Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
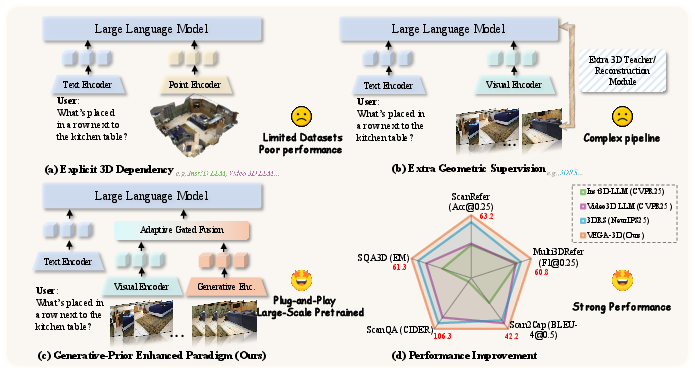
Abstract: While Multimodal LLMs demonstrate impressive semantic capabilities, they often suffer from spatial blindness, struggling with fine-grained geometric reasoning and physical dynamics. Existing solutions typically rely on explicit 3D modalities or complex geometric scaffolding, which are limited by data scarcity and generalization challenges. In this work, we propose a paradigm shift by leveraging the implicit spatial prior within large-scale video generation models. We posit that to synthesize temporally coherent videos, these models inherently learn robust 3D structural priors and physical laws. We introduce VEGA-3D (Video Extracted Generative Awareness), a plug-and-play framework that repurposes a pre-trained video diffusion model as a Latent World Simulator. By extracting spatiotemporal features from intermediate noise levels and integrating them with semantic representations via a token-level adaptive gated fusion mechanism, we enrich MLLMs with dense geometric cues without explicit 3D supervision. Extensive experiments across 3D scene understanding, spatial reasoning, and embodied manipulation benchmarks demonstrate that our method outperforms state-of-the-art baselines, validating that generative priors provide a scalable foundation for physical-world understanding. Code is publicly available at https://github.com/H-EmbodVis/VEGA-3D.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a common weakness in today’s AI vision systems: they’re good at naming what they see (like “a chair” or “a dog”), but not so good at understanding where things are in 3D space (like what’s in front, behind, left, right, near, or far). The authors propose a new way to fix this by borrowing a “sense of space” from video-making AI models. Their system, called VEGA-3D, taps into what video generators already know about 3D structure and physics to help other AI models reason about scenes more accurately—without needing special 3D data like depth maps or point clouds.
The big questions the paper asks
- Do video generation models (the kind that make realistic, consistent videos) quietly learn a good understanding of 3D space and basic physics?
- If they do, can we reuse that hidden knowledge to help other AI models better understand and reason about the real world?
- How can we combine this “3D sense” with a model’s usual “what is it?” knowledge without getting in the way?
- When (and where) inside a video generator is this 3D knowledge the most useful?
How the approach works, in plain language
Imagine a video generator as a “world simulator” in its head. To make a convincing video, it has to keep track of objects as the camera moves, make sure things don’t pop in and out, and follow simple physics. That means it likely builds a mental 3D model, even if it never sees depth or 3D labels during training.
VEGA-3D reuses that mental model in three steps:
- Find out if the video model “knows 3D”
- The authors check whether the model represents the same physical point similarly when seen from different camera angles. Think of placing the same LEGO brick on a table and walking around it—if the model’s internal features line up across views, that suggests it understands the object in 3D.
- They show this “multi-view consistency” is strongly linked to better 3D understanding.
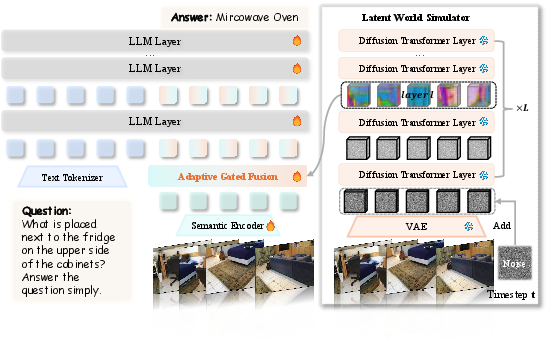
- Treat the video generator as a Latent World Simulator
- They feed a short video (or multi-view images) into a powerful video generator that’s kept frozen (not retrained).
- They add a little noise to the video’s hidden representation so the generator tries to “clean it up.” This forces the generator to use its internal understanding of structure and motion.
- While it’s “thinking,” they read out its internal features from the middle of the network and the middle of the denoising process—like listening in while it reasons, not just judging the final pixels. These features carry rich spatial and motion cues.
- Blend 3D sense with normal vision features
- Regular vision models are great at recognizing “what” things are; the video generator is great at “where” and “how things move.”
- VEGA-3D fuses both using an adaptive gate—a smart, per-spot “volume knob” that decides how much to trust the 3D signal versus the semantic signal at each location. This lets the system lean on the 3D cues for localization tasks (like “Where is the red chair?”) while keeping strong recognition for descriptions and answers.
Simple analogy:
- Semantic encoder: a librarian who knows the names of everything.
- Video generator: a stage director who knows where everyone stands and how they move.
- VEGA-3D: a coordinator that asks both, and turns each one up or down as needed.
What they found and why it matters
Here are the main takeaways the authors report, explained in easy terms:
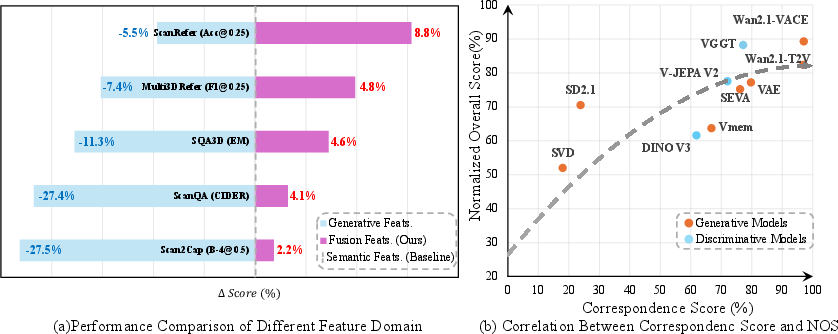
- Video generators really do learn space: Models that make stable, consistent videos hold strong, reusable 3D cues inside. The more consistent they are across views, the better they do on 3D understanding tasks.
- The “sweet spot” is in the middle: The most helpful 3D signals are found in the generator’s middle layers and at mid-steps of the “noise cleanup” process—where the model is actively reasoning about structure, not just polishing pixels.
- Better at finding and locating things: VEGA-3D improves tasks that depend on precise positions—like pointing to the exact object mentioned in a sentence, answering spatial questions, or grounding text in 3D scenes.
- Works across different challenges:
- 3D scene understanding (finding objects, describing scenes, answering questions): VEGA-3D beats strong baselines, especially on “where is it?” style tasks.
- Spatial reasoning from videos (like measuring relative distances or planning a route): It gives clear gains by grounding answers in a consistent “mental” world model.
- Robot manipulation (in simulation): Even in tightly tuned systems, VEGA-3D adds helpful stability and spatial grounding for longer, trickier tasks.
- No special 3D labels needed: Unlike many methods that require extra depth maps, 3D reconstructions, or complex geometry pipelines, VEGA-3D gets its spatial sense “for free” from the video generator’s training.
Why this could be a big deal
VEGA-3D shows that we don’t always need more 3D-labeled data to teach AI about space. Instead, we can unlock the 3D and physics knowledge already baked into large video generators and plug it into other models. That’s scalable: as video generators improve, anything using VEGA-3D can get better, too. This can help:
- Make AI assistants better at understanding scenes, not just naming objects.
- Improve spatial reasoning in education, AR/VR, and planning tasks.
- Give robots a steadier sense of where things are and how they move.
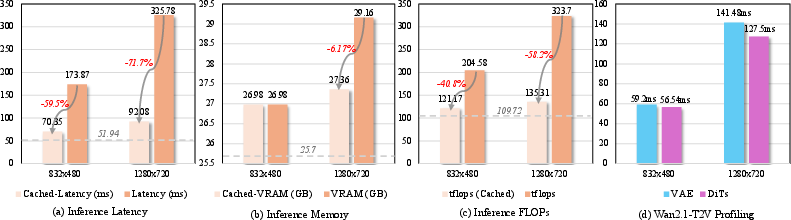
One trade-off: adding a video generator increases computing cost at inference time. The authors suggest future work to “distill” this knowledge into lighter models, keeping most of the benefits while speeding things up.
In short, the paper’s message is: Video-making AIs already “know” a lot about 3D space and simple physics. VEGA-3D shows how to tap into that hidden knowledge to help other AIs see the world more like we do.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that are missing, uncertain, or left unexplored in the paper; each item is framed to support actionable follow‑up research.
- Causality vs. correlation of “3D priors”: The paper shows a correlation between multi‑view correspondence and downstream performance but does not establish causal evidence that specific internal mechanisms of video generators produce the observed 3D benefits. How can interventions (e.g., ablating attention heads, modifying training objectives) identify which components encode geometry?
- Metric without ground‑truth poses/depth: The proposed multi‑view correspondence metric depends on ground‑truth camera poses and depth (available only for analysis). How can we design proxy or self‑supervised metrics for 3D consistency that are computable at test time without 3D annotations, and that still predict downstream gains?
- Generalization beyond indoor, rigid scenes: Most 3D evaluations are on indoor scans (e.g., ScanNet) and curated benchmarks. How does the method perform on outdoor, highly dynamic, non‑rigid, crowded, or adverse‑condition datasets (e.g., KITTI/Waymo/nuScenes, Ego4D/HoloAssist, DAVIS/JHMDB, Night/OOD weather)?
- Sim‑to‑real transfer for robotics: LIBERO experiments are in simulation with near‑saturated baselines and small gains. Does the approach improve real‑robot performance under sensor noise, latency, camera calibration drift, and control delays? What are the impacts on safety and failure recovery in closed‑loop deployment?
- Real‑time constraints and latency budgets: The added diffusion backbone increases inference cost (even with caching). What is the end‑to‑end latency in time‑critical settings (robotics, AR/VR), and how do pruning, token sparsification, partial‑frame processing, or feature streaming trade precision vs. latency?
- Sensitivity to frame count and sampling: The pipeline uniformly samples 32 frames. How does performance degrade with fewer frames or different sampling strategies (keyframe selection, event‑driven frames, variable frame rates), especially on resource‑constrained devices?
- Noise‑time and layer selection robustness: The method fixes a specific diffusion step (k=300) and layer (20th) per model. Are these selections stable across content types, generators, and tasks? Can we learn per‑scene or per‑task adaptive schedules/layer selectors (e.g., via hypernetworks or entropy‑based criteria)?
- Generator architecture dependence: The paper recommends DiT‑based models over U‑Nets; however, it does not disentangle architectural effects from data/scale differences. What minimal architectural features (global attention, token mixing depth, receptive field) are necessary for strong 3D priors?
- Domain shift of the generator: The video generator was pretrained on large internet video corpora. How robust are the extracted priors to domain shifts (medical, aerial, underwater, industrial) and sensor modalities (fisheye, thermal)? Is light fine‑tuning or LoRA adaptation of the frozen generator beneficial and safe?
- Text‑conditioning effects: Features are extracted with an empty prompt to avoid hallucination. How do different text prompts, negative prompts, or semantic guidance during feature extraction alter spatial priors? Can joint text‑visual conditioning improve instruction‑specific localization without degrading stability?
- Fusion mechanism limits: The Adaptive Gated Fusion is scalar per token and time; it does not model cross‑token dependencies or long‑range cross‑stream interactions. Would structured fusion (e.g., spatially aware gates, cross‑attention with geometric constraints, or token routing) yield better alignment?
- Interpreting and auditing the gate: The paper does not analyze the learned gate values across tasks/time/regions. Do gates systematically up‑weight generative features on localization tokens and when? Can gating be used to detect when spatial priors conflict with semantics or to flag uncertainty?
- Failure modes and edge cases: The paper lacks qualitative/quantitative analysis of failure cases—e.g., mirrors, glass, glossy/textureless surfaces, heavy occlusions, thin structures, fast motion/blur, extreme lighting. Where do generative priors hurt (e.g., Scan2Cap CIDEr drop), and how can we mitigate trade‑offs?
- Physical reasoning beyond geometry: The approach claims to capture “physical laws,” but evaluations emphasize geometric understanding. Do the extracted priors improve prediction of dynamics, contacts, stability, collisions, or counterfactual/what‑if questions (e.g., intuitive physics benchmarks)?
- Absolute vs. relative geometry: Benchmarks largely emphasize relative relationships. Can the approach recover or stabilize absolute scale/orientation under varying camera intrinsics/extrinsics? How does it affect metric tasks (depth, camera pose, 3D reconstruction) without explicit supervision?
- Complementarity with explicit 3D inputs: The paper avoids explicit 3D supervision; it remains unclear how priors combine with light‑weight depth/pose or sparse point clouds. When is it beneficial to add weak 3D cues, and what is the best fusion strategy for mixed 2D/2.5D/3D inputs?
- Distillation to lightweight encoders (future work mentioned, not realized): What teacher–student strategies, objectives (e.g., contrastive geometry, equivariance), and sampling policies can compress the priors into small, real‑time encoders without losing spatial benefits?
- Training data efficiency and scaling laws: The method claims data efficiency but does not quantify gains vs. training data size. How do improvements scale with fewer instruction‑tuning samples, varied visual corpora, or reduced generator size?
- Stability across generator versions: If the generator is upgraded (e.g., Wan2.1→2.2), do previously trained fusion/gating modules transfer or require re‑training? Can we design generator‑agnostic adapters to maintain stability across versions?
- Robustness to adversarial or synthetic artifacts: Generative backbones may encode biases or artifacts from training data. How susceptible is the fused model to adversarial textures, deepfakes, or distributional artifacts that manipulate spatial priors?
- Evaluation breadth for VSI‑Bench: Gains are reported on average with limited per‑category analysis. Which sub‑skills (e.g., route planning vs. relative direction) benefit most, and why? Are there categories where priors hinder performance?
- Beyond RGB: The approach is demonstrated on RGB video only. Do latent priors extend to multi‑modal inputs (audio, depth, events, IMU) and can those signals further anchor spatial reasoning without heavy 3D labels?
- Zero‑shot and few‑shot settings: The current results involve finetuning on established datasets. How much do generative priors help in zero‑shot or few‑shot 3D tasks where semantic encoders struggle?
- Memory and long‑horizon reasoning: The approach extracts features per scene and caches them, but it doesn’t address very long videos or cross‑scene continuity. How should we maintain, update, and forget priors over long horizons and scene changes?
- Licensing and reproducibility: Some powerful video generators or weights may be non‑redistributable. How reproducible are the results with strictly open‑weights models, and how do licensing constraints affect adoption?
- Benchmark completeness: The methodology does not evaluate on explicit 3D reconstruction or camera pose estimation benchmarks. Can the priors be directly used or fine‑tuned for classic geometric tasks (e.g., depth, SfM/MVS) to validate metric geometry competence?
- Auto‑selection of priors at inference: Currently, t and layer choices are fixed. Can we devise a runtime mechanism to select or ensemble the most informative diffusion steps/layers per query, guided by uncertainty or attention diagnostics?
- Energy and environmental cost: Using a frozen diffusion backbone increases energy consumption. Can partial forward passes, intermediate token dropping, or early‑exit criteria reduce footprint while preserving spatial gains?
- Safety and fairness: The paper does not evaluate whether the priors amplify social or geographic biases present in web‑scale video corpora, nor whether spatial reasoning differs across demographic or cultural contexts within embodied tasks.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s models and infrastructure by integrating VEGA-3D as a plug-and-play visual module into existing multimodal systems. They are especially effective for localization-centric tasks and multi-view/video inputs.
- Robotics (logistics/warehousing): Drop-in visual backbone upgrade for pick-and-place, bin packing, and tool use
- What: Replace or augment the robot’s vision stack with VEGA-3D-enhanced perception to reduce failures from “spatial blindness” (e.g., left/right confusions, occlusions).
- Workflow/product: ROS2 node or perception SDK that precomputes and caches “latent world” features per scene, then feeds fused tokens to the policy network during training/inference.
- Sector: Robotics, Manufacturing
- Dependencies/assumptions: Access to a DiT-based video generator (e.g., Wan2.1) or a comparable open model; GPU for feature extraction; multi-frame inputs; safety validation for deployment.
- Video analytics for retail operations: Spatially aware planogram and compliance checking from CCTV
- What: Detect product placement errors and spatial relationships (e.g., “beverages left of snacks”) without LIDAR or depth sensors.
- Workflow/product: On-prem inference service that caches VEGA-3D features per camera scene; enterprise dashboard for alerts and audit trails.
- Sector: Retail, Operations
- Dependencies/assumptions: Legal/consented video; compute overhead acceptable; model adapted to store environments (domain shift risk).
- AEC site monitoring and scan-to-BIM QA with commodity video
- What: Verify spatial relationships (e.g., door/window placements, clearance) by querying site videos; reduce reliance on dense 3D scanning for routine checks.
- Workflow/product: “Spatial QA” assistant integrated into BIM viewers where users ask queries (“Is the conduit 10 cm above the beam?”) and receive evidence-backed answers.
- Sector: Architecture, Engineering, Construction
- Dependencies/assumptions: Adequate camera coverage; tolerance for approximate (non-metric) answers unless calibrated; feature caching to amortize compute.
- E-commerce media tooling: Spatially informed captions and product-relationship tags
- What: Auto-generate descriptions like “The rug is centered under the table” to improve search and recommendations.
- Workflow/product: Batch captioning pipeline using VEGA-3D-fused VLMs; CMS plugin to curate spatial tags.
- Sector: Software, Retail
- Dependencies/assumptions: Domain adaptation for studio/home imagery; human-in-the-loop review for quality control.
- Post-production/VFX tracking assistance with multi-view consistency
- What: Improve object tracking, roto, and match-moves across shots by leveraging the generator’s multi-view priors.
- Workflow/product: Nuke/After Effects plugin that exports stable attention maps and correspondence fields from VEGA-3D features.
- Sector: Media/Entertainment
- Dependencies/assumptions: GPU resources; legal access to generator weights and licensing for commercial use.
- Safety monitoring in industrial settings: Proximity and layout checks from ambient video
- What: Detect unsafe spatial configurations (e.g., blocked emergency exits, incorrect distance to hazardous zones).
- Workflow/product: Edge gateway that computes VEGA-3D features once per scene and streams spatial alerts to a safety dashboard.
- Sector: Energy, Manufacturing, Occupational Safety
- Dependencies/assumptions: Privacy-compliant deployment; environment-specific tuning to reduce false alarms.
- Education tools for spatial reasoning and physics intuition
- What: Interactive tutors that answer “where/why” questions over lab or household videos (e.g., relative distances, object ordering).
- Workflow/product: Classroom app that runs VEGA-3D-enhanced Q&A on recorded experiments; teacher dashboards for misconceptions.
- Sector: Education, EdTech
- Dependencies/assumptions: Cloud inference to handle compute; curated content to avoid edge-case failures.
- Insurance and risk assessment triage from incident videos
- What: Rapid, spatially grounded summaries of scenes (e.g., “vehicle approached from the right, impact near rear-left”).
- Workflow/product: Claims intake tool that precomputes VEGA-3D features and provides structured spatial reports.
- Sector: Finance/Insurance
- Dependencies/assumptions: Legal use of footage; model robustness to low-light/compression; human verification.
- Robotics policy learning acceleration in simulation
- What: Improve sample efficiency of visuomotor learning by injecting VEGA-3D priors into the visual stream before training policies.
- Workflow/product: RL/IL training pipeline that uses frozen generative features and token-level fusion; logging of spatial attention maps for debugging.
- Sector: Robotics, Research
- Dependencies/assumptions: Simulator integration; reproducible access to DiT-based video backbones; compute budget.
- Smart-home AR measurement and layout assistants (cloud-backed)
- What: Enable smartphone video-based measurements and layout suggestions (“sofa fits between these two windows”).
- Workflow/product: Mobile app that uploads short room captures, runs server-side VEGA-3D-enhanced analysis, returns spatial overlays.
- Sector: Consumer Software, Real Estate
- Dependencies/assumptions: Latency tolerance; privacy; approximate scale unless calibrated.
- Dataset annotation acceleration for 3D tasks
- What: Pre-annotate spatial relations, object localization, and dense captions to reduce manual labeling time.
- Workflow/product: Labeling tool extension that overlays VEGA-3D attention and proposals for rapid acceptance/editing.
- Sector: Software, AI/ML Ops
- Dependencies/assumptions: Human-in-the-loop to correct biases; licensing for derived data.
- Benchmarking and diagnostics for spatial reasoning in MLLMs
- What: Use multi-view correspondence as a proxy metric to predict 3D performance and diagnose “spatial blindness.”
- Workflow/product: Evaluation suite computing correspondence scores and downstream task predictions pre- and post-fusion.
- Sector: Academia, AI Quality
- Dependencies/assumptions: Posed frames or approximate poses for analysis; standardized datasets.
- Policy and procurement pilots: Minimum spatial reasoning checks for embodied AI systems
- What: Add VEGA-3D-based tests (e.g., VSI-Bench categories) to procurement/safety checklists for robots or surveillance analytics.
- Workflow/product: Simple test harness that runs a fixed battery of spatial questions on representative videos.
- Sector: Public sector, Corporate governance
- Dependencies/assumptions: Policy alignment; transparency on model provenance and compute costs.
Long-Term Applications
These use cases are promising but require further research, engineering, validation, or ecosystem changes (e.g., distillation, on-device efficiency, regulatory approvals).
- On-device, real-time VEGA-3D via distillation/quantization
- What: Compress generative priors into lightweight encoders to meet latency and power budgets on edge devices.
- Sector: Mobile, IoT, Robotics
- Dependencies/assumptions: Successful distillation of mid-denoise representations; hardware acceleration; acceptable accuracy trade-offs.
- Autonomous driving and ADAS perception enhancement
- What: Use generative spatial priors to improve multi-camera 3D understanding (occlusions, cross-view consistency) without heavy LiDAR dependence.
- Sector: Transportation
- Dependencies/assumptions: Domain-specific training; safety-grade validation; robust performance in adverse weather/lighting.
- Surgical video understanding and robot-assisted procedures
- What: Provide spatially grounded instrument tracking and anatomy relation reasoning for decision support.
- Sector: Healthcare
- Dependencies/assumptions: Clinical-grade reliability; FDA/CE approval; domain adaptation to endoscopic/laparoscopic video; strict privacy.
- Consumer navigation and accessibility assistants
- What: Wearable or phone-based real-time spatial guidance (“chair to your left 1 meter”), aiding low-vision users.
- Sector: Assistive Tech, Consumer
- Dependencies/assumptions: On-device efficiency; robust generalization; safety guarantees; offline operation options.
- Digital twins with video-only updates
- What: Maintain factory/building twins by ingesting ambient videos to update spatial relations and detect drifts.
- Sector: Energy, Manufacturing, AEC
- Dependencies/assumptions: Calibration to approximate metric scale; integration with existing twin platforms; privacy-preserving deployment.
- AR/VR content creation with physics-consistent spatial edits
- What: Author scenes using natural-language spatial constraints (“move the lamp slightly behind the sofa”) with consistent multi-view coherence.
- Sector: Software, Gaming, Media
- Dependencies/assumptions: Tooling integration in DCC pipelines; user-friendly interfaces; hybrid workflows with 3D engines.
- Household robots with generalized spatial common sense
- What: Teach home robots to understand cluttered environments using VEGA-3D priors, improving grasping, placement, and tidying.
- Sector: Consumer Robotics
- Dependencies/assumptions: Long-horizon planning; safety; continual learning from diverse homes.
- Industrial inspection and maintenance from drone/bodycam video
- What: Recognize spatial anomalies (clearance violations, misalignments) in plants or pipelines without exhaustive 3D scanning.
- Sector: Energy, Utilities
- Dependencies/assumptions: Harsh-condition robustness; partial observability handling; compliance and auditability.
- Spatially grounded content moderation and platform safety
- What: Detect dangerous configurations (e.g., unsafe stunts, hazardous proximity) in user videos.
- Sector: Trust & Safety
- Dependencies/assumptions: Clear policy definitions; minimizing false positives; scalable inference.
- Finance and real estate: Property and damage assessment at scale
- What: Automated spatial reasoning over walk-through videos for inspections, valuations, and claims.
- Sector: Finance, Real Estate, Insurance
- Dependencies/assumptions: Standardized capture protocols; fairness and bias monitoring; human oversight.
- Science of intelligence: Probing learned “physical priors” in generative models
- What: Use VEGA-3D to study how implicit physics emerges and how it transfers to reasoning tasks.
- Sector: Academia, Cognitive Science
- Dependencies/assumptions: Access to intermediate representations; standardized benchmarks and ablations.
- Cross-modal 3D grounding for language agents
- What: Enable LLM agents to reliably refer to and manipulate objects in 3D simulators and the real world via unified spatial tokens.
- Sector: Software, Robotics
- Dependencies/assumptions: Tool-use frameworks for agents; safety layers; memory across long-horizon tasks.
- Standardization and certification of spatial reasoning capabilities
- What: Define sector-specific “spatial competency” tests (e.g., for service robots) drawing on correspondence metrics and task suites.
- Sector: Policy, Standards Bodies
- Dependencies/assumptions: Multi-stakeholder consensus; alignment with liability frameworks; periodic re-certification processes.
Cross-cutting assumptions and dependencies
- Model access and licensing: Many strongest video generators are DiT-based and may be proprietary; commercial use might require licenses or substitutions with open models.
- Compute and latency: VEGA-3D adds inference cost; practical deployments benefit from scene-level feature caching, batching, or distilled/lightweight variants.
- Data and domain shift: Performance depends on similarity to training domains; specialized finetuning or adapters may be necessary.
- Privacy and compliance: Video ingestion requires consent and secure handling; sensitive sectors (healthcare, workplace) demand stringent governance.
- Non-metric outputs by default: Without calibration, outputs are relational/spatial rather than metrically accurate; workflows should reflect this.
- Robustness and safety: For high-stakes applications, human-in-the-loop review, uncertainty estimates, and fail-safes are recommended.
Glossary
- Adaptive Average Pooling: A pooling operation that adaptively averages features to a target spatial/token size. "After Adaptive Average Pooling to match the semantic tokenization, we obtain the generative representation"
- Adaptive Gated Fusion: A token-level mechanism that dynamically weights and combines heterogeneous feature streams. "Adaptive Gated Fusion. It dynamically integrates heterogeneous features using a token-level gating mechanism."
- BEV rendering: Bird’s-Eye View projection that lifts 2D features to a top-down 3D representation. "project 2D features into 3D space using positional embeddings or BEV rendering."
- Camera extrinsics: The parameters (rotation and translation) that transform coordinates from the world frame to the camera frame. "using the ground-truth camera extrinsics and depth."
- Camera pose: The position and orientation of a camera in 3D space. "task-specific geometric annotations (e.g., depth, camera pose)."
- Convex combination: A weighted sum of vectors where weights are non-negative and sum to one. "The final fused representation is a convex combination determined by this gate:"
- Cosine similarity: A similarity measure between vectors based on the cosine of the angle between them. "The consistency score for this voxel is defined as cosine similarity:"
- Denoising: The diffusion-model process of removing noise to reconstruct structured signals. "Diffusion models are trained to enforce structural coherence primarily during active denoising of a corrupted signal;"
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion models that captures global spatiotemporal dependencies. "are Diffusion Transformers trained with Flow Matching"
- Flow Matching: A training objective that learns a continuous-time transport field to map noise to data in diffusion models. "are Diffusion Transformers trained with Flow Matching"
- Latent World Simulator: A generative model repurposed to provide implicit physical and geometric priors for downstream tasks. "repurposes a pre-trained video diffusion model as a Latent World Simulator."
- Layer Normalization: A normalization technique that normalizes activations across feature dimensions per token. "LN denotes Layer Normalization,"
- Min-Max normalization: Rescaling values to a fixed range (typically [0, 1]) based on dataset minima and maxima. "with Min-Max normalization across all evaluated models,"
- Multi-view Correspondence Score: A metric that quantifies cross-view geometric consistency via feature similarity in a shared 3D space. "we introduce Multi-view Correspondence Score."
- Normalized Overall Score (NOS): An aggregate metric formed by min-max normalizing per-task scores and averaging them. "we define a Normalized Overall Score (NOS)."
- Positional embeddings: Encodings that inject spatial position information into features for geometry-aware processing. "using positional embeddings or BEV rendering."
- Receptive field: The spatial extent of input that influences a neuron’s activation in a network. "limits the receptive field and hinders long-range geometric alignment."
- UNet architectures: Encoder–decoder networks with skip connections commonly used in diffusion models. "Models based on UNet architectures (e.g., SVD"
- Variational Autoencoder (VAE): A latent-variable generative model used to encode and decode images/videos into a compact latent space. "via the model's Variational Autoencoder (VAE)"
- Vision-Language-Action (VLA): Models that integrate visual perception, language understanding, and action policies for control. "a pre-trained Vision-Language-Action (VLA) model (e.g., OpenVLA-OFT"
- Voxel grid: A discrete 3D grid partitioning space into volumetric pixels (voxels) for aggregating features. "into a shared global voxel grid"
- Voxelization: The process of converting 3D space or point sets into a grid of voxels. "we use a voxel size of 0.1 for voxelization."
Collections
Sign up for free to add this paper to one or more collections.