- The paper introduces Mirage, a latent spatial memory system that leverages VAE latent tokens to preserve 3D scene structure without costly per-frame RGB rasterization.
- It achieves superior 3D consistency and efficiency by using depth-guided back-projection and dynamic object filtering, resulting in 10.57× faster generation and 55× lower GPU memory usage.
- Empirical evaluations on WorldScore and RealEstate10K confirm Mirage’s robust long-horizon spatial anchoring and high-quality novel view synthesis under dynamic camera trajectories.
Latent Spatial Memory: Efficient and Consistent 3D Video Generation
Motivation and Prior Approaches
The task of 3D-consistent video generation necessitates maintenance of spatial consistency across generated frames, particularly as the camera traverses complex trajectories in dynamic scenes. Conventional video world models employ explicit spatial memory structures in pixel (RGB) space, typically based on point cloud caches constructed by lifting observed frames via depth estimation. This prevailing strategy enforces multi-view consistency but imposes two major limitations: (1) repeated pixel-space rasterization and VAE re-encoding are computationally expensive and infeasible for long rollouts; (2) RGB caches discard rich latent-space features learned by the backbone, thereby incurring representational loss and degrading conditioning fidelity.
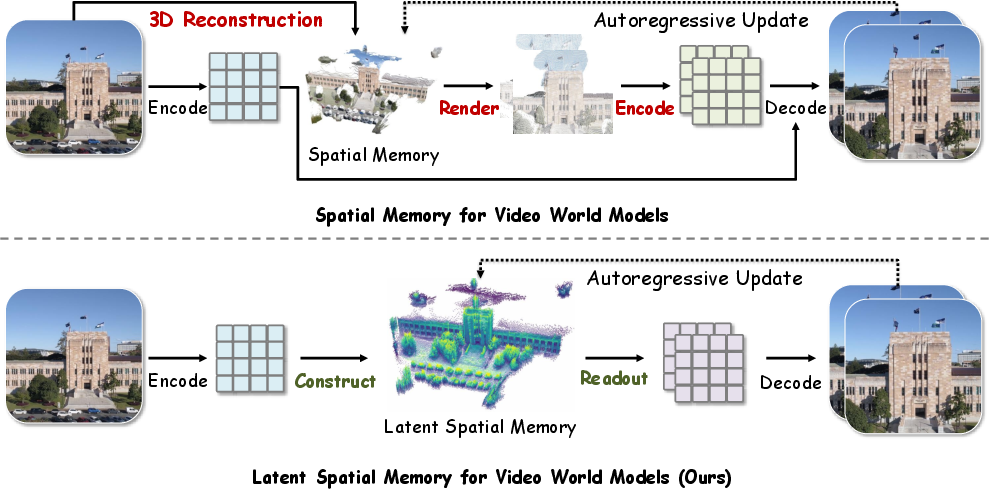
Figure 1: Comparison between RGB point cloud memory (top) and latent spatial memory (bottom), demonstrating reduction in per-step rasterization and cache footprint by operating directly in VAE latent space.
Mirage: A Latent Spatial Memory-Based World Model
The paper introduces Mirage, a video world model leveraging latent spatial memory to persistently capture scene structure in the latent manifold of the VAE diffusion backbone. Instead of storing RGB colors, Mirage records VAE latent tokens at each world-space point via depth-guided back-projection. This approach eliminates pixel-space reconstruction at every conditioning step, allowing efficient memory queries through latent-resolution projection and yielding substantial gains in computational efficiency and memory usage. Each frame’s latent features are backprojected using estimated depth into a persistent 3D cache, and conditioning for generation is performed by directly reading out cache tokens in latent space.
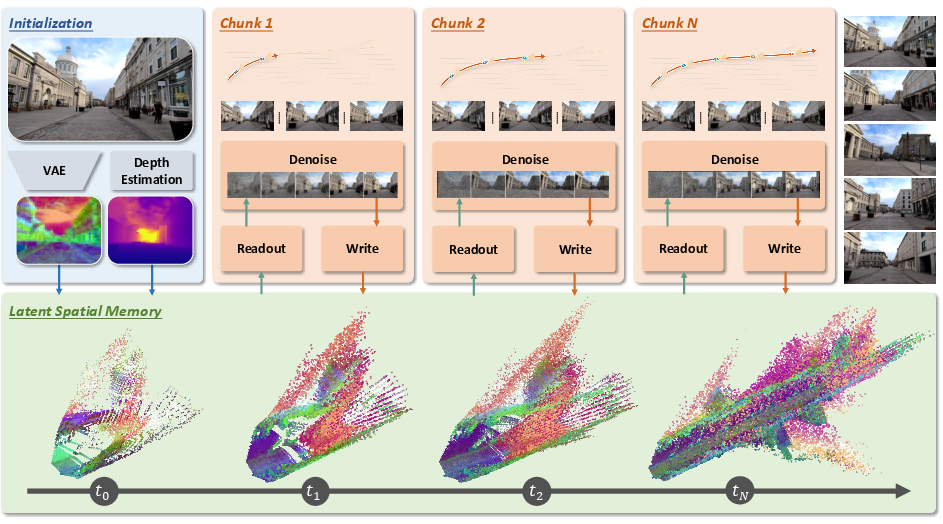
Figure 2: Mirage pipeline, illustrating initial latent cache creation, per-chunk cache readout, and cache update mechanisms using depth-guided back-projection and latent-space operations.
During generation, Mirage follows an initialize-readout-update cycle: the initial cache is seeded from the input frame; for each subsequent chunk, the cache is projected onto target camera grids to provide geometric conditioning for the diffusion backbone; generated frames are decoded, re-encoded into latents, and back-projected to update the cache. Dynamic object filters (entity extraction and segmentation) ensure that only static geometry persists, preventing contamination from unreliable or transient entities.
Empirical Evaluation
Generation Quality and Consistency
Mirage is evaluated on WorldScore and RealEstate10K, using diverse metrics for controllability, 3D consistency, and perceptual quality. Mirage attains state-of-the-art Average Score on WorldScore, outperforming both RGB-cache and memory-free foundation models, especially in 3D and photometric consistency metrics. In challenging out-of-domain scenarios, Mirage maintains temporal and geometric coherence, whereas baselines suffer from stretched textures and geometric drift.

Figure 3: Qualitative comparison on out-of-domain prompts, evidencing Mirage's geometric stability and texture consistency under aggressive camera motion.
On RealEstate10K, Mirage surpasses existing baselines in novel view synthesis—especially SSIM and LPIPS—and achieves the highest closed-loop consistency when trajectories revisit initial viewpoints, indicative of robust long-horizon spatial anchoring.

Figure 4: Comparison on RealEstate10K, showing sharper structure and stable appearance for Mirage across temporal rollouts compared to leading baselines.

Figure 5: Closed-loop consistency test on RealEstate10K, with Mirage exhibiting strong fidelity between revisit frames and initial input.
Efficiency
Mirage’s latent-space design yields dramatic improvements in per-frame readout time and cache footprint. Benchmarking on autoregressive rollouts demonstrates an order-of-magnitude reduction: end-to-end generation is 10.57× faster and uses 55× less GPU memory than RGB-cache pipelines, scaling gracefully with rollout length.
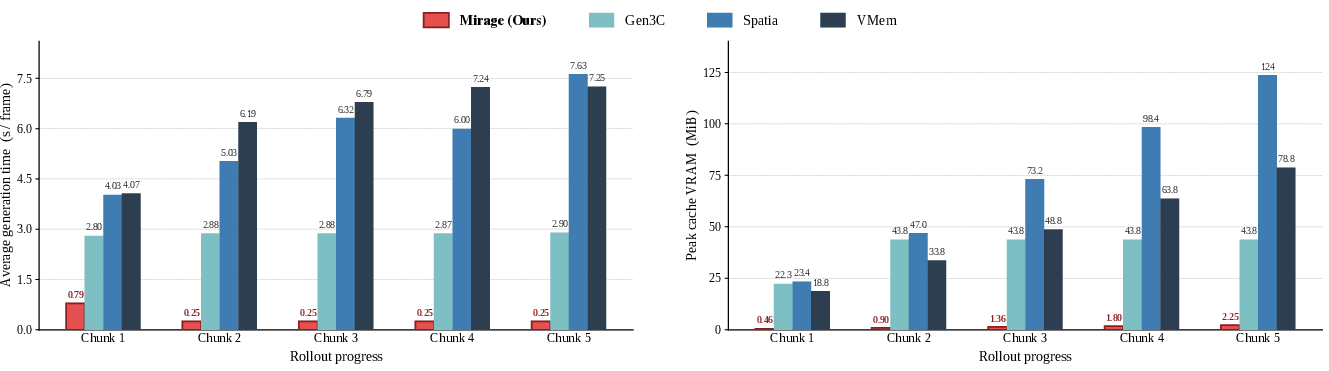
Figure 6: Efficiency scaling with rollout progress, highlighting Mirage’s constant per-frame readout time and minimal cache growth relative to RGB-point cloud and view-memory baselines.
Ablation Studies
Component-wise ablations confirm that latent spatial memory is the critical factor driving both quality and efficiency. Replacing the latent cache with RGB point clouds degrades 3D and photometric consistency. Upsampling features to pixel resolution for lifting introduces distributional discrepancies detrimental to native backbone operation. Dynamic object filtering significantly improves long-horizon stability. Robustness to depth estimation variation is shown, with only modest degradation observed under less reliable predictors, due to geometric conditioning being soft rather than hard.

Figure 7: Comparison on a difficult indoor trajectory, highlighting Mirage's stability and coherence while RGB-cache and view-memory baselines succumb to deformation and blur.
Practical and Theoretical Implications
The latent spatial memory paradigm fundamentally alters the cost structure and conditioning fidelity of world-consistent video generation. By anchoring geometric memory directly in the latent space, Mirage achieves scalable performance unaffected by per-step rasterization bottlenecks. This unlocks practical real-time generation for exploration, robotics, and embodied simulation applications on commodity hardware. The latent token cache carries richer semantic and textural information than RGB caches, suggesting new directions for world model conditioning, semantic memory, and reinforcement learning-driven video generation.
However, exclusion of dynamic regions from the persistent cache implies that Mirage’s spatial memory is optimized for static scene geometry; future extensions may persist dynamic actors by developing reliable representations compatible with chunk-level updates and cross-chunk geometry.
Conclusion
Mirage operationalizes latent spatial memory for video world modeling, yielding superior 3D consistency and efficiency without pixel-space detours. This approach establishes new baselines for quality and runtime scaling in challenging multi-view video generation. The methodology provides a generalizable blueprint for latent-space spatial memory in on-device applications, continuous procedural simulation, and long-horizon video synthesis, with potential for further advances in dynamic scene memory and embodied world modeling.