- The paper presents a novel reinforcement learning framework, ARBOR, that introduces process-level rewards via a reusable rubric buffer.
- It leverages contrastive induction and a dynamic rubric memory to score diverse search trajectories, reducing zero-gradient events by up to 61%.
- Experimental results show consistent accuracy gains of up to 4.2 points across multi-hop QA tasks, highlighting improved reasoning efficiency.
ARBOR: Process-Level Reward via a Reusable Rubric Buffer for LLM-Based Search Agents
Current LLM-based search agents typically rely on outcome-only reward signals—predominantly final answer correctness—during reinforcement learning. This paradigm fundamentally overlooks the qualitative diversity in search trajectories (Figure 1): agents can pursue markedly different reasoning and tool-use processes yet receive identical rewards for converging to the same final answer. When RL training is conducted with group-relative objectives such as GRPO, this outcome homogeneity leads to frequent zero-gradient events, stalling policy improvement precisely in regions where process-level differences are most informative.
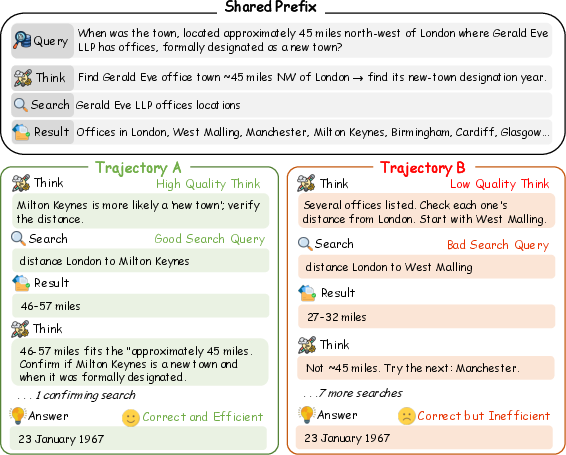
Figure 1: Process quality divergence under identical outcomes. Two trajectories from the same query reach the same answer yet differ markedly in search efficiency.
Existing approaches to process-level supervision either introduce costly verifier models or apply per-query rubrics with no cross-query reusability, resulting in inconsistent and ephemeral process criteria. This creates a gap: there is a need for process rewards that (1) functionally supervise search strategies, (2) constitute reusable, cross-query criteria, and (3) co-evolve with policy distribution to avoid reward staleness.
ARBOR Framework: Adaptive, Reusable Rubric Buffer
ARBOR (Adaptive Rubric Buffer for Online Reward) directly addresses this need. It introduces an architecture for persistent process-level reward, operationalized via a memory buffer of rubrics that are induced, consolidated, and retired online as RL training proceeds (Figure 2).
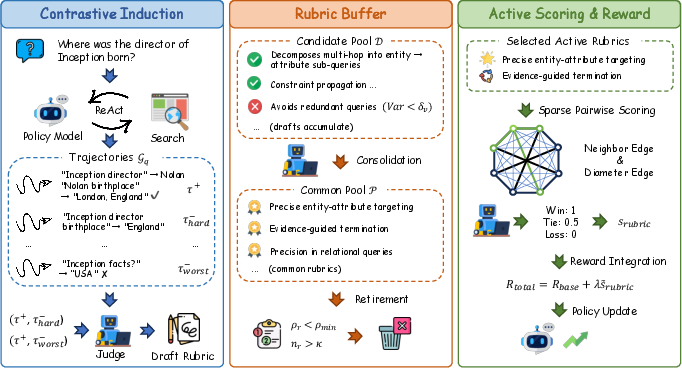
Figure 2: Overview of ARBOR. (a) Contrastive induction extracts query-local draft rubrics from trajectories within a query group. (b) The rubric buffer admits drafts into a candidate pool, consolidates them into a common pool, and retires stale rubrics. (c) At each step, two active common rubrics are selected for sparse pairwise trajectory scoring.
Contrastive Induction
For each query group, ARBOR identifies representative positive ("best") and negative ("worst"/"hard negative") trajectories according to F1 with respect to the gold answer. An external LLM then generates a small set of natural language process rubrics that describe the key process differentiators responsible for success or failure. This induces local, query-specific rubrics via contrastive analysis, focusing strictly on process (not outcome content).
Buffer Lifecycle: Admission, Consolidation, Retirement
Draft rubrics enter a candidate pool D after passing discriminativeness and base reward correlation criteria. Upon reaching a threshold, D is fed into a consolidation module (again LLM-powered), which abstracts generalizable process patterns into the common pool P—the reusable rubric set. Stale rubrics are retired based on their ongoing variance and predictive utility relative to base reward and policy evolution.
Sparse Process-Based Scoring and Reward Augmentation
At every training step, two active rubrics from P are used to score all sampled trajectories in the query group by sparse pairwise LLM judgment. The resultant process-based scores are centered and combined additively with the base RL reward, thus injecting process-level gradient even where the outcome signal is degenerate.
Experimental Evaluation
The framework was evaluated on four multi-hop QA tasks (Bamboogle, HotpotQA, MuSiQue, 2Wiki), using Qwen3 backbones of varying scale. ARBOR is compared against key baselines: outcome-only RL (GRPO), DAPO (which skips outcome-homogeneous groups), and prompting-only variants.
Main Results
ARBOR provides consistent and substantial improvements over outcome-only and non-reusable process reward systems. On average, ARBOR lifts LLM-judge accuracy by up to 4.2 points and reduces the fraction of zero-gradient (outcome-homogeneous) training groups by up to 42%. The improvements hold across all backbones and benchmarks, with the relative gains on LLM-judged semantic answer quality exceeding those on lexical metrics (EM, F1), underscoring the effectiveness of persistent process supervision.
Ablations and Diagnostics
Impact of Reusable Rubric Memory
Figure 3 provides a critical comparison: ARBOR's ablation to single-use, per-query rubrics (either reference-conditioned as in Rubrics-as-Rewards, or contrastively induced but non-recycled) does not yield the same robustness or performance—ARBOR's reusable rubric memory provides 1–2.7 accuracy points improvement across scales, highlighting that the primary benefit stems from the abstraction and cross-query reusability of high-value process standards.
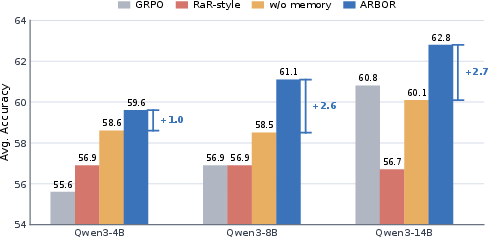
Figure 3: Effect of reusable rubric memory. Average LLM-judge accuracy across four benchmarks.
Rescue of No-Gradient Groups
ARBOR directly transforms the RL-relevant landscape: it reduces the number of all-correct and all-wrong (reward-homogeneous) training groups by up to 61%, enabling continued learning in regions where outcome-only RL is entirely blind.
Analysis of Rubric Reuse
Figure 4 demonstrates that a small core set of consolidated rubrics drives a disproportionate amount of scoring events, indicating that the memory's abstraction focus produces high-utility, policy-adaptive process criteria.
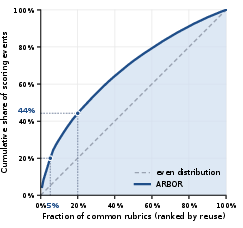
Figure 4: Cumulative share of scoring events covered by the top fraction of common rubrics, ranked by reuse count.
Theoretical and Practical Implications
ARBOR's design relaxes the fundamental bottleneck of outcome-only RL for search agents by providing persistent, evolving supervision for process-level behaviors. Practically, this enables RL-trained agents to stably improve reasoning strategies—such as targeted query formulation and termination judgment—even when outcome signals plateau, and these improvements generalize across queries by construction. Theoretically, ARBOR demonstrates the viability and effectiveness of converting local process observations into global, reusable reward signals—a paradigm adaptable to other non-verifiable, multi-step agentic settings.
Future Prospects
The rubric memory architecture is agnostic to the domain and toolset; its deployment can be envisaged in more complex reasoning environments, program synthesis, and mathematical problem solving, provided the process structure is observable. Scaling up rubric consolidation (e.g., by curriculum learning or transfer across RL tasks) and integrating more capable judge or induction LLMs are likely next steps. Moreover, extending the buffer's life cycle or introducing meta-learning for the rubrics themselves opens avenues for more autonomous and effective process reward generation.
Conclusion
ARBOR materially advances RL for LLM-based search agents by providing persistent, reusable, and policy-evolving process-level reward via an online rubric memory and consolidation mechanism. The empirical evidence demonstrates both robust accuracy gains and more efficient utilization of training samples, especially in reward-homogeneous settings where standard RL plateaus. This approach reframes process knowledge as an evolving, persistent reward resource, offering a new foundation for RL in complex, non-verifiable domains.