MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
Abstract: Video diffusion models are moving beyond short, plausible clips toward world simulators that must remain consistent under camera motion, revisits, and intervention. Yet spatial memory remains a key bottleneck: explicit 3D structures can improve reprojection-based consistency but struggle to depict moving objects, while implicit memory often produces inaccurate camera motion even with correct poses. We propose Mosaic Memory (MosaicMem), a hybrid spatial memory that lifts patches into 3D for reliable localization and targeted retrieval, while exploiting the model's native conditioning to preserve prompt-following generation. MosaicMem composes spatially aligned patches in the queried view via a patch-and-compose interface, preserving what should persist while allowing the model to inpaint what should evolve. With PRoPE camera conditioning and two new memory alignment methods, experiments show improved pose adherence compared to implicit memory and stronger dynamic modeling than explicit baselines. MosaicMem further enables minute-level navigation, memory-based scene editing, and autoregressive rollout.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces MosaicMem, a new way for AI video models to “remember” the world they’re showing you. The goal is to make long, controllable videos that stay consistent when the camera moves around, comes back to old places, or when objects move—like a playable, explorable world inside a video.
What questions does the paper try to answer?
- How can a video model keep a stable memory of a scene so it looks consistent when the camera moves or returns to a spot seen before?
- How can it also handle moving objects and follow text prompts (like “a knight rides a horse through a sci‑fi city”) without making everything rigid and static?
- How can we control the camera path (where it looks and moves) accurately over long videos?
- Can we make this efficient enough to generate long videos, edit scenes, and even run in real time?
How does MosaicMem work? (Explained with simple ideas)
To understand the method, think of building a big scene with tiny tiles—like a mosaic—and guiding a camera through it.
- Two old ways to “remember” a scene:
- Explicit memory: Build a 3D model (like a point cloud). Good for keeping geometry consistent, but bad at moving objects (it gets stiff).
- Implicit memory: Store what you saw in the model’s hidden features (like remembering frames). Good with motion and prompts, but it drifts over time and wastes memory.
MosaicMem combines the best of both:
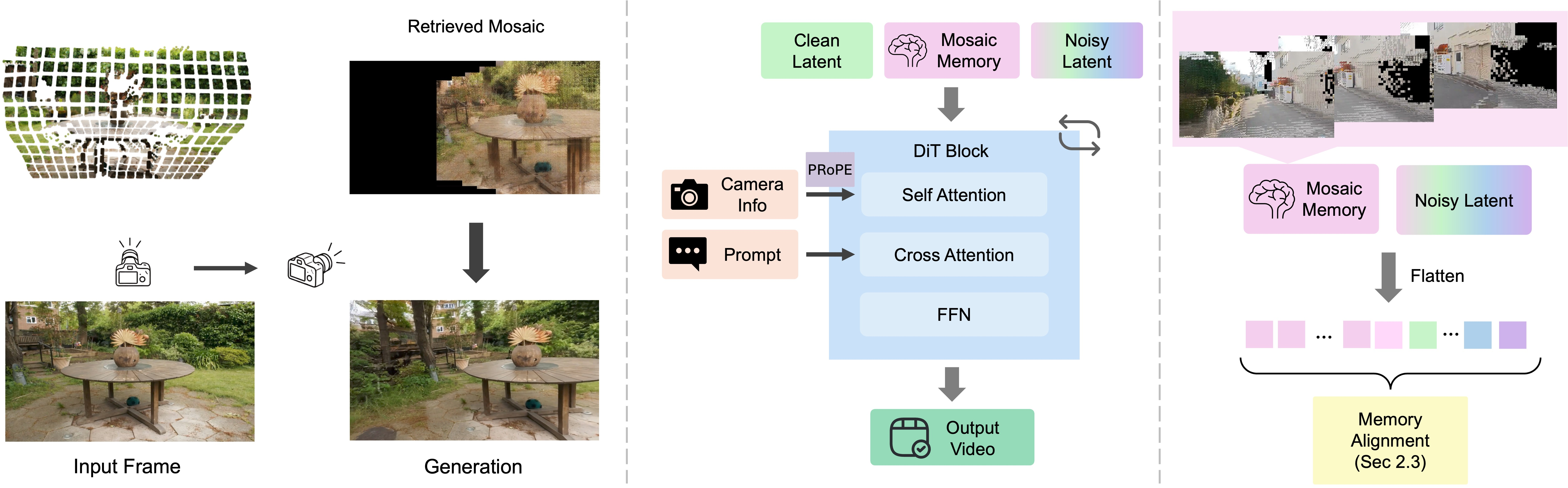
- Patch-and-compose like a mosaic:
- The model stores small image “patches” (little tiles) from frames.
- Each patch is “lifted” into 3D using estimated depth, so we know where it sits in the scene.
- When the camera moves, the model “reprojects” only the patches that matter into the new view and stitches them together—like placing just the right tiles in the right place.
- Anything missing or that should change (like a moving person) gets “inpainted” (filled in) by the model so it remains natural and follows the prompt.
- Lining things up cleanly:
- Warped RoPE: Think of it as adjusting the coordinates so patches land in the exact right spot when the view changes.
- Warped Latent: If that’s not enough, it also warps the model’s internal features directly, like gently stretching a sticker so it fits the perspective.
- Using both makes the memory line up better and stay sharp over long videos.
- Accurate camera steering with PRoPE:
- PRoPE is like giving the model a mini “camera GPS.” It encodes how the camera moves and sees the world so the model follows the intended path precisely, even when memory is sparse or the camera moves a lot.
- New test world:
- The authors built a benchmark called MosaicMem-World that includes scenes with moving objects and lots of revisits (not just straight walking), so it really tests whether the model can remember and come back to places correctly.
What did the researchers find, and why is it important?
They compared MosaicMem to both “explicit memory” and “implicit memory” systems and found:
- Better camera control:
- The camera sticks to the planned path more accurately, with much less drift over time.
- Stronger handling of moving things:
- Unlike explicit 3D caches that often freeze motion, MosaicMem produces lively, prompt-following dynamics (e.g., a knight actually riding a horse through a futuristic street).
- More consistent revisits:
- When the camera returns to a place, the scene looks the same as before (same layout and objects), instead of slowly changing or blurring.
- Long videos without falling apart:
- They generated minute‑long navigation videos that stayed stable, while baselines often accumulated errors and broke down.
- Scene editing and remixing:
- Because memory is stored in small, localized patches, you can copy, move, or delete objects, and even stitch two different scenes together (like connecting a medieval street to a modern city so you can walk between them).
- Real-time version:
- An autoregressive variant (“Mosaic Forcing”) runs around 16 frames per second at 640×360, keeping quality and consistency.
Why it matters:
- It brings us closer to “world simulators” that you can explore, revisit, and edit—useful for games, training AI agents, virtual filmmaking, robotics planning, and interactive storytelling.
How does this impact the future?
- More believable virtual worlds: Videos can feel like places you can return to, not just short, one-off clips.
- Better tools for creators: You can edit scenes by rearranging memory patches, merge worlds, or add new elements that stay consistent.
- Smarter AI agents: Agents can “imagine” multiple futures and plan better if the simulated world stays stable and responds correctly to camera moves and interactions.
- Practical long-form generation: The model retrieves only what it needs and aligns it precisely, making long videos more efficient and reliable.
In short, MosaicMem shows a practical way to build controllable, persistent, and dynamic video worlds by combining small 3D-aware patches (for accurate memory) with a modern video model’s strengths (for creativity and motion).
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances hybrid spatial memory for controllable video world models but leaves several concrete questions unresolved. Future work can target the following gaps:
Method and design limitations
- Patch granularity and selection remain heuristic: no principled approach is provided for patch sizing, overlap, adaptivity, or learned patch boundaries under a memory/latency budget.
- Memory management is unspecified: there is no retrieval/eviction policy, prioritization strategy, or memory compaction scheme for long-horizon rollouts (e.g., which patches to keep, summarize, or forget as scenes evolve).
- Dynamic-object handling in 3D lifting is underdefined: monocular depth/pose used to lift patches may be view- and time-dependent for moving, non-rigid objects; the paper does not specify how to update or re-localize such patches over time.
- Conflict resolution for overlapping/contradictory patches is not addressed: when multiple reprojected patches vote for the same target region with inconsistent depth/appearance, there is no uncertainty-aware blending, visibility gating, or confidence weighting scheme.
- Mosaic seams and compositing artifacts are not analyzed: the “patch-and-compose” interface may introduce boundary artifacts; no strategies (e.g., learned blending, anti-aliasing, boundary-aware attention) are described or evaluated.
- Warping mechanisms lack principled regularization: Warped RoPE and Warped Latent are mixed empirically; there is no formal criterion for when to prefer one over the other, nor a unified framework to prevent failure modes (e.g., repeated boundary generation under slow motion).
- Camera control vs. memory coupling is not characterized: how PRoPE and MosaicMem jointly disambiguate trajectory vs. content retrieval (and when one should dominate) is not formalized; failure modes when memory is sparse and motion is large remain unresolved.
- Visibility and occlusion reasoning are implicit: there is no explicit visibility test or differentiable z-buffering to prevent using occluded memory patches during composition.
- Uncertainty is ignored: depth/pose estimation and patch localization confidence are not modeled or propagated to attention, limiting robust retrieval under estimator noise.
- Global consistency is not enforced: local, independent patches may drift in global scale/pose over long horizons; no global alignment or loop-closure mechanism is provided to enforce scene-level coherence.
- Prompt shifts and multi-object control are not tested: how to preserve spatial consistency when text prompts change mid-trajectory or when multiple moving objects with different prompts interact is unaddressed.
Evaluation and dataset limitations
- No ground-truth geometry/pose: camera adherence and consistency are evaluated with estimates from DA V3/VIPE, introducing estimator biases and metric coupling; performance on datasets with GT depth/pose (e.g., synthetic) is not reported.
- Motion/dynamics metrics are crude: “Dynamic Score” uses average optical flow magnitude, which measures motion amount but not correctness or identity/trajectory consistency; no object-level tracking, 3D trajectory accuracy, or long-term identity preservation metrics are reported.
- Limited stress testing of hard cases: performance under rolling-shutter, lens distortion, extreme rotations, high-motion blur, severe lighting changes, reflective/transparent surfaces, and crowded multi-agent scenes is not systematically evaluated.
- Dataset curation bias: MosaicMem-World uses estimated 3D and filters out “excessive motion blur,” potentially biasing toward easy estimation regimes and overstating robustness; generalization to unfiltered, noisy real-world sequences remains unclear.
- Editing/manipulation evaluation is qualitative: scene concatenation/relocation lacks quantitative metrics (e.g., seam detectability, photometric/geometry continuity, physics plausibility, lighting consistency).
- Autoregressive stability horizons are not quantified: beyond minute-level demonstrations, there is no systematic measurement of drift, collapse rates, or error accumulation as a function of length or retrieval density.
Scalability and efficiency gaps
- Compute and memory footprint are not characterized: there is no analysis of token counts, patch storage growth, retrieval latency, or GPU memory use versus implicit/explicit baselines across video length and resolution.
- Real-time viability of online lifting/retrieval is unclear: the AR model reports 16 FPS at 640×360, but the cost of online depth/pose inference and patch warping is not reported, nor the hardware configuration or breakdown of time per module.
- Model-size dependence is untested: the approach is integrated into Wan 2.2 (5B); benefits and trade-offs for smaller or larger base models, or different VAEs/architectures, are not explored.
Robustness and generalization questions
- Sensitivity to estimator quality is unmeasured: robustness to errors in depth/camera intrinsics/extrinsics, calibration drift, or differing 3D estimators is not quantified.
- VAE compression dependence is unclear: Warped RoPE/Latent are introduced partially to mitigate 4× temporal compression; how performance varies with different spatial/temporal compression factors or VAEs is not studied.
- Cross-model portability is not established: beyond a training-free demo on Wan 2.2, generalization to other video DiTs/UNet-based models, different tokenizers, or non-diffusion generators is not evaluated.
- Domain transfer is underexplored: performance across synthetic UE5 scenes, commercial games, and real-world videos is shown qualitatively but lacks quantitative cross-domain generalization/robustness analysis.
- Multi-camera/multi-agent settings are unsupported: the framework does not address fusing memory from multiple viewpoints, agents, or sensors with different calibrations and timebases.
Open algorithmic and application directions
- Memory-selection/eviction as an optimization problem: learnable policies (e.g., RL, bandits) for selecting, compressing, and discarding patches under compute/memory budgets remain open.
- Learned confidence and visibility modeling: develop uncertainty-aware attention weights that incorporate depth confidence, reprojection error, and occlusion for robust patch selection/composition.
- Loop-closure and global alignment: integrate SLAM-like global registration to maintain long-horizon global consistency without explicit full-scene reconstruction.
- Physics-aware editing and continuity: introduce constraints or differentiable rendering cues (lighting, shadows, contact) to make scene stitching/relocation physically and photometrically consistent.
- Better camera-control integration: unify PRoPE with memory retrieval via a single geometric-attention mechanism that handles per-frame, sub-frame, and cross-frame guidance, and adapts under sparse memory.
- Revisitation detection and online scene graph extraction: automatic revisit detection, object-centric memory slots, and scene graph layers for interpretable, queryable memory are not explored.
- Closed-loop control and downstream tasks: effects on planning/RL (sample efficiency, task success), interactive camera control, and policy learning from imagined rollouts remain untested.
- Theoretical understanding of warping-attention: formalize when Warped RoPE vs. Warped Latent minimize alignment error given VAE compression and motion statistics, and derive stability conditions for autoregressive use.
Glossary
- 3D Gaussian splats: 3D point-based primitives used to represent scenes for rendering or conditioning. "a set of 3D primitives (e.g., points, voxels, or 3D Gaussian splats shown in Fig.~\ref{fig:mem_comparison})"
- 3D VAE: A variational autoencoder that encodes videos with spatial and temporal compression across 3D (space-time) dimensions. "due to the temporal compression of the 3D VAE"
- AdamW: An optimizer that decouples weight decay from gradient-based updates, commonly used for training deep models. "using the AdamW optimizer with a learning rate of "
- Autoregressive video generation: Generating future frames sequentially, conditioning on previously generated outputs. "we explore autoregressive video generation for efficient long-horizon synthesis"
- Bilinear grid sampling: A differentiable resampling operation that interpolates feature values at fractional coordinates. "applying differentiable bilinear grid sampling"
- Camera frustum: The pyramidal volume of space visible to a camera, defined by its intrinsics and pose. "injecting relative camera frustum geometry directly into self-attention"
- Camera intrinsics/extrinsics: Parameters defining a camera’s internal calibration (intrinsics) and its position/orientation in the world (extrinsics). "camera intrinsics/extrinsics "
- Causal Forcing: A distillation strategy to convert bidirectional diffusion into a causal, autoregressive generator. "using Causal Forcing \cite{zhu2026causal}, an upgraded version of Self Forcing \cite{huang2025self,chen2024diffusion}, and Rolling Forcing \cite{liu2025rolling}"
- Consistency Score: An evaluation metric for memory retrieval accuracy, combining SSIM, PSNR, and LPIPS on corresponding regions. "Consistency Score, our metric for memory retrieval accuracy"
- ControlMLP: A multi-layer perceptron baseline for camera control in video generation. "As a baseline, we adopt ControlMLP \cite{kant2025pippo} for camera control"
- ControlNet: A conditioning branch architecture that injects external signals into diffusion models. "ControlNet-style branches \cite{wu2025video}"
- DiT (Diffusion Transformer): A transformer-based diffusion architecture operating on tokenized spatio-temporal representations. "a dedicated camera control module ... tailored to modern DiT architectures"
- Dynamic Score: A motion metric computed as the average optical flow magnitude to measure object dynamics. "Dynamic Score (Average Optical Flow Magnitude) for motion intensity"
- Egomotion: The motion of the camera (observer) itself through the scene. "depict precise egomotion and enable rich prompt-driven dynamics"
- FID: Fréchet Inception Distance, measuring distributional similarity between generated and real images/videos. "FID\cite{bynagari2019gans} ... for overall generation quality"
- Flow Matching: A training objective that learns a vector field to transport noise to data along continuous time. "by learning the joint distribution of the entire video via Flow Matching"
- FOV overlap: Overlap between fields of view used for retrieving relevant memory based on shared visible regions. "WorldMem \cite{xiao2025worldmem} retrieving by FOV overlap"
- FVD: Fréchet Video Distance, evaluating distributional similarity for video sequences. "FVD\cite{unterthiner2019fvd} for overall generation quality"
- GTA-style transformed attention: An attention variant that applies geometric transforms to Q/K/V for camera-conditioned reasoning. "applies it through GTA-style transformed attention"
- Implicit memory: Storing and retrieving past scene information within the model’s latent features rather than explicit 3D structures. "Implicit memory \cite{oshima2025worldpack,yu2025contextasmem,sun2025worldplay}, by contrast, stores world state in the model’s latent representation"
- LPIPS: Learned Perceptual Image Patch Similarity, a perceptual metric for visual similarity. "LPIPS\cite{zhang2018unreasonable}"
- Mosaic Memory (MosaicMem): A hybrid patch-based spatial memory that lifts patches to 3D for localization and composes them via implicit conditioning. "We propose Mosaic Memory (MosaicMem), a hybrid spatial memory that lifts patches into 3D for reliable localization and targeted retrieval"
- Novel view synthesis (NVS): Generating images from unseen viewpoints of a scene using known camera geometry. "as in frame-to-frame NVS"
- PE-Field: A positional encoding field extending 2D encodings into structured 3D for geometry-aware DiT modeling. "The recently proposed PE-Field \cite{bai2025pef} extends 2D positional encodings into a structured 3D field"
- Perspective projection: Mapping 3D points to the 2D image plane using camera intrinsics and pose. "where denotes the perspective projection"
- Plücker embeddings: A representation of 3D lines (camera rays) enabling pixel-wise geometric conditioning. "encodes camera rays via pixel-wise Plücker embeddings"
- Point cloud: A set of 3D points representing scene geometry for explicit memory or rendering. "GEN3C \cite{ren2025gen3c} maintains a point-cloud cache"
- PRoPE (Projective Positional Encoding): A camera-conditioning method that injects relative projective geometry into attention. "Projective Positional Encoding (PRoPE) \cite{li2025prope} as a principled camera-conditioning interface"
- Probability-flow ODE: The deterministic ODE that transports samples in diffusion/flow matching from noise to data. "The generative process follows a probability-flow ODE"
- Projective transform: A transformation relating two camera views via their 4x4 projection matrices. "via the projective transform "
- PSNR: Peak Signal-to-Noise Ratio, a distortion metric used for reconstruction fidelity. "PSNR"
- RoPE (Rotary Positional Embedding): A positional encoding technique that rotates Q/K features to encode relative positions. "a modified RoPE mechanism (\S\ref{sec:alignment})"
- Rolling Forcing: A strategy for stabilizing long-horizon autoregressive generation by rolling context updates. "and Rolling Forcing \cite{liu2025rolling}"
- RotErr: Rotation error, a camera control metric measuring angular deviation of predicted poses. "RotErr/TransErr for camera motion accuracy"
- Self Forcing: A technique to adapt diffusion models for causal generation by self-distillation. "an upgraded version of Self Forcing \cite{huang2025self,chen2024diffusion}"
- SLAM (visual SLAM): Simultaneous localization and mapping from video to reconstruct scene structure and camera trajectory. "Spatia \cite{zhao2025spatia} updates memory via visual SLAM"
- Spatio-temporal tokens: Tokenized features representing both spatial and temporal dimensions within DiT/VAEs. "our spatio-temporal tokens are produced from a VAE that compresses time by a factor "
- SSIM: Structural Similarity Index, a perceptual metric for image/video similarity. "SSIM\cite{wang2004image}"
- Surfel: A surface element primitive used to represent geometry with oriented discs. "VMem \cite{li2025vmem} retrieves views using surfel-indexed visibility"
- TI2V (text+image-to-video): Conditioning setup where both text prompts and an image guide video generation. "Our method builds on text+image-to-video (TI2V) models"
- Token concatenation: Conditioning mechanism that appends memory tokens to the input sequence for retrieval in attention. "typically via token concatenation"
- TransErr: Translation error, a camera control metric measuring positional deviation of predicted poses. "RotErr/TransErr for camera motion accuracy"
- VAE: Variational Autoencoder, a latent variable model for compressing and reconstructing data. "our spatio-temporal tokens are produced from a VAE"
- VBench: A benchmarking protocol assessing video quality and temporal consistency along multiple dimensions. "we follow the VBench protocol \cite{huang2024vbench}"
- Video inpainting: Filling in or synthesizing missing/uncertain regions guided by constraints. "The downstream video generator therefore behaves largely as video inpainting"
- Voxels: Volumetric grid elements used as 3D primitives in explicit representations. "points, voxels, or 3D Gaussian splats"
- Warped Latent: An alignment method that resamples latent features to target-view coordinates for geometry-consistent conditioning. "Warped Latent offers a complementary alignment mechanism by directly transforming the retrieved memory patches in the feature space"
- Warped RoPE: A positional encoding warping that reprojects RoPE coordinates across camera motion for precise alignment. "Warped RoPE is a new positional encoding mechanism that aligns patches across time and camera motion in latent space"
- World simulators: Generative models that maintain persistent, consistent scene state enabling interactive, long-horizon prediction. "Video diffusion models are moving beyond short, plausible clips toward world simulators"
Practical Applications
Practical Applications of MosaicMem
Below are actionable, real‑world applications that stem from the paper’s methods and findings (hybrid patch‑based spatial memory, PRoPE camera conditioning, warped RoPE/latent alignment, long‑horizon navigation, memory manipulation, and the AR “Mosaic Forcing” variant). Each item notes sectors, what it enables, potential tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
These can be piloted or deployed now using the described training‑free injection, fine‑tuned models, or narrow integrations with existing TI2V pipelines.
- Bold, camera‑controlled long‑form video generation for media production
- Sectors: film/VFX, advertising, entertainment, social media
- What: Generate minute‑long, viewpoint‑consistent clips that follow designer camera paths; preserve object/layout consistency across revisits; compose dynamic scenes from text prompts.
- Tools/Workflows:
- “MosaicMem plugin” for existing TI2V models (e.g., Wan 2.2) to inject patch‑and‑compose memory and PRoPE.
- Storyboard‑to‑camera path authoring, with MosaicMem conditioning to maintain spatial continuity across shots.
- Assumptions/Dependencies: Access to accurate camera trajectories or a path editor; an off‑the‑shelf depth/camera estimator (e.g., DepthAnything V3/VIPE); GPU capacity; best results require fine‑tuning rather than zero‑shot injection.
- Scene‑consistent AR/VR prototyping and previz
- Sectors: XR, immersive media, real‑time graphics, design
- What: Rapidly synthesize explorable, coherent scene fly‑throughs (including revisits) for concept demos and level previz.
- Tools/Workflows:
- Offline pre‑generation of explorable clips following specified trajectories.
- Unity/Unreal integration to import MosaicMem‑generated sequences as backdrops or reference videos.
- Assumptions/Dependencies: Engine integration; camera path design; fidelity may limit direct in‑engine use without additional processing.
- Memory‑based scene‑level video editing
- Sectors: post‑production, marketing, social content creation, creative tools
- What: Manipulate “memory patches” (duplicate, delete, relocate), or stitch multiple scenes into a geometrically continuous composite (e.g., horizontal/vertical connections).
- Tools/Workflows:
- “Patch‑and‑compose editor” UI that exposes patch selection and spatial relocation in a timeline.
- Assumptions/Dependencies: Accurate depth/pose metadata for source content; user‑guided patch selection; best results with fine‑tuned MosaicMem.
- Data augmentation for robotics perception and autonomy
- Sectors: robotics, drones, autonomous systems
- What: Produce long, camera‑controlled synthetic sequences with consistent geometry for training camera pose estimators, revisitation handling, and object tracking under motion.
- Tools/Workflows:
- Generate domain‑targeted trajectories with PRoPE; vary prompts for dynamic scenes; use consistency metrics (SSIM/LPIPS) for filtering.
- Assumptions/Dependencies: Sim2real gap; realism of dynamics; suitable prompts; licensing of visual assets.
- Benchmarking and evaluation of spatial memory and camera control
- Sectors: academia, industry R&D
- What: Use MosaicMem‑World and the paper’s metrics (RotErr/TransErr, Consistency Score, FID/FVD) to evaluate viewpoint control and retrieval under revisits and dynamics.
- Tools/Workflows:
- Standardized eval harness around MosaicMem‑World; integrate DA‑V3/VIPE for pose/depth supervision.
- Assumptions/Dependencies: Dataset access; agreement on evaluation protocols.
- Real‑time autoregressive content at low resolution (Mosaic Forcing)
- Sectors: live streaming, VTubing, interactive media, game prototyping
- What: 16 FPS, 640×360 AR video generation with better camera adherence and temporal stability vs. baselines for live or semi‑interactive use.
- Tools/Workflows:
- Pipeline to drive AR generation with pre‑authored camera paths; live prompting for dynamics.
- Assumptions/Dependencies: Latency budget; content moderation; quality constraints at low resolution.
- Virtual tours and AEC (architecture/engineering/construction) walkthroughs
- Sectors: real estate, architecture, interior design
- What: Create consistent navigable camera paths through spaces from sparse photos or a single image + text prompts, with stable revisits to rooms or features.
- Tools/Workflows:
- Camera path presets; patch memory anchored to uploaded photos for consistent details.
- Assumptions/Dependencies: Robust depth/pose estimation from limited imagery; legal use of images.
- E‑commerce product showcases with controlled camera and persistent assets
- Sectors: retail, marketing
- What: Maintain product identity and details across multiple angles and revisits while introducing text‑driven dynamics (e.g., environment change).
- Tools/Workflows:
- Product‑centric patch memory; standardized turntable and fly‑by camera paths via PRoPE.
- Assumptions/Dependencies: Brand/aesthetic constraints; photorealism thresholds.
- Education/training videos with consistent spatial context
- Sectors: education, corporate training, museums
- What: Produce long, camera‑controlled explainer videos that revisit key locations/objects to reinforce learning.
- Tools/Workflows:
- Prompted dynamics layered over a consistent spatial core; pre‑authored revisit sequences.
- Assumptions/Dependencies: Content validation; simplification bias in generated environments.
- Game design ideation and level previsualization
- Sectors: game development
- What: Quickly iterate on level ideas by “stitching” scenes and previewing long camera paths through composite spaces.
- Tools/Workflows:
- Export video previz for designers; optional back‑projection of layout cues into DCC tools.
- Assumptions/Dependencies: Engine interoperability; translation from video concepts to playable geometry remains manual.
Long‑Term Applications
These require further research, scaling, domain adaptation, or tighter system integration.
- On‑device, patch‑level world models for robot planning and navigation
- Sectors: robotics, autonomous vehicles, drones
- What: Use hybrid memory for localization under revisits, dynamic object handling, and planning in persistent scenes.
- Tools/Workflows:
- Integrate MosaicMem‑like memory with RL or model‑predictive control; patch‑level updates during operation.
- Assumptions/Dependencies: Real‑time depth/pose on edge devices; safety validation; robust dynamics modeling from real data.
- Interactive digital twins with persistent generative memory
- Sectors: manufacturing, energy, logistics, smart cities
- What: Long‑horizon, explorable digital twins where operators can “what‑if” test camera paths and scene edits with dynamic entities.
- Tools/Workflows:
- Coupling telemetry with patch memory; scene edits via memory manipulation (relocate/duplicate objects).
- Assumptions/Dependencies: Accuracy requirements; integration with CAD/BIM/SCADA; governance over synthetic vs. measured state.
- Autonomous driving and traffic simulation augmentation
- Sectors: mobility, transportation R&D
- What: Consistent city‑scale scene reconstructions with controllable camera/ego motion and dynamic agents for rare‑event training.
- Tools/Workflows:
- Scenario libraries driven by prompts; revisit‑focused trajectories to test localization and re‑identification.
- Assumptions/Dependencies: High‑fidelity dynamics and traffic realism; regulatory acceptance for training pipelines.
- Geometry‑aware, long‑form video editing with post‑hoc camera moves
- Sectors: creative software, post‑production
- What: “Move the camera” after the fact across long sequences, maintain spatial coherence, and manipulate scene memory at object/patch granularity.
- Tools/Workflows:
- NLE plug‑ins that expose PRoPE camera controls and MosaicMem patch operations; mixed warped RoPE/latent for alignment.
- Assumptions/Dependencies: High‑res stability; efficient UIs; more robust object‑level tracking and selection.
- AR navigation assistants with scene recall across sessions
- Sectors: consumer navigation, enterprise facilities, retail
- What: Persistent memory of spaces to improve guidance and wayfinding over multiple visits.
- Tools/Workflows:
- On‑device patch memory cache; anchor revisits to past observations.
- Assumptions/Dependencies: Privacy and consent; storage/security; on‑device compute and battery.
- Safety‑critical operator training (e.g., surgery, aviation)
- Sectors: healthcare, aerospace, industrial safety
- What: Long sessions with consistent spatial memory and realistic dynamics for scenario practice and debriefing (including revisits).
- Tools/Workflows:
- Domain‑specific fine‑tuning; integration with simulators/haptics; objective evaluation via consistency metrics.
- Assumptions/Dependencies: Domain data and validation; regulatory oversight; very high fidelity and reliability.
- Multi‑agent, persistent generative environments for RL
- Sectors: AI research, gaming AI
- What: Agents interact in a shared, evolving world where memory is manipulable and persistent across long horizons.
- Tools/Workflows:
- MosaicMem‑style memory per agent plus shared/global memory; curriculum with revisit‑centric tasks.
- Assumptions/Dependencies: Synchronization and credit assignment; scaling AR generation; stability under long rollouts.
- Cross‑modal semantic and physics integration
- Sectors: foundation model research, simulation
- What: Fuse patch‑level geometry with language, semantics, and lightweight physics for more faithful world models.
- Tools/Workflows:
- Co‑training with segmentation, 3D tracking, and simple dynamics; memory patches carry semantic tags.
- Assumptions/Dependencies: New datasets with aligned semantics/physics; model capacity and training costs.
- Policy and standards for generative simulators used in training and testing
- Sectors: public policy, industry consortia
- What: Establish benchmarks and acceptance criteria for camera control adherence, spatial consistency, and long‑horizon stability when simulators are used for training or safety assessments.
- Tools/Workflows:
- Protocols built on MosaicMem‑World and metric suites (RotErr, TransErr, SSIM/PSNR/LPIPS, VBench).
- Assumptions/Dependencies: Community adoption; governance around dataset curation, bias, and representativeness.
- Personal memory and lifelogging reconstruction
- Sectors: consumer apps, quantified self
- What: Turn casual captures into consistent, explorable “worlds” with revisit capability and scene edits.
- Tools/Workflows:
- Mobile ingestion → depth/pose estimation → patch memory → camera‑controlled playback.
- Assumptions/Dependencies: Strong privacy/consent controls; storage and compute; artifact management in low‑light/handheld footage.
Key Method Dependencies and Caveats
- Off‑the‑shelf geometry: Requires reliable per‑frame depth and camera poses (e.g., DepthAnything V3, VIPE). Accuracy degrades with poor estimates.
- Model backbone: Best results achieved by fine‑tuning DIFFUSION/DiT backbones (Wan 2.2 in paper). Training‑free injection works but is weaker.
- Alignment mechanisms: Warped RoPE and Warped Latent each have trade‑offs; mixing them improves robustness (especially for AR settings).
- Camera conditioning: PRoPE materially improves viewpoint controllability; large/sparse memory settings still need explicit camera inputs.
- Compute and latency: Long‑horizon generation and fine‑tuning require significant GPU resources; AR variant trades resolution for speed (16 FPS at 640×360).
- Dynamics and realism: While improved versus explicit memory baselines, fidelity of moving objects depends on training data and prompt design; extreme motions and edge cases may still cause artifacts.
- Legal/ethical constraints: Scene memory may contain identifiable content; ensure rights management, privacy protection, and content moderation in deployments.
Collections
Sign up for free to add this paper to one or more collections.

