Lyra: Generative 3D Scene Reconstruction via Video Diffusion Model Self-Distillation
Abstract: The ability to generate virtual environments is crucial for applications ranging from gaming to physical AI domains such as robotics, autonomous driving, and industrial AI. Current learning-based 3D reconstruction methods rely on the availability of captured real-world multi-view data, which is not always readily available. Recent advancements in video diffusion models have shown remarkable imagination capabilities, yet their 2D nature limits the applications to simulation where a robot needs to navigate and interact with the environment. In this paper, we propose a self-distillation framework that aims to distill the implicit 3D knowledge in the video diffusion models into an explicit 3D Gaussian Splatting (3DGS) representation, eliminating the need for multi-view training data. Specifically, we augment the typical RGB decoder with a 3DGS decoder, which is supervised by the output of the RGB decoder. In this approach, the 3DGS decoder can be purely trained with synthetic data generated by video diffusion models. At inference time, our model can synthesize 3D scenes from either a text prompt or a single image for real-time rendering. Our framework further extends to dynamic 3D scene generation from a monocular input video. Experimental results show that our framework achieves state-of-the-art performance in static and dynamic 3D scene generation.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Lyra, a new way to quickly create 3D and 4D scenes (3D is space; 4D adds time) from just a single image or a short video. Instead of needing lots of real photos from many camera angles, Lyra learns by “teaching itself” using a powerful video generation model. The result is a 3D scene you can view from any angle and render in real time, like in video games, VR/AR, or robot simulators.
What questions does the paper try to answer?
- Can we build detailed and consistent 3D worlds without collecting tons of real multi-view data?
- Can we turn a single image (or one video) into a full 3D scene quickly, in a single pass, without slow per-scene optimization?
- Can we extend this to dynamic scenes (things moving over time), so it becomes 4D?
How does it work?
The big idea in simple terms
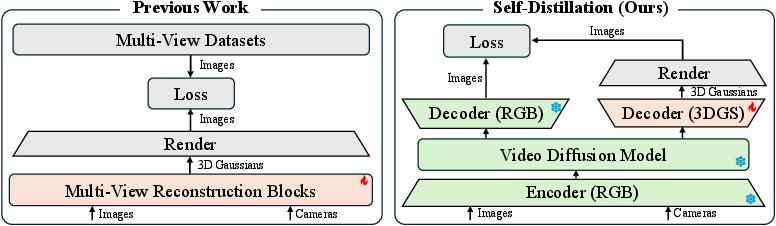
Think of a very smart “video imagination machine” (a video diffusion model). It has watched a huge number of videos and learned how scenes look and change. The authors use this machine like a teacher: it generates videos of a scene from different camera paths. Lyra is the student: it learns to produce a real 3D model by matching what the teacher shows.
Here are the key parts:
- Teacher–student training: The video model (teacher) generates frames from various camera viewpoints. The 3D model (student) tries to render images that look the same from those viewpoints. Over time, the student learns the 3D shape and appearance that best matches the teacher’s videos.
- No real multi-view data needed: Instead of filming the scene from many angles, the teacher can “imagine” views using its knowledge from the internet-scale videos it was trained on.
- Fast, feed-forward generation: Once trained, Lyra directly outputs a 3D scene from a single image or video in one go, without extra optimization steps.
What is “3D Gaussian Splatting” (3DGS)?
Imagine building a scene out of many small, soft, colored blobs (Gaussians), like a fog of dots that together form objects. This format is:
- Explicit: It’s a real 3D representation, not just 2D frames.
- Fast to render: Great for real-time viewing from different angles.
Lyra’s student decoder outputs these blobs to form the scene.
Working in “latent space” (a compressed representation)
Instead of working with full-resolution pixels (which is heavy and slow), Lyra processes a compressed version of videos called “latents” (like a zip file of visual information). This makes it much faster to handle many views and long sequences.
Multi-view coverage without real cameras
To learn a complete 3D scene, Lyra needs to see it from multiple angles. The teacher provides this by generating videos along several camera paths (like flying around the scene). The student combines information across all these paths to build one coherent 3D model.
Making scenes move (4D)
For dynamic scenes (e.g., people walking), Lyra adds time conditioning: the 3D model changes over time. During training, the authors balance the viewpoints seen at early and late times by also reversing the video sequences. This prevents the model from becoming thin or empty at certain times and helps it learn motion more evenly.
Training details simplified
- Image matching: The student renders the 3D scene and compares it to the teacher’s frames (how close do the images look?).
- Depth guidance: A depth map (how far things are) helps avoid “flat” 3D and gives proper shape.
- Pruning: Very faint blobs get removed to keep the scene lean and fast to render.
What did they find?
- Strong performance: Lyra outperforms previous methods on standard benchmarks (like RealEstate10K and Tanks and Temples) for turning a single image into a 3D scene.
- Real-time rendering: The 3D Gaussian scenes can be viewed from new angles smoothly and quickly.
- Generalization: Because it learns from the video model’s diverse “imagined” multi-view data, Lyra works well across many scene types (indoor, outdoor, realistic, and creative).
- 4D extension: Lyra also handles dynamic scenes from a single input video, enabling novel view synthesis over time.
Why this matters:
- It removes the need to collect real multi-view datasets or run slow optimization per scene.
- It produces explicit 3D, which is crucial for simulations, robots, and interactive applications.
What’s the impact?
Lyra can make high-quality 3D and 4D environments from minimal input, which is valuable for:
- Games and VR/AR: Quickly generate explorable worlds from a single picture or video.
- Robotics and autonomous systems: Train and test agents in realistic, consistent, controllable environments.
- Content creation and simulation: Scale up scene generation without expensive capture setups.
Limitations and future directions:
- The quality still depends on how good the teacher video model is. Stronger video models will directly improve Lyra’s 3D results.
- The authors suggest exploring auto-regressive techniques and better motion modeling to enhance long-term consistency and dynamic scene quality.
Overall, Lyra shows a practical path to “teach” a 3D model using a video model’s imagination, turning sparse inputs into rich, interactive 3D/4D scenes efficiently.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and unresolved questions that emerge from the paper, organized to guide follow-up research.
Dependence on the teacher video diffusion model
- Quantify how errors and 3D-inconsistencies in the teacher (GEN3C) propagate into the distilled 3DGS (e.g., via controlled corruption of teacher latents or pose noise).
- Assess bias transfer: measure whether scene/appearance biases from internet-scale video pretraining are inherited by the 3D reconstructions (domain-wise breakdowns and failure cases).
- Evaluate sensitivity to teacher depth/camera annotation quality (e.g., ablations with noisier ViPE estimates, or alternative depth/pose estimators).
Supervision design and losses
- The method lacks an explicit multi-view geometric consistency loss beyond RGB/LPIPS and depth; test whether enforcing epipolar/photometric consistency across teacher trajectories improves geometry.
- Investigate whether distilling teacher feature-space or score distillation signals (instead of only RGB/depth) yields better 3D fidelity and view consistency.
- Explore uncertainty-aware supervision (e.g., per-pixel/region teacher confidence weighting) to down-weight unreliable teacher hallucinations.
Representation and physical realism
- 3DGS limitations: no explicit materials, BRDF, or illumination modeling; study integrating view-dependent appearance and relighting to improve cross-view consistency.
- Evaluate conversion to simulation-ready assets (meshes/SDFs) and quantify losses in geometry/material fidelity during Gaussian-to-mesh/SDF conversion.
- Thin structures, transparency, and specular surfaces remain challenging for 3DGS; benchmark specialized priors or hybrid representations for these cases.
Dynamic (4D) scenes
- No quantitative 4D evaluation: establish metrics/datasets for time-varying geometry accuracy (e.g., flow consistency, cycle-consistency across time, dynamic scene benchmarks).
- Temporal coherence relies on reversed-trajectory augmentation; test principled motion regularizers (e.g., scene flow priors, temporal smoothness, correspondence constraints).
- Handle topology changes and non-rigid deformations explicitly (e.g., per-Gaussian trajectories, articulated priors, or learned deformation fields).
- Study long-horizon performance (beyond 121 frames, higher motion complexity) and drift under extended temporal sequences.
Trajectory sampling and multi-view fusion
- The six fixed trajectory patterns are heuristic; explore adaptive view planning for coverage/completeness and quantify coverage-vs-quality trade-offs.
- Analyze failure modes in multi-trajectory fusion (cross-trajectory inconsistencies, duplicated geometry) and test cross-trajectory consistency losses or correspondence alignment.
- Compare latent-space fusion to pixel-space fusion under compute-parity to isolate the benefits/limits of latent aggregation.
Scalability, efficiency, and limits
- Memory/time scaling with more trajectories, longer sequences, and higher spatial resolution remains underexplored; provide scaling laws and breakpoints.
- Study throughput/latency under resource constraints (edge GPUs), and whether model compression or token pruning preserves quality.
- Investigate the upper bound on scene extent/complexity (large outdoor spaces, multi-floor interiors) and strategies for tiling or hierarchical scene composition.
Inference requirements and robustness
- Clarify inference-time pose/intrinsics requirements for single-image and video inputs; test robustness to intrinsics mismatch and lens distortion.
- Evaluate robustness to real-world degradations (noise, motion blur, rolling shutter) and to errors in monocular video pose estimates at inference.
- Provide uncertainty estimates (e.g., per-region confidence) to flag unreliable geometry or appearance, especially in heavily hallucinated regions.
Evaluation breadth and comparability
- Lack of geometry-centric metrics: add depth error, normal consistency, surface completeness, and SfM reconstruction success to complement NVS metrics.
- Cross-paper comparability is limited by unavailable baselines and OOD settings; establish a common, open benchmark for generative image-to-3D/4D with standardized protocols.
- Report systematic failure-case analysis (scene categories, lighting, motion types) to guide targeted improvements.
Training data generation and reproducibility
- The synthetic training corpus is generated from prompts and teacher outputs; quantify how prompt diversity, prompt quality, and camera sampling influence generalization.
- Study reproducibility of the data engine: how sensitive are results to teacher version, seed, and diffusion sampling parameters?
- Investigate curriculum or active data selection (e.g., focusing on under-covered geometries/motions) to reduce training compute while improving coverage.
Joint optimization and alternative teachers
- Only the student is trained; test joint or alternating teacher–student optimization to improve teacher 3D-consistency where it matters for reconstruction.
- Evaluate portability to other camera-controlled video models and to future stronger teachers; characterize what teacher properties most predict downstream 3D quality.
Downstream applicability claims
- Validate claims for robotics/simulation: test navigation/planning/perception tasks in reconstructed scenes and quantify gaps vs. ground-truth 3D assets.
- Assess domain transfer to real robot perception (sim2real) and whether 3DGS assets suffice for physics-based interaction without conversion or augmentation.
Safety, provenance, and licensing
- The training data stem from generated videos; document provenance, licensing constraints of the teacher and prompts, and mechanisms for content filtering/copyright-safe generation.
- Explore watermarking or provenance tracking for generated 3D/4D assets to mitigate misuse and enable auditing.
Practical Applications
Immediate Applications
The following applications can be deployed now with the paper’s feed-forward 3D/4D generation (3D Gaussian Splatting) using a camera-controlled video diffusion model as teacher, real-time rendering, and released code/weights.
- Media/VFX/Gaming: Rapid 3D scene prototyping from text or a single concept image, then exporting 3DGS assets to Unreal/Unity for interactive camera moves and quick previz.
- Potential tools/workflows: Lyra-based “image-to-3D” DCC plugin; 3DGS viewers/renderers; export to mesh/texture for downstream editing.
- Assumptions/dependencies: Access to a strong teacher model (e.g., GEN3C); GPU for inference; 3DGS fidelity is sufficient for creative iteration (not measurement).
- VR/AR Production: Instant XR backdrops and environments from a single photo/video, enabling real-time rendering for immersive demos and social filters.
- Potential tools/workflows: WebXR/ARKit/ARCore integrations; live camera-controlled rendering on PC GPUs; prototyping via Blender/Unreal plugins.
- Assumptions/dependencies: Consumer-grade GPU; 3DGS shaders in target engine; non-physical geometry acceptable for experiential content.
- Robotics (Simulation/Perception): Generate diverse, multi-view-consistent synthetic scenes for training navigation and perception models without costly multi-view capture.
- Potential tools/workflows: Synthetic data engines; import into Isaac Sim/Gazebo; camera trajectory sampling for dataset diversity.
- Assumptions/dependencies: Geometry is plausible but approximate; physics proxies needed; teacher’s 3D consistency governs training value.
- Autonomous Driving (Synthetic Edge-Case Generation): Create varied indoor/outdoor scenes to augment AV simulation with rare viewpoints and lighting.
- Potential tools/workflows: Scene generator service; scenario libraries; integration with driving sim toolchains.
- Assumptions/dependencies: Not metric-accurate; requires careful domain adaptation; current scale tied to the teacher model capacity.
- Architecture/Real Estate (Virtual Staging & Walkthroughs): Convert listing photos to interactive 3D walkthroughs for marketing and concept evaluation.
- Potential tools/workflows: Cloud “photo-to-3D” API; web viewer; optional mesh extraction for BIM-adjacent workflows.
- Assumptions/dependencies: Generated geometry is not suitable for compliance or measurement; content may hallucinate occluded areas.
- E-commerce/Marketing (Product Visualization): Stage products in photorealistic 3D contexts generated from a single reference image, enabling interactive multi-view shots.
- Potential tools/workflows: WebGL viewers; pipeline to composite products into generated 3D scenes; batch prompt-to-catalog generation.
- Assumptions/dependencies: Brand safety reviews; provenance tagging of synthetic media.
- Education (Interactive 3D Content from 2D Materials): Turn textbook or lecture images/videos into navigable 3D scenes for teaching optics, geometry, and spatial reasoning.
- Potential tools/workflows: Classroom web apps; annotation overlays; replayable camera trajectories for explaining parallax/occlusion.
- Assumptions/dependencies: Didactic use tolerates non-metric geometry; requires school-friendly GPU/cloud resources.
- Academic Research (Synthetic Multi-View/4D Data Engines): Produce diverse, camera-controlled, multi-trajectory datasets for benchmarking 3D reconstruction, view synthesis, and RL.
- Potential tools/workflows: Prompt curation, automatic camera trajectory sampling, depth supervision via ViPE, opacity pruning for compact 3DGS.
- Assumptions/dependencies: Ethics and labeling of synthetic data; reliance on teacher model’s distribution and 3D consistency.
Long-Term Applications
These applications require further research, scaling, or engineering beyond the current system’s limits (teacher model fidelity, physical consistency, city-scale generation, mobile optimization).
- Embodied AI Training at Scale (Closed-Loop Simulation): Physically interactive environments with accurate geometry, dynamics, and long-horizon coherence for policy learning.
- Potential tools/products: “Lyra-Sim” with physics-aware assets; auto-regressive generative loops for large scenes.
- Assumptions/dependencies: Replace/augment 3DGS with meshes/SDFs; stronger teacher models; reliable motion/tracking integration.
- City-Scale Digital Twins from Web Videos: Generate consistent, large-area urban environments with controllable cameras for planning and traffic studies.
- Potential tools/products: Urban synthetic twin engine; streaming latents for scalable aggregation.
- Assumptions/dependencies: Global geometric consistency; geo-referencing; regulatory data use; massive compute.
- On-Device AR “Instant 3D” Capture: Mobile inference turning single photos or short videos into interactive 3D scenes for consumer apps.
- Potential tools/products: Mobile-optimized Lyra; quantized models; edge GPU utilization.
- Assumptions/dependencies: Aggressive model compression; acceptable latency and battery impact; teacher model distilled to lightweight variants.
- Healthcare (Training/Planning Simulations): Procedure rehearsal and training in lifelike synthetic environments derived from sparse clinical imagery.
- Potential tools/products: Surgical sim scenes; anatomy-aware generative modules.
- Assumptions/dependencies: High-fidelity, anatomically accurate geometry and dynamics; regulatory approval; data privacy constraints.
- Construction/Facility Management (Dynamic Digital Twin Updates): Continuous 4D site updates from handheld video for progress tracking and logistics.
- Potential tools/products: Jobsite 4D recon engine; BIM alignment tools.
- Assumptions/dependencies: Metric accuracy; robust dynamic object modeling; integration with project management platforms.
- Insurance & Forensics (Scene Reconstruction from Claims Footage): Recreate incident environments from consumer video to aid adjusters or investigators.
- Potential tools/products: Claims 3D recon portal; evidence review tools with provenance checks.
- Assumptions/dependencies: Trustworthy geometry; evidentiary standards; strong content provenance/watermarking.
- Autonomous Robotics (On-Board 4D Mapping from Monocular Video): Real-time dynamic scene recon for navigation in changing environments.
- Potential tools/products: Embedded Lyra module; sensor fusion with depth/IMU/LiDAR.
- Assumptions/dependencies: Low-latency inference; robust motion modeling; safety-critical validation.
- Policy & Standards (Synthetic Media Governance for 3D/4D): Provenance, watermarking, and disclosure frameworks for generative 3D assets used in public communication and simulation.
- Potential tools/workflows: Asset-level cryptographic provenance; dataset documentation standards; evaluation benchmarks.
- Assumptions/dependencies: Multi-stakeholder adoption; alignment with emerging regulations and platform policies.
- Digital Twin Editing & Crowd Simulation: Authoring workflows that combine generative 4D scenes with agent-based simulation for planning events and emergency response.
- Potential tools/products: Motion-aware Gaussian editors; agent simulation plug-ins.
- Assumptions/dependencies: Reliable dynamic scene modeling; interfaces to agent simulation engines.
- Geo-Spatial Education & Tourism (Photoreal “Virtual Visits”): Large-scale, coherent reconstructions for guided exploration and learning.
- Potential tools/products: Educational platforms with controllable camera narratives; time-aware reconstructions.
- Assumptions/dependencies: Scale and consistency beyond current teacher models; licensing of public-source videos.
Notes on global assumptions and dependencies across applications:
- Technical: Strong camera-conditioned video diffusion teacher (e.g., GEN3C), accurate camera pose/depth (e.g., ViPE), and sufficient compute; current geometry is plausible but not metrically guaranteed; 3DGS is fast but not intrinsically physics-ready.
- Productization: Plugins/viewers for 3DGS in major engines, optional mesh extraction for downstream pipelines, and content provenance/watermarking.
- Risk/Compliance: Synthetic content must be disclosed; domain-specific validation for safety-critical uses; dataset documentation and ethical use of generated media.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit 3D representation that models scenes as collections of Gaussian primitives for fast, differentiable rendering. "3D Gaussian Splatting (3DGS) representation"
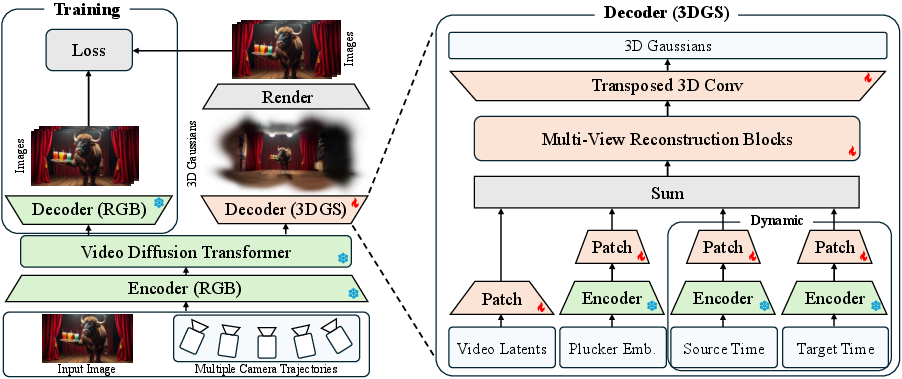
- 3DGS decoder: A neural network head that converts multi-view video latents (and camera/ray encodings) into explicit 3D Gaussian parameters. "we augment the typical RGB decoder with a 3DGS decoder"
- 4D scene generation: Producing time-varying 3D scenes (3D over time), enabling dynamic content and novel-view rendering across time. "single-video 4D scene generation."
- Auto-regressive techniques: Generative modeling methods that predict future elements conditioned on past outputs, often used for long-horizon synthesis. "the adaptation of auto-regressive techniques~\citep{chen2024diffusion}"
- Bullet-time: A design pattern for time-aware scene generation that outputs 3D content at specific timestamps across a motion sequence. "We follow the bullet-time design of \cite{liang2024btimer}"
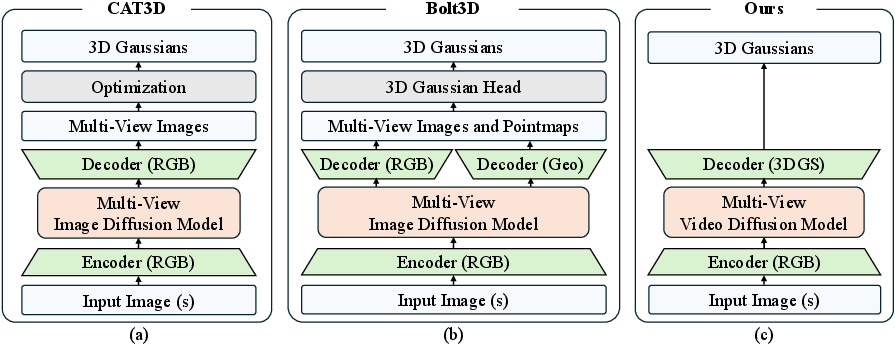
- Camera-controlled video diffusion model: A diffusion-based generator conditioned on explicit camera poses to synthesize pose-consistent video frames. "a pre-trained camera-controlled video diffusion model with its RGB decoder output (teacher) supervises the rendering of the 3DGS decoder (student)."
- Disocclusion masks: Binary masks marking regions that are not visible in renderings and must be hallucinated by the model. "The disocclusion masks indicate areas that the video diffusion model should fill in."
- Feed-forward: A single-pass inference approach that produces results without per-scene optimization or iterative refinement. "in a feed-forward fashion"
- L1 regularization: A sparsity-inducing penalty on parameters, here applied to Gaussians’ opacity to encourage pruning. "we use an L1 regularization on the opacity "
- Latent space: A compressed representation space produced by an encoder where diffusion and decoding operate efficiently. "latent space for efficient training and inference."
- LPIPS: A perceptual similarity metric that compares deep features to assess image quality differences. "an LPIPS loss "
- Mamba-2: A state-space model architecture used for efficient sequence modeling within the reconstruction blocks. "seven Mamba-2~\citep{dao2024transformers} layers."
- Mean Squared Error (MSE): A pixel-wise reconstruction loss measuring squared differences between predictions and targets. "a Mean Squared Error (MSE) loss "
- Monocular: Using a single camera stream (image or video) as input, without multi-view supervision. "monocular input video."
- Multi-view: Refers to multiple camera viewpoints of the same scene; important for 3D consistency and supervision. "multi-view training data"
- Novel-view synthesis: Rendering a scene from viewpoints not present in the input data. "enable novel-view synthesis of dynamic scenes."
- Opacity-based pruning: Removing low-opacity Gaussians to compact the scene representation and speed up rendering. "Opacity-based pruning."
- Patchification: Converting spatial feature maps into patch tokens (e.g., 2x2) for transformer-like processing. "a spatial patchification layer~\citep{ViT}"
- Plücker coordinates: A line parameterization (ray representation) used for pixel-wise camera conditioning. "represent cameras as Plücker coordinates for pixel-wise conditioning."
- Plücker embeddings: Encoded ray features (direction and moment) derived from Plücker coordinates for conditioning the decoder. "Raw Plücker embeddings are first computed"
- Point cloud: A set of 3D points (often colored) representing scene geometry. "colored point cloud"
- PSNR: Peak Signal-to-Noise Ratio; a fidelity metric measuring reconstruction accuracy in decibels. "PSNR, SSIM, and LPIPS."
- Quaternion: A 4D rotation parameterization used to represent 3D Gaussian orientations. "rotation quaternion "
- Scale-invariant depth loss: A depth supervision that is invariant to global scale, stabilizing geometry learning. "the scale-invariant depth loss "
- Self-distillation: A training paradigm where a model (teacher) supervises another (student) using its own generated signals. "self-distillation framework"
- Sinusoidal embedding: Positional/time encoding using sinusoidal functions to inject ordering information into the model. "augmented with a 2-dimensional sinusoidal embedding"
- Spatiotemporal 3D cache: A time-indexed set of point clouds derived from depth and camera views to guide consistent video generation. "spatiotemporal 3D cache "
- SSIM: Structural Similarity Index; a perceptual metric measuring structural fidelity between images. "PSNR, SSIM, and LPIPS."
- Structured guidance: Rendering-based conditioning that provides the diffusion model with structured visual cues to improve consistency. "These renderings serve as structured visual guidance"
- Teacher–student framework: Training setup where a teacher model supervises a student model to transfer knowledge. "teacherâstudent paradigm"
- Transformer: An attention-based neural architecture used here within reconstruction blocks. "Transformer-only blocks"
- Transposed 3D convolution: A learnable upsampling operator mapping hidden features to Gaussian parameter volumes. "a transposed 3D convolution maps the hidden representation to 14 Gaussian channels"
- Unprojection: Mapping image pixels and depths back into 3D space to form point clouds. "unprojecting the depth estimation"
- Variational Autoencoder (VAE): A probabilistic autoencoder used to compress videos into a latent space for diffusion. "video variational autoencoder (VAE)"
- Video diffusion model: A generative model that iteratively denoises latent variables to produce videos. "video diffusion models have shown remarkable imagination capabilities"
Collections
Sign up for free to add this paper to one or more collections.

