Lyra 2.0: Explorable Generative 3D Worlds
Abstract: Recent advances in video generation enable a new paradigm for 3D scene creation: generating camera-controlled videos that simulate scene walkthroughs, then lifting them to 3D via feed-forward reconstruction techniques. This generative reconstruction approach combines the visual fidelity and creative capacity of video models with 3D outputs ready for real-time rendering and simulation. Scaling to large, complex environments requires 3D-consistent video generation over long camera trajectories with large viewpoint changes and location revisits, a setting where current video models degrade quickly. Existing methods for long-horizon generation are fundamentally limited by two forms of degradation: spatial forgetting and temporal drifting. As exploration proceeds, previously observed regions fall outside the model's temporal context, forcing the model to hallucinate structures when revisited. Meanwhile, autoregressive generation accumulates small synthesis errors over time, gradually distorting scene appearance and geometry. We present Lyra 2.0, a framework for generating persistent, explorable 3D worlds at scale. To address spatial forgetting, we maintain per-frame 3D geometry and use it solely for information routing -- retrieving relevant past frames and establishing dense correspondences with the target viewpoints -- while relying on the generative prior for appearance synthesis. To address temporal drifting, we train with self-augmented histories that expose the model to its own degraded outputs, teaching it to correct drift rather than propagate it. Together, these enable substantially longer and 3D-consistent video trajectories, which we leverage to fine-tune feed-forward reconstruction models that reliably recover high-quality 3D scenes.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Lyra 2.0: Explorable Generative 3D Worlds”
What is this paper about?
This paper shows how to create big, explorable 3D worlds starting from just one picture. The system, called Lyra 2.0, first makes a long, camera-controlled video that looks like you’re moving through the scene. Then it turns that video into a real 3D model you can walk around in, view from different angles, and use in game engines or simulations.
What questions are the researchers trying to answer?
In simple terms, they ask:
- How can we make a video that stays consistent when the camera moves a long way, even coming back to places seen before?
- How do we stop the video from slowly “drifting”—where tiny mistakes add up and the scene’s colors and shapes get warped over time?
- How can we turn those videos into clean, useful 3D models quickly and reliably?
How does Lyra 2.0 work? (Step-by-step, with plain-language analogies)
Here’s the basic loop Lyra 2.0 follows:
- You give it one image and tell it how the camera should move next (like planning a path through a room or down a street). You can also give a short text hint about the style.
- The system generates a short video chunk that follows that camera path.
- It updates a “memory” of what the scene looks like so it can stay consistent.
- It repeats this to keep exploring, and later converts the video into a 3D world.
To make this reliable over long distances, Lyra 2.0 uses two key ideas:
1) Anti-forgetting: keeping the world consistent when you revisit places
- The problem: As the camera moves forward, earlier frames fall out of the model’s short-term memory. When you come back to an old spot, the model might “forget” how it looked and make something different.
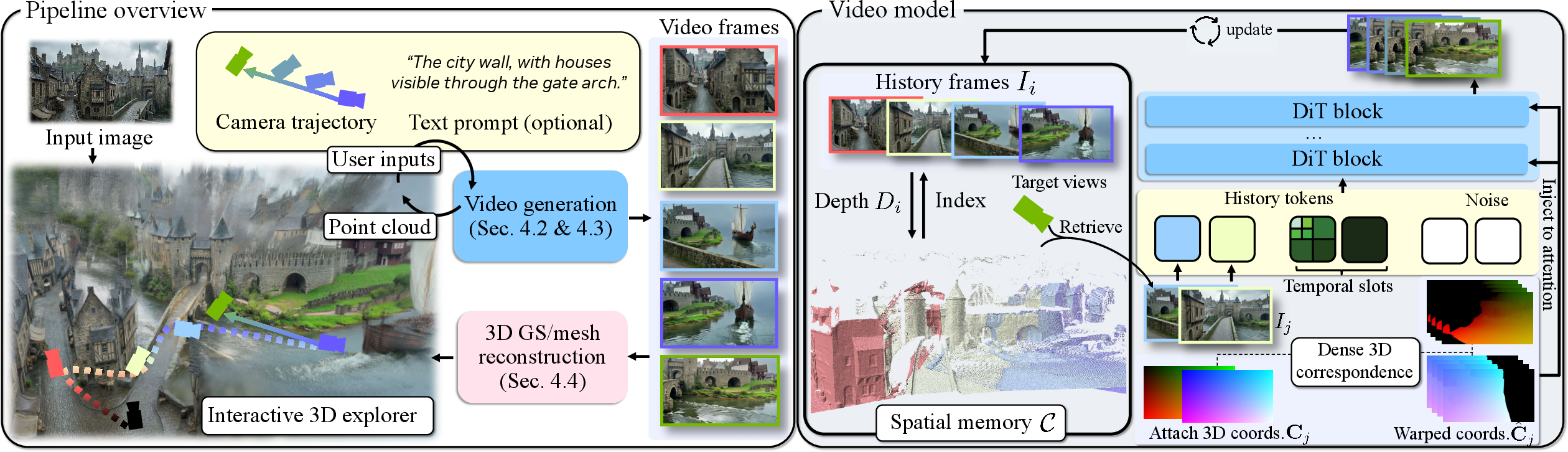
- The idea: Lyra 2.0 keeps a lightweight 3D “index” for each past frame (like pinning points on a map for that frame). It doesn’t try to build one giant, perfect 3D model while generating the video; it only uses these per-frame 3D hints to find and line up the most relevant past views. Think of it like using pins and strings on a corkboard to find matching spots between old photos and the new view.
- Why this helps: The video model gets the right past frames and precise “which pixel matches which” guidance, but it still paints the final image itself. That avoids copying past errors forward or forcing hard, glitchy renderings into the new frame.
2) Anti-drifting: stopping small mistakes from growing
- The problem: The video is made step-by-step, using previous outputs to make the next ones. It’s like photocopying a photocopy—small flaws can accumulate into big distortions.
- The idea: During training, the model sometimes practices using slightly imperfect versions of its own recent frames (not just perfect ground truth). This is like practicing to fix your own mistakes instead of only practicing under ideal conditions.
- Plus: Lyra 2.0 compresses history cleverly (called “FramePack”) so it can keep a longer timeline in view: recent frames are detailed; older frames are summarized. It always keeps the very first image sharp as a style anchor so the look doesn’t drift.
Turning videos into 3D you can use
- After generating the long video, Lyra 2.0 converts it into 3D using a fast, feed-forward method called 3D Gaussian Splatting (imagine building shapes from millions of tiny, colored “glow-dots” that together form surfaces).
- It then extracts a mesh (the familiar “skin” of a 3D model) that can be loaded into common tools. They fine-tune this converter to handle slight inconsistencies that video generation might still have, so the final 3D is clean and stable.
Speeding things up
- They also “distill” the big model into a faster one (like teaching a smaller student to mimic a high-performing teacher) so it needs far fewer steps to produce good results. That makes interactive use faster.
What did they find, and why is it important?
- The videos stay consistent over much longer “journeys” than past methods, even when the camera returns to earlier places.
- The system follows the camera path accurately and keeps the style (colors, materials, lighting) steady over time.
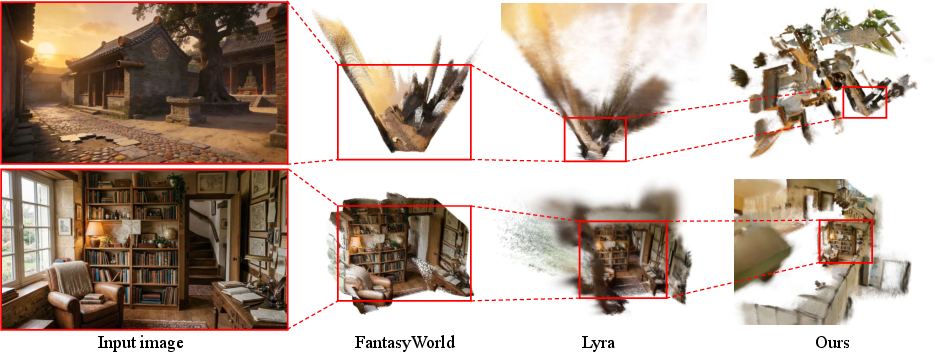
- When those videos are turned into 3D, the results are cleaner and more faithful, with fewer floaty bits or distortions, than other approaches they compared with.
- The faster, distilled version still looks good while being much quicker, which is useful for interactive exploration.
This matters because it shows a practical way to go from one image to a large, believable 3D environment you can actually explore and use. It reduces the need for expensive real-world scanning or many photos, making 3D world creation more accessible.
What could this change in the future?
- Game development and VR/AR: Rapidly generate big, walkable spaces from a single concept image.
- Robotics and simulation: Create varied, realistic training spaces without needing to scan real locations.
- Education and creativity: Let artists and students quickly turn sketches or photos into explorable worlds.
In short, Lyra 2.0 combines smarter memory with practice-on-its-own-mistakes training to generate long, consistent videos from a single image and then turns those videos into high-quality 3D worlds—pushing forward how fast and how far we can create explorable virtual spaces.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper that future researchers could address:
- Static-scene assumption: the pipeline implicitly assumes rigid, static environments; it does not address dynamic objects or non-rigid motion and how to represent, retrieve, and reconstruct them consistently in 3D.
- Dependence on monocular depth quality: retrieval and correspondence warping hinge on depth estimates from generated frames; there is no uncertainty modeling, depth refinement, or robustness analysis under severe depth errors (e.g., textureless areas, reflections, translucency, motion blur, low light).
- No loop-closure or global layout correction: per-frame caches avoid fusing depth errors but do not supply global constraints; the method lacks mechanisms to detect and correct global drift over very long trajectories or across repeated loops.
- Occlusion handling in correspondences: canonical coordinate warping uses a fixed depth threshold δ and forward warping; there is no explicit, learned occlusion reasoning, backward checks, or confidence-weighted fusion to mitigate boundary bleeding and disocclusion artifacts.
- Handcrafted retrieval heuristics: geometry-aware frame selection is greedy and threshold-based; there is no learned retrieval policy, per-pixel/patch-level weighting, or uncertainty-aware scoring, and no analysis of the trade-off between spatial coverage and noise accumulation.
- Spatial slot budget fixed at N_s=5: the paper does not explore adaptive slot counts, dynamic per-scene budgets, or how performance scales as N_s grows/shrinks under tight token budgets.
- Extreme camera motions and sparse-overlap regimes: behavior under large, discontinuous camera jumps, teleports, or panoramic spins with minimal historical overlap is not characterized; failure modes and safeguards are unclear.
- Self-augmentation approximation gap: the proposed one-step denoise augmentation may not match the full error distribution encountered during multi-step, multi-chunk autoregressive rollouts; alternatives like scheduled sampling, multi-step synthetic rollouts, or student-driven histories are not evaluated.
- Anti-drift trade-offs: while self-augmentation improves long-horizon robustness, it can reduce per-frame subjective quality; the paper does not quantify optimal choices of augmentation probability p_aug, noise range t, or curriculum schedules.
- Distillation control loss: DMD distillation reduces denoising steps but degrades camera controllability; the paper does not investigate control-aware distillation losses, trajectory-consistency regularizers, or hybrid few-step samplers to retain control.
- Memory growth and scalability: the 3D cache grows per frame; there is no pruning, summarization, or hierarchical memory policy, nor analysis of memory/latency behavior for thousands of frames or city-scale explorations.
- Metric scale and pose consistency: monocular depth and pose estimates can be scale-ambiguous or drift over time; the method does not enforce or evaluate metric fidelity or inter-chunk scale consistency needed for robotics/simulation use.
- Robustness to camera noise: the approach assumes accurate intrinsics/extrinsics; its tolerance to pose/intrinsic errors, quantization, or latency in interactive control is unexplored.
- Domain and condition generalization: beyond DL3DV and Tanks-and-Temples, robustness to adverse weather, nighttime, highly reflective/transparent scenes, stylized images, or synthetic/AI-generated inputs is not assessed.
- Illumination and relighting: generated worlds and 3DGS reconstructions are not physically-based; consistent global illumination, view-dependent effects, relightability, and material recovery remain open.
- Reconstruction fidelity and artifacts: feed-forward 3DGS handles minor inconsistencies but can retain floaters or holes; there is no explicit post-processing or global optimization to enforce multi-view consistency or surface regularity.
- Mesh extraction quality: the hierarchical VDB meshing lacks quantitative evaluation (watertightness, topology correctness, normal/curvature fidelity) and scalability analysis for very large scenes; no LOD/streaming strategy is provided.
- Feedback-loop risk in reconstruction fine-tuning: fine-tuning DAv3 on self-generated data can entrench model biases or artifacts; safeguards (e.g., mixed real/generative curricula, uncertainty filtering) are not explored.
- Evaluation metric gaps: metrics like SSIM/LPIPS/FID and reprojection error (computed from SLAM on generated frames) may not reflect global layout correctness or loop-closure consistency; new benchmarks/metrics for long-horizon 3D persistence are needed.
- Retrieval latency vs. token budget: the cost of geometry-based retrieval and tokenization at high resolutions is not profiled; practical limits for interactive use (fps, memory) and resolution scaling remain unclear.
- Text guidance interactions: the system allows optional text prompts, but how semantics edits interact with spatial memory (e.g., adding objects while preserving layout) and how to avoid geometry-text conflicts is not addressed.
- Thin structures, mirrors, and transparency: known depth and correspondence failure cases (thin poles, glass, water, specularities) are not analyzed; targeted mitigations are absent.
- Multi-agent/multi-camera settings: generating and fusing simultaneous trajectories from multiple cameras or agents is not supported; conflict resolution, memory sharing, and synchronization remain open.
- Active exploration: camera paths are user-defined; there is no automatic trajectory planning to maximize coverage, close loops, or reduce uncertainty via information gain across long sessions.
- Alternative correspondence signals: only warped canonical coordinates are injected; comparisons to feature-space warping (e.g., learned descriptors, optical flow), or joint 2D-3D correspondence learning with uncertainty are missing.
- Confidence-aware attention: the aggregation MLP does not incorporate per-pixel confidence (depth uncertainty, warp residuals) to gate attention; designing uncertainty-weighted attention for noisy multi-view context is open.
- Ultra-long horizon stability: while examples near ~800 frames are shown, failure rates, drift statistics, and memory/quality behavior over thousands of frames (or hours of interaction) are not reported.
- Safety and ethics: dataset curation, bias, and content safety in long-horizon world generation are not discussed; mechanisms for preventing harmful or misleading content in interactive exploration are absent.
Practical Applications
Immediate Applications
The following use cases can be piloted today using the paper’s methods (camera-controlled video diffusion with anti-forgetting retrieval and anti-drifting self-augmentation, feed-forward 3D Gaussian Splatting with mesh extraction, and the 13× faster DMD-distilled model). Each item includes sectors, example tools/workflows, and key assumptions or dependencies.
- Entertainment, Games, and VR/AR
- Rapid level pre-visualization and world prototyping from concept art or a single reference image
- Workflow: Import image → define camera path interactively → generate long-horizon video (DMD model for interactive speed) → reconstruct to 3DGS → extract mesh via hierarchical OpenVDB → import to Unity/Unreal for blocking, lighting, and gameplay tests.
- Dependencies: GPU with enough memory; availability of Lyra 2.0 or equivalent camera-controlled video model; 3DGS/mesh import plugins; rights to the input image.
- Virtual set extension and storyboarding for film/TV and advertising
- Workflow: Storyboard frame → generate controlled camera moves with consistent lookbacks → export mesh for DCC tools (Maya/Blender) → iterate art direction.
- Assumptions: Creative teams accept generative hallucinations for previz; color/drift held in check via anti-drifting training.
- Indie VR/AR content creation
- Workflow: “Photo-to-world” asset creation for immersive scenes; deploy meshes and Gaussian splats to lightweight viewers.
- Dependencies: Device-side viewers supporting 3DGS or mesh rendering; stable camera control UI.
- Robotics and Embodied AI
- Synthetic training and evaluation environments for navigation, mapping, and embodied tasks
- Workflow: Define patrol/coverage trajectories → generate persistent long-horizon scenes with revisits → reconstruct 3DGS/mesh → deploy in simulators (e.g., Isaac Sim, Gazebo, Habitat).
- Assumptions: Visual realism sufficient for sim2real pretraining; camera-control fidelity is adequate for robotics FOVs; domain randomization may still be needed.
- Benchmarking long-horizon consistency for SLAM/VO/Depth models
- Workflow: Use exported camera trajectories and generated frames to compute reprojection errors and consistency metrics; stress-test revisit stability.
- Dependencies: Access to evaluation metrics (e.g., reprojection error) and integration with SLAM toolchains.
- Architecture, Real Estate, and Interior Design
- Early-stage spatial ideation and client visualization from a single photo
- Workflow: Photo of room/site → define walkthrough → generate explorable video → produce 3D mesh for quick spatial layouts and mood boards.
- Assumptions: Not metrically accurate; suitable for conceptual communication, not construction; clear disclaimers to prevent misrepresentation.
- E-commerce and Marketing
- Contextualized, interactive product showcases
- Workflow: Generate room/scene from an inspiration photo → place 3D products into reconstructed mesh → render interactive views for web/AR product pages.
- Dependencies: Product 3D assets and simple collision/placement tools; quality control to avoid implausible geometry.
- Education and Cultural Heritage
- Exploratory learning content and museum experiences from archival imagery
- Workflow: Historical photo → generate long camera paths (including lookbacks) → reconstruct a navigable 3D experience for exhibits or online platforms.
- Assumptions: Generative hallucination acceptable for public engagement with appropriate provenance notices; not a substitute for scientific reconstructions.
- Research and Academic Tooling
- Methodological baselines for long-horizon 3D consistency and memory in video generation
- Use cases: Ablation comparisons; studying anti-forgetting (per-frame geometry routing, canonical coordinate warping) and anti-drifting (self-augmentation + FramePack); improved 3D reconstruction tolerance to generative noise.
- Dependencies: Access to model weights or reimplementation on an open video diffusion backbone; datasets with pose/depth.
- Software/Tools Ecosystem
- “Photo-to-World” plugins and SDKs
- Workflow: Wrap retrieval-based conditioning, DMD-distilled inference, and 3DGS→mesh extraction as a plugin for Unity/Unreal/Blender and viewers.
- Assumptions: Licenses permitting redistribution; engineering integration with OpenVDB-based extraction and 3DGS viewers.
- Policy and Compliance (Immediate Guidance)
- Disclosure and provenance for generative 3D assets in marketing/real estate
- Workflow: Auto-embed provenance metadata/watermarks when exporting meshes; provide disclaimers in listings or product pages.
- Dependencies: Organizational policy; watermarking standards; legal review of derivative content.
Long-Term Applications
These use cases need further research, scaling, accuracy improvements, or ecosystem development before broad deployment.
- Autonomous Driving and Mobility
- City-scale, consistent synthetic worlds for closed-loop perception/planning tests
- Potential: Generate long, revisitable street scenes from minimal references for scenario testing and rare-event synthesis.
- Dependencies: Higher metric/geometric fidelity; validated traffic agents; regulatory acceptance for safety-critical testing; multi-sensor realism (LiDAR, radar).
- Architecture, Engineering, and Construction (AEC) and Digital Twins
- From photo to metrically accurate, BIM-aligned walkthroughs and early feasibility analysis
- Potential: Rapidly explore design options, space usage, and renovations from sparse imagery.
- Dependencies: Metric calibration, multi-view constraints, and alignment with CAD/BIM; error bounds; legal/contractual acceptance.
- Healthcare and Surgical Simulation
- Generative 3D training scenarios for procedures and patient education
- Potential: Create explorable virtual operating rooms or anatomical contexts from limited visual references.
- Dependencies: High anatomical accuracy and validation; risk and ethics review; alignment with real instrumentation and physics.
- Public Safety, Emergency Response, and Defense
- Mission rehearsal in synthetic but consistent facilities
- Potential: Create large-scale, revisitable environments from few references for training responders.
- Dependencies: Accurate semantics, physics, and materials; strong provenance and access control; policy guardrails for dual-use risks.
- Geospatial Mapping and Smart Cities
- From sparse oblique/satellite imagery to explorable urban twins for planning and analytics
- Potential: Rapid scenario prototyping for pedestrian/traffic flow or infrastructure planning.
- Dependencies: Domain adaptation to aerial/oblique sensors, metric accuracy, semantics, and integration with GIS; regulatory oversight.
- Consumer AR/VR World Expansion
- On-device or cloud-assisted “expand my room/world” apps
- Potential: Interactive, headset-native generation and exploration, with real-time refinement.
- Dependencies: On-device acceleration, streaming of 3DGS/meshes, robust UX for camera control; privacy handling for user imagery.
- Robotics Foundation Models and Large-Scale RL
- Procedurally generated, long-horizon, consistent worlds for training generalist agents
- Potential: Massive diverse scenes with revisit dynamics to improve memory and exploration policies.
- Dependencies: Scalable generation pipelines, realism and task diversity, sim2real bridging techniques, standardized benchmarks.
- Standards, Governance, and Provenance
- Industry-wide frameworks for labeling, watermarking, and auditing generative 3D
- Potential: Prevent misuse (e.g., deceptive real estate visuals), enable trust in simulations and public-facing content.
- Dependencies: Cross-industry agreement, interoperable metadata formats, auditing tools integrated into export pipelines.
- Enterprise Asset Pipelines and Marketplaces
- Generative world studios and asset marketplaces for explorable scenes
- Potential: One-click services to turn references into navigable worlds; licensing and royalty frameworks.
- Dependencies: IP clarity for derivative works; quality control; scalable hosting/rendering infrastructure.
- Energy/Industrial Inspection Simulation
- Training environments for inspection robots in plants and refineries
- Potential: Rapid creation of plausible-but-consistent spaces for procedure rehearsal and anomaly detection pretraining.
- Dependencies: Accurate industrial semantics and physics; safety certifications; domain adaptation to industrial imagery.
- Finance and Real Estate Analytics (Ethical/Regulatory Gatekeeping)
- Visualization and marketing collateral generation (with strict disclosure)
- Potential: Faster content creation for listings or feasibility teasers.
- Dependencies: Clear policies to avoid misrepresentation; compliance tooling for disclosures and watermarks; potential regulation.
Cross-Cutting Assumptions and Dependencies
- Technical
- High-performance GPUs; access to or reimplementation of the camera-controlled video diffusion backbone (e.g., Wan-derived DiT + VAE) and Lyra 2.0 techniques.
- Support for 3DGS rendering or conversion to meshes; stable OpenVDB-based extraction and decimation workflows.
- Domain adaptation for non-photographic inputs (aerial, medical, industrial) and for metric accuracy when required.
- Data and Quality
- Input image rights and privacy compliance; variable realism and geometric accuracy—outputs are generative, not ground truth.
- Drifting and minor inconsistencies remain possible; fine-tuning reconstruction on generated data helps but does not guarantee metric fidelity.
- Legal and Policy
- Provenance, watermarking, and disclosure are recommended, especially in consumer-facing or regulated domains.
- Clear guidelines for use of synthetic data in safety-critical training and evaluation.
These applications build on the paper’s core contributions: decoupled geometry for information routing (anti-forgetting), self-augmentation for drift correction (anti-drifting), scalable feed-forward 3D reconstruction robust to minor inconsistencies, hierarchical mesh extraction, and fast DMD-distilled inference for interactive workflows.
Glossary
- 3D cache: An incremental per-frame geometric memory storing depths, camera parameters, and subsampled point clouds for retrieval and correspondence. "We maintain a 3D cache"
- 3D Gaussian Splatting (3DGS): A real-time 3D representation and rendering method that models scenes as collections of anisotropic Gaussians. "We employ a feed-forward 3D Gaussian Splatting (3DGS) pipeline"
- 3D Gaussians: Parametric Gaussian primitives used to represent scene geometry and appearance for fast rendering. "3D Gaussians and surface meshes"
- autoregressive generation: A sequential generation process where each step conditions on previously generated outputs, prone to error accumulation. "Meanwhile, autoregressive generation accumulates small synthesis errors over time"
- canonical coordinate map: A spatial encoding that assigns normalized coordinates to pixels, used here as geometry-only correspondence signals. "we assign a canonical coordinate map"
- canonical coordinate warping: Forward-warping canonical coordinates using depth and camera transforms to create dense cross-view correspondences. "we further establish dense correspondences via canonical coordinate warping"
- causal video VAE: A video autoencoder whose encoding of future frames depends causally on past frames, enabling efficient temporal compression. "modern causal video VAEs encode the first frame independently and temporally compress subsequent frames."
- classifier-free guidance: A sampling technique that trades off conditional and unconditional scores to steer diffusion outputs without an explicit classifier. "We also distill the classifier-free guidance into the student"
- DiT (Diffusion Transformer): A transformer architecture trained to predict diffusion velocities or noise in latent/video diffusion models. "Our method builds upon DiT-based latent video diffusion models"
- Distribution Matching Distillation (DMD): A distillation method that matches the output distribution of a teacher diffusion model with far fewer sampling steps. "using Distribution Matching Distillation (DMD)"
- feed-forward 3D reconstruction: A single-pass 3D recovery approach (no per-scene optimization) from images or videos to explicit 3D representations. "feed-forward 3D reconstruction, recovering explicit scene geometry and appearance."
- field-of-view (FOV) overlap: The area of scene coverage shared between two camera views, used to retrieve relevant history frames. "retrieve earlier frames based on field-of-view (FOV) overlap"
- flow matching: A training objective that learns a velocity field to transport noisy samples to clean data in continuous-time diffusion. "Generation is performed in this latent space via flow matching"
- forward warping: Projecting pixels (or features) from a source frame into a target view using depth and camera poses. "Depth-based warping forward-warps the most recent frame"
- FramePack: A context compression scheme that adaptively patchifies history frames by recency to extend the effective temporal window. "We adopt FramePack to compress the history context and mitigate drifting."
- generative reconstruction: Lifting synthesized multi-view videos into 3D using reconstruction models, replacing real captures. "This generative reconstruction approach combines the visual fidelity and creative capacity of video models with 3D outputs"
- hierarchical sparse grid: A multi-resolution voxel structure that allocates fine cells near observed regions and coarse cells elsewhere for efficient meshing. "we develop a hierarchical sparse grid approach for large-scale mesh extraction"
- key--value caches: Persisted transformer attention states that propagate information across long sequences for temporal coherence. "maintaining persistent latent states or key--value caches that propagate information across timesteps."
- marching cubes: An isosurface extraction algorithm that converts volumetric fields (e.g., SDFs) into polygonal meshes. "Surfaces are extracted via marching cubes"
- memory bank: An external repository of past frames/features that can be retrieved to guide current generation. "treat past frames as an external memory bank"
- OpenVDB: A sparse volumetric data structure and library used for efficient storage and processing of volumetric grids. "based on OpenVDB"
- out-of-domain generalization: Evaluating or performing on data distributions different from the training set. "for out-of-domain generalization."
- outpainting: Extending an image or video beyond its original content boundaries using generative models. "an optional text prompt to guide outpainting"
- Pl\"ucker coordinates: A 6D representation of 3D rays enabling pixel-wise camera conditioning in neural models. "using Pl\"ucker coordinates"
- Pl\"ucker ray injection: Injecting per-pixel Plücker ray features into the model to provide geometric camera guidance. "We therefore complement it with Pl\"ucker ray injection"
- point cloud: A set of 3D points representing sampled scene geometry, often derived from depth via unprojection. "a downsampled point cloud"
- reprojection error: The discrepancy between projected 3D points and observed image points, used as a 3D consistency metric. "We further report reprojection error"
- self-augmentation training: Conditioning on the model’s own noisy or partially denoised outputs during training to reduce train-test mismatch and drift. "a self-augmentation training strategy"
- self-attention: A transformer mechanism where tokens attend to each other, enabling context integration across space and time. "the self-attention layer of every transformer block."
- signed distance function: A scalar field whose value at any point is the signed distance to the nearest surface, used for meshing. "construct a signed distance function on the sparse grid"
- SLAM: Simultaneous Localization and Mapping; here, a system used to estimate camera trajectories and depth for evaluation. "an off-the-shelf SLAM system"
- spatial forgetting: Loss of consistency when previously seen regions fall outside the model’s temporal context and are later revisited. "First, spatial forgetting: as the camera moves,"
- surface mesh: A polygonal representation of a surface extracted from volumetric or point-based data. "we further extract a surface mesh."
- temporal context window: The finite span of past frames the model can attend to during generation. "the model's finite temporal context window."
- temporal drifting: Gradual deviation in appearance or geometry across long generated sequences due to accumulated errors. "Second, temporal drifting:"
- unprojecting: Converting per-pixel depths from an image into 3D points using camera intrinsics/extrinsics. "unprojecting it into world coordinates."
- VAE (Variational Autoencoder): A neural encoder–decoder that maps data to a latent space and back, often used to compress videos/images. "a VAE encoder compresses it into a latent"
- visibility score: A metric counting target-view-visible points from a source frame, used to rank/retrieve history frames. "we compute the visibility score of each history frame."
- world-to-camera extrinsic: The rigid transformation mapping world coordinates into the camera coordinate frame. "we denote the world-to-camera extrinsic as "
Collections
Sign up for free to add this paper to one or more collections.

