Memory Forcing: Spatio-Temporal Memory for Consistent Scene Generation on Minecraft
Abstract: Autoregressive video diffusion models have proved effective for world modeling and interactive scene generation, with Minecraft gameplay as a representative application. To faithfully simulate play, a model must generate natural content while exploring new scenes and preserve spatial consistency when revisiting explored areas. Under limited computation budgets, it must compress and exploit historical cues within a finite context window, which exposes a trade-off: Temporal-only memory lacks long-term spatial consistency, whereas adding spatial memory strengthens consistency but may degrade new scene generation quality when the model over-relies on insufficient spatial context. We present Memory Forcing, a learning framework that pairs training protocols with a geometry-indexed spatial memory. Hybrid Training exposes distinct gameplay regimes, guiding the model to rely on temporal memory during exploration and incorporate spatial memory for revisits. Chained Forward Training extends autoregressive training with model rollouts, where chained predictions create larger pose variations and encourage reliance on spatial memory for maintaining consistency. Point-to-Frame Retrieval efficiently retrieves history by mapping currently visible points to their source frames, while Incremental 3D Reconstruction maintains and updates an explicit 3D cache. Extensive experiments demonstrate that Memory Forcing achieves superior long-term spatial consistency and generative quality across diverse environments, while maintaining computational efficiency for extended sequences.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
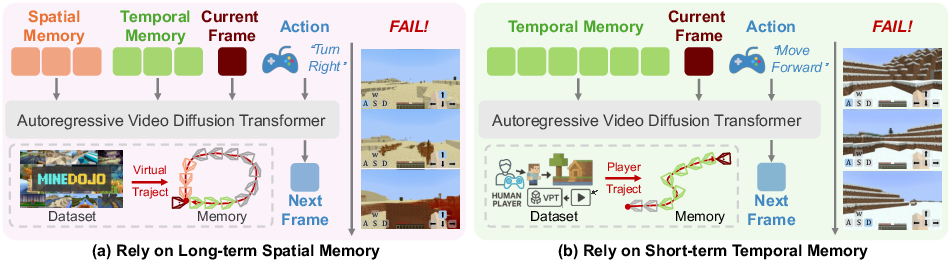
This paper is about teaching an AI to “play” and generate videos of Minecraft in a way that looks real and stays consistent over time. The big challenge is memory: the AI needs to remember what it has seen before so that when it comes back to the same place, things look the same. But it also needs to handle brand-new areas it has never seen before. The authors propose a method called “Memory Forcing” that helps the AI balance two kinds of memory:
- Temporal memory: short-term memory of recent frames (like remembering what you just saw).
- Spatial memory: long-term memory tied to the 3D world (like a map of the environment).
Key Questions the Paper Asks
- How can we make AI-generated Minecraft videos stay consistent when revisiting a place, without hurting the quality in brand-new scenes?
- With only a limited “memory window” (a fixed amount of past frames), how can the AI choose what to remember and use?
- Can we build a smarter, geometry-based memory system that is fast, uses little storage, and stays accurate even as the video gets very long?
How They Did It (Methods)
To make this easier to understand, imagine the AI is a player with a backpack. The backpack can only carry a limited number of “memories.” The authors teach the AI what to pack and when to use those memories.
Temporal vs. Spatial Memory
- Temporal memory is like remembering the last few moments of your walk.
- Spatial memory is like having a lightweight 3D map of the world saved in your backpack, so you can check what a place looked like before.
Hybrid Training
- The AI is trained on two kinds of gameplay:
- Human play (VPT): lots of exploring new areas. Here, the AI mainly uses temporal memory.
- Simulated play (MineDojo): lots of revisiting areas from nearby angles. Here, the AI is encouraged to use spatial memory.
- By practicing both, the AI learns when to rely on short-term memory (for exploration) and when to pull out the 3D map (for revisits).
Chained Forward Training (CFT)
- Normally, AI models train using perfect past frames (ground truth). But in real use, they have to rely on their own previous predictions, which might be a bit off.
- CFT makes the model practice using its own predicted frames as context—like learning to walk while carrying your own drawings of the past instead of perfect photos.
- This causes small viewpoint errors to accumulate, which nudges the AI to use spatial memory more to keep scenes consistent.
- Result: the AI gets better at handling long sequences and avoiding “drift” when it revisits places.
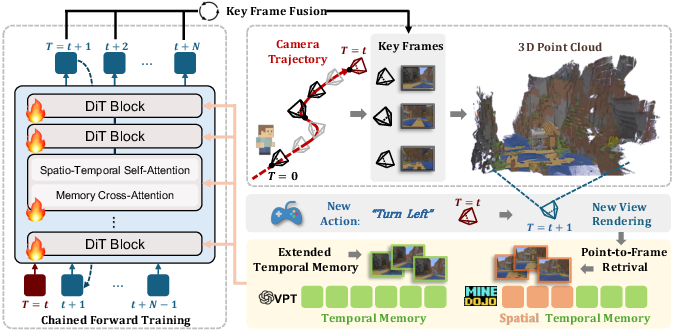
Geometry-Indexed Spatial Memory
- Instead of saving tons of whole frames and searching by appearance (which can be slow and confused by lighting or angle changes), the AI builds a simple 3D “point cloud” map of the world as it goes.
- Each 3D point remembers which frame it came from. Think of it like pinning the place on a map and noting the photo that captured it.
Point-to-Frame Retrieval
- When the AI looks at the current scene, it projects the 3D map into the view and counts which past frames contributed the visible points.
- It then picks the top few most relevant frames, no matter how long the video has been. This stays fast because it depends on what the camera currently sees, not on how many frames exist.
Incremental 3D Reconstruction
- The model decides which frames are “keyframes” to add to the 3D map—only when they show new areas or when history is too thin.
- It aligns scales across windows and updates a global point cloud efficiently, using voxel downsampling (like keeping the map neat and not too crowded).
- This keeps storage small and lookup fast, even for very long videos.
Main Findings
- The method improves both long-term consistency and visual quality.
- It beats other strong baselines in three areas:
- Long-term memory: better at keeping scenes consistent when revisiting places.
- Generalization: better on unseen terrains (new biomes).
- Generation quality: smoother, clearer video with sensible movement and distances.
To make the results concrete:
- Retrieval is about 7.3× faster overall.
- Memory storage for retrieval is cut by about 98.2%.
- Video quality metrics (like FVD, PSNR, SSIM, LPIPS) all improve compared to prior methods.
Why this matters:
- The AI doesn’t forget what the world looks like when it returns.
- It still explores new places well without getting “confused.”
- It stays efficient, so it can handle long sequences without slowing down or needing huge memory.
Implications and Potential Impact
- Better game world models: This can make AI agents that “play” look more realistic and consistent over time, which is great for interactive demos, game design, and testing.
- Smarter memory use: The idea of combining short-term and geometry-based long-term memory could be used in other 3D video tasks, like robotics, AR/VR, or self-driving simulations.
- Efficient scaling: Because memory use grows with how much of the world you’ve actually covered (not with how long the video is), this approach is practical for very long sessions.
Limitations and Future Directions
- Tested mainly on Minecraft; other games or real-world videos may need extra tweaks.
- Current resolution is moderate; higher-resolution versions could improve detail.
- Future work aims to adapt this method to more environments and boost performance with better acceleration and training strategies.
In short: Memory Forcing teaches an AI when to use short-term memory vs. a compact 3D world map, making Minecraft video generation both consistent and high-quality, while staying fast and efficient even for long play sessions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of missing pieces, uncertainties, and open directions that future researchers could address.
- External validity beyond Minecraft: The approach is only validated in Minecraft; it is unclear how well Geometry-indexed Spatial Memory and Hybrid/CFT training transfer to other games or real-world video where intrinsics, textures, and dynamics differ substantially.
- Dependence on accurate poses: Point-to-Frame Retrieval and cross-attention (with Plücker encodings) assume accurate current poses. The paper does not specify how poses are obtained at inference (e.g., from actions vs. an estimator), nor robustness to pose noise/drift or unknown intrinsics.
- Handling dynamic worlds: The 3D cache assumes quasi-static geometry. There is no mechanism to detect/forget points invalidated by world edits (e.g., mining/placing blocks) or moving entities, leading to stale memory and potential ghosting.
- Separation of static vs. dynamic content: Retrieved historical frames may include dynamic objects (mobs, particles). The method lacks a strategy to filter dynamics (e.g., via motion/semantic segmentation) to avoid imprinting transient content into long-term memory.
- Memory invalidation and conflict resolution: No policy is provided to resolve conflicts when current observations contradict stored geometry (e.g., blocks removed). Criteria for invalidating or updating affected points are unspecified.
- Inference-time memory allocation policy: Hybrid Training uses dataset-specific regimes, but at test time the paper does not define a principled, learned controller to decide when to prioritize spatial memory vs. extended temporal context (i.e., “revisit” vs. “explore” detection and gating).
- Scalability of 3D memory with world size: Although retrieval is constant-time w.r.t. sequence length, complexity and memory scale with spatial coverage. There is no analysis for very large maps (e.g., millions of points): point-cloud size, voxel parameters, GPU/CPU memory, retrieval latency, and failure modes.
- Sensitivity to key hyperparameters: No systematic study of top-k retrieval size (e.g., k=8), voxel size, keyframe selection thresholds (e.g., τ_hist=L/2), “NovelCoverage” criterion, or CFT rollout depth/denoising steps and their impact on quality/latency.
- Robustness to discontinuities: CFT induces modest pose variation but does not evaluate performance under large discontinuities (teleports, respawns, fast travel) or sudden FOV/intrinsics changes.
- Reconstruction error propagation: The impact of VGGT depth/scale errors and cross-window scale alignment (CSA) inaccuracies on retrieval correctness and generation fidelity is not quantified; no robustness analysis or failure characterization is given.
- Illumination/time-of-day/weather changes: While geometry-anchored retrieval is viewpoint-robust, it is unclear how well it handles photometric changes (day/night, shadows, emissive blocks). No photometric normalization or time-aware memory strategy is evaluated.
- Updating memory from generated frames: In long rollouts, the 3D cache is updated from model-generated frames, risking amplification of hallucinations. No safeguards (e.g., confidence gating, consistency checks, cross-view validation) are described or evaluated.
- Occlusion-aware retrieval: The point-to-frame voting ignores occlusion consistency tests against current geometry; frames containing now-occluded evidence may be retrieved. No explicit occlusion validation or z-buffer checks are reported.
- Forgetting/eviction policy: Voxel downsampling controls density but there is no age-, uncertainty-, or conflict-based eviction. Long sessions may accumulate stale or low-quality geometry without prioritization.
- End-to-end learnability of memory: The reconstruction/retrieval pipeline is non-differentiable and hand-engineered, preventing joint optimization of memory building, selection, and usage. The benefits of differentiable 3D memory or learned retrieval policies remain unexplored.
- Runtime performance breakdown: While retrieval speed is reported, end-to-end interactive latency (input-to-photon) and its breakdown across DiT denoising, reconstruction, and retrieval are not provided, especially on commodity GPUs or real-time constraints.
- Metrics for spatial consistency: Evaluation relies on FVD/PSNR/SSIM/LPIPS but lacks loop-closure metrics, re-localization error, map consistency over revisits, or human preference ratings specific to spatial fidelity.
- Baseline coverage: Comparisons omit recent surfel- or 3D-indexed memory systems (e.g., VMem) and strong state-space long-memory models; unified training budgets and protocols for these baselines are missing.
- Resolution and detail fidelity: The model is limited to 384×224 and a 2D VAE with 16× compression. The effect of higher resolutions on memory efficiency, retrieval speed, and fine-grained texture consistency is untested.
- Action-conditioning scope and UI: Training excludes GUI frames and focuses on 25-D low-level actions. How the method handles inventory/crafting interfaces, text overlays, or richer action vocabularies is not addressed.
- Robustness to noisy/adversarial actions: The system’s tolerance to mis-specified or adversarial inputs and its ability to self-correct over long horizons are untested.
- Memory–appearance complementarity: Geometry-only retrieval may lose fine appearance details (biome color tones, textures). The value of hybrid geometry+appearance memory or feature fusion is not studied.
- Multi-camera/multi-agent settings: The approach targets single egocentric camera. Extensions to third-person/spectator views, agent handoffs, or multi-agent shared memory are not explored.
- CSA stability over long runs: Cross-window scale alignment is described but not stress-tested for cumulative scale drift over very long sequences or under low-overlap windows; no quantitative analysis of long-horizon stability.
- Revisit detection criterion: The operational definition and runtime detector for “revisiting previously observed areas” (used to switch memory regimes) are not formally specified or evaluated for precision/recall.
- Failure case taxonomy: The paper provides qualitative wins but lacks a systematic taxonomy of failure modes (e.g., geometry drift, texture aliasing, dynamic object artifacts) with frequency and conditions of occurrence.
- Safety of CFT vs. exposure bias: CFT resembles scheduled sampling/DAgger but there is no theoretical or empirical study of convergence/stability, optimal rollout depths, or potential training instabilities.
- Intrinsics variability and FOV changes: Retrieval assumes fixed intrinsics; effects of FOV changes (sprint FOV, settings) or lens distortion are unaddressed, and no intrinsics-adaptive retrieval is proposed.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now or prototyped with modest effort, derived from the paper’s methods (Hybrid Training, Chained Forward Training), and geometry-indexed spatial memory (Point-to-Frame Retrieval and Incremental 3D Reconstruction).
- Persistent, scene-consistent content generation for open‑world games
- Sector: gaming, software
- What: Integrate Geometry‑indexed Spatial Memory and Memory Cross‑Attention into existing generative game engines (e.g., Minecraft mods, Unity/Unreal plugins) to maintain environment consistency when players revisit areas while keeping exploration flexible.
- Tools/products/workflows: “Spatial Memory SDK” exposing point‑to‑frame retrieval APIs; a Memory Forcing–based inference pipeline that swaps between spatial and temporal conditioning based on gameplay regime; server‑side plugin for Minecraft to generate dynamic yet consistent landscapes and interiors.
- Assumptions/dependencies: Validated primarily in Minecraft; requires action‑conditioned data and pose/depth estimation; GPU inference; current model resolution 384×224.
- Real‑time spectator/replay generation with geometric continuity
- Sector: gaming, media
- What: Generate consistent camera replays and spectator views that respect previously seen scene geometry (stadiums, tracks, arenas) during camera pans and revisits.
- Tools/products/workflows: “Generative Replay Assistant” that buffers keyframes via incremental 3D reconstruction and selects top‑k historical frames per view for cross‑attention.
- Assumptions/dependencies: Needs access to camera poses and reliable depth or geometry proxies; performance depends on scene rigidity and lighting stability.
- Efficient long‑sequence generative video services
- Sector: cloud/edge computing, software
- What: Deploy Memory Forcing to reduce retrieval latency and memory footprint for long sessions (e.g., streaming generative worlds, sandbox experiences), leveraging the paper’s reported 7.3× speedup and ~98.2% memory reduction versus frame‑bank approaches.
- Tools/products/workflows: “Geometry‑Indexed Memory Service” that scales with spatial coverage (voxel‑downsampled point clouds, selective keyframing) rather than time.
- Assumptions/dependencies: Benefits depend on scenes with revisits; requires robust 3D cache maintenance and scale alignment across windows.
- SLAM‑adjacent synthetic dataset generation for vision models
- Sector: robotics, computer vision research
- What: Produce coherent synthetic egocentric video with consistent geometry across revisits to augment training for depth/pose networks or to stress‑test mapping algorithms.
- Tools/products/workflows: Mining sequences with frequent revisits (MineDojo‑style), exporting point‑cloud plus frame indices to create labeled datasets for correspondence and consistency.
- Assumptions/dependencies: Synthetic‑to‑real gap; relies on availability of accurate actions/poses in synthetic environments.
- Spatially consistent AI previz and virtual cinematography
- Sector: media/film, AR/VR
- What: Previsualize shots with generative cameras that preserve set geometry when returning to previously filmed areas, improving continuity across takes.
- Tools/products/workflows: “Generative Previz Assistant” using Chained Forward Training to tolerate drift and still recover consistency via spatial memory.
- Assumptions/dependencies: Requires calibration to known set geometry or high‑quality monocular depth; best with rigid scenes.
- Creative video tools for continuity across cuts
- Sector: consumer software, creator tools
- What: AI b‑roll generation that maintains consistent environments across edits (e.g., vlogs returning to the same street or room).
- Tools/products/workflows: Plug‑in for editors that caches a coarse 3D representation and retrieves top‑k frames for continuity during autoregressive synthesis.
- Assumptions/dependencies: Needs approximate camera pose estimation from handheld videos; dynamic objects may reduce consistency.
- Research adoption: training protocol improvements for AR video models
- Sector: academia
- What: Apply Hybrid Training and Chained Forward Training to other autoregressive video diffusion baselines to reduce inference‑time drift and teach adaptive reliance on temporal vs spatial memory.
- Tools/products/workflows: “Memory Forcing Trainer” scripts; reproducible ablations on retrieval strategies (pose vs 3D).
- Assumptions/dependencies: Requires mixed datasets (exploration‑heavy and revisit‑heavy) and access to compute; careful hyperparameter tuning for window sizes.
- Education: hands‑on labs in world modeling and memory retrieval
- Sector: education
- What: Use Minecraft‑based labs to teach students the trade‑off between temporal and spatial memory, with assignments implementing point‑to‑frame retrieval and selective keyframing.
- Tools/products/workflows: Course modules and sample notebooks demonstrating windowed training and geometry‑indexed memory.
- Assumptions/dependencies: Needs GPU‑enabled lab infrastructure; familiarity with PyTorch and diffusion transformers.
Long‑Term Applications
These use cases require further research, domain adaptation, scaling, or integration with additional sensors/components before practical deployment.
- Persistent AR Cloud and spatially anchored generative overlays
- Sector: AR/VR, mobile
- What: Maintain geometry‑indexed memory across sessions so generative content remains anchored when users revisit locations (homes, stores, campuses).
- Tools/products/workflows: “AR Cloud SDK” integrating point‑to‑frame retrieval with device SLAM; session persistence keyed by geometry rather than time.
- Assumptions/dependencies: Robust real‑world depth/pose estimation on consumer devices; handling of dynamic objects/lighting; privacy and on‑device storage policies.
- Generative world simulators for autonomous driving and robotics training
- Sector: autonomous vehicles, robotics
- What: Simulate long‑horizon scenarios with consistent road/scene geometry as agents revisit segments; train policies that benefit from memory‑consistent visual cues.
- Tools/products/workflows: Hybrid Training on driving/robotics trajectories; geometry cache fused with LiDAR/IMU; evaluation on closed‑loop planners.
- Assumptions/dependencies: Domain gap from stylized worlds; multi‑sensor fusion; safety validation and scenario coverage.
- Video‑first digital twins with memory‑efficient scene updates
- Sector: industrial IoT, smart cities, facility management
- What: Generate visual twins that keep consistent geometry and efficiently update only novel coverage, scaling maintenance cost with spatial changes.
- Tools/products/workflows: “Spatial Memory Service” attached to site cameras; incremental reconstruction and top‑k frame retrieval per view for monitoring/analysis.
- Assumptions/dependencies: Requires stable camera calibration and change detection; integration with existing BIM/metadata; regulatory compliance.
- Low‑bandwidth telepresence via predictive, consistent video synthesis
- Sector: communications, remote operations
- What: Use autoregressive generation with spatial memory to predict frames between sparse transmissions, preserving environment consistency for operators.
- Tools/products/workflows: Edge‑side geometry cache; server‑side action‑conditioned synthesis; drift‑aware chained forward training for robustness.
- Assumptions/dependencies: Safety critical; must handle unexpected changes; strong synchronization protocols and fallbacks.
- Medical training simulators with consistent anatomy across revisits
- Sector: healthcare education
- What: Endoscopy/arthroscopy simulators that preserve the spatial layout when the virtual camera revisits tissues, improving trainees’ spatial understanding.
- Tools/products/workflows: Domain‑adapted reconstruction (tissue deformation models); hybrid memory protocols tuned for revisits vs exploration.
- Assumptions/dependencies: Non‑rigid geometry; need biomechanical models, high‑fidelity rendering; validation with clinicians.
- Home robotics: memory‑aware perceptual augmentation
- Sector: consumer robotics
- What: Equip robots with geometry‑indexed memory for persistent mapping, enabling generative perception to fill in occluded areas consistently when revisited.
- Tools/products/workflows: Fusion with SLAM/VIO; top‑k historical view selection for planning and object search; long‑horizon task memory.
- Assumptions/dependencies: Real‑time constraints, multi‑sensor integration; handling moving furniture and people; privacy and data retention.
- Standards and policy guidance for efficient, consistent generative systems
- Sector: policy, standards bodies
- What: Inform best practices for memory management in long‑video generative systems—favoring spatial coverage scaling over linear frame banks to reduce energy and cost.
- Tools/products/workflows: Benchmarks for consistency on revisits; metrics beyond FVD/PSNR that capture geometric stability and latency/storage budgets.
- Assumptions/dependencies: Cross‑industry adoption; transparent reporting of memory footprints and retrieval complexity; alignment with data governance.
- Cross‑domain research on geometry‑indexed retrieval for video analytics
- Sector: academia, surveillance analytics
- What: Adapt point‑to‑frame mapping to select evidence frames in long‑term video analytics (e.g., facility monitoring), improving retrieval relevance and compute efficiency.
- Tools/products/workflows: Geometry caches derived from multi‑camera setups; top‑k historical frames per query region; hybrid noise schedules for robust inference.
- Assumptions/dependencies: Multi‑camera calibration; privacy/ethics; handling environmental changes and non‑rigid motion.
- Generative CAD/scene authoring with revisit‑aware modeling
- Sector: AEC (architecture, engineering, construction), design software
- What: Author large scenes where generative fills remain consistent across revisits (corridors, rooms), improving iterative design workflows.
- Tools/products/workflows: Plugins to parametric modeling tools; selective keyframe reconstruction to track novel coverage; memory cross‑attention for consistent re‑generation.
- Assumptions/dependencies: CAD‑to‑render pipeline alignment; high‑res model scaling; versioning and change tracking.
- Multi‑agent simulation platforms with consistent shared memory
- Sector: multi‑agent systems, game AI
- What: Provide agents a shared, geometry‑indexed memory for the world so coordinated behaviors rely on the same spatial facts during revisits.
- Tools/products/workflows: Shared 3D caches; agent‑level APIs for requesting top‑k frames; hybrid training across exploration and revisit regimes.
- Assumptions/dependencies: Concurrency control; memory coherence; adaptation to non‑stationary environments.
Cross‑cutting assumptions and dependencies
- Domain generalization beyond Minecraft requires additional datasets, sensor inputs (depth, pose), and robustness to illumination and dynamics.
- Current implementation operates at 384×224 resolution; higher‑fidelity applications need model scaling and optimization.
- Real‑time deployment depends on GPU/accelerator availability; latency budgets must accommodate retrieval and cross‑attention.
- Privacy and safety considerations arise in persistent mapping of real environments; policies for storage, access, and user consent are needed.
Glossary
- action-conditioned generation: Video generation where the model conditions on both visual input and action commands to produce future frames. "For action-conditioned generation, the model predicts noise conditioned on both visual observations and actions: "
- adaLN-zero conditioning: A conditioning mechanism using Adaptive LayerNorm with zero-initialized parameters to inject control signals into a transformer. "adopting Spatio-Temporal Self-Attention for efficient modeling, adaLN-zero conditioning for action integration, and 3D positional embeddings within a Diffusion Transformer (DiT) Backbone."
- Autoregressive video diffusion models: Sequence models that generate future video frames via diffusion, conditioned on past frames. "Autoregressive video diffusion models have proved effective for world modeling and interactive scene generation, with Minecraft gameplay as a representative application."
- autoregressive (AR) rollouts: Iterative generation where model outputs feed into subsequent steps to simulate continuous interaction. "enabling autoregressive (AR) rollouts that react to player inputs in real time."
- back-projection: The process of reconstructing 3D points from 2D depth maps using camera parameters. "3D geometry is reconstructed through depth map back-projection using extrinsics derived from quaternion-composed poses:"
- Chained Forward Training (CFT): A training protocol that substitutes ground-truth context with model predictions across windows to simulate inference drift and encourage memory use. "Chained Forward Training extends autoregressive training with model rollouts, where chained predictions create larger pose variations and encourage reliance on spatial memory for maintaining consistency."
- Cross-Attention: Attention mechanism that queries one set of tokens against another set to fuse information (e.g., current frame with memory frames). "we integrate Cross-Attention modules within each DiT block to leverage long-term spatial memory during generation."
- Diffusion Forcing: A training technique that unifies next-token prediction with full-sequence diffusion by mixing clean and noisy frames. "Following Diffusion Forcing~\citep{chen2024diffusion}, we denote a video sequence as "
- Diffusion Transformer (DiT): A transformer backbone tailored for diffusion modeling of high-dimensional signals like images or video. "within a Diffusion Transformer (DiT) Backbone."
- extrinsics: Camera parameters describing rotation and translation (pose) relative to the world coordinate frame. "using predicted depth maps and pose-derived camera extrinsics."
- Fréchet Video Distance (FVD): A perceptual metric measuring distributional distance between sets of videos. "We measure perceptual quality with Fréchet Video Distance (FVD) and Learned Perceptual Image Patch Similarity (LPIPS)"
- Geometry-indexed Spatial Memory: A memory system that stores and retrieves past visual information via explicit 3D geometry and spatial indexing. "Beyond the training protocol, we equip the model with Geometry-indexed Spatial Memory."
- Hybrid Training: A strategy that mixes datasets and conditioning regimes to teach a model when to rely on temporal versus spatial memory. "Hybrid Training exposes distinct gameplay regimes, guiding the model to rely on temporal memory during exploration and incorporate spatial memory for revisits."
- Incremental 3D Reconstruction: Ongoing update of a global 3D scene representation from streamed frames, depth, and poses. "Incremental 3D Reconstruction maintains and updates an explicit 3D cache."
- LPIPS: Learned Perceptual Image Patch Similarity, a metric for perceptual image/video quality. "We measure perceptual quality with Fréchet Video Distance (FVD) and Learned Perceptual Image Patch Similarity (LPIPS)"
- masked conditioning: Conditioning scheme in diffusion where certain frames or tokens are masked to control information flow during training. "achieve superior quality through masked conditioning and per-frame noise control."
- MineDoJo: A Minecraft simulation platform and dataset suite used for training and evaluation. "Additionally, we utilize a synthetic dataset generated from MineDoJo~\citep{fan2022minedojo} for long-term memory training"
- per-frame noise control: Assigning or controlling noise levels per frame in diffusion training to modulate conditioning strength. "achieve superior quality through masked conditioning and per-frame noise control."
- Plücker coordinates: A 6D representation of 3D lines used to encode relative viewpoint geometry in attention. "augmented with Plücker coordinates to encode relative pose information between current and historical viewpoints."
- Point-to-Frame Retrieval: Geometry-based selection of relevant past frames by tracing visible 3D points back to their source frames. "Point-to-Frame Retrieval efficiently retrieves history by mapping currently visible points to their source frames"
- PSNR: Peak Signal-to-Noise Ratio, a pixel-level fidelity metric for frames. "while assessing pixel-level accuracy through Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM)."
- quaternion-composed poses: Camera orientations computed via quaternion composition to avoid gimbal lock and enable smooth rotation. "using extrinsics derived from quaternion-composed poses:"
- SLAM: Simultaneous Localization and Mapping; algorithms that estimate camera trajectory and build maps from sensor data. "SLAM-based approaches like VGGT-SLAM~\citep{maggio2025vggt} handle long sequences through incremental submap alignment."
- Spatio-Temporal Self-Attention: Attention over both spatial and temporal tokens to model video dependencies efficiently. "adopting Spatio-Temporal Self-Attention for efficient modeling"
- SSIM: Structural Similarity Index Measure, a perceptual metric capturing structural fidelity. "while assessing pixel-level accuracy through Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM)."
- state-space methods: Models that compress sequence history into latent states, enabling long-range dependencies with fixed memory. "State-space methods~\citep{po2025long} compress history into latent states and alleviate this efficiency issue, but they lack explicit spatial indexing"
- streaming 3D reconstruction: Real-time incremental 3D reconstruction from sequential frames for long sequences. "we maintain a coarse scene representation via streaming 3D reconstruction"
- surfel-indexed view selection: Retrieval using surface elements (surfels) to index and select views relevant to current geometry. "like VMem~\citep{li2025vmem} with surfel-indexed view selection."
- teacher-forced training: Training that uses ground-truth previous frames/actions as context, which can misalign with inference drift. "Moreover, teacher-forced training~\citep{huang2025self} underestimates inference-time drift"
- variational autoencoder: A generative model that encodes frames into a compressed latent space for tokenization. "We employ a 2D variational autoencoder following NFD~\citep{cheng2025playing} for frame tokenization"
- VGGT: Visual Geometry Grounded Transformer used to estimate geometry (depth/pose) for reconstruction. "We employ the VGGT~\citep{wang2025vggt} network with our cross-window scale alignment to enable streaming reconstruction."
- voxel downsampling: Reducing point cloud density by aggregating points into voxels to limit memory and retrieval cost. "Second, voxel downsampling maintains an upper bound on point density for any pose region"
- VPT: Video PreTraining dataset of human Minecraft play with action labels used for exploration-oriented training. "we adopt temporal-only conditioning on VPT~\citep{baker2022video} (human play, exploration-oriented)"
- world models: Predictive models that simulate future environment states from current observations and actions. "World models predict future states from current states and actions"
Collections
Sign up for free to add this paper to one or more collections.

