalysts, battery materials, or process parameters with automated dead-end avoidance and cross-lab sharing.
- Tools/products/workflows: Coupling with high-throughput computation (DFT/MD) and experimental robotics; multi-objective (performance, cost, stability) orchestration.
- Assumptions/dependencies: Reliable simulators or surrogate models; lab integration; lifecycle and sustainability constraints.
- Marketplace and cloud platforms for “AutoScientists-as-a-Service” (Software/Cloud)
- What: Managed offerings that provide analyst/experiment agent teams, shared-state backends, and UI dashboards for experiment orchestration under user-specified budgets.
- Tools/products/workflows: APIs for champion/experiment logs; billing by experiment or improvement; templates per sector (biomed, NLP, vision).
- Assumptions/dependencies: Vendor neutrality; data/IP protection; transparent cost-performance guarantees.
- Open standards for negative results and shared experimental state (Standards/Community)
- What: Community schemas for experiment logs, dead-end registries, and champion lineage to enable tool interoperability and meta-analyses.
- Tools/products/workflows: JSON/Protobuf schemas; registries akin to model hubs; integration with FAIR principles.
- Assumptions/dependencies: Broad adoption; governance for quality control; incentives for sharing.
- Household and personal research assistants for advanced users (Daily life/Prosumer)
- What: Personal agents that manage long-running coding/data experiments (e.g., home automation ML, hobby bioinformatics), maintain logs, and avoid redoing failed ideas.
- Tools/products/workflows: Desktop sandboxes; lightweight GPU/edge integration; simplified UIs for proposal critique.
- Assumptions/dependencies: Accessible compute; safe code execution; curated tasks with clear metrics.
Notes on feasibility across applications:
- Compute is the main bottleneck for parallelism; benefits scale with available GPUs/CPUs.
- Outcomes depend on LLM coding quality; results may vary with different backends.
- Best suited to computational experiments with clear, automatable metrics; physical domains require robust lab integration and safety governance.
- The system trades higher LLM-token usage for better experimental-compute efficiency; budget planning should account for both.
Glossary
- ACE2--Spike binding: The binding interaction between the human ACE2 receptor and the SARS-CoV-2 Spike protein, often used as a protein fitness assay target. "improves ACE2--Spike binding Spearman's from $0.747$ to $0.840$."
- Ablation: A controlled removal or disabling of a system component to measure its contribution to performance. "These findings motivate our ablation studies and comparison to single-agent baselines like Autoresearch."
- AUROC: Area Under the Receiver Operating Characteristic curve; a threshold-independent metric for binary classification performance. "AUROC ()"
- Bits-per-byte (bpb): A compression-style metric for LLMs that measures average bits per input byte; lower is better. "validation bits-per-byte (val_bpb; lower is better)."
- Champion (): The current best-performing program/model configuration found during the search. "a champion tracking the current best model with full hyperparameters and reproduction instructions"
- Compile autotuning: Automated compiler-driven kernel/tuning selection to optimize runtime performance. "compile autotuning"
- Consensus-based discussion: A coordination approach where agents debate to reach agreement before action. "central coordinators, consensus-based discussion, or fixed decompositions of the search space"
- Cross-agent feedback: Structured critique and information exchange among agents about proposals and results. "No cross-agent feedback disables comment threads on proposals and results, so agents cannot critique each other or share near-misses across teams"
- Cross-validation (CV): An evaluation protocol that partitions data into folds to estimate generalization. "across all three CV schemes."
- Dead-end registry: A shared log of failed or unproductive experimental directions to avoid redundant exploration. "track failed experiments in a dead-end registry "
- Deep mutational scanning (DMS) assays: High-throughput experiments measuring functional effects of many protein variants. "comprising 217 DMS assays across UniProt/function groups."
- Ensemble: A model that combines multiple predictors to improve robustness or accuracy. "The discovered predictor is a three-GP ensemble"
- Final-learning-rate fraction: A schedule parameter controlling the ending learning rate as a fraction of the initial or peak value. "final-learning-rate fraction"
- Gaussian process (GP): A Bayesian nonparametric model defined by a mean function and kernel, used for regression/classification with uncertainty estimates. "a Gaussian-process method for supervised protein variant-effect prediction"
- Greedy diversity-based feature selection: A heuristic that incrementally selects features to maximize diversity/coverage of information. "greedy diversity-based feature selection, and quantile-warped targets."
- Heartbeat (loop): A periodic execution cycle in which an agent reads state, acts, and writes results. "Each agent is repeatedly invoked by a deterministic monitor process in a heartbeat loop."
- hERG: A cardiac potassium channel (KCNH2) whose blockade is a key safety concern in drug discovery. "TDC hERG Blocking Prediction model discovered by AutoScientists."
- Leaderboard percentile: Percentile rank of a submission relative to others on a benchmark leaderboard. "Performance on 24 biomedical tasks measured by leaderboard percentile (left)"
- Matrix initialization: The strategy for setting initial parameter values of matrices (e.g., weights) before training. "matrix initialization"
- Mean squared error (MSE): Average squared difference between predictions and targets; a common regression loss. "MSE increasing slightly by 0.006."
- Negative-knowledge file: A document that records previously explored and failed directions to guide future search. "negative-knowledge file EXPLORED.md listing previously dead-ended directions."
- Noise band: The expected range of metric variation due to stochasticity, used to judge whether changes are significant. "improvements within the empirically measured noise band are confirmed on a second seed before promotion to "
- Noise-floor recalibration: Adjusting the estimated baseline variability to correctly interpret small metric changes. "noise-floor recalibration of the starting champion"
- Odds ratio: A measure of association used to compare the odds of an outcome between groups. "(Odds Ratio , the largest proportional drop in the table)"
- Out-of-fold: Refers to evaluations or predictions made on the held-out fold during cross-validation. "out-of-fold Spearman correlation"
- Pearson correlation: A measure of linear correlation between two continuous variables. "Pearson correlation , leaderboard percentile "
- ProteinGym: A benchmark suite for protein fitness prediction across many assays and proteins. "the full ProteinGym supervised substitution benchmark"
- Quantile warping: A monotonic transformation that maps values to target quantiles to better align distributions. "quantile-warped targets."
- Query-key normalization order: The sequence in which normalization is applied to query and key vectors in attention mechanisms. "query-key normalization order"
- Rank-oriented model selection: Choosing models based on rank-based metrics (e.g., Spearman’s rho) rather than calibration. "rank-oriented model selection"
- Self-organization: Decentralized coordination where teams/roles form and adapt without a central controller. "a self-organizing agent team for long-running scientific experimentation"
- Softcap value: A saturation-style hyperparameter that limits or soft-bounds a quantity during training or scoring. "softcap value"
- Spearman's rho: A rank correlation coefficient assessing monotonic association between two variables. "Spearman's "
- UniProt: A comprehensive, curated repository of protein sequence and functional information. "across UniProt/function groups."
- Value-embedding gate width: The dimensionality/width of a gating mechanism applied to value embeddings in a model. "value-embedding gate width"
- Variant-effect prediction: Modeling to estimate the functional impact of sequence variants (e.g., mutations) on proteins. "protein variant-effect prediction"
- Zero-shot features: Features derived without task-specific training (e.g., pretrained embeddings) used directly in new tasks. "expanded zero-shot features"
Collections
Sign up for free to add this paper to one or more collections.