Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models
Abstract: Video world models have shown immense potential in simulating the physical world, yet existing memory mechanisms primarily treat environments as static canvases. When dynamic subjects hide out of sight and later re-emerge, current methods often struggle, leading to frozen, distorted, or vanishing subjects. To address this, we introduce Hybrid Memory, a novel paradigm requiring models to simultaneously act as precise archivists for static backgrounds and vigilant trackers for dynamic subjects, ensuring motion continuity during out-of-view intervals. To facilitate research in this direction, we construct HM-World, the first large-scale video dataset dedicated to hybrid memory. It features 59K high-fidelity clips with decoupled camera and subject trajectories, encompassing 17 diverse scenes, 49 distinct subjects, and meticulously designed exit-entry events to rigorously evaluate hybrid coherence. Furthermore, we propose HyDRA, a specialized memory architecture that compresses memory into tokens and utilizes a spatiotemporal relevance-driven retrieval mechanism. By selectively attending to relevant motion cues, HyDRA effectively preserves the identity and motion of hidden subjects. Extensive experiments on HM-World demonstrate that our method significantly outperforms state-of-the-art approaches in both dynamic subject consistency and overall generation quality.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper is about teaching computers to make better videos of the world—especially when things move in and out of the camera’s view. The authors call this skill Hybrid Memory. It means the model must remember two things at once:
- The background that doesn’t move (like buildings or roads), and
- The moving subjects (like people, animals, or cars), including what they look like and how they move—even when they go off-screen and come back later.
To study this, the authors built a new dataset (HM-World) and a new method (HyDRA) to help video models keep track of hidden, moving subjects so they reappear naturally and consistently.
What questions are they trying to answer?
They focus on simple but important questions:
- Can a video model remember the background correctly when the camera moves around?
- Can it keep track of moving subjects even when they leave the frame and come back later?
- How can we design memory that handles both background and moving subjects at the same time?
How did they do it? (Methods in simple terms)
To test and train these ideas, they did two main things:
- Built a custom video dataset (HM-World):
- They used Unreal Engine 5 (a game engine) to create 59,000 short, high-quality video clips.
- These clips include many “exit-and-entry” moments—where a person or animal leaves the camera view and re-enters later.
- They mixed 17 types of scenes, 49 different subjects (people and animals), 10 types of subject movement paths, and 28 kinds of camera motions.
- Think of it like a movie set where the camera and actors have separate, carefully planned moves so the actors often go off-screen and come back.
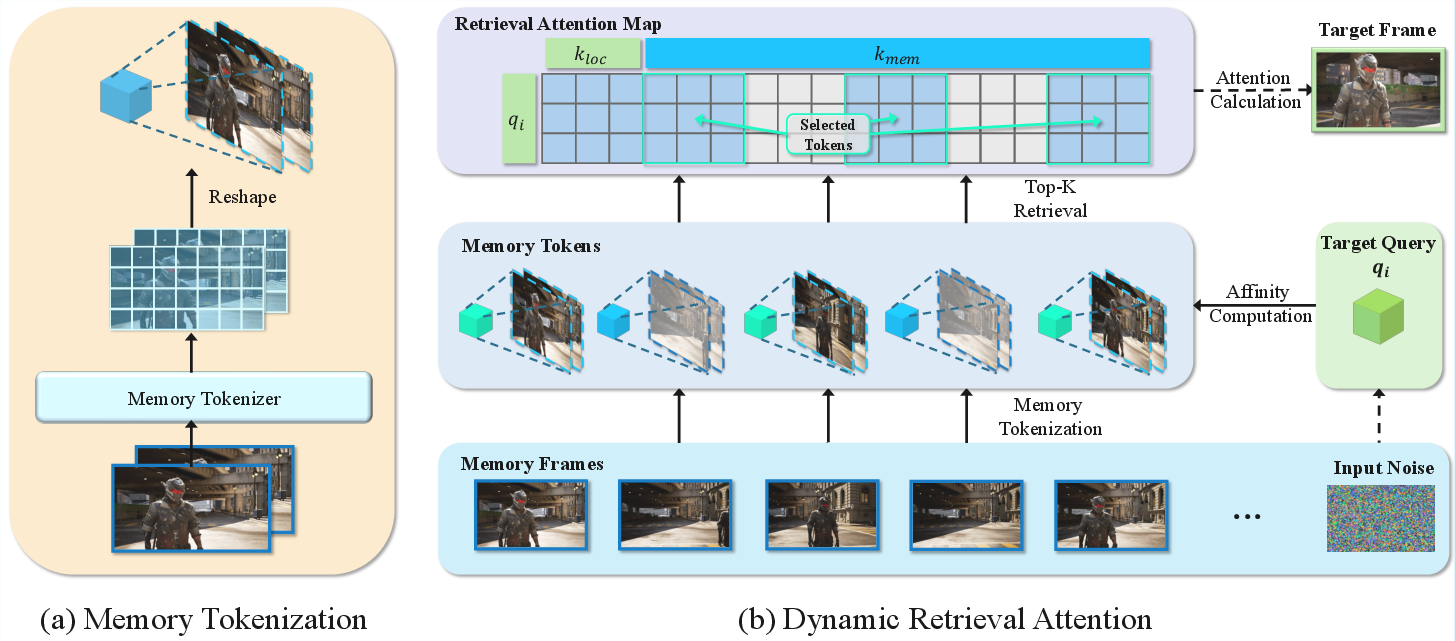
- Designed a new memory method called HyDRA:
- Imagine the model has a scrapbook of what it has seen before (that’s its memory).
- HyDRA first “packs” that scrapbook into compact, important “memory tokens” (like summary sticky notes) using 3D filters that understand both space and time.
- When generating the next frames, HyDRA doesn’t read the whole scrapbook. Instead, it smartly “retrieves” the few most relevant tokens (like flipping to the right sticky notes) based on what is happening now. This helps it remember how a specific person moved and looked before—so when that person comes back into view, they look right and move smoothly.
- Technically, this is called dynamic retrieval attention: the model compares the current moment to past “memory tokens” and pulls in the ones that match best in space and time.
In short: they built the perfect testbed (HM-World) and a focused memory system (HyDRA) that acts like a careful archivist (for backgrounds) and a skilled tracker (for moving subjects).
What did they find, and why does it matter?
Main results:
- HyDRA made the generated videos more accurate and consistent than other top methods.
- It did a better job keeping subjects’ identities and movements consistent after they re-enter the frame.
- It also kept backgrounds stable when the camera moved away and back again.
- Even compared to a strong commercial system, HyDRA performed better on their tests.
Why this matters:
- Without good memory, video models can make mistakes like freezing a person mid-step, stretching their shape, or making them vanish when they come back into the frame.
- HyDRA reduces those errors, making videos look more natural and believable.
What could this be used for?
This kind of “hybrid memory” can improve:
- Video generation for movies, games, and virtual worlds
- Training robots or self-driving cars in realistic simulations
- Any system that needs to understand and predict how people and objects move over time
Limitations and what’s next
The authors note that the method can still struggle in very crowded or complicated scenes (like three or more moving subjects or heavy occlusions). In the future, they plan to build even stronger memory systems and test them in more open, real-world situations.
Summary in one sentence
The paper introduces a smarter way for video models to remember both still backgrounds and moving subjects—even when those subjects go off-screen—using a new dataset (HM-World) and a targeted memory method (HyDRA) that retrieves the right memories at the right time to keep videos consistent and realistic.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open problems the paper leaves unresolved, aimed at guiding follow-up research:
- Generalization to real-world videos: HM-World is fully synthetic (UE5), and HyDRA is evaluated primarily on this domain; robustness to real video distributions, photometric variations, and sensor artifacts remains untested.
- Sensitivity to camera-pose noise: The method assumes perfect camera extrinsics; how retrieval and generation degrade with realistically noisy or estimated poses is not studied.
- Limited multi-subject complexity: Performance degrades with ≥3 subjects and severe occlusions; no explicit identity association or multi-object tracking mechanism is included to prevent ID switches.
- Long-horizon out-of-view tracking: The maximum out-of-view duration for which identity and motion can be recovered is not quantified; memory drift over very long gaps is unaddressed.
- Dynamic backgrounds and scene changes: The approach largely assumes static backgrounds; behavior with moving backgrounds (e.g., traffic, crowds, foliage, water) or scene topology changes is not evaluated.
- Memory update policy during inference: It is unclear whether and how memory tokens are updated with newly generated frames; strategies to prevent error accumulation or memory corruption are unexamined.
- Retrieval ambiguity with look-alike subjects: No mechanism is provided to resolve retrieval conflicts when multiple similar-looking subjects exist; identity swap failure modes are not analyzed.
- Fixed Top-K retrieval: Retrieval size is static; adaptive K, confidence-based gating, or budgeted retrieval across layers/timesteps is not explored.
- Computational profile and scalability: Claims of reduced computational burden are not supported with wall-clock, memory, or throughput benchmarks; scaling to higher resolutions and longer sequences is unreported.
- Geometry utilization beyond camera poses: Although HM-World provides 3D subject poses/trajectories, HyDRA uses only camera poses; integrating explicit 3D subject geometry or kinematics remains unexplored.
- Camera conditioning design: Camera information is injected via an MLP and addition; comparisons with geometry-aware feature warping, epipolar constraints, or 3D-aware attention are absent.
- Tokenizer architecture choices: Memory tokenization relies on 3D convolutions; alternatives (e.g., spatiotemporal transformers, deformable attention, learned slot-based memory) and their trade-offs are not studied.
- Memory compression vs. quality trade-off: No analysis of compression ratios, token counts, or spatial/temporal downsampling levels on quality vs. efficiency is provided.
- Local window hyperparameters: The impact of local temporal window size and pooling strategy on stability and fidelity is not ablated.
- Robustness to fast/abrupt motions: Behavior under rapid ego-motion, sudden subject direction changes, motion blur, or exposure flicker remains untested.
- Physics- and dynamics-aware prediction: Out-of-view motion is inferred without explicit physical constraints; integrating dynamics priors, kinematic models, or learned motion predictors is an open direction.
- Evaluation metric limitations (DSC): DSC relies on YOLOv11 detections and CLIP features—sensitivity to detection failures, identity fragmentation, and limited motion sensitivity is not quantified; comparisons with flow/pose-based metrics or human studies are missing.
- Use of ground-truth annotations in evaluation: Despite having subject positions/poses in HM-World, evaluation uses detector-derived boxes; leveraging GT tracks to reduce evaluation noise is not done.
- Baseline fairness and reproducibility: Re-implemented baselines are trained on HM-World with the authors’ settings; parity in hyperparameters, tuning effort, and code differences is not fully detailed.
- Cross-dataset validation: Beyond a small set of anecdotal open-domain results, no systematic cross-dataset tests (e.g., real videos with estimated poses) are provided.
- Handling of heavy occlusions: The method lacks explicit occlusion modeling; retrieval and generation under prolonged or layered occlusions are not analyzed.
- Text conditioning and re-identification: Although HM-World includes captions, HyDRA does not use textual cues; whether text or identity prompts can improve re-entry recovery is untested.
- Failure taxonomy and diagnostics: Failure modes (freezing, vanishing, distortion, ID switches) are not quantitatively categorized or linked to scene factors (occlusion level, subject count, motion speed).
- Dataset diversity and biases: HM-World has 17 scenes, 49 subjects, 10 subject paths, and 28 camera trajectories; coverage of complex social interactions, cluttered crowds, and rare edge cases may be limited.
- Pose/trajectory estimation errors in the wild: The pipeline assumes known camera and subject trajectories during data creation; how HyDRA performs when these must be estimated from real videos is open.
- Legal/ethical and release details: Dataset licensing, real-world deployment considerations, and code/model release status and exact reproducibility details (e.g., training schedules, seeds, full configs) are not specified.
Practical Applications
Immediate Applications
The following use cases can be deployed with modest engineering effort by leveraging the paper’s released dataset (HM-World), metric (DSC), and method (HyDRA) within existing video-generation or analysis pipelines.
- Hybrid-memory plugin for video generation platforms (sectors: software, media/advertising)
- What: Integrate HyDRA’s memory tokenizer + dynamic retrieval attention into diffusion-based video generators to prevent “frozen/distorted subjects” after occlusions or camera pans.
- Tools/products/workflows: “HyDRA Memory” module for DiT-based video models; fine-tuning on HM-World; optional camera-trajectory conditioning; preset retrieval token lengths for latency control.
- Assumptions/dependencies: Access to model internals for adding memory layers; camera trajectory data or reliable estimation; GPU capacity; domain-adaptation to real footage due to synthetic-data distribution gap.
- Occlusion-aware tracking and inpainting in post-production (sectors: film/VFX, broadcast)
- What: Use HyDRA to maintain identity and motion continuity of actors/objects that exit and re-enter the frame during complex pans/reframes; reduce manual rotoscoping or re-tracking.
- Tools/products/workflows: A plug-in for NLE/VFX suites (e.g., After Effects, Nuke, DaVinci) that re-generates frames using HyDRA memory; pre-train on HM-World then fine-tune per show.
- Assumptions/dependencies: Camera intrinsics/poses available or estimated via SLAM/structure-from-motion; consistent visuals across shots; compute budget for sequence-level diffusion.
- Auto-reframing and montage continuity assistants (sectors: creator tools, social video)
- What: Preserve subject continuity when editors crop/reframe or create “pan-and-scan” cuts; avoid identity changes when subjects briefly leave the crop.
- Tools/products/workflows: “Continuity-preserving reframer” for vertical/short video creation; batch processing plug-ins that leverage HyDRA’s token retrieval to pull relevant context.
- Assumptions/dependencies: On-device constraints (for mobile) may require server-side or quantized models; camera path proxy available from reframing transforms.
- Sports broadcast overlays with persistent player identity (sectors: sports media, analytics)
- What: Maintain player identity during broadcast pans/zooms; generate augmented graphics that remain coherent after off-screen intervals.
- Tools/products/workflows: Hybrid-memory module in telestration pipelines; DSC-based validation for continuity during replay generation.
- Assumptions/dependencies: Real-time constraints; robust camera calibration and tracking; latency budgets for live production.
- Scenario generation for robotics and autonomous driving simulation (sectors: robotics, mobility)
- What: Generate training clips where agents (pedestrians, cyclists) leave/return to view; stress-test perception stacks on occlusions and re-entry events.
- Tools/products/workflows: Use HM-World as a benchmark; fine-tune generative world models on HM-World then synthesize domain-specific datasets; evaluate with DSC for dynamic consistency.
- Assumptions/dependencies: Domain gap mitigation (sim-to-real); accurate ego-motion injection; alignment with simulator coordinate frames.
- Benchmarking and QA for generative video consistency (sectors: academia, model evaluation, policy pre-standards)
- What: Adopt HM-World as a public benchmark and the DSC metric to quantify dynamic subject consistency, complementing PSNR/SSIM/LPIPS.
- Tools/products/workflows: DSC evaluation package; internal leaderboards for model releases; regression tests for memory upgrades.
- Assumptions/dependencies: Availability/licensing of HM-World; agreement on evaluation protocols; CLIP/Yolo-based subject feature extraction as in the paper’s DSC definition.
- Synthetic data generation pipeline for exit–entry events (sectors: simulation/data engineering)
- What: Reuse the UE5-based pipeline to programmatically create targeted occlusion scenarios for training/testing any video model or tracker.
- Tools/products/workflows: Templates for camera/subject trajectories; rendering farm workflows; dataset documentation mirroring HM-World.
- Assumptions/dependencies: UE5 assets licensing; compute/render budget; skill in procedural content creation.
- Multi-camera stitching and continuity checking (sectors: film/TV, news, user-generated content)
- What: Score candidate edits with DSC to flag identity discontinuities when switching angles; optionally regenerate transitions with hybrid memory for smoother continuity.
- Tools/products/workflows: “Continuity score” plug-ins in editing suites; batch QC over rough cuts to prioritize manual review.
- Assumptions/dependencies: Reliable subject detection across cameras; tolerance for added compute during offline QC.
- Academic baselines for hybrid memory research (sectors: academia, open-source)
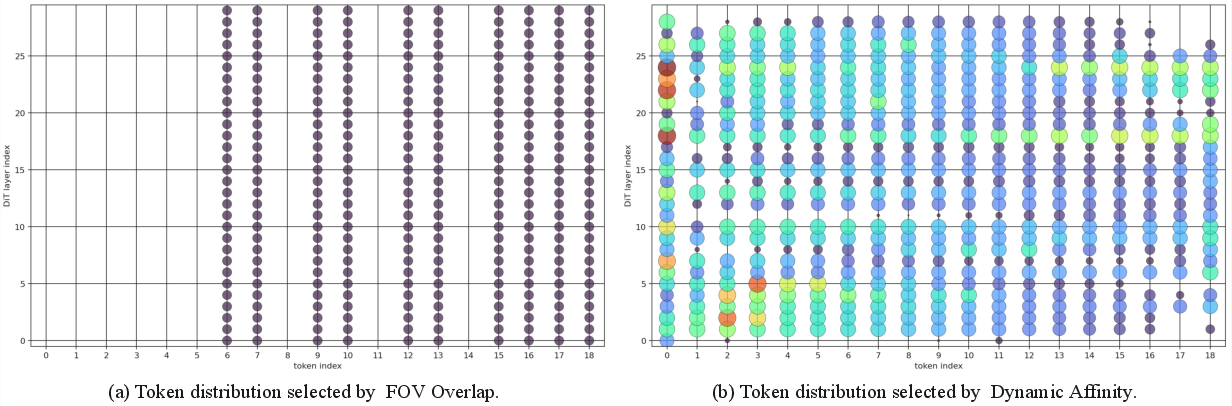
- What: Use HM-World to train/evaluate novel memories; extend HyDRA retrieval, tokenization, and camera injection designs; compare with FOV-overlap baselines.
- Tools/products/workflows: Reference training scripts; ablation-ready configs (token lengths, kernel size); DSC as the core metric.
- Assumptions/dependencies: Dataset and code availability; compute for 3D VAE + DiT training.
- Consumer video enhancement for social apps (sectors: consumer software)
- What: Cloud-based enhancement that fixes “re-entry glitches” during pans in smartphone footage (e.g., kids/pets leaving and returning to view).
- Tools/products/workflows: One-click “keep subject consistent” filters; server-side processing with camera-trajectory approximations from gyroscope/IMU logs.
- Assumptions/dependencies: Privacy-compliant data handling; latency acceptable for consumer workflows; robustness on handheld camera noise.
Long-Term Applications
These use cases require further research, scaling, or productization—e.g., real-time performance, robustness to many subjects, or integration into safety-critical systems.
- Real-time hybrid memory for embodied AI and AR (sectors: robotics, AR/VR)
- What: Onboard world models that persistently remember and predict dynamic objects’ motion when off-screen; enable AR assistants to keep coherent overlays on reappearance.
- Tools/products/workflows: Low-latency HyDRA variants with sparse token retrieval; hardware accelerators; on-device SLAM integration.
- Assumptions/dependencies: Significant optimization for inference; robust handling of 3+ subjects and severe occlusions (noted limitation); battery/compute constraints.
- Occlusion-aware planning for autonomous vehicles (sectors: autonomous driving)
- What: Generative world models that forecast where occluded agents will re-emerge; support contingency planning at intersections or behind large vehicles.
- Tools/products/workflows: Hybrid-memory modules coupled with trajectory prediction stacks; simulation-to-road transfer; DSC-like metrics for safety QA.
- Assumptions/dependencies: Regulatory approval; rigorous verification/validation; domain adaptation to sensor suites; strong safety guarantees.
- Persistent generative game worlds with off-screen NPC motion (sectors: gaming)
- What: NPCs continue plausible behaviors when off-camera and re-enter seamlessly, improving immersion in open worlds and cutscenes.
- Tools/products/workflows: Engine plug-ins that fuse HyDRA-style memory with gameplay state; tokenized memory for many agents; directors’ tools for camera paths.
- Assumptions/dependencies: Scalability to large agent populations; synchronization with physics and AI planners; real-time constraints.
- Video editing copilots that reconstruct off-screen action (sectors: creative tools, media)
- What: AI assistants that “fill in what happened off-screen,” synthesize missing footage, or rewrite transitions while preserving character identity and motion.
- Tools/products/workflows: Text-guided edits with hybrid memory conditioning; storyboard-to-video continuity preservation; human-in-the-loop approval.
- Assumptions/dependencies: High creative control and explainability; rights management; avoiding narrative drift/hallucinations.
- City-scale digital twins with plausible agent flows (sectors: smart cities, urban planning)
- What: Simulate pedestrian/traffic flows with consistent re-entry behavior across many sensors; evaluate infrastructure or evacuation plans.
- Tools/products/workflows: Multi-camera hybrid memory with spatiotemporal token banks; cross-sensor camera injection; analytics dashboards.
- Assumptions/dependencies: Massive scaling of memory/retrieval; data governance; integration with agent-based simulators.
- Surgical AR and medical video assistance (sectors: healthcare)
- What: Maintain instrument/tissue identity and motion consistency during occlusions in endoscopy or surgery; aid training and replay.
- Tools/products/workflows: Domain-trained hybrid memory models; latency-optimized inference; DSC-like clinical metrics adapted to medical semantics.
- Assumptions/dependencies: Regulatory clearance; medical-grade reliability; annotated clinical datasets; strong privacy and security.
- Forensics and surveillance gap-filling under governance (sectors: public safety, policy)
- What: Reconstruct plausible subject trajectories across camera blind spots for investigative support; score consistency and uncertainty.
- Tools/products/workflows: Hybrid-memory reconstructor with confidence overlays; DSC-based audit trails; policy frameworks to restrict misuse.
- Assumptions/dependencies: Legal/ethical constraints; risk of hallucination; requirement for human oversight and provenance tracking.
- Sports analytics with predictive reappearances and multi-view fusion (sectors: sports tech)
- What: Anticipate re-entry locations of players for camera operators; smooth identity tracking across broadcast and wearable cameras.
- Tools/products/workflows: Real-time hybrid retrieval across cameras; coach-facing analytics dashboards; training with HM-World-like scenarios.
- Assumptions/dependencies: Tough latency budgets; robust calibration; multi-subject scalability.
- Standards and certification for generative video consistency (sectors: standards bodies, policy)
- What: Use HM-World and DSC (extended to multi-subject setups) to define compliance thresholds for long-horizon consistency in model releases and tools.
- Tools/products/workflows: Public benchmark/leaderboard; “consistency scorecards” shipped with generative systems; procurement specs for public-sector tools.
- Assumptions/dependencies: Community consensus on metrics; dataset governance; periodic updates to cover new edge cases.
- Home assistants that remember moving objects (sectors: consumer robotics, IoT)
- What: Persistent memory of household items/people when cameras move; predict where objects will reappear to speed retrieval/interaction.
- Tools/products/workflows: Edge-friendly hybrid memory with selective token retrieval; sensor fusion (RGB, depth, IMU).
- Assumptions/dependencies: Privacy-by-design; robustness in cluttered scenes; efficient on-device compute.
Notes across applications:
- The core technical assumptions are (a) camera trajectory availability or reliable estimation, (b) training/fine-tuning on HM-World plus domain data to bridge the synthetic–real gap, (c) adequate compute for diffusion-based generation with retrieval, and (d) addressing known limitations (multiple subjects and heavy occlusion) for production use. Privacy, licensing, and regulatory compliance are critical for surveillance, healthcare, and automotive applications.
Glossary
- 3D convolution: A neural network operation that extends convolution over two spatial dimensions and time, enabling joint spatiotemporal feature extraction in videos. "we introduce a 3D-convolution-based memory tokenizer"
- Ablation studies: Controlled experiments that remove or alter components of a system to assess their individual contributions. "Ablation studies further verify the robustness of our design."
- Affinity metric: A quantitative measure of similarity or relevance between features, used here to match queries with memory tokens across space and time. "We then compute a spatiotemporal affinity metric"
- Autoregressive denoising: A generation process that denoises future frames conditioned on previously denoised outputs in sequence. "incorporates autoregressive denoising to achieve controllability and visual quality comparable to video games."
- Autoregressive generation: Sequential generation where each step conditions on prior outputs, often used for long video synthesis. "Yume further increases the length of generated videos through autoregressive generation."
- Causal 3D VAE: A video variational autoencoder that models temporal causality, encoding and decoding sequences with causal dependencies. "comprising a causal 3D VAE \cite{kingma2013auto} and a Diffusion Transformer (DiT) \cite{peebles2023scalable}."
- CLIP: A vision-LLM that maps images and text to a shared embedding space for similarity comparisons. "using a pretrained CLIP\cite{radford2021learning} model."
- Context forcing: A training or inference strategy that constrains the model to adhere closely to provided context to improve consistency. "context forcing technique to deliver both exceptional visual quality and consistency"
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "refers to the spatially averaged cosine similarity across the feature channels"
- Cross-attention: An attention mechanism that allows one set of features (queries) to attend to another set (keys/values), integrating external context. "Each DiT block integrates dynamic retrieval attention, a projector, cross-attention, and a feedforward network (FFN)."
- Diffusion Forcing: A consistency technique that guides diffusion models to follow given contexts or constraints. "Worldmem\cite{xiao2025worldmem} combines FOV-based retrieval for an external memory bank with Diffusion Forcing \cite{chen2024diffusion} on Minecraft data."
- Diffusion Transformer (DiT): A transformer architecture tailored for diffusion models to model complex data distributions. "comprising a causal 3D VAE \cite{kingma2013auto} and a Diffusion Transformer (DiT) \cite{peebles2023scalable}."
- Dynamic Retrieval Attention: An attention mechanism that retrieves and attends to the most relevant memory tokens based on dynamic, spatiotemporal relevance. "we propose Dynamic Retrieval Attention, a spatiotemporal-informed retrieval method and memory mechanism that directly replaces the standard 3D self-attention layers within the base model."
- Ego-motion: The motion of the camera (observer) itself, as opposed to motion of objects in the scene. "independently untangle the camera's ego-motion from the subject's independent trajectory."
- Feature entanglement: A situation where different factors (e.g., background and subject features) are mixed in representation, making them hard to separate. "3) Feature entanglement."
- Field-of-View (FOV) overlap: A retrieval heuristic that selects frames or tokens whose camera view overlaps with the current frame’s field of view. "Context-as-Memory \cite{yu2025context} adopts Field-of-View (FOV) overlap."
- Flow Matching: A training framework for generative models that learns velocity fields to transform noise into data. "The model follows Flow Matching \cite{lipman2022flow}."
- LPIPS: A learned perceptual similarity metric that measures perceptual differences between images. "PSNR, SSIM, and LPIPS analyze pixel-wise differences across frames to measure overall reconstruction fidelity."
- Memory bank: An external repository storing representations from past frames to support consistent generation. "Worldmem\cite{xiao2025worldmem} combines FOV-based retrieval for an external memory bank with Diffusion Forcing"
- Memory Tokenizer: A module that compresses memory latents into compact, informative tokens for efficient retrieval. "the memory tokenizer employs a 3D convolution with a kernel size of ."
- Multi-Layer Perceptron (MLP): A feedforward neural network with one or more hidden layers used here to encode diffusion timesteps or camera parameters. "The diffusion timestep is encoded via a Multi-Layer Perceptron (MLP) to modulate the DiT blocks."
- Out-of-view extrapolation: Predicting the motion state of subjects while they are outside the camera’s field of view. "2) Out-of-view extrapolation."
- PSNR: Peak Signal-to-Noise Ratio, a reconstruction quality metric measuring fidelity between generated and reference frames. "PSNR, SSIM, and LPIPS analyze pixel-wise differences across frames to measure overall reconstruction fidelity."
- Replayed back-propagation: A training strategy that revisits earlier segments or states during backpropagation to improve long-horizon consistency. "distills longâvideo generation with replayed back-propagation, enabling stable, longâduration generation."
- Self-attention: An attention mechanism where queries, keys, and values come from the same sequence, enabling intra-sequence context modeling. "replaces the standard 3D self-attention layers within the base model."
- Semantic pack: A compact, updatable representation that stores semantically relevant memory throughout generation. "introduces an updatable semantic pack throughout the generation process, retaining semantically relevant memory."
- Spatiotemporal decoupling: Separating spatial and temporal factors, such as disentangling camera motion from subject motion, in the model’s representation. "1) Need for spatiotemporal decoupling."
- Spatiotemporal relevance-driven retrieval mechanism: A retrieval approach that selects memory based on joint spatial and temporal relevance. "utilizes a spatiotemporal relevance-driven retrieval mechanism."
- SSIM: Structural Similarity Index, a metric assessing perceived image quality based on structural information. "PSNR, SSIM, and LPIPS analyze pixel-wise differences across frames to measure overall reconstruction fidelity."
- Surfel-indexed memory: A memory representation indexed by surface elements (surfels) for efficient 3D context retrieval. "Vmem\cite{li2025vmem} employs a 3D surfel-indexed memory structure to retrieve context"
- Top-K selection: Choosing the K highest-scoring items (e.g., memory tokens) based on a relevance score. "we employ a Top-K selection strategy to filter the memory tokens"
- Uniform spatial down-sampling: Reducing spatial resolution by a fixed factor uniformly across the frame to compress memory or context. "applies uniform spatial down-sampling to compress context memory."
- YOLOv11: A version of the YOLO object detection family used here to obtain bounding boxes for subjects. "which are obtained via YOLOv11\cite{khanam2024yolov11}"
Collections
Sign up for free to add this paper to one or more collections.