- The paper introduces a systematic approach that frames harness adaptation as a symbolic RL problem for co-evolving agent harness configurations and models.
- It decomposes the agent harness into type-safe, composable processors to enable targeted, per-task optimization and variant isolation.
- Empirical evaluations across diverse benchmarks demonstrate significant performance improvements—with gains up to 44% and robust mitigation of RL pathologies.
HarnessX: Adaptive, Compositional, and Evolvable Agent Harnesses
Introduction and Motivation
The capacity of LLM agents is deeply contingent on not only model architecture or pretraining, but also on the harness—the runtime system integrating prompts, tools, memory modules, and control flow that mediates agentic interaction with tasks and environments. Historically, harnesses have been handcrafted artifacts: bespoke, monolithic, and essentially static for a given model-task pairing. This coupling is brittle: new domains, models, or emergent task behaviors demand labor-intensive re-engineering, and the extensive collection of execution traces is rarely leveraged for harness improvement.
"HarnessX: A Composable, Adaptive, and Evolvable Agent Harness Foundry" (2606.14249) develops a systematic approach to agent harness engineering. The key insights are (i) formulating the harness as a composable, type-safe, independently evolvable object, (ii) treating harness adaptation as a formal RL problem in symbolic space, and (iii) demonstrating that harness and model should be co-evolved to overcome their respective optimization ceilings.
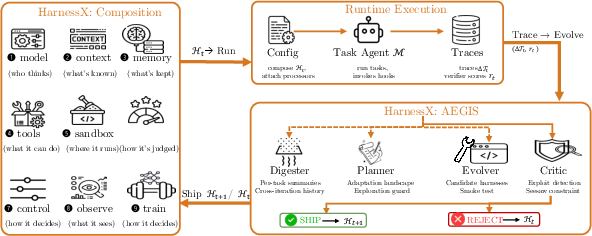
Figure 1: The AEGIS evolution loop. A single meta-agent M drives the Digester, Planner, Evolver, and Critic stages, evolving the harness based on full trace feedback and deterministic safety gates.
HarnessX formalizes the harness H as a pair: the model configuration M and the harness configuration C. The harness configuration is further decomposed as a typed collection of processors (atomic, composable modules) attached to well-defined hooks in the agent computation lifecycle. A substitution algebra supports type- and hook-safe insertion, replacement, and removal. This design enables per-task configuration and exposes the scaffolding's full behavioral surface for systematic manipulation.
Behaviorally, the harness is dissected along nine axes: model selection, context assembly, memory management, tool ecosystem, execution environment, evaluation/reward, control/safety, observability, and a training bridge connecting trajectories to RL signals. Each processor's composition is constrained by type and hook contracts, ensuring edit locality for safe evolution and enabling variant isolation: distinct clusters of tasks can be assigned distinct harness variants, preserving gains without cross-task regressions.
Harness Adaptation as Symbolic Reinforcement Learning
HarnessX introduces AEGIS, a meta-agent-driven adaptation engine that operationalizes harness evolution as RL on symbolic artifacts rather than model parameters. The correspondence is as follows:
- States: harness configurations H
- Actions: typed harness edits (code, prompt, tool, config)
- Transitions: harness modification and batch execution
- Rewards: Verifier-evaluated scores aggregated from execution traces
- Feedback: Full, structured execution traces—not scalars—are available
- Policy: An LLM meta-agent orchestrates a four-stage pipeline (Digester, Planner, Evolver, Critic)
AEGIS's architecture is explicitly designed to manage RL pathologies shown to arise in symbolic optimization:
- Reward hacking: Edits that exploit superficial verifier weaknesses (e.g., smuggling benchmark answers)
- Catastrophic forgetting: Edits that improve a subset of tasks while silently regressing others, due to shared harness state
- Under-exploration: Meticulous or local prompt edits that ignore larger, structural action space edits (e.g., tool addition, processor re-architecture)
Pathology mitigation is handled through exclusivity and gating: the deterministic gate enforces non-regression (the "seesaw constraint"), Critic stages check code and manifest-level attributions, and variant isolation enables mutually incompatible behaviors to co-exist stably.
Harness-Model Co-Evolution
HarnessX closes the optimization loop by interleaving harness adaptation with on-policy model training, both reading from a unified replay buffer containing full execution traces and verifier scores. Model training leverages Group Relative Policy Optimization (GRPO), which groups trajectories by task identity (but not harness version), internalizing strategies learned in prior harness versions, and enabling transfer of harness-induced policies. This mechanism is formally off-policy but uses cached log-probabilities to compute policy gradients safely.
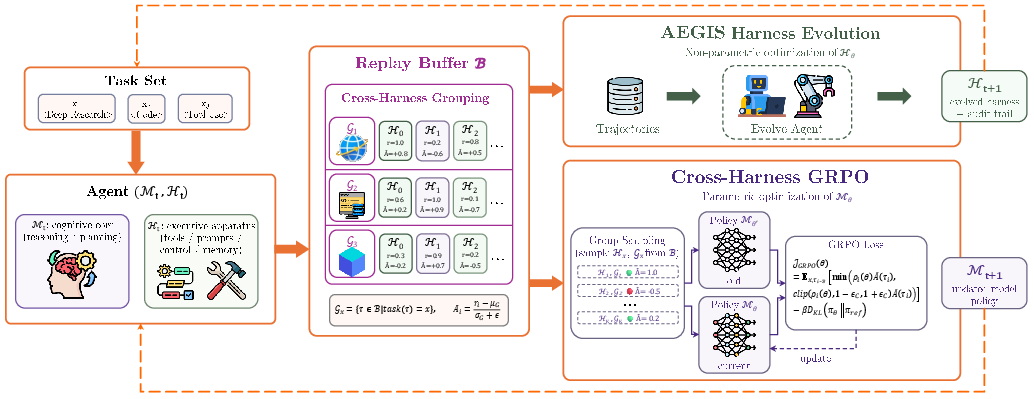
Figure 2: The harness-model co-evolution loop. The agent executes tasks; the buffer accumulates traces; both harness and model are updated in response, sharing exploration and feedback.
Empirical Evaluation: Benchmarks and Key Results
HarnessX is evaluated on five challenging agentic benchmarks:
- GAIA: Multi-hop retrieval (103 tasks)
- ALFWorld: Embodied planning (134 tasks)
- WebShop: Simulated e-commerce search (100 sessions)
- τ3-Bench: Multi-turn dialogue in three real-world domains
- SWE-bench Verified: Software bug fixing (55 tasks)
Task agents span three model families (Sonnet 4.6, GPT-5.4, Qwen3.5-9B). Static-harness and single-stage baselines are established for all settings.
Strong, quantitive results are reported:
- Harness evolution delivers absolute gains averaging +14.5% (up to +44%) across 15 model-benchmark settings
- Inverse-scaling: Weaker models profit most from harness evolution (e.g., Qwen3.5-9B on ALFWorld: 53% to 97%, +44%)
- Joint co-evolution (harness + GRPO model training) consistently yields an additional +4.7% over harness-only adaptation, breaking plateaus due to model or harness individually saturating
- Variant isolation (multiple harnesses per task cluster) prevents catastrophic forgetting and stabilizes gains where heterogeneous tasks otherwise cause regression
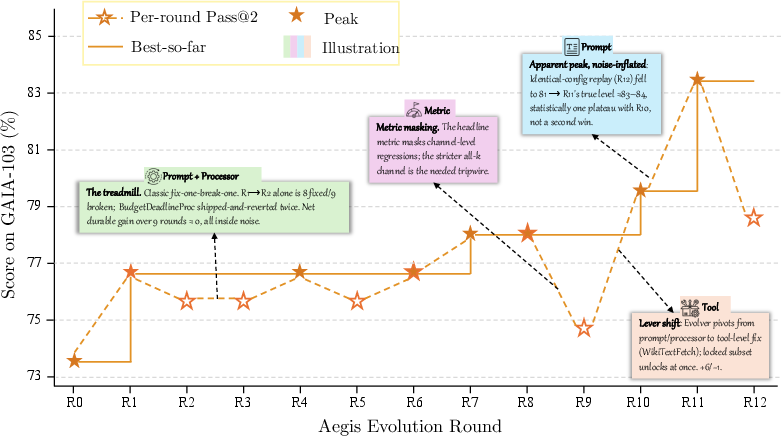
Figure 3: Evolution trajectories (pass@2 success rate vs. evolution round) across model-benchmark pairs, demonstrating consistent, often substantial, improvement over static baselines.
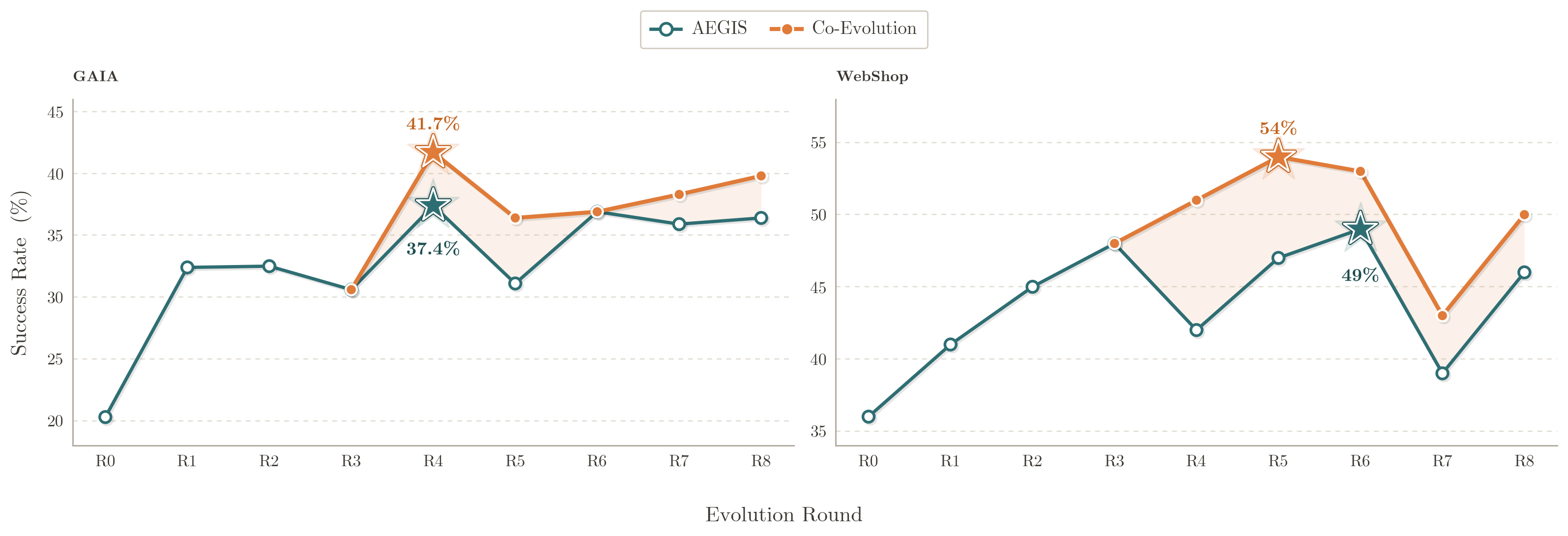
Figure 4: Co-evolution outperforms harness-only adaptation on both GAIA and WebShop tasks; gains are sustained through later rounds.
Analysis of Evolution Dynamics and Failure Clusters
Detailed per-benchmark and per-edit analyses show evolution is driven by failures in search efficiency, multi-hop reasoning, mechanical retrieval, control flow, and tool utilization. The selection and effectiveness of prompt, processor, tool, and config bucket edits vary with model strength and task characteristics.

Figure 5: Empirical examples of RL pathologies—reward hacking, catastrophic forgetting, under-exploration—surfaced and mitigated by the AEGIS loop, confirming the need for the operational mirror and isolation.
Implications, Practical and Theoretical
HarnessX's findings have significant implications:
- For agentic AI, model scaling is insufficient without continual, compositional, and resilient improvement of the runtime harness interface with the environment.
- Symbolic optimization over harness structure is subject to RL pathologies traditionally associated with parameter-space RL, highlighting the need for isolation, explicit attribution, and deterministic gatekeeping.
- Harness evolution is most impactful on weaker task models—efforts to improve model performance up to a point should be matched with systematic harness evolution.
- Trace richness is critical—the sophistication of harness evolution is limited by the information density and observability of feedback channels.
Theoretically, the operational mirror between RL and symbolic evolution provides a powerful framework for analysis and design of future agentic systems. However, limitations remain: generalization to unseen tasks, extension to continuous action spaces, automation of meta-agent roles with open-weight LLMs, and deployment in multi-organizational workflows all require further research.
Future Directions
Several promising avenues emerge:
- Automating or distilling the meta-agent LLM's multi-step, multi-file reasoning with self-improving open models
- Extending typed harness composition to high-dimensional continuous control (robotics, vision agents)
- Robustly bridging agent harness adaptation across distribution shifts using richer or adversarial trace feedback
- Developing benchmarks explicitly constructed to challenge and advance harness compositionality and evolution procedures
Conclusion
HarnessX establishes that the harness is a first-class, evolvable object in agentic RL. Its compositional abstraction, adaptation via trace-driven RL in symbolic space, and closure of the model-harness improvement loop yield consistent, significant performance gains across a spectrum of challenging tasks. These results underscore that agentic progress is not strictly a matter of scaling model parameters, but of structured, systematic engineering of the agent’s runtime environment. HarnessX sets a technical benchmark for subsequent work targeting compositional, self-adapting, and empirically grounded agentic systems (2606.14249).

