WorldWarp: Propagating 3D Geometry with Asynchronous Video Diffusion
Abstract: Generating long-range, geometrically consistent video presents a fundamental dilemma: while consistency demands strict adherence to 3D geometry in pixel space, state-of-the-art generative models operate most effectively in a camera-conditioned latent space. This disconnect causes current methods to struggle with occluded areas and complex camera trajectories. To bridge this gap, we propose WorldWarp, a framework that couples a 3D structural anchor with a 2D generative refiner. To establish geometric grounding, WorldWarp maintains an online 3D geometric cache built via Gaussian Splatting (3DGS). By explicitly warping historical content into novel views, this cache acts as a structural scaffold, ensuring each new frame respects prior geometry. However, static warping inevitably leaves holes and artifacts due to occlusions. We address this using a Spatio-Temporal Diffusion (ST-Diff) model designed for a "fill-and-revise" objective. Our key innovation is a spatio-temporal varying noise schedule: blank regions receive full noise to trigger generation, while warped regions receive partial noise to enable refinement. By dynamically updating the 3D cache at every step, WorldWarp maintains consistency across video chunks. Consequently, it achieves state-of-the-art fidelity by ensuring that 3D logic guides structure while diffusion logic perfects texture. Project page: \href{https://hyokong.github.io/worldwarp-page/}{https://hyokong.github.io/worldwarp-page/}.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces WorldWarp, a method that turns a single photo into a long, smooth video where the camera moves around the scene while everything still looks 3D-correct. Think of it like exploring a room in a video game: even though you only start with one picture, the system creates a believable 3D world and lets the camera fly through it without things bending or breaking.
Key Objectives and Questions
The researchers wanted to answer three simple questions:
- How can we make long videos from just one image where the camera moves a lot, but the scene still makes 3D sense?
- How do we keep the video consistent over time so things don’t wobble, blur, or drift out of place?
- Can we combine strong 3D structure (so the geometry is right) with a powerful image generator (so the visuals look great) in a way that works for long sequences?
How It Works (Methods and Approach)
To make this easy to picture, imagine two jobs:
- The “builder”: creates a rough 3D model of the scene so the camera can move correctly.
- The “artist”: fills in missing parts and cleans up mistakes so the video looks nice and realistic.
WorldWarp mixes these two jobs carefully, step by step.
The 3D “builder”: an online 3D cache
- The method keeps an on-the-fly 3D model called a 3D Gaussian Splatting (3DGS) cache. You can think of 3DGS as a cloud of tiny glowing dots placed in 3D space to represent the scene. It’s fast and good at capturing shape and basic appearance.
- At every step, the system updates this 3D model using the most recent high-quality frames it made. This avoids the “snowball effect” where small errors grow bigger over time.
The 2D “artist”: a Spatio-Temporal Diffusion model (ST-Diff)
- Diffusion is a popular image/video method that starts with noisy pictures and gradually removes the noise, ending with sharp, realistic frames.
- ST-Diff is trained to look both backward and forward in time (non-causal), which means it can use “hints” from multiple frames instead of only the past. This is helpful because the camera path is known, so future views aren’t a total mystery.
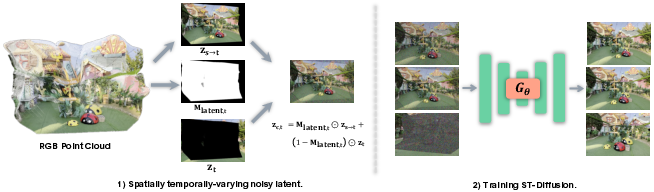
- The key trick: the system “warps” past frames into the next camera view. This creates a strong hint for what the next frame should look like. But warped images have holes (where the old camera couldn’t see) and distortions (from imperfect 3D). So ST-Diff learns to:
- Fill blank areas (newly visible parts) by generating them from scratch.
- Fix and refine warped areas to remove blur or errors.
A smart “noise schedule” to guide the artist
- In diffusion, noise tells the model how much to invent or how much to edit.
- WorldWarp uses different noise levels for different parts of the frame:
- Blank (occluded) regions get lots of noise, so the model fully generates new content.
- Warped (already filled) regions get only some noise, so the model gently corrects and improves them.
- This noise also varies per frame over time, which helps keep long videos stable.
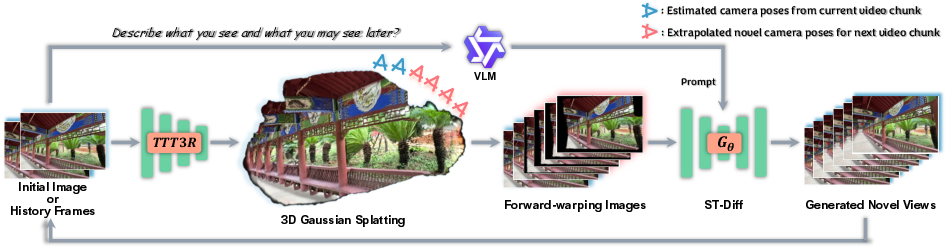
Step-by-step video creation (chunk-by-chunk)
- The system generates the video in chunks (small groups of frames), not all at once.
- For each chunk, it:
- Estimates camera poses and depth from the current history (using a geometry tool).
- Optimizes the 3DGS cache with those frames (the builder improves the 3D scene).
- Warps hints from this 3D model into the next camera viewpoints.
- Uses ST-Diff (the artist) to fill holes and fix errors with the smart noise plan.
- Moves on to the next chunk, now using the newly made frames as history.
This loop keeps geometry anchored and visuals polished as the camera moves far away from the original view.
Main Findings and Why They Matter
WorldWarp creates long videos (e.g., 200 frames) from a single image that stay 3D-consistent and visually sharp.
- It beats other methods on standard benchmarks (RealEstate10K and DL3DV) across many metrics:
- Better image quality (PSNR, SSIM, LPIPS, FID).
- Better camera correctness (lower rotation and translation errors), meaning the scene layout stays stable as the camera moves.
- A striking proof: the generated 200-frame video can be turned back into a high-quality 3D model using 3DGS. That means the video isn’t just pretty; it actually makes geometric sense over time.
- Ablation tests (small experiments to remove features and compare) show:
- Updating the 3DGS cache online is critical for avoiding drifting errors.
- The spatial-temporal noise design (different noise for holes vs. warped regions, and per-frame variation) strongly improves stability and detail.
Implications and Impact
- Better novel view synthesis: Explore scenes from new angles using just one photo—useful for virtual reality, movies, and games.
- More reliable camera control: The camera can move far and in complex paths without breaking the scene’s 3D logic.
- Practical content creation: Artists, developers, and creators can quickly build long, believable camera fly-throughs from minimal inputs.
- A powerful general idea: Combine a fast-updating 3D “anchor” (structure) with a flexible diffusion “refiner” (appearance). This balance of 3D logic and visual polish could improve many generative tools, not just camera-controlled video.
In short, WorldWarp shows how to keep long, moving-camera videos both beautiful and believable by smartly mixing geometry (the builder) with generation (the artist), guided by a clever noise plan and updated 3D cache at every step.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Training–inference mismatch: During training, “filled” (blank) regions in the composite latents are taken from ground-truth frames, whereas inference initializes them with pure noise. Quantify and mitigate this domain gap (e.g., train with noise-only fills, curriculum schedules, or synthetic occlusion augmentation).
- Sensitivity to depth/pose estimation: The method relies on TTT3R for depth and camera parameters. Provide a systematic robustness analysis to errors in depth, intrinsics, and extrinsics (including calibration drift, rolling shutter, lens distortion) and develop uncertainty-aware conditioning or error-correction strategies.
- Prior quality dependence: Forward-warped priors (and masks) are central to ST-Diff. Characterize performance as a function of prior coverage/quality (mask sparsity, warping artifacts) and investigate adaptive noise schedules or priors confidence weighting.
- Training with single-source warping vs. inference with 3DGS cache: Training uses one-to-all warps from a single source image; inference uses warps from a test-time optimized 3DGS built from generated history. Study the impact of this discrepancy and explore training with 3DGS-like priors (e.g., learned or synthetic caches) to reduce exposure bias.
- Non-causal token-wise timestep embedding: The paper introduces per-token, spatially varying time embeddings but lacks theoretical justification and sampling analysis. Provide formal convergence properties, ablations versus per-frame uniform timesteps, and comparisons to standard v-prediction or epsilon-prediction designs under mixed timesteps.
- Incomplete ablations: The ablation table omits results for “Temporal-varying noise” and does not isolate contributions from bidirectional attention, forward-warped priors, mask quality, or cache length. Complete these ablations and provide effect sizes with confidence intervals.
- VLM prompt role: The pipeline uses VLM-generated text prompts for semantic guidance without quantifying their contribution. Evaluate prompt sensitivity, prompt-free performance, prompt quality (hallucinations), and failure modes; consider human-in-the-loop or controllable semantics.
- Camera path specification and extrapolation: The paper references “extrapolated novel camera poses” but does not specify how paths are generated (heuristics vs. VLM-guided vs. GT). Clarify and evaluate robustness to OOD camera trajectories (e.g., extreme rotations, FOV changes, rapid parallax) and interactive path changes at test time.
- Dynamic scenes and non-rigid motion: The approach assumes quasi-static geometry cached in 3DGS. Test and extend to dynamic objects, articulated motion, and non-rigid deformations (e.g., motion segmentation, dynamic 3DGS, deformation fields).
- Lighting and material effects: Forward-warping assumes Lambertian behavior; gloss/specular/illumination changes are not modeled. Evaluate and design conditioning for view-dependent appearance (e.g., learned reflectance/BRDF priors or neural relighting).
- Long-horizon stability: Results are reported up to 200 frames. Characterize drift and texture degradation beyond 200 frames, analyze cache lifespan and update policies, and propose regularizers or periodic re-grounding to prevent self-reinforcement of artifacts.
- Cache design trade-offs: The online 3DGS cache is optimized each iteration (~200 steps). Report compute cost, memory footprint, latency, and scalability; explore lighter caches (e.g., sparse point clouds, meshes) or amortized optimization to enable real-time or resource-constrained deployment.
- Self-conditioning risk: Optimizing the 3DGS with generated frames may “lock-in” hallucinations or biases. Develop safeguards (e.g., confidence-weighted optimization, cross-view consistency checks, reinitialization schedules, or mixed-history training).
- Evaluation metrics limitations: FID/LPIPS/PSNR/SSIM do not directly assess 3D consistency or temporal coherence. Add video-specific metrics (e.g., FVD, tOF/tLPIPS temporal stability), multi-view photometric consistency, and 3D alignment metrics using scenes with GT geometry.
- Pose accuracy confound: Pose errors are computed from DUST3R poses re-estimated on generated frames, conflating image quality with pose recoverability. Evaluate pose error against the specified input trajectory directly or via scene reprojection consistency with GT geometry.
- Occlusion handling scale: The method fills blank regions with full noise but does not quantify performance under large disocclusions or severe missing priors. Benchmark across occlusion scales and propose priors (e.g., learned scene completion) when masks are extremely sparse.
- Chunk size and schedule: The paper does not analyze the effect of chunk length, tau/noise schedules, and update frequency on stability and quality. Provide systematic sweeps to identify optimal settings and adaptive policies.
- Multi-source conditioning: Although the teaser emphasizes single-image input, the pipeline can ingest multiple initial views. Explore gains from multi-view initialization, strategies to fuse priors across views, and training aligned to multi-source warps.
- Generalization beyond indoor scenes: Benchmarks focus on RealEstate10K and DL3DV. Test on outdoor/non-architectural datasets (e.g., urban/landscapes, aerial) and report OOD generalization, failure cases, and necessary priors (e.g., sky models).
- Alternative 3D priors: Compare 3DGS caches to meshes, NeRF variants, or hybrid point–mesh representations in terms of warping fidelity, artifacts, and compute; consider uncertainty-aware 3D priors.
- Theoretical grounding of “velocity” target: The loss regresses to ε − z_t, which deviates from standard diffusion formulations. Provide derivation, clarify relationship to v-pred, and analyze how mixed-token timesteps affect training dynamics and sampling correctness.
- Mask estimation quality: Validity masks depend on renderer z-buffering and depth quality. Investigate mask noise/false positives and propose learned mask refinement or uncertainty-aware blending to reduce artifacts at warp boundaries.
- Interactive/online use: The approach presumes known future camera poses to create non-causal priors. Assess responsiveness to user-driven path changes and propose mechanisms for on-the-fly prior generation without full cache re-optimization.
- Reproducibility and accessibility: Training uses a 1.3B model with 8×H200 GPUs; runtime and resource requirements are not reported. Provide open-source code, inference-time benchmarks on commodity hardware, and guidance for low-resource fine-tuning.
Practical Applications
Practical Applications of WorldWarp
WorldWarp couples an online 3D Gaussian Splatting (3DGS) cache with a non-causal, spatio-temporal diffusion model (ST-Diff) that uses forward-warped priors and spatially varying noise to generate long, geometrically consistent novel-view video from a single image. Below are actionable applications derived from its findings, methods, and innovations.
Immediate Applications
The following can be deployed now, assuming access to modern GPUs, the provided pipeline components (TTT3R for geometry, 3DGS for caching, VAE encoder/decoder, ST-Diff), and appropriate content licenses.
- Single-photo real estate walkthroughs (real estate, e-commerce)
- Use case: Turn a listing photo into a 200-frame, camera-controlled interior “tour” for marketing.
- Tools/workflow: Upload photo → estimate camera/depth (TTT3R) → optimize 3DGS cache on photo/history → render warped priors → ST-Diff fill-and-revise → export video and optional 3DGS asset.
- Dependencies/assumptions: Static scenes; accurate depth/pose estimation; GPU inference; disclosure that views are synthetic (policy/compliance).
- Previsualization in film and game production (media/entertainment)
- Use case: Generate long camera moves from a single concept art or plate image for shot planning.
- Tools/workflow: Blender/Unreal plug-in for path authoring; forward-warp prior visualization; ST-Diff refinement; 3DGS export for layout blocking.
- Dependencies/assumptions: Artistic plausibility over photometric accuracy; compute budget; careful use of VLM prompts for semantic guidance.
- AR/VR experience prototyping from a single photo (software/XR)
- Use case: Rapid creation of immersive scenes for pitch demos, ideation, and early UX testing.
- Tools/workflow: Unity/Unreal SDK; user-defined camera trajectories; chunk-based generation; import reconstructed 3DGS for scene integration.
- Dependencies/assumptions: Non-metric scale unless calibrated; static backgrounds; cloud GPU recommended.
- E-commerce product spins and zooms from one image (retail)
- Use case: Create consistent, camera-controlled product videos when only one image is available.
- Tools/workflow: Shopify app integration; automatic path generation; background cleanup; ST-Diff for occlusion fill; watermarking.
- Dependencies/assumptions: Best for isolated products with clear contours; depth estimation quality; label synthetic views.
- Architectural/interior visualization from a single render/photo (AEC)
- Use case: Produce fly-throughs of proposed designs or spaces from one still for stakeholder reviews.
- Tools/workflow: CAD plug-in; pose calibration wizard; path authoring; 3DGS export for quick spatial iteration.
- Dependencies/assumptions: Not metrically accurate unless intrinsics are calibrated; static scene; disclaimers for measurement reliability.
- Robotics dataset augmentation for monocular navigation/SLAM (robotics)
- Use case: Generate diverse view sequences for pretraining vision modules along controlled trajectories.
- Tools/workflow: Scripted path generation; forward-warp priors; ST-Diff synthesis; 3DGS reconstruction for synthetic maps.
- Dependencies/assumptions: Domain gap vs. real-world physics; static/uncluttered scenes preferred; label synthetic data.
- Educational demos for 3D geometry and camera motion (education)
- Use case: Interactive modules showing warping, masks, and spatially varying noise denoising.
- Tools/workflow: Notebooks with warping visualizations; ST-Diff step-by-step denoising; short sequences for teaching.
- Dependencies/assumptions: GPU access; curated example scenes; emphasis on conceptual understanding over metric fidelity.
- Cultural heritage storytelling from archival photos (culture)
- Use case: Guided explorations that extend archival imagery for exhibitions and kiosks.
- Tools/workflow: Curator-defined camera paths; conservative texture refinement; provenance and disclosure tagging.
- Dependencies/assumptions: Ethical considerations; authenticity disclaimers; static subject matter.
- Insurance claim triage visuals (finance/insurance)
- Use case: Generate multiple viewpoints from a single claim photo to assist early assessment.
- Tools/workflow: Claims platform plug-in; risk flagging; ST-Diff synthesis with watermarking; human-in-the-loop review.
- Dependencies/assumptions: Synthetic views are advisory, not evidentiary; policy guardrails; bias and misuse prevention.
- Social media cinematic moves from one image (consumer apps)
- Use case: Users author camera paths to make creative, long, consistent videos.
- Tools/workflow: Mobile app with path UI; cloud generation; safety filters; auto-caption “synthetic view.”
- Dependencies/assumptions: Cost control (batch/chunk generation); content moderation; licensing.
- Geospatial coverage QA augmentation (geospatial)
- Use case: Fill gaps for internal QA visualizations where street-level imagery is sparse.
- Tools/workflow: Internal tooling to visualize synthetic extensions; no map publication; clear internal labeling.
- Dependencies/assumptions: For QA only; not for public maps; synthetic must be distinct from real.
- 3DGS asset bootstrapping from a single image (3D content/tools)
- Use case: Derive a high-fidelity 3DGS model from the generated long sequence for rapid prototyping.
- Tools/workflow: WorldWarp-to-3DGS exporter; import into 3D editors; fast iteration for look dev.
- Dependencies/assumptions: Requires sufficiently long and varied camera paths; static scenes; memory footprint.
Long-Term Applications
These require further research, scaling, or development—e.g., robust handling of dynamic content, real-time performance, metric accuracy, regulatory frameworks, and broader generalization.
- Interactive telepresence from a single snapshot (communications/XR)
- Vision: Allow remote participants to explore environments beyond what’s captured in a single photo via camera-controlled novel views.
- Needed advances: Multi-image fusion; dynamic scene handling; privacy-preserving generation; low-latency inference; on-device acceleration.
- Digital-twin bootstrapping from sparse imagery (industrial/energy)
- Vision: Initialize facility/site twins from minimal photos to accelerate planning and inspection workflows.
- Needed advances: Metric scale recovery; multi-sensor fusion; semantic grounding; validation against real measurements; compliance standards.
- Autonomous navigation simulation at scale (robotics/automotive)
- Vision: Generate large libraries of geometrically consistent worlds from sparse inputs to train perception and control.
- Needed advances: Physics- and dynamics-aware generation; moving objects; controllable environmental conditions; domain adaptation strategies.
- Healthcare training scenes from references (healthcare/edtech)
- Vision: Create VR procedure rooms and clinical environments from limited imagery for training modules.
- Needed advances: Clinical accuracy and validation; patient privacy; regulatory approval; domain-specific geometry priors.
- Camera-conditioned generative video editors (software/tools)
- Vision: NLE plug-ins that maintain 3D consistency across edits and long camera moves with precise control.
- Needed advances: Tight integration with professional workflows; interactive path editing; incremental caching; real-time previews.
- Real-time on-device AR novel view synthesis (mobile)
- Vision: Run WorldWarp-like methods on mobile hardware for live AR camera moves from a single snapshot.
- Needed advances: Model distillation/quantization; hardware acceleration; low-power spatio-temporal noise scheduling; fast geometry estimation.
- Regulatory standards for synthetic spatial media (policy)
- Vision: Industry-wide metadata, watermarking, and disclosure norms for synthetic novel views used in commerce, maps, or journalism.
- Needed advances: Robust provenance tools; interoperable metadata; detection methods; stakeholder alignment and enforcement.
- Property appraisal and remote inspection protocols (finance/real estate)
- Vision: Controlled use of synthetic walkthroughs for preliminary appraisal and inspection under clear rules.
- Needed advances: Accuracy audits; liability frameworks; explicit disclaimers; standardized workflows; human verification steps.
- Safety test suites for spatial AI (robotics/software assurance)
- Vision: Systematically generate corner-case camera paths and scenes to stress-test SLAM/VIO and perception stacks.
- Needed advances: Scenario libraries; measurable coverage metrics; physics-grounded consistency; coupling with simulators.
- Educational curricula on 3D generative geometry (education)
- Vision: Institutionalized modules combining forward-warping, masking, and spatio-temporal diffusion to teach modern 3D vision.
- Needed advances: Open educational resources; interactive tooling; low-cost compute access; alignment with standards.
Cross-Cutting Assumptions and Dependencies
Across applications, feasibility depends on:
- Static scene bias: Current pipeline performs best when the scene is mostly static; dynamic objects introduce artifacts without additional modeling.
- Geometry quality: Reliance on accurate camera pose and depth estimation (e.g., TTT3R or similar); errors propagate into warping and synthetic views.
- Compute requirements: Training used 8×H200 for fine-tuning; inference benefits from high-end GPUs, especially for longer sequences and 3DGS optimization.
- Calibration and scale: Without known intrinsics or scale, outputs are visually consistent but not metrically accurate; some sectors require calibration.
- Synthetic disclosure: Many use cases (real estate, insurance, geospatial, media) require explicit labeling/watermarking and provenance.
- Domain generalization: Performance can degrade under extreme OOD camera paths or unusual textures; ongoing dataset and model improvements are needed.
- Workflow integration: Production-grade tools need path authoring UIs, cache management, VLM prompt co-pilots, batch/chunk orchestration, and editor/game-engine plug-ins.
Glossary
- 3D Gaussian Splatting (3DGS): A 3D representation that models scenes using Gaussian primitives for fast, differentiable rendering and view synthesis. "The high geometric consistency of our 200-frame generated sequence is demonstrated by its successful reconstruction into a high-fidelity 3D Gaussian Splatting (3DGS)~\cite{3dgs} model (right)."
- 3D geometry foundation model: A model that estimates scene geometry (e.g., depth and camera parameters) used to condition generation or warping. "obtained from a 3D geometry foundation model~\cite{ttt3r}."
- Autoregressive inference pipeline: A sequential generation approach where each produced chunk informs the next, reducing error propagation. "WorldWarp operates via an autoregressive inference pipeline that generates video chunk-by-chunk (see \cref{fig:inference})."
- Bidirectional attention: An attention mechanism that conditions on both past and future information across frames. "The key to our system is a Spatio-Temporal Diffusion (ST-Diff) model~\cite{wan,ldm}, which is trained with a powerful bidirectional, non-causal attention mechanism."
- CaPE: A relative camera pose encoding scheme used to represent viewpoint changes more robustly than absolute parameters. "or relative representations like CaPE~\cite{kong2024eschernet}."
- Camera extrinsics: External camera parameters (rotation and translation) defining the camera’s position and orientation in world coordinates. "Simply using raw camera intrinsics and extrinsics is often suboptimal,"
- Camera intrinsics: Internal camera parameters (e.g., focal length, principal point) describing projection from 3D to image space. "Simply using raw camera intrinsics and extrinsics is often suboptimal,"
- Camera pose encoding: Embedding camera parameters into a condition for generative models to control viewpoint. "The first is camera pose encoding, which embeds abstract camera parameters as a latent condition~\cite{zero123,cameractrl,motionctrl,genwarp,zeronvs,kong2024eschernet}."
- DFoT (Diffusion Forcing Transformer): A diffusion paradigm that applies per-frame noise schedules to enable non-causal conditioning in video denoising. "The Diffusion Forcing Transformer (DFoT)~\cite{dfot} paradigm re-frames the noising operation as progressive masking, where each frame in a video is assigned an independent noise level $k_t \in [0, 1]."</li> <li><strong>Differentiable point-based renderer</strong>: A renderer that projects point clouds to images while allowing gradients to flow for optimization. "using a differentiable point-based renderer."</li> <li><strong>Diffusion model</strong>: A generative model that iteratively denoises random noise into structured outputs guided by conditioning signals. "A novel diffusion model then generates the next chunk by correcting these hints and filling in occlusions using a spatio-temporal varying noise schedule."</li> <li><strong>DUST3R</strong>: A method for estimating camera poses from images, used here to evaluate geometric alignment of generated views. "We use DUST3R~\cite{dust3r} to extract poses ($\mathbf{R}_{\text{gen}\mathbf{t}_{\text{gen}$) from generated views."</li> <li><strong>Explicit 3D spatial priors</strong>: 3D scene representations (e.g., meshes, point clouds, 3DGS) used to guide novel view generation via re-projection. "The second strategy, which uses an explicit 3D spatial prior, was introduced to solve this OOD issue~\cite{fridman2023scenescape,hollein2023text2room,viewcrafter,vmem}."</li> <li><strong>Forward-warped images</strong>: Images reprojected from a source view into future target camera viewpoints to provide geometric hints. "using forward-warped images from future camera positions as a dense, explicit 2D spatial prior~\cite{ttt3r}."</li> <li><strong>Fréchet Image Distance (FID)</strong>: A metric measuring distributional similarity between generated and real images using deep features. "We measure the distributional similarity between generated views and the test set using the Fréchet Image Distance (FID)~\cite{fid}."</li> <li><strong>Inpainting</strong>: Filling missing or occluded regions in images or videos with plausible content. "This strategy typically employs standard inpainting or video generation techniques~\cite{fridman2023scenescape,hollein2023text2room,vmem},"</li> <li><strong>Latent space</strong>: A compressed representation space where diffusion and compositing operations are performed. "then performs all diffusion, compositing, and noising operations in the latent space using a pre-trained VAE encoder $\mathcal{E}(\cdot)\mathcal{D}(\cdot)$~\cite{wan,ldm}."</li> <li><strong>LPIPS</strong>: A perceptual similarity metric comparing deep feature distances to assess visual quality. "we assess the model's ability to preserve image details across views by computing PSNR, SSIM~\cite{ssim}, and LPIPS~\cite{lpips}."</li> <li><strong>Non-causal attention</strong>: Attention that does not enforce temporal causality, allowing conditioning on future frames. "trained with a powerful bidirectional, non-causal attention mechanism."</li> <li><strong>Novel View Synthesis (NVS)</strong>: Generating images or video from new camera viewpoints of a scene. "Novel View Synthesis (NVS) has emerged as a cornerstone problem in computer vision and graphics,"</li> <li><strong>Occlusions</strong>: Regions not visible from a given viewpoint due to blocking geometry, leading to blank areas after warping. "suffering from occlusions (blank regions) and distortions from 3D estimation errors~\cite{genwarp,viewcrafter}."</li> <li><strong>Out-Of-Distribution (OOD)</strong>: Data or conditions not represented in the training set, often causing poor generalization. "often fails to generalize to Out-Of-Distribution (OOD) camera poses,"</li> <li><strong>Plücker embeddings</strong>: A 6D line representation per pixel that encodes camera rays for geometry-aware conditioning. "For example, Plücker embeddings~\cite{sitzmann2021light} define a 6D ray vector for each pixel."</li> <li><strong>Point cloud</strong>: A set of 3D points (with color) representing a scene, used for warping and rendering. "unprojected into a 3D RGB point cloud $\mathcal{P}_s$:"
- PSNR: Peak Signal-to-Noise Ratio, a pixel-wise fidelity metric for image/video quality. "we assess the model's ability to preserve image details across views by computing PSNR, SSIM~\cite{ssim}, and LPIPS~\cite{lpips}."
- Re-projection: Rendering 3D content from one viewpoint into another to create priors for generation. "builds 3D models (e.g., meshes, point clouds, 3DGS~\cite{3dgs})~\cite{fridman2023scenescape, hollein2023text2room, muller2024multidiff, popov2025camctrl3d, viewcrafter,vmem} for re-projection and inpainting."
- Spatio-Temporal Diffusion (ST-Diff): A diffusion model designed to jointly handle spatial and temporal conditioning for novel view synthesis. "We address this using a Spatio-Temporal Diffusion (ST-Diff) model designed for a \"fill-and-revise\" objective."
- Spatio-temporal varying noise schedule: A noise strategy assigning different levels across space and time to trigger generation in blanks and refinement elsewhere. "Our key innovation is a spatio-temporal varying noise schedule: blank regions receive full noise to trigger generation, while warped regions receive partial noise to enable refinement."
- SSIM: Structural Similarity Index Measure, assessing perceived structural fidelity between images. "we assess the model's ability to preserve image details across views by computing PSNR, SSIM~\cite{ssim}, and LPIPS~\cite{lpips}."
- Test-time optimized 3D representation: A 3D model refined during inference to serve as a high-fidelity geometric cache. "our inference pipeline leverages a dynamic, test-time optimized 3D representation as an explicit geometric cache."
- VAE (Variational Autoencoder): An encoder–decoder architecture that maps images to latents and back, used for diffusion in latent space. "using a pre-trained VAE encoder and decoder ~\cite{wan,ldm}."
- Validity mask: A per-pixel mask indicating which warped pixels are valid after rendering from a point cloud. "and a corresponding validity mask sequence, ."
- Vision-LLM (VLM): A model that processes both visual and textual inputs to provide semantic guidance. "a Vision-LLM (VLM)~\cite{qwen} for semantic guidance."
- View extrapolation: Generating views that extend well beyond the set of original camera poses, creating new content and structure. "the frontier of the field lies in view extrapolation~\cite{infinitenature,infinitenature0,genwarp,cameractrl,motionctrl,vmem}."
- View interpolation: Generating views between existing camera poses within the original distribution. "While traditional NVS methods excel at view interpolation, which generates new views within the span of existing camera poses~\cite{nerf,3dgs,mipnerf},"
- Warped priors: Reprojected images used as geometric hints for diffusion-based refinement. "These warped priors, along with the VLM prompt, are fed into our non-causal ST-Diff model () to denoise and generate the -th chunk of novel views."
Collections
Sign up for free to add this paper to one or more collections.