- The paper presents DistIL, which achieves monotonic policy improvement by applying a sequence-level forward cross-entropy objective for effective credit assignment.
- It overcomes the limitations of tokenwise RL updates by incorporating future-aware gradients that leverage rich, multi-step supervision signals.
- Empirical results across reasoning, code, and math tasks demonstrate DistIL’s superior stability, sample-efficiency, and performance compared to standard distillation methods.
Reinforcement Learning from Rich Feedback with Distributional DAgger
Motivation and Limitations of Standard Self-Distillation in RL
The work addresses critical deficiencies in the standard RL from verifiable rewards (RLVR) pipeline applied to LLMs for reasoning tasks. RLVR typically broadcasts sparse terminal feedback (e.g., binary correctness at the end of a sequence) uniformly across all tokens, preventing effective credit assignment. However, LLMs and related environments often provide much richer supervision signals, such as execution traces, error logs, and expert demonstrations.
Several prior approaches attempt to harness this feedback via on-policy distillation and self-distillation objectives such as reverse KL (SDPO) and Jensen-Shannon (OPSD). The authors present two core theoretical pathologies with this paradigm:
- f-divergence-based self-distillation does not ensure monotonic reward improvement: even when the privileged teacher is strictly better, the induced update can decrease the student’s expected reward, as formalized via covariance-based first-order expansions and explicit bandit counter-examples (see Proposition 1/2).
- Tokenwise (local) credit assignment is insufficient: gradients computed only at the current token fail to propagate supervision from later tokens or steps back to causally responsible early decisions, often driving learning toward suboptimal stationary points even in simple multi-step MDPs.
Distributional DAgger: Sequence-Level Forward Cross-Entropy for RL
To resolve these challenges, the authors introduce DistIL, a distributional variant of DAgger that enforces a sequence-level, future-aware credit assignment across visited prefixes through a full forward cross-entropy objective between the privileged teacher and the student:
LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]
where H×(p,q)=−Ey∼p[logq(y)] is the forward cross-entropy, and trajectories are sampled from the current student. This formulation is specifically engineered to:
- Permit both white-box and black-box (sampled) teachers, tolerating lack of access to explicit teacher probabilities.
- Enable future-aware sequence-level gradients via the full application of the reparameterization trick for autoregressive models, i.e., the gradient of LDistIL decomposes into explicit local and delayed credit terms (see Eq. 9).
DistIL’s local term directly mimics the privileged teacher’s distribution at every state, while its future-credit component properly backpropagates the cross-entropy of future states through the log-probabilities of preceding actions (i.e., properly tracks causality in decision sequences).
Theoretical Analysis: Reward Alignment, Regret, and Pass@N
DistIL is rigorously shown to enjoy multiple important theoretical properties:
- Monotonic Policy Improvement: Under a tangent-space realizability assumption and fixed visitation distribution, a natural gradient update on forward cross-entropy is guaranteed to improve expected reward towards that of the privileged teacher when the teacher's reward is higher (Proposition 3).
- No-Regret Online Imitation Bound: DistIL achieves a sublinear regret bound versus the teacher in expectation. The policy returned after n rounds is within O(n−1/4) (or O(n−1/2) for deterministic teachers) of the teacher's expected reward, with the rates determined by student-teacher support overlap (concentrability) and the teacher's variance/recoverability.
- Alignment to Teacher-Weighted Success Likelihood: The forward cross-entropy objective lower-bounds the teacher-weighted expected success log-likelihood, inherently maximizing Pass@N—the probability of producing at least one correct response in N draws (Proposition 5). This is not generally true for reverse-KL or other LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]0-divergences.
Empirical Results
Extensive experiments across science (undergraduate-level reasoning problems), code (LiveCodeBench with execution-feedback), and hard mathematical domains demonstrate:
- DistIL consistently outperforms RLVR, SDPO, OPSD, and GRPO across all settings, often substantially. For instance, gains up to 9.6 points in Avg@16 on physics/chemistry reasoning, and consistent improvements in code correctness (Best@LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]1, Maj@LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]2, Score@16) and Pass@LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]3/Avg@16 on hard mathematics.
- Superior credit assignment yields both more stable and faster learning, with Best@16 improving monotonically early in training (Figure 1). By contrast, SDPO exhibits instability and even performance collapse after continued updates. The advantage is magnified in tasks or feedback regimes where local or on-policy-only RLVR cannot propagate non-terminal or delayed reward signals.
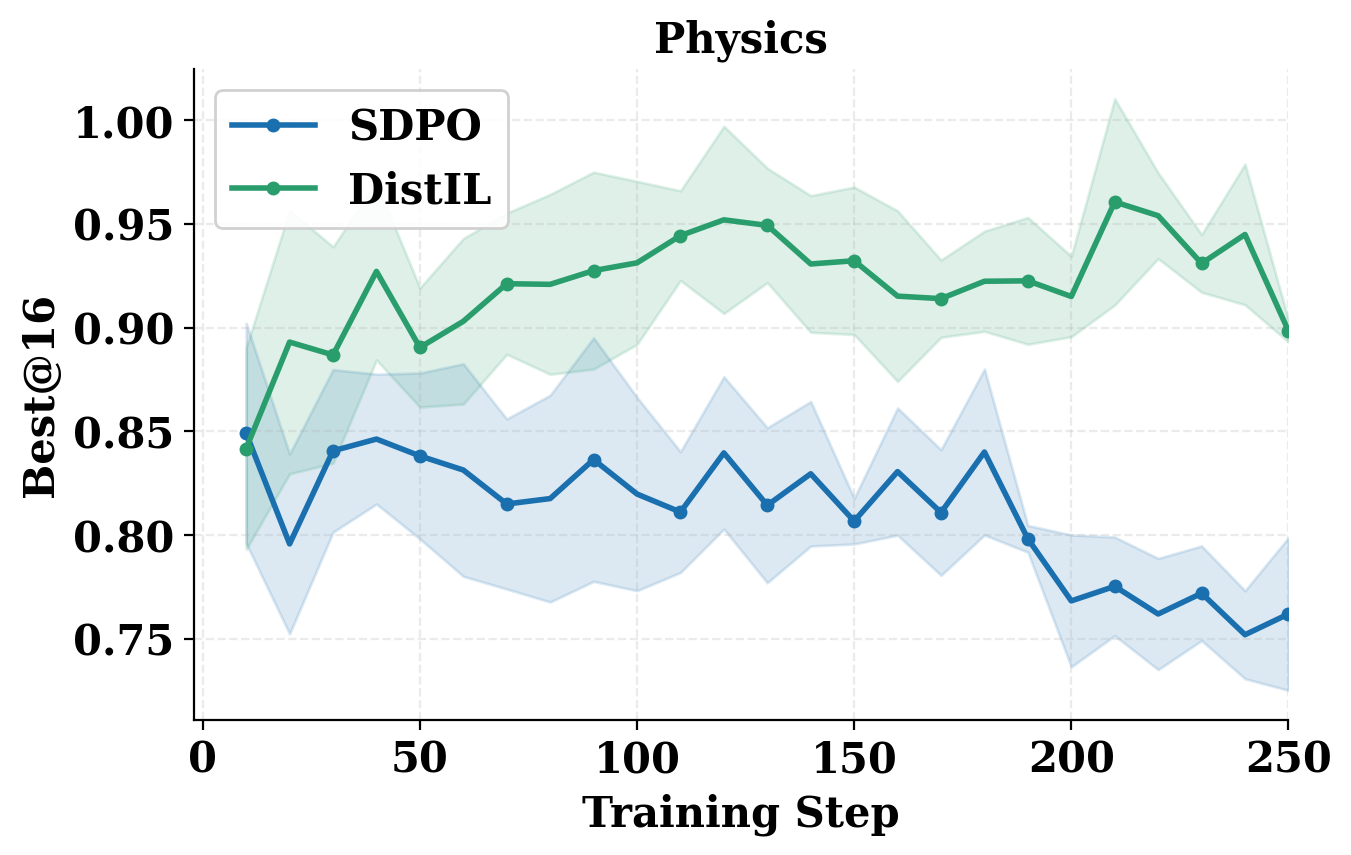
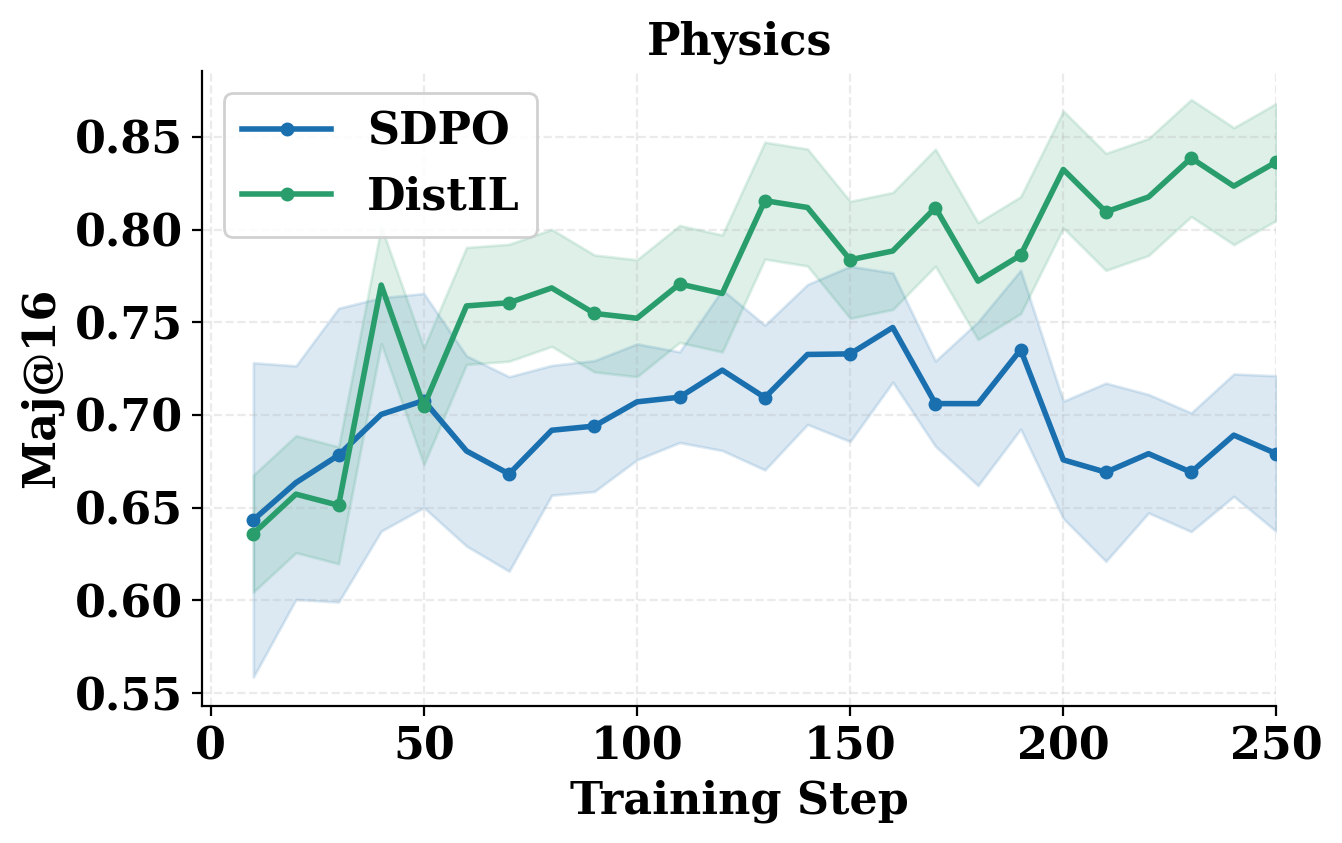
Figure 1: Validation Best@16 (top) and Maj@16 (bottom) for RL with self-distillation (SDPO) versus DistIL across science reasoning domains; DistIL shows higher, more stable performance.
On LiveCodeBench, DistIL surpasses all baselines on both strict (all tests passed) and partial (fractional) correctness metrics for various values of LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]4 (Figures 2 and 4), confirming the theoretical predictions for code synthesis with rich dynamic supervision.
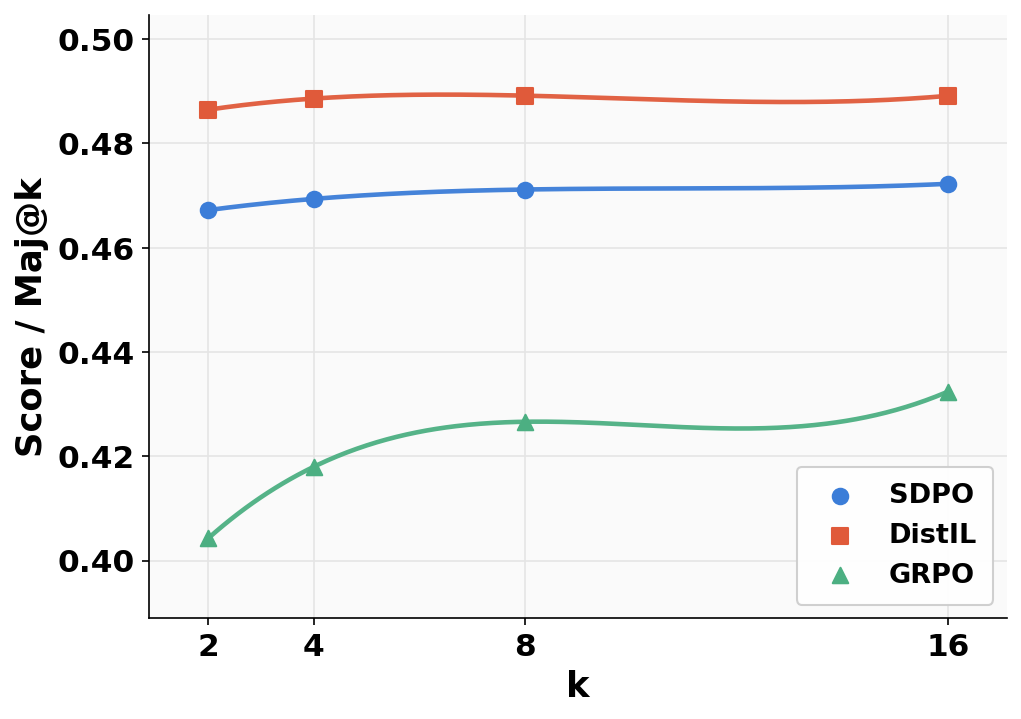
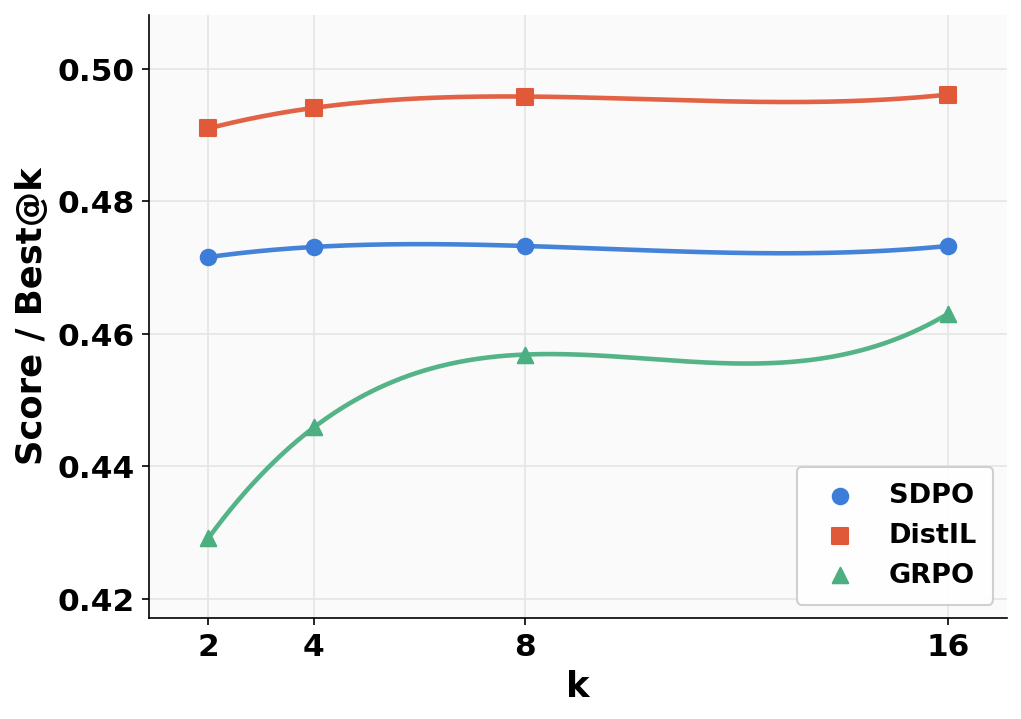
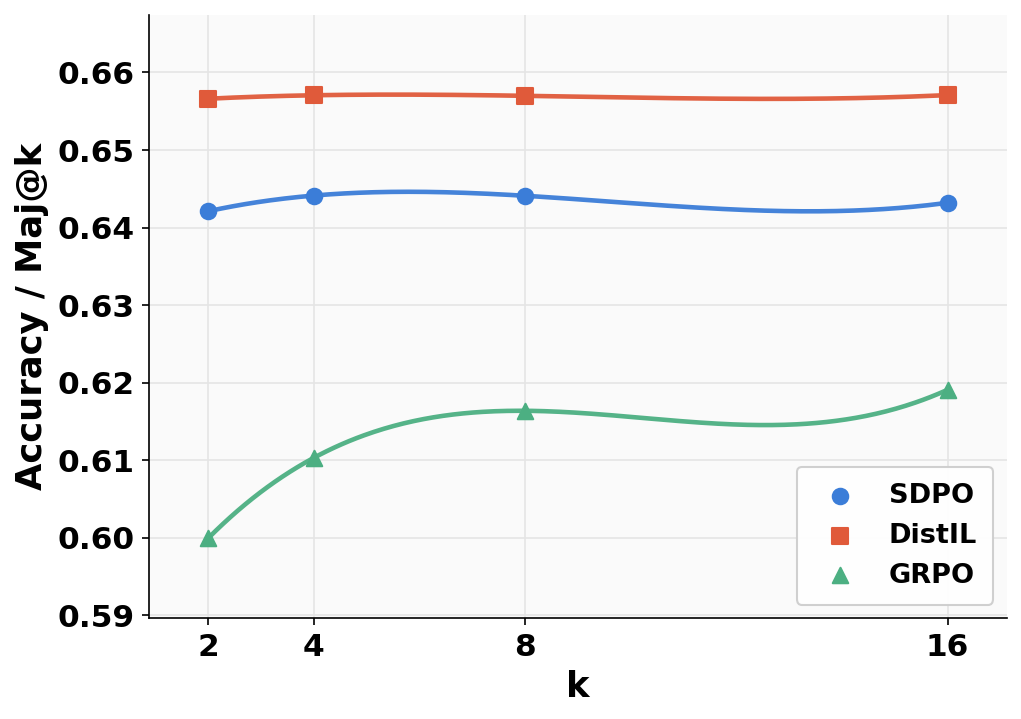
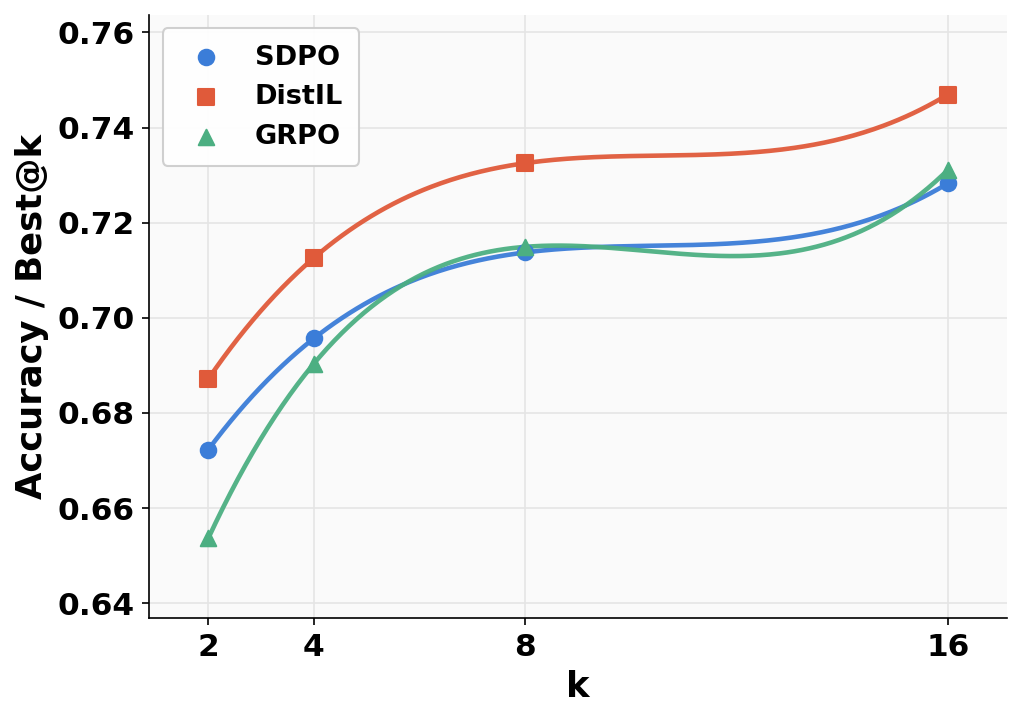
Figure 2: LCBv6 evaluation at LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]50.2 for accuracy and correctness metrics.
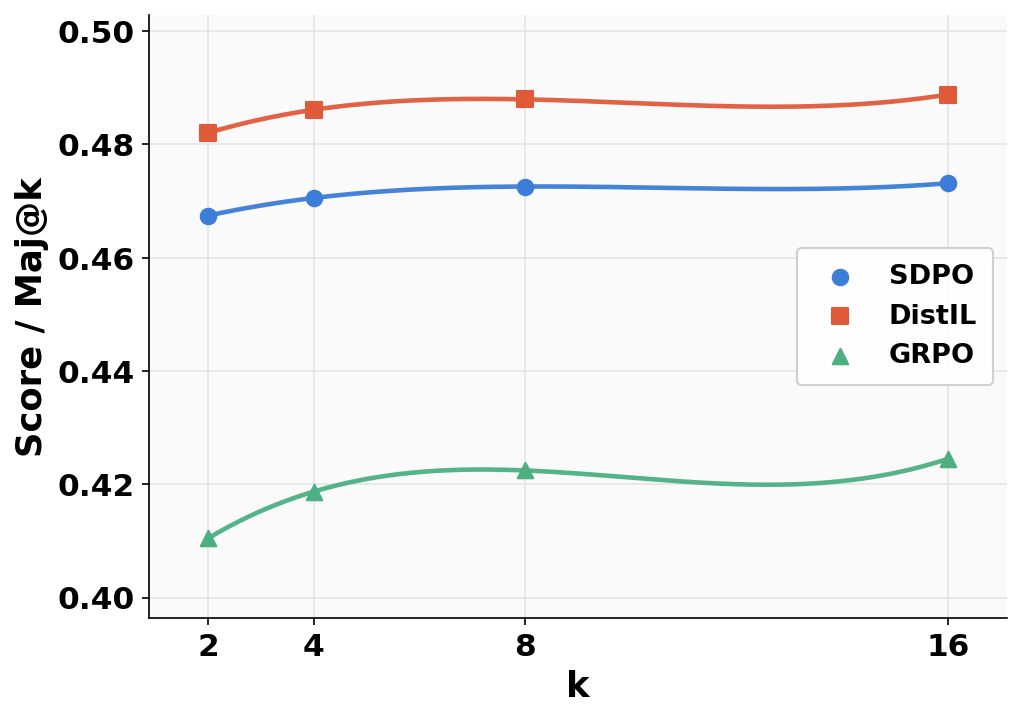
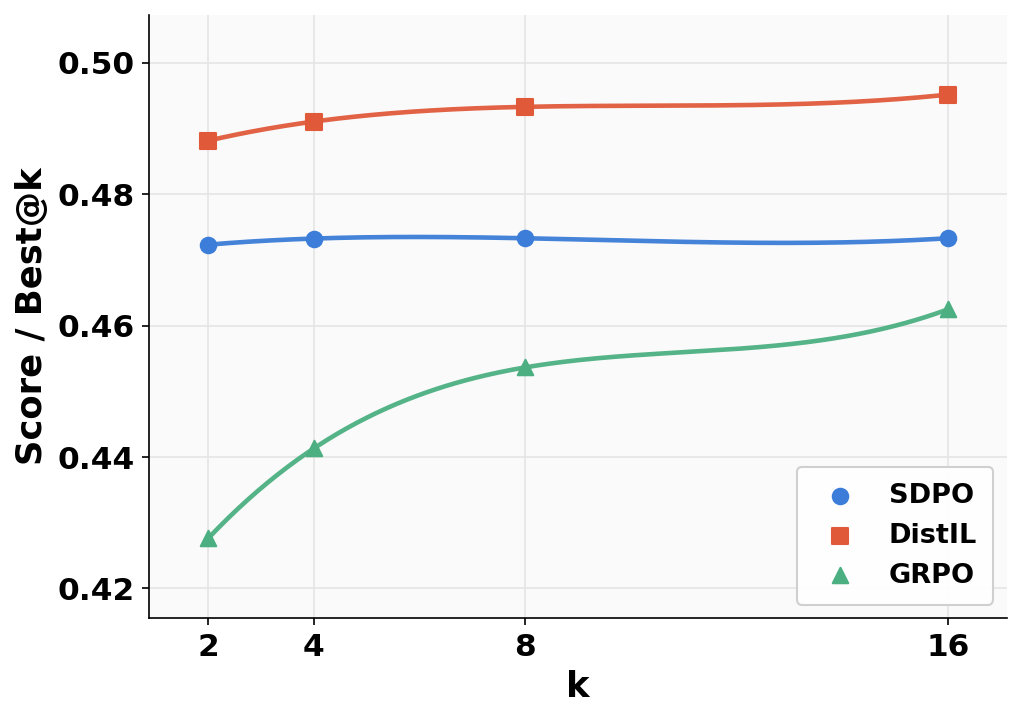
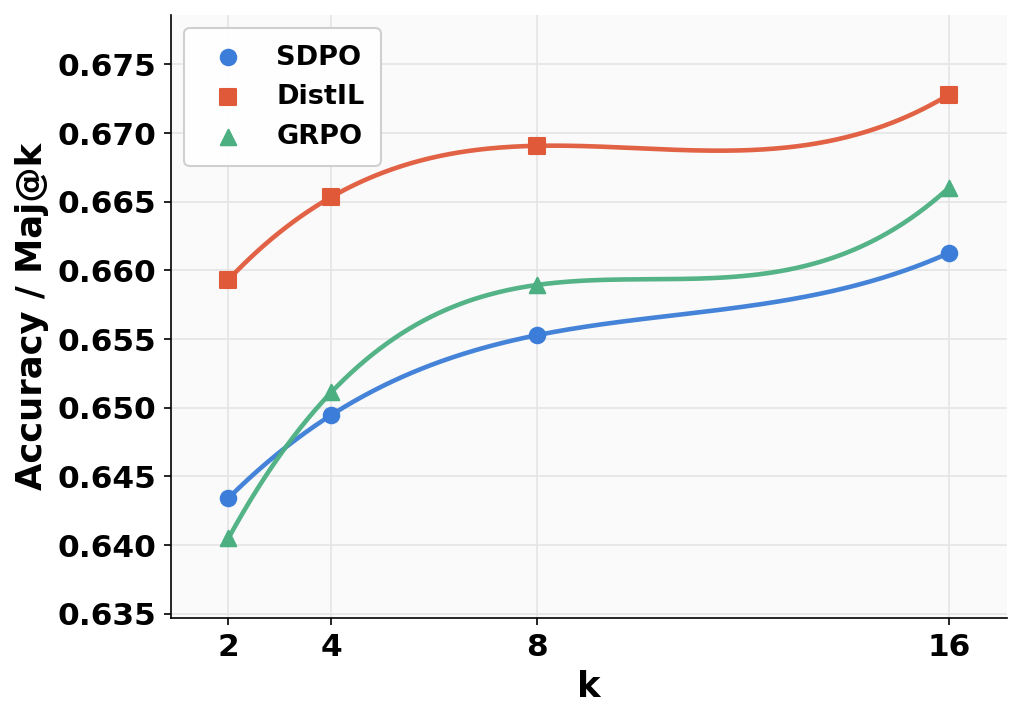
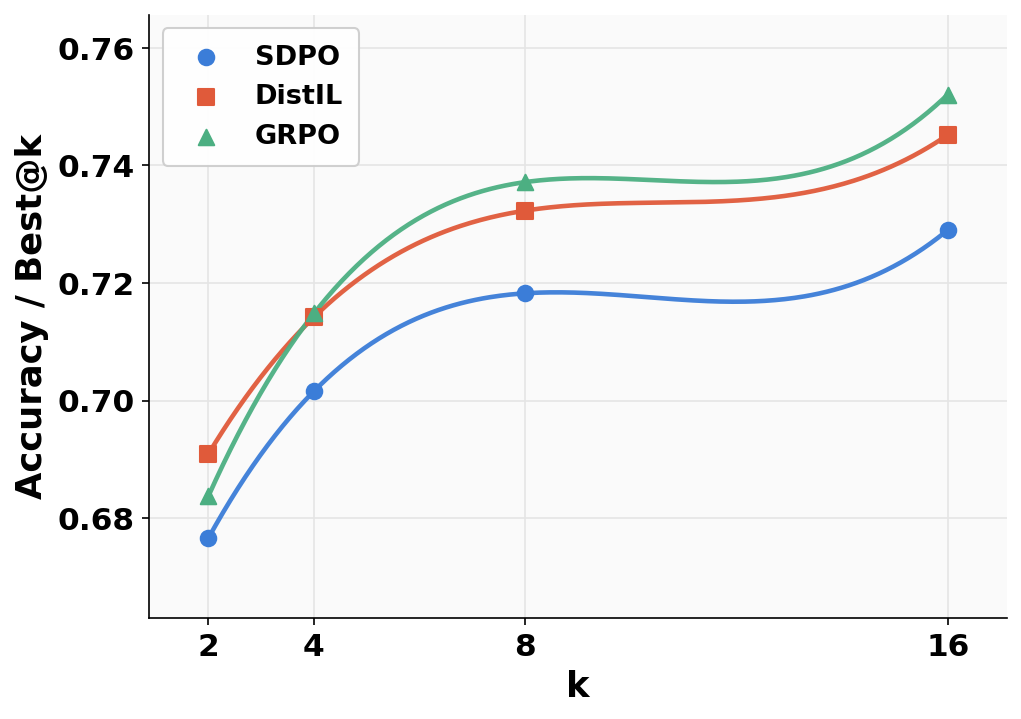
Figure 3: LCBv6 evaluation at LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]60.6 highlighting robustness to sampling temperature and code generation diversity.
Ablations demonstrate that the sequence-level future-credit gradient is crucial; local CE-based credit assignment (even with forward cross-entropy but no future-termed gradients) exhibits much higher variance and substantially reduced final accuracy (Figure 4).
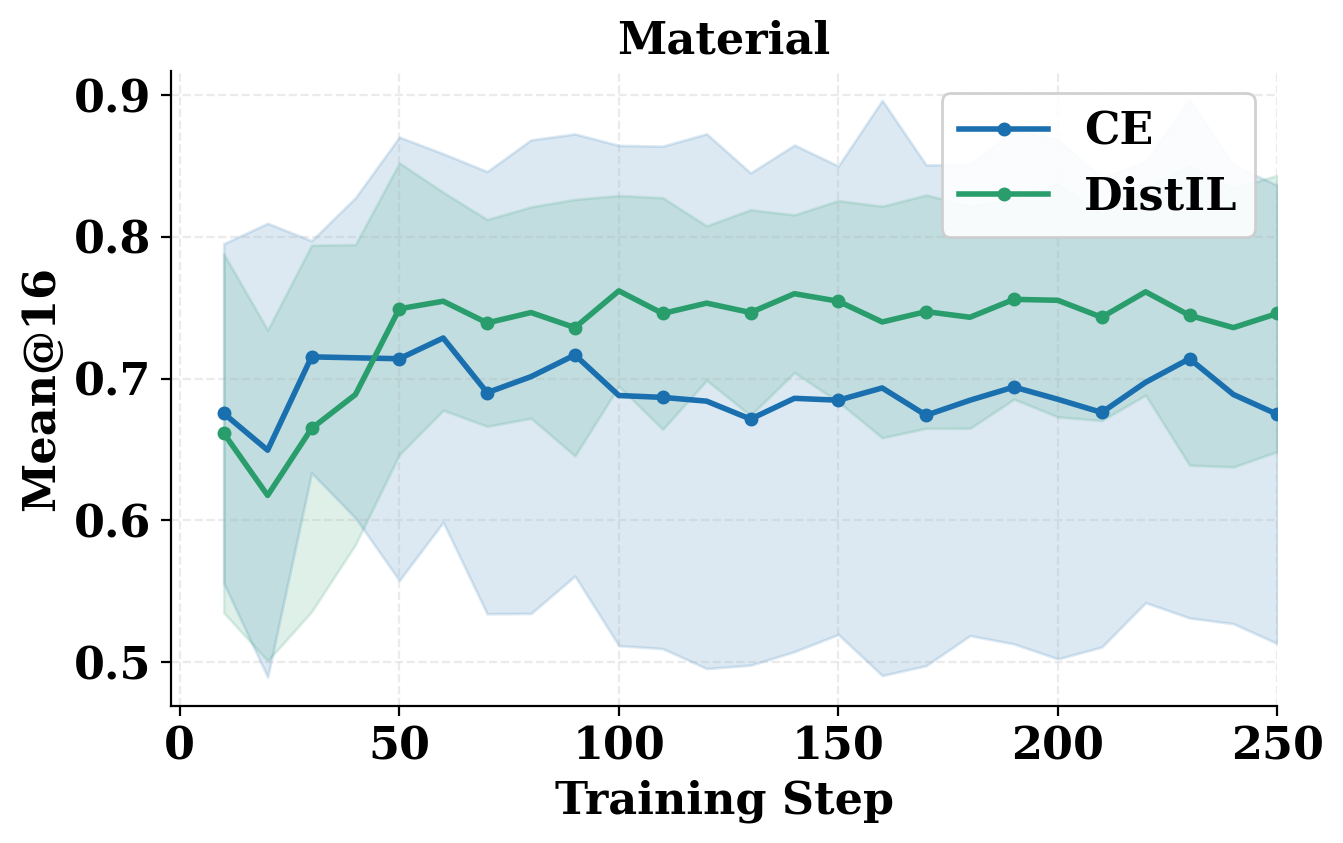
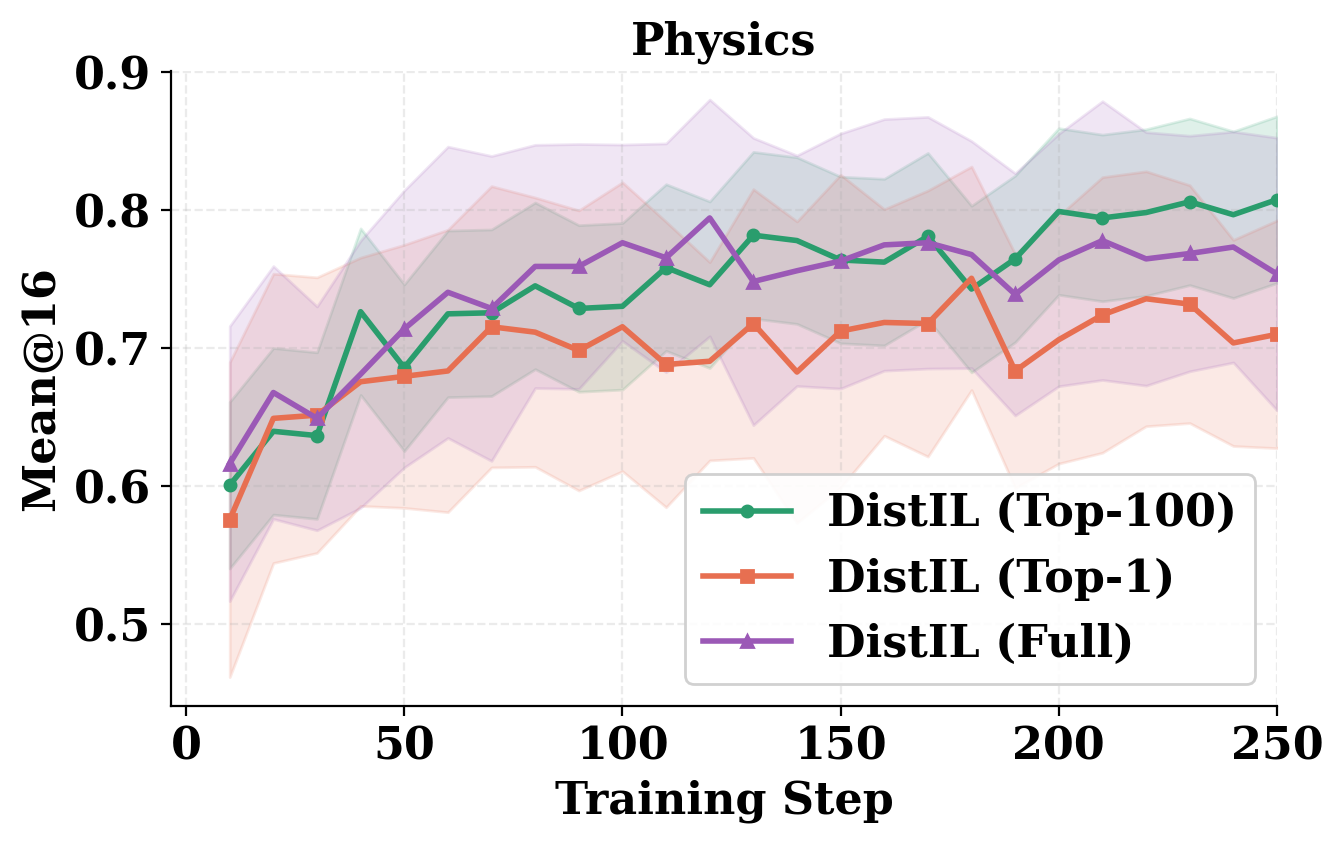
Figure 4: Comparing DistIL and local CE: sequence-level, future-aware credit assignment (DistIL) drives substantial gains in validation accuracy and consistency.
Top-1 versus Top-LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]7 distillation also confirms the benefit of leveraging more teacher mass, though using the full distribution can introduce deleterious noise from low-probability tokens.
Practical and Theoretical Implications
This work gives a prescription for RL from complex rich supervision signals in LLMs and sequence models:
- Sequence-level, future-aware distillation is necessary for effective utilization of feedback—including execution logs, intermediate correctness, and ground-truth traces—as it captures the causal dependence of later supervision on earlier decisions.
- Forward cross-entropy is the only divergence in this family with strong first-order reward alignment, monotonic improvement, regret bounds, and Pass@LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]8 connections. Reverse KL, Jensen-Shannon, and all standard LDistIL(θ)=Ex,y∼πθ[t=1∑HH×(πT(⋅∣st),πθ(⋅∣st))]9-divergence-based objectives can be misaligned even when the teacher is strictly superior.
- The generic recipe unifies classical imitation learning (DAgger) and modern RL from privileged/model feedback, with immediate application for black-box teachers, human-in-the-loop feedback, and model distillation settings.
In the broader context of RLHF, preference-based RL, and direct alignment, these results highlight the limitations of policy optimization by traditional divergence objectives and tokenwise local signals, motivating a shift toward distributional, sequence-level methods for dense, causally correct credit assignment. Given the demonstrated sample-efficiency, stability, and performance improvements, distributional DAgger-style distillation can be considered a new standard for RL from rich feedback across reasoning, code, and complex plan domains.
Conclusion
"Reinforcement Learning from Rich Feedback with Distributional DAgger" (2606.05152) provides both the first tight theory and strong empirical evidence clarifying the failure modes of standard H×(p,q)=−Ey∼p[logq(y)]0-divergence self-distillation and tokenwise RL objectives in the presence of complex supervision. Through a carefully constructed sequence-level forward cross-entropy objective and full-credit gradient, the proposed DistIL framework achieves high stability, monotonic reward improvement, and strong generalization performance, directly supporting scalable RL with rich supervision in LLMs and complex autoregressive agents. Future work may extend these findings to real-time interactive environments with human and programmatic corrective signals, and inform the next generation of credit assignment and feedback-propagation strategies for RL in the LLM era.

