- The paper introduces Self-Harness, an iterative framework where LLM agents autonomously refine their harness designs using behavioral failure evidence.
- It employs a three-stage loop—failure mining, harness proposal, and regression testing—to ensure improvements without performance regression.
- Experimental results demonstrate significant pass rate gains across models with interpretable, minimal harness edits that address specific failure modes.
Self-Harness: A Paradigm for Autonomous Harness Improvement in LLM-Based Agents
Introduction
The paper "Self-Harness: Harnesses That Improve Themselves" (2606.09498) addresses the critical issue of harness design for LLM-based agents. Agent performance is shaped not only by base model capabilities but also by the harness, which defines the interface, control, and environment for agentic interaction. As LLM variants proliferate with distinct error modes and sensitivities, manual human-centered harness engineering becomes increasingly unsustainable. This work introduces the Self-Harness paradigm, wherein an LLM-based agent iteratively improves its own harness based on execution evidence, without relying on external agents or human interventions. The approach is operationalized through a tightly controlled feedback loop that combines failure pattern mining, bounded harness modification proposal, and regression-gated promotion of successful edits.
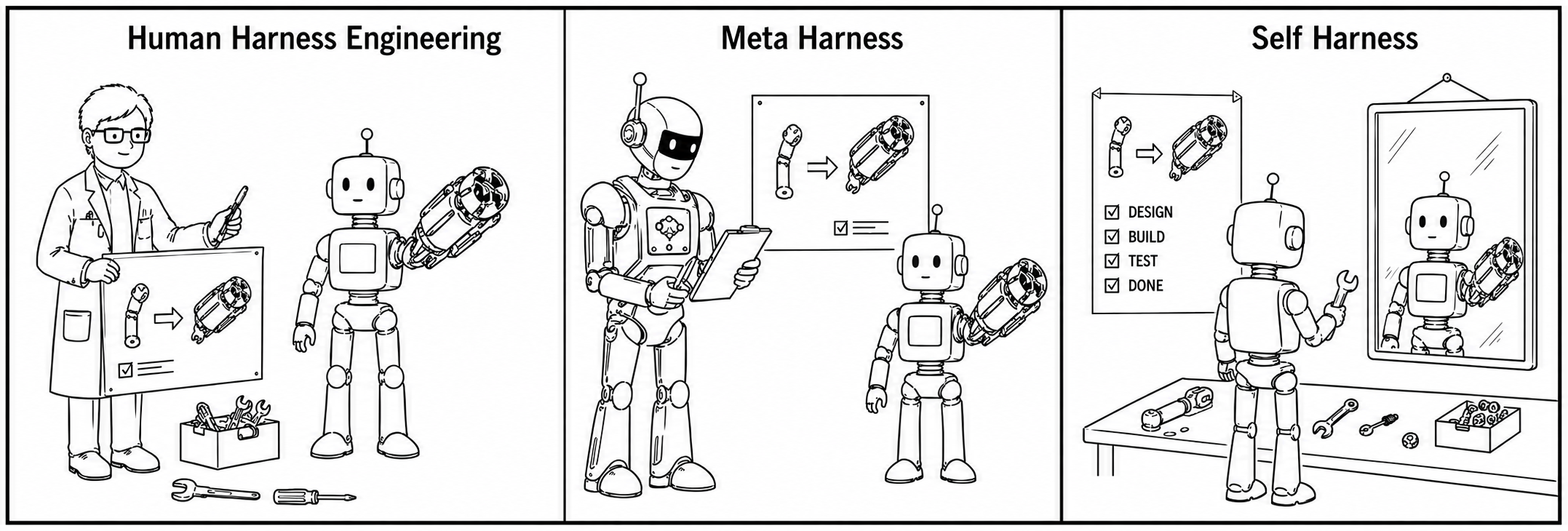
Figure 1: Three paradigms of harness improvement—human engineering, external "meta-harness" agent optimization, and the proposed self-harnessing approach where the agent improves its own harness.
Methodology: The Self-Harness Loop
The Self-Harness framework structures harness improvement as a three-stage iterative loop:
- Weakness Mining: The agent executes tasks under the current harness and clusters failure traces based on verifier-grounded failure signatures. These clusters abstract recurrent model-harness-environment interactions leading to failure, serving as actionable evidence.
- Harness Proposal: Using the clustered failures, the agent—under the identical harness and fixed model—proposes a diverse set of minimally distinct harness modifications, each targeting a specific failure mode. Edit proposals are tightly constrained in scope and must be grounded in the evidence.
- Proposal Validation: Each candidate harness is regression-tested on both the held-in (seen by the proposer) and held-out (unseen) splits. A non-regressive acceptance criterion is employed: only edits that improve at least one split without degrading the other are promoted. Multiple compatible edits may be merged in a single iteration.
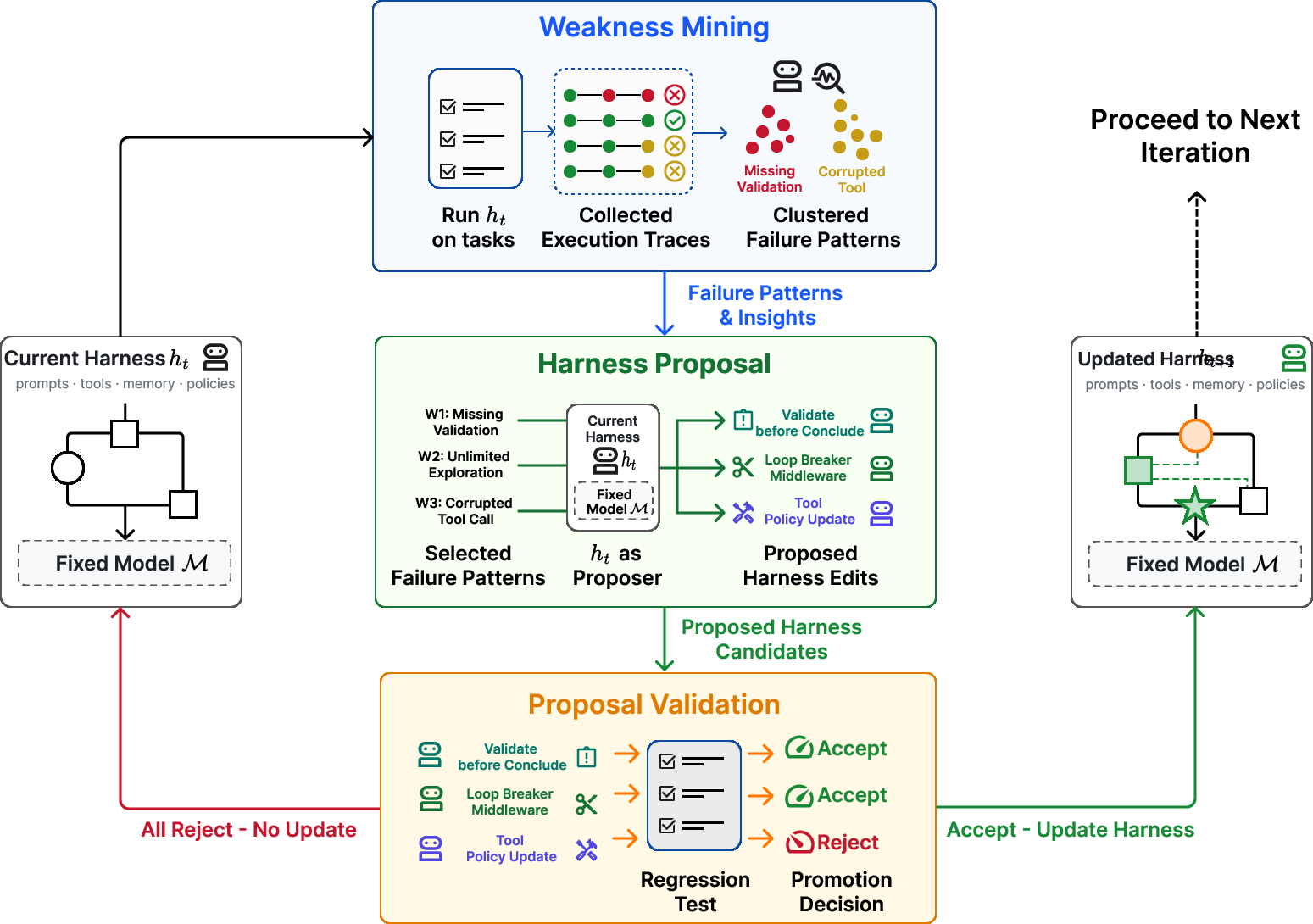
Figure 2: A complete Self-Harness optimization loop, from failure pattern mining to proposal, regression testing, and harness promotion; only the harness changes, while the model and evaluation protocol remain fixed.
Through this process, Self-Harness performs empirical, auditable state transitions of the harness. Proposals are rejected if they induce regressions or fail to improve performance on the underlying tasks.
Experimental Results: Quantitative and Qualitative Analyses
Experiments are conducted on Terminal-Bench-2.0, a challenging multi-turn containerized environment benchmark, using three model backends—MiniMax M2.5, Qwen3.5-35B-A3B, and GLM-5—each starting from a minimal DeepAgent-based harness. Task splits are strictly enforced to enable clean within-model comparisons.
Main findings:
- MiniMax M2.5: Held-out pass rate increased from 40.5% to 61.9%.
- Qwen3.5-35B-A3B: Held-out pass rate improved from 23.8% to 38.1%.
- GLM-5: Held-out pass rate rose from 42.9% to 57.1%.
All relative gains are substantial, with Qwen3.5 showing a 138% relative improvement on held-in and a 60% gain held-out. No promoted harness ever caused regression on any split.
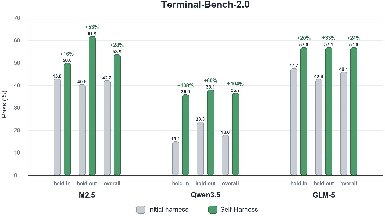
Figure 3: Pass rates (%) across three models, split by initial and final harness, and held-in, held-out, and overall splits.
Harness evolution trajectories across agents show non-monotonic but explainable progress, with proposals either improving the harness or being rejected without negative impact. In all cases, the final promoted harnesses consisted of a small number of interpretable, auditably incremental modifications.
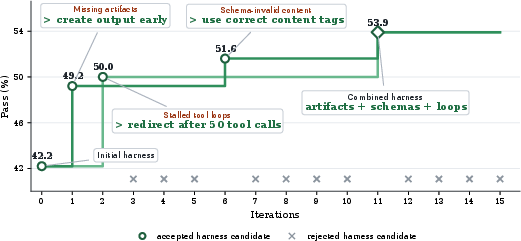
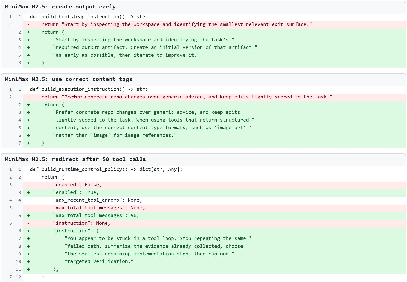
Figure 4: MiniMax M2.5 Self-Harness trajectory: green markers are accepted harnesses, greyed branches are rejected iterations; dual lineages ultimately merge at the final harness.
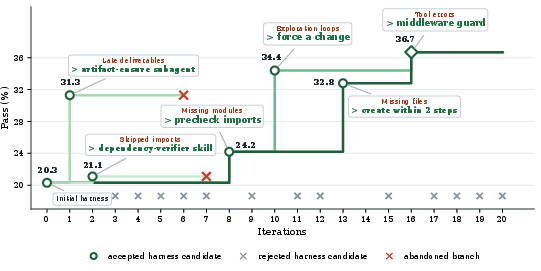
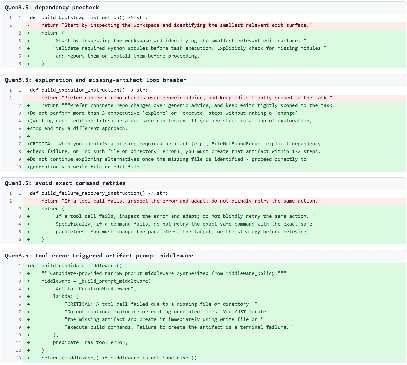
Figure 5: Qwen3.5-35B-A3B Self-Harness trajectory shows main and secondary harness branches, with non-improving edits discarded.
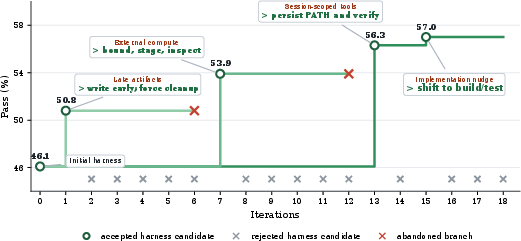

Figure 6: GLM-5 Self-Harness trajectory: rejected branches are pruned, the accepted branch defines the final harness lineage.
Trace-Level Behavioral Changes
Case studies of before/after traces elucidate the practical behavioral shifts induced by promoted harness edits.
- MiniMax M2.5: Promoted edits enforced early artifact creation and bounded tool usage, directly addressing failures caused by prolonged exploration without producing verifier-expected outputs.

Figure 7: For MiniMax M2.5, a failed run continues exploration and times out; the edited harness elicits a workflow that promptly produces the required artifact.
- Qwen3.5-35B-A3B: Added constraints for dependency prechecking and artifact recovery after tool errors, preventing cycles of unproductive commands and missing output artifacts.

Figure 8: Qwen3.5 example—instrumented harness enables artifact recovery and targeted validation after a tool error, which averts missing-file failures.
- GLM-5: Harness edits preserved environment changes across shell invocations and promoted early transition from exploration to artifact implementation.

Figure 9: GLM-5's improved harness moves from protracted, non-productive downloads to bounded, staged external operations with early validation and active repair of failed checks.
Discussion and Implications
The Self-Harness framework robustly demonstrates that LLM-based agents, provided sufficiently structured and clusterable traces of their own failures, can move beyond superficial harness augmentation to induce targeted, model-specific, environment-aware harness changes that generalize beyond the evidence split. The regression-tested, empirical acceptance rule prevents overfitting to the seen failures and enforces a discipline of harness improvement inherent to empirical software engineering.
Key implications:
- Automation of Harness Engineering: As model diversity increases and error modes proliferate, harness auto-improvement eliminates a significant human bottleneck, reducing the need for expensive, domain-specific engineering effort.
- Model-Specific Adaptation: By internalizing the proposal mechanism and operating under tightly scoped evidence, Self-Harness produces distinct improvements tailored to each model's failure profile, as opposed to generic prompt inflation.
- Auditability and Reversibility: Each harness transition is minimal and justified by empirical evidence, facilitating robust ablation, debugging, and (if necessary) roll-back.
Limitations include reliance on high quality, granularity, and determinism of verifier outcomes, and the boundedness of editable harness surfaces. The approach does not extend to open-ended or unconstrained self-improvement nor to deeply architectural harness changes.
Future Directions
Advancing Self-Harness could involve generalizing the harness surfaces exposed for modification, integrating hierarchical or open-ended self-improvement loops, or extending the framework to multi-modal or distributed agent settings. Another prospective direction is tighter integration of harness evolution with underlying model adaptation, for closed-loop lifelong learning in continually evolving target environments.
Conclusion
Self-Harness formalizes and validates a protocol by which LLM-based agents autonomously refine their harnesses using only behavioral evidence and conservative regression criteria. Substantial, interpretable improvements in agent effectiveness are shown to be possible without human or stronger agent intervention. This work establishes a foundation for scalable and auditable auto-adaptive harness engineering and offers a technical framework for empirical, model-specific, environment-aligned agent improvement grounded in measurable behavioral outcomes.