SIA: Self Improving AI with Harness & Weight Updates
Abstract: Humans are the bottleneck in building and improving AI. Both the models and the agents that wrap them are written, tuned, and corrected by people. The long-horizon goal of an AI that can figure out how to improve itself remains open. Two largely disjoint research lines attack this bottleneck. The harness-update school has a meta-agent rewrite the scaffold of a task-specific agent (its tools, prompts, retry logic, and search procedure) while the model weights are held fixed. The test-time training school uses hand-written RL pipelines to update the model's own weights on task feedback while the harness is held fixed. These two silos operate in isolation. We propose SIA, a self-improving loop in which a language-model agent (the Feedback-Agent) updates both the harness and the weights of a task-specific agent. We evaluate across three contrasting domains: Chinese legal charge classification, low-level GPU kernel optimisation, and single-cell RNA denoising. Combining both levers outperforms scaffold iteration alone on all three benchmarks. The gains are 56.6% on LawBench, 91.9% runtime reduction on GPU kernels, and 502% on denoising over the initial baseline. Harness updates make the model agentic, shaping how it searches and acts, while weight updates build the domain intuition that no prompt or scaffold can instil.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Easy-to-Understand Summary of the Paper
What is this paper about?
This paper is about building an AI system that can improve itself with less help from humans. Instead of people constantly rewriting the AI’s instructions or retraining the AI’s “brain,” the system—called SIA—uses an on-board “coach” to decide how to get better next: by fixing its setup and tools (the “harness”) or by updating the AI’s own skills (its model “weights”).
What questions did the researchers try to answer?
- Question 1: If we only improve the AI’s setup and tools (the harness), how far can we get? And if we also let the AI update its own skills (its weights), do we get better results than harness fixes alone?
- Question 2: What kinds of improvements come from harness fixes versus weight updates? In other words, what does each type of change actually do?
How the system works (in simple terms)
Think of the AI as a student taking tests, with two ways to improve:
- Harness updates: This is like changing the student’s study routine, notes, and test-taking strategy—better instructions, smarter retry rules, clearer ways to use tools, and better ways to check answers.
- Weight updates: This is like the student actually practicing and learning new skills, so they understand the material more deeply. In AI terms, that means updating the model’s internal parameters (its “weights”) so it gets better from experience.
SIA has three main parts, each like a different role:
- Meta-Agent (the “architect”): Builds the first version of the study plan and tools for the task.
- Task-Specific Agent (the “student”): Tries to solve the task using the current plan and skills.
- Feedback-Agent (the “coach”): Watches what happened, spots mistakes, and decides what to do next—either improve the harness (study plan/tools) or train the model (skills).
Some key ideas explained simply:
- Verifier: An automatic checker that tells the AI if its answer is right or wrong (like a grading script).
- Trajectory: A play-by-play log of everything the AI did—its prompts, tool uses, code runs, and answers.
- Weights: The AI’s internal “knobs” that determine how it thinks and writes. Updating weights = learning new patterns.
- LoRA: A lightweight way to update a big model by adding small “adapters,” kind of like clip-on upgrades instead of rebuilding the whole model.
- Reinforcement learning (RL): Learning by doing and getting feedback from the verifier. Good outcomes push the model toward better behavior next time.
The improvement loop repeats:
- Run the task and collect the full log.
- The coach analyzes what went wrong and what helped.
- The coach picks one of two actions: improve the harness (tools/rules) or train the weights (skills).
- Repeat until the time/step budget is used up.
What did they test this on?
The team tried SIA on three very different tasks to see if it works broadly:
- Chinese legal charge classification: Given a case summary, pick the correct criminal charge from 191 options.
- GPU kernel optimization: Write faster GPU code (CUDA) for a specific operation (TriMul) on powerful H100 hardware.
- Single-cell RNA denoising: Clean up noisy biological data so gene expression signals are clearer.
Each task has a strict verifier:
- Law: Was the legal charge correct?
- GPU: How fast did the code run?
- Biology: Did the cleaned data match the ground truth better?
Main results (and why they matter)
Across all three tasks, updating both the harness and the weights beat harness-only improvements.
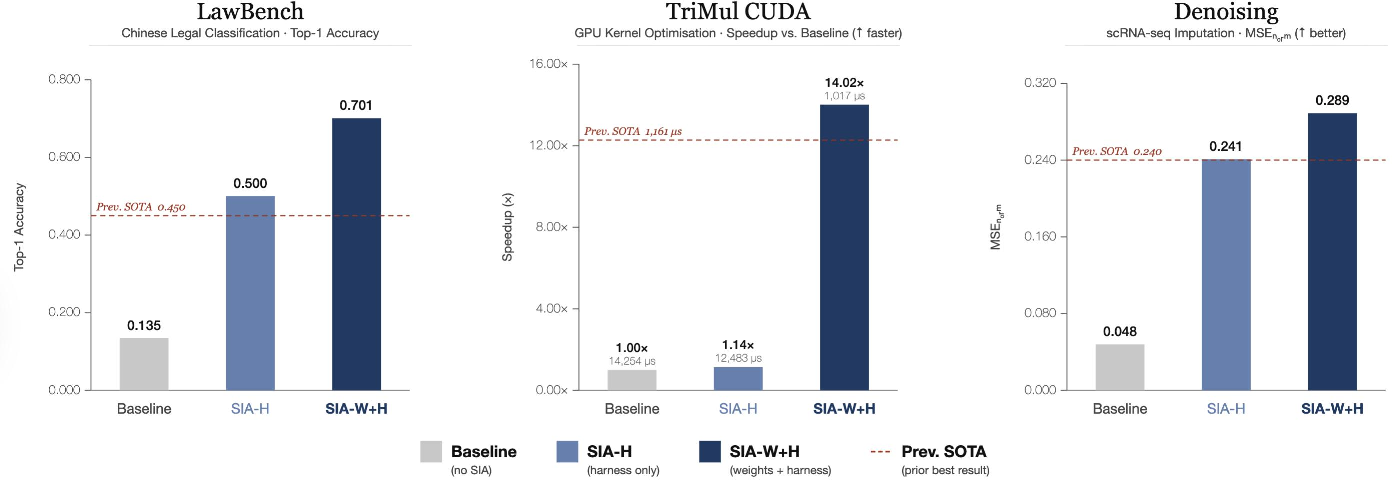
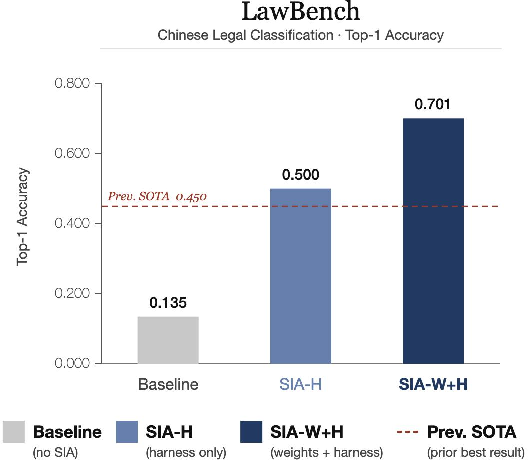
- Law (191-class classification):
- Harness-only improved accuracy a lot, but then stalled.
- Adding weight updates pushed accuracy much higher, reaching 70.1% top-1 accuracy.
- Why it matters: The model developed deeper “legal sense” that isn’t just about better instructions—it's genuine learning of fine distinctions.
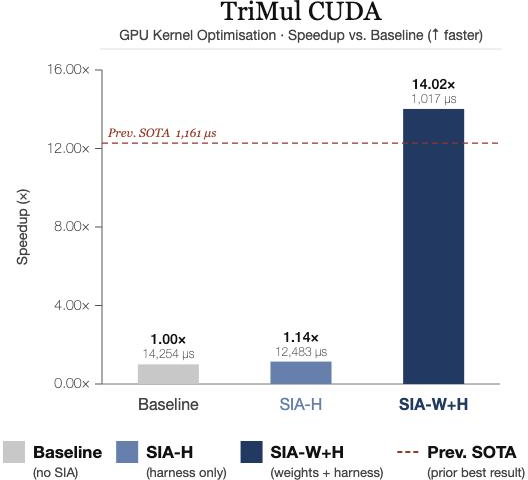
- GPU kernel optimization (TriMul on H100):
- Harness-only brought small speedups by improving the build/run setup.
- With weight updates, the model learned hardware-savvy coding patterns and cut runtime by 91.9% vs the harness-only best, achieving a 14.02× speedup over the original baseline.
- Why it matters: The model picked up specialized performance tricks that are hard to encode in prompts or scripts.
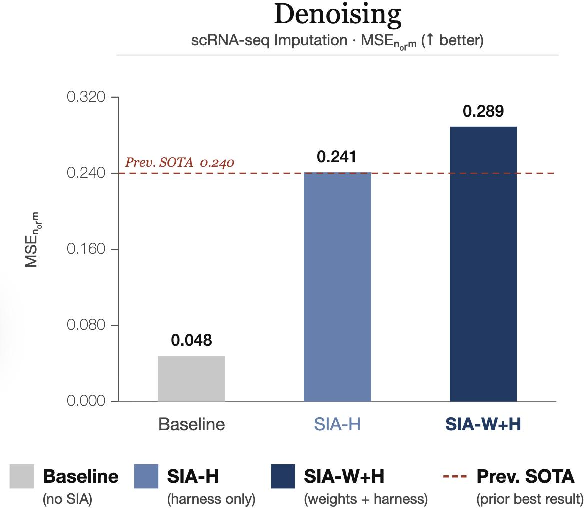
- Single-cell RNA denoising:
- Harness-only tuning reached a strong baseline (around the previous best).
- Weight updates then found a simple but powerful new step (rounding and clipping values to biologically valid counts), boosting performance further (20% over harness-only and about +502% over the very first baseline).
- Why it matters: The model discovered a sensible domain rule that the harness never proposed, showing real “internalized” domain insight.
Overall takeaway:
- Harness updates make the AI better at organizing how it works—cleaner tools, smarter retries, and better result parsing.
- Weight updates make the AI smarter—learning domain-specific patterns that fixed instructions alone can’t provide.
- Using both together gives the best results.
What could this change in the future?
- Fewer bottlenecks: Today, people spend a lot of time tweaking AI prompts, tools, and training pipelines. SIA shows a path where the AI can do much of that itself.
- Works across fields: From law to high-performance computing to biology, the same self-improving loop helped—suggesting this approach is general.
- Smarter, safer loops: Because the system uses a verifier, it learns from clear feedback. But there’s a caution: if the AI overfits to one checker, it might “game” the test. Future work needs to make verifiers and evaluation more robust.
In short: This paper shows that letting an AI improve both its setup and its own skills—guided by a smart coach and a clear checker—can make it learn faster, perform better, and need less handholding from humans.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable follow‑up work.
- Lack of a weights-only baseline: no evaluation of “fixed harness + test‑time weight updates” under identical budgets to isolate the pure contribution of weight updates versus scaffold edits.
- Ambiguous data usage for RL updates: unclear whether weight updates used the training split, the test split, or both (especially for LawBench); using the test verifier for adaptation risks test leakage and invalidates fair generalization claims.
- No statistical rigor reporting: results are presented without confidence intervals, variance across seeds, or multiple independent runs to establish robustness and significance.
- Compute and efficiency not specified: missing GPU hours, number of RL steps, rollout counts, G (group size) for GRPO, tokens processed, and wall-clock per generation; impedes cost–benefit assessment and reproducibility.
- Reproducibility constraints: reliance on internal, unreleased models (gpt‑oss‑120b; Claude Sonnet 4.6) and private infrastructure (Modal) without released code/configs/trajectories/checkpoints.
- Incomplete training details: absent hyperparameters for each RL algorithm (learning rates, batch sizes, KL weights, PPO clip ε, GRPO group size, entropic temperature schedule, LoRA optimizer/learning rate/schedule, training steps).
- No convergence criteria or schedules: the interleaved harness/weight update policy lacks a formal stopping rule or convergence test; no comparison to staged (H-then-W) schedules or to fixed alternation cycles.
- “Plateau detection” unspecified: the rule for declaring harness progress stalled (triggering a switch to weight updates) is not defined or ablated; could bias comparisons.
- Selection policy opacity: the Feedback‑Agent’s decision-making features/thresholds for choosing among RL algorithms (PPO, GRPO, DPO, etc.) are described qualitatively but lack quantitative ablations or a learned/meta‑learned policy; reproducibility is unclear.
- No guardrails against regression: aside from occasional KL-to-base, there is no systematic rollback, canary tests, or gating to prevent capability regression or reward hacking after weight updates.
- Theoretical grounding missing: no analysis of convergence or stability of the coupled two-optimizer loop (harness+weights), despite Goodhart’s Law concerns noted in limitations; no formalization of equilibria or conditions for benign fixed points.
- Verifier dependence unresolved: all tasks use deterministic verifiers; the approach’s behavior under noisy, partial, or adversarial verifiers (or purely ordinal feedback) is not empirically tested.
- Robustness to verifier misspecification: no stress tests with perturbed/shifted verifiers to quantify overfitting or “gaming” the reward function.
- Generalization after adaptation: no evaluation on out-of-domain or out-of-distribution samples following test-time updates to assess whether learned LoRA/scaffold changes transfer beyond the adapted set.
- TriMul generality concerns: CUDA kernel improvements validated on a single fixed input shape and single GPU (H100); no checks across varied shapes, batch sizes, memory footprints, or different architectures (A100, consumer GPUs).
- Code correctness beyond speed: kernel evaluation focuses on runtime; correctness tests across edge cases, numerical stability, and long-duration runs are not documented.
- Biological metric validity: for scRNA denoising, the provenance and reliability of “ground truth” for mse_norm are not detailed; no tests on multiple datasets or alternative metrics (e.g., downstream clustering/DE analysis) to validate biological relevance.
- External classical pipeline vs. LLM learning: on LawBench, scaffold introduces TF‑IDF + LinearSVC; it’s unclear how much gain comes from non‑LLM components versus model adaptation; no ablation removing the classical re‑ranker.
- Transferability of LoRA adapters: not tested whether LoRA weights trained under one scaffold remain beneficial under scaffold changes or transfer to related tasks/datasets.
- Interaction effects unstudied: how scaffold edits post‑RL update alter the utility of previously learned weights (and vice versa) is not quantified; risk of chasing a moving target remains unmitigated.
- Sensitivity to LoRA design: no study of adapter rank, placement, and layer selection on performance and stability across tasks.
- Reward sparsity extremes: while a GRPO variant is used, there is no systematic benchmark across a spectrum of reward densities (extremely sparse/deceptive rewards) to map algorithm suitability boundaries.
- Schedule optimization: no exploration of learned or adaptive schedules for interleaving H and W steps (e.g., bandit/meta‑RL over action selection), despite being hinted as future work.
- Compute parity between levers: unclear if harness-only and weight-update phases were given comparable compute/time budgets; unequal budgets could confound the contribution analysis.
- Safety and oversight: allowing an LLM to autonomously trigger weight updates lacks a documented oversight framework (human-in-the-loop checkpoints, red‑team tests, audit logs, or safety thresholds).
- Security of code execution: sandbox guarantees (isolation, timeouts, resource quotas, filesystem/network access) are not specified; essential for safe agent‑generated code execution.
- Privacy and data governance: trajectory logging of full prompts/responses/tool calls may introduce privacy risks if tasks involve sensitive data; no mitigation or policy discussed.
- Broader‑task scalability: the approach is shown on three tasks; scaling to multi‑tool, long‑horizon, or multi‑objective settings (e.g., complex planning) is untested.
- Comparison to strong TTT baselines: missing head‑to‑head comparisons with state‑of‑the‑art test‑time training under matched budgets and identical verifiers, and with expert‑designed harness+fine‑tune pipelines.
- Checkpoint selection and early stopping: criteria for selecting the “best” RL‑adapted checkpoint (validation set, moving average reward, or verifier‑based selection) are not described; risk of cherry‑picking.
- Effect of sample‑task regularization: introduced for scaffold generation but not quantified; ablations needed to measure its impact on overfitting and generalization.
- Language/tokenization effects: for Chinese legal text, the base model’s tokenizer and pretraining coverage are not discussed; gains may be sensitive to tokenization and corpus mismatch.
- Open science commitments: absence of a plan to release code, scaffolds, trajectories, verifiers, and trained adapters prevents independent verification and downstream research.
Practical Applications
Immediate Applications
The following applications can be deployed today when tasks have a reliable verifier (deterministic grader, unit tests, or well-defined metrics), a sandboxed execution environment, and access to LoRA-based fine-tuning infrastructure.
- Self-improving legal document classifiers (e.g., charge prediction, statute mapping)
- Sectors: legal tech, gov/regulatory.
- What it does: Automatically iterates prompts/tools (scaffold) and adapts LoRA weights via GRPO/PPO using correct-label verifiers to boost accuracy on multi-class legal tasks (mirroring the LawBench setup).
- Tools/workflows/products: “LawCharge+” (domain-adapted LoRAs bundled with a scaffold for Chinese criminal charge classification); continuous-improvement loop that alternates harness edits (parsing, ranking, re-tries) with weight updates until reward stalls.
- Dependencies/assumptions: High-quality labeled datasets; deterministic grading (exact-match labels); language/domain coverage in the base model; data governance for sensitive legal documents; compute budget for on-demand RL fine-tuning.
- Auto-tuning GPU kernels and low-level systems code
- Sectors: software, HPC, semiconductors, ML infra.
- What it does: Generates/optimizes Triton/CUDA kernels with a test-and-benchmark verifier (compiles, runs unit tests, measures runtime), switching to GRPO with entropic weighting when pass rates are low to discover high-performance patterns (as shown for TriMul on H100).
- Tools/workflows/products: “KernelSmith” (CI-integrated agent that generates kernels, runs benchmarks in a sandbox, and ships improved LoRA adapters and scaffolds); performance dashboards and step budgets to control cost.
- Dependencies/assumptions: Deterministic unit tests and timing harnesses; GPU access (e.g., H100/L4) and secure sandboxes; license compliance for generated code; safeguards against overfitting to microbenchmarks.
- Bioinformatics pipeline tuner (e.g., scRNA-seq imputation, denoising, normalization)
- Sectors: healthcare, life sciences, biotech.
- What it does: Co-evolves pipeline scaffolds (hyperparameter sweeps, batching, result parsing) and LoRA weights to optimize objective metrics (e.g., mse_norm) and to discover simple-but-impactful invariants (e.g., count clipping/rounding, as in MAGIC).
- Tools/workflows/products: “BioTune” (self-improving orchestration for common tools like MAGIC, Scanpy, Seurat); LoRA adapters for specific assays/datasets with tracked provenance.
- Dependencies/assumptions: Ground truth or trusted proxy metrics; reproducible verifiers; IRB/compliance for biomedical data; careful validation to avoid Goodharting to a single dataset.
- CI/CD code-generation agent hardening with unit-test verifiers
- Sectors: software engineering, DevOps.
- What it does: Uses unit tests as deterministic reward to iteratively improve the code-generation scaffold (tools, retries, parsing) and then adapt weights (e.g., GRPO or PPO with KL-to-base) to increase pass@k and reduce flaky behavior.
- Tools/workflows/products: “AgentCI” plugin for GitHub/GitLab that runs a step-budgeted SIA loop on PRs; gated promotion of new LoRA/scaffold only if pass rates and latency budgets improve.
- Dependencies/assumptions: Comprehensive unit tests; hermetic sandboxes; audit logs for traceability; rollback mechanisms; cost caps for RL loops.
- Self-improving information extraction for documents (e.g., invoices, KYC, claims)
- Sectors: finance/fintech, insurance, back-office automation.
- What it does: Iteratively refines extraction scaffolds (schema, validators, parsing) and then fine-tunes LoRA weights using exact-match field verifiers to improve field-level precision/recall.
- Tools/workflows/products: “DocExtract+” with a library of validators (regex, checksum, cross-field consistency) and dataset-specific LoRA adapters; retraining triggered by error spikes.
- Dependencies/assumptions: Labeled datasets and deterministic field validators; PII handling and privacy; stability tests to avoid regressions on rare formats.
- RAG agent optimization with exact-answer or unit-test verifiers
- Sectors: enterprise software, knowledge management, customer support.
- What it does: Improves retrieval+reasoning scaffolds (tool selection, reranking, caching) and then adapts LoRA weights against a question set with exact-match answers or rule-based verifiers (e.g., equations checked by a solver).
- Tools/workflows/products: “Self-Improving RAG Harness” that tracks per-query failure modes, applies harness edits first, and switches to GRPO once gains stall; adapter promotion per domain (policy docs, SOPs).
- Dependencies/assumptions: High-quality QA sets or deterministic graders (numeric/structured answers); content access controls; monitoring for memorization/leakage.
- AIOps/runbook automation with simulation-based verifiers
- Sectors: IT operations, SRE/DevOps.
- What it does: Encodes runbooks as tools and validates remediation suggestions in a simulator (e.g., chaos testing, sandboxed clusters). Harness iterations improve tool orchestration; RL weight updates bias policy toward reliable fixes.
- Tools/workflows/products: “AgentOps” that proposes patches/commands, validates in staging, and escalates with signed-off LoRA/scaffold changes.
- Dependencies/assumptions: High-fidelity simulators; blast-radius control; strong guardrails to prevent production drift; deterministic success criteria.
- Structured data cleaning and validation agents
- Sectors: data engineering, analytics.
- What it does: Uses rule- and constraint-based verifiers (range checks, uniqueness, referential integrity) to improve cleaning pipelines (harness) and then learn domain-specific fixes (weights) that satisfy constraints.
- Tools/workflows/products: “CleanLoop” for schema-driven data pipelines; per-dataset LoRA adapters capturing recurring error patterns.
- Dependencies/assumptions: Clear, enforceable data constraints; versioned datasets; drift detection for re-training triggers.
- Security-focused code repair with test/fuzz verifiers
- Sectors: application security, DevSecOps.
- What it does: Harness edits to integrate fuzzers and SAST; RL weight updates guided by pass/fail on exploit test suites to improve patch quality and reduce regressions.
- Tools/workflows/products: “PatchFix” that proposes minimal diffs validated by exploit harnesses; adapter store per language/framework.
- Dependencies/assumptions: Reliable exploit/test suites; secure sandboxes; human review for high-severity changes.
Long-Term Applications
These opportunities require further research, scaling, or ecosystem development (e.g., robust preference modeling, broader verifier coverage, safety frameworks).
- General-purpose self-improving assistants for open-ended tasks
- Sectors: cross-sector AI copilots (productivity, analysis, content).
- What it could do: Extend SIA to tasks without deterministic verifiers using preference-based objectives (DPO, human rankings) and uncertainty-aware reward modeling; meta-learn when to update scaffold vs. weights.
- Dependencies/assumptions: Reliable preference elicitation; guardrails against reward hacking and capability regression; online evaluation frameworks.
- Regulatory-grade self-improvement with auditability and compliance gates
- Sectors: policy/public sector, healthcare, finance.
- What it could do: Bake SIA into “regulatory sandboxes” that enforce step budgets, immutable logs, approval workflows, red-team tests, and rollback; use formal verifiers or property checks where possible.
- Dependencies/assumptions: Standards for dual-optimizer audit trails; certifiable verifiers; role-based approval flows; privacy-preserving training.
- Clinical decision-support adaptation in real-world settings
- Sectors: healthcare.
- What it could do: Co-evolve clinical pipelines (harness) and domain LoRAs using proxy verifiers (simulation, retrospective outcomes) and, eventually, prospective trials; encode clinical invariants as post-processing learned through RL.
- Dependencies/assumptions: Rigorous validation, bias monitoring, and regulatory approval; access to de-identified data; conservative KL constraints to prevent regression.
- Robotics and autonomy with simulator-to-real transfer
- Sectors: robotics, manufacturing, logistics.
- What it could do: Use high-fidelity simulators as verifiers; harness evolves tool-use and planning, weights adapt to environment dynamics with PPO/GAE; later, deploy with safety monitors in the real world.
- Dependencies/assumptions: Accurate simulators; sim2real transfer techniques; safety envelopes and intervention policies; sample-efficient training.
- Financial modeling and risk systems with Goodhart resistance
- Sectors: finance, insurance.
- What it could do: Co-evolve forecasting scaffolds and domain LoRAs using backtesting/cross-validation verifiers augmented with causal or stress-test checks to avoid overfitting.
- Dependencies/assumptions: Verifier designs that penalize backtest leakage; robust OOD evaluation; compliance oversight.
- Energy and industrial optimization via digital twins
- Sectors: energy, manufacturing, supply chain.
- What it could do: Optimize schedules, dispatch, and control policies using digital twins as verifiers; harness orchestrates simulations, weights adapt to non-linear dynamics with entropic-weighted GRPO/PPO.
- Dependencies/assumptions: Trustworthy simulators; constraint-aware reward shaping; safe deployment gating.
- Meta-RL for action selection (when to edit harness vs. weights)
- Sectors: AI infrastructure, MLOps.
- What it could do: Learn a policy over SIA’s “next action” (FB:H vs. FB:W and algorithm choice), conditioned on reward density, pass-rate, and cost, to maximize improvement per compute-dollar.
- Dependencies/assumptions: Large-scale ablations across tasks; credit assignment for decision quality; generalization across domains.
- Adapter marketplaces and multi-tenant “LoRA slots”
- Sectors: model platforms, SaaS.
- What it could do: Host vetted, task-specific LoRA adapters co-evolved with harnesses; tenants auto-provision adapters under SIA with safe KL constraints and promotion gates.
- Dependencies/assumptions: Standardized adapter interfaces; IP/licensing controls; automated regression tests and security scans.
- Goodhart-resilient verifier design and adversarial evaluation
- Sectors: academia, standards bodies.
- What it could do: Develop verifier ensembles, adversarial tests, and perturbation audits tailored to two-optimizer settings (co-evolving scaffold and weights) to ensure out-of-distribution robustness.
- Dependencies/assumptions: Community benchmarks; shared logging schemas; reproducible evaluation harnesses.
- Personalized agents that adapt to user preferences safely
- Sectors: consumer productivity, education.
- What it could do: Combine scaffold edits (tools, style prompts) with LoRA updates from preference signals (DPO/implicit rankings) to align with user style while retaining general competence.
- Dependencies/assumptions: Privacy-preserving on-device or federated training; robust preference collection; safeguards against undesirable drift.
- Cross-domain self-improvement across heterogeneous tasks
- Sectors: general AI research.
- What it could do: Train a unified Feedback-Agent that learns transferable heuristics for when/how to update across law, systems, biology, etc., leveraging trajectory features and verifier properties.
- Dependencies/assumptions: Large, diverse task suites with standardized verifiers; meta-learning infrastructure; careful monitoring for negative transfer.
Notes on Feasibility and Assumptions
- SIA excels where you can define a strong verifier and run sandboxes safely; tasks with fuzzy or subjective reward need preference/ranking methods and stricter safety gates.
- Compute and latency matter: GRPO and PPO are effective but can be costly; step budgets and promotion gates are critical for production use.
- Risk of Goodharting is amplified by co-evolution (harness and weights): rotate verifiers, add perturbation tests, and maintain a frozen reference policy with KL constraints and regression checks.
- Governance is essential for sensitive sectors: immutable logs, human approvals, and strict data-handling policies should wrap the self-improvement loop.
Glossary
- AlphaEvolve TriMul: A benchmark task focusing on optimizing the TriMul operation for protein structure models. Example: "AlphaEvolve TriMul: CUDA Kernel Optimisation for Protein Structure Prediction."
- CUDA kernel: A GPU program (function) executed in parallel on NVIDIA GPUs. Example: "write a custom CUDA kernel for this operation"
- DPO (Direct Preference Optimization): A preference-based training method that optimizes policy probabilities directly from ranked pairs without a reward model. Example: "DPO. Selected when: the verifier can rank outputs but not score them absolutely, tasks with soft quality criteria where ordinal signal is reliable but cardinal reward is not."
- Entropic advantage weighting: A weighting scheme that redistributes gradient mass toward high-reward rollouts using a softmax with adaptive temperature. Example: "Entropic advantage weighting. Selected when: the reward histogram is heavily right-skewed"
- Entropic-utility objective: A test-time training objective that biases learning toward high-utility (high-reward) outputs via entropy-shaped weighting. Example: "Trains weights at test time using rollouts under an entropic-utility objective"
- Evoformer: A core AlphaFold2 module that updates pairwise residue features in protein structure prediction. Example: "AlphaFold2's Evoformer module"
- Feedback-Agent: The controller LLM that analyzes trajectories and decides whether to update the harness or the model weights. Example: "a language-model agent (the Feedback-Agent) updates both the harness and the weights of a task-specific agent."
- Generalized Advantage Estimation (GAE): A low-variance estimator for advantages used with policy gradient methods. Example: "PPO with GAE. Selected when: step-level rewards are dense and training stability is the binding constraint"
- GRPO (Group-Relative Policy Optimization): A policy-gradient method that normalizes advantages within rollout groups, eliminating the need for a value function. Example: "GRPO: group-relative advantage estimation across rollout batches, with no learned value function required."
- H100 GPU: NVIDIA’s high-end data center GPU architecture used for training and kernel benchmarks. Example: "on an H100 GPU"
- Harness (scaffold): The fixed, non-weight code and prompts that structure an agent’s interaction with tools and tasks. Example: "We call the fixed, non-weight component of the agent the scaffold (equivalently, harness) throughout."
- k-nearest-neighbour (k-NN) graph: A graph connecting each data point to its k most similar neighbors, often used for diffusion or imputation. Example: "constructing a -nearest-neighbour graph over cells"
- KL-to-base: A KL-divergence regularization term penalizing deviation from a frozen base policy during training. Example: "REINFORCE + KL-to-base. Selected when: the reward is dense"
- LawBench: A Chinese legal charge classification benchmark with 191 classes. Example: "LawBench: 191-Class Chinese Criminal Charge Classification."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that learns low-rank adapters on top of a frozen base model. Example: "an RL-adapted set of LoRA weights (Hu et al., 2022)."
- MAGIC (Markov Affinity-based Graph Imputation of Cells): A graph-diffusion method for imputing missing gene expression in single-cell data. Example: "MAGIC (Markov Affinity-based Graph Imputation of Cells) addresses this by constructing a -nearest-neighbour graph over cells"
- Meta-Agent: An LLM that synthesizes or modifies agents (including their scaffolds) rather than solving the task directly. Example: "A meta-agent is an LLM call whose output is itself an agent."
- mse_norm: A normalized mean-squared-error metric used to evaluate denoising quality (higher is better). Example: "mse_norm (, higher = better)"
- Nash equilibrium: A fixed point of interacting optimizers where no component can improve unilaterally. Example: "The joint fixed point of this coupled system is a Nash equilibrium between two optimisers"
- PPO (Proximal Policy Optimization): A policy-gradient algorithm using a clipped surrogate objective to stabilize updates. Example: "PPO with GAE. Selected when: step-level rewards are dense and training stability is the binding constraint"
- Register pressure: The demand for limited GPU registers during kernel execution; high pressure can cause spills and slowdowns. Example: "register pressure management"
- REINFORCE: The basic Monte Carlo policy gradient algorithm using returns as advantages. Example: "REINFORCE + KL-to-base."
- Rollout: A sampled trajectory/output from the policy used for evaluation and learning. Example: "Advantages are normalised within a rollout group of size "
- scRNA-seq: Single-cell RNA sequencing, measuring gene expression at single-cell resolution. Example: "Single-cell RNA sequencing (scRNA-seq) measures gene expression"
- Shared-memory tiling: A GPU optimization technique that partitions data into tiles stored in fast shared memory to improve locality. Example: "shared-memory tiling"
- Tensor core scheduling: Strategically mapping computations to GPU tensor cores to maximize throughput. Example: "tensor core scheduling"
- Test-time training (TTT): Adapting model weights during inference using task-specific feedback. Example: "The test-time training school uses hand-written RL pipelines to update the model's own weights on task feedback while the harness is held fixed."
- Tool-dispatch logic: Code that interprets and routes tool calls produced by the model to appropriate handlers. Example: "Tool-dispatch logic. Python code that parses model tool-call outputs and routes them to handlers"
- Trajectory (execution trajectory): The complete structured log of an agent’s run, including prompts, actions, tool calls, and results. Example: "the full trajectory , the complete structured execution log from running against "
- Triangular multiplicative update (TriMul): A triangular interaction operation in Evoformer for updating pairwise residue features. Example: "The triangular multiplicative update (TriMul) is a core operation in AlphaFold2's Evoformer module"
- Trust region: A constraint region limiting policy updates to prevent destabilizing shifts. Example: "prevents the policy from leaving the trust region."
- Verifier: A deterministic function that scores or checks outputs to produce rewards for learning. Example: "The deterministic verifier the orchestrator invokes to compute the per-instance reward."
- Warp divergence: Inefficiency in GPU SIMT execution when threads in a warp follow different control paths. Example: "inducing warp divergence and cache misses"
Collections
Sign up for free to add this paper to one or more collections.