Restoring the Sweet Spot: Pass-Rate Weighted Self-Distillation for LLM Reasoning
Published 26 May 2026 in cs.LG and cs.AI | (2605.27765v1)
Abstract: Self-Distillation Policy Optimization (SDPO) provides dense token-level credit assignment for reinforcement learning with LLMs by leveraging the model's own feedback-conditioned predictions as a self-teacher. Unlike GRPO, however, whose group-relative advantage naturally concentrates learning on a sweet spot of intermediate-difficulty questions, SDPO's KL-based advantage lacks an implicit notion of difficulty awareness. We analyze this gap through the lens of GRPO's advantage normalization. Extending the learnability framework to normalized rewards, we show that normalization absorbs the variance term $p(1-p)$, equalizing leading-order learnability across questions and leaving $\sqrt{p(1-p)}$ as the sole residual scaling factor in the per-question gradient. This analysis yields a simple prescription: weight each question's SDPO loss by $[\hat{p}(1-\hat{p})]{1/2}$, resulting in SC-SDPO, a scale-consistent variant of SDPO. The proposed weights are obtained as a zero-cost byproduct of on-policy rollouts with batch-adaptive normalization, inducing an implicit curriculum that dynamically tracks the model's evolving competence. Experiments on scientific reasoning and tool-use benchmarks demonstrate that SC-SDPO consistently improves over SDPO, yielding gains of +3.2/+4.3 (mean@16/maj@16) on Qwen3-8B and +1.8/+3.0 on OLMo-3-7B, while preserving stable training dynamics throughout optimization.
The paper introduces SC-SDPO, which augments self-distillation with pass-rate weighting to restore difficulty-aware credit assignment in LLM reasoning.
It leverages on-policy empirical pass rates to dynamically scale gradients, yielding notable performance gains and enhanced training stability across benchmarks.
The method incurs zero additional generation cost and generalizes across varied model architectures, underscoring its practical applicability for scaling LLMs.
Pass-Rate Weighted Self-Distillation for LLM Reasoning: The SC-SDPO Framework
Motivation and Theoretical Foundations
The continual refinement of LLMs for reasoning-intensive domains such as scientific QA and tool-use increasingly relies on reinforcement learning with verifiable rewards (RLVR) and on-policy distillation (OPD). RLVR’s sparse, binary outcome constraints create a fundamental credit assignment bottleneck: models receive a singular reward for correctness, but lack token-level feedback. SDPO (Self-Distillation Policy Optimization) addresses this by utilizing the model’s in-context learning, producing dense supervision via self-teacher reprompting conditioned on privileged information, typically errors or correct exemplars (Hübotter et al., 28 Jan 2026). However, unlike GRPO (Group Relative Policy Optimization), whose normalization implicitly concentrates learning on intermediate-difficulty problems (the "sweet spot"), SDPO’s KL-based distillation objective is agnostic to question difficulty.
This paper extends theoretical analyses from [bae2026online] to normalized reward settings. It demonstrates that GRPO’s normalization strategy absorbs the p(1−p) pass-rate variance—forming a constant learnability bound—while the gradient magnitude scales with p(1−p). This leads to an idealized weighting scheme: scale each SDPO loss by [p^(1−p^)]1/2, restoring the difficulty-aware regime to SDPO while maintaining dense credit assignment.
Methodology: Scale-Consistent SDPO (SC-SDPO)
SC-SDPO augments SDPO with a minimal but principled modification: a per-question scalar weight based on on-policy empirical pass rate p^. Rollout groups are classified by success, weights are dynamically recomputed on each training step, and normalized within each batch to control learning rate drift. The objective is given by:
Zero additional generation cost: pass-rate statistics are free byproducts of the SDPO pipeline.
Implicit curriculum: weights automatically adapt as questions are solved or mastered, broadening and shifting the sweet spot in lockstep with model performance.
Scale consistency: α=1/2 yields optimal empirical results and aligns with learned gradient scaling, outperforming α=1 and static, offline weighting schemes like PACED (Xu et al., 11 Mar 2026).
Empirical Results
Experiments leverage Qwen3-8B and OLMo-3-7B on reasoning and tool-use tasks, following the benchmarks and protocol from [hubotter2026reinforcement]. Several baselines (GRPO, SDPO, PACED, Hard Filter, SRPO) are compared, isolating the effect of difficulty-aware weighting.
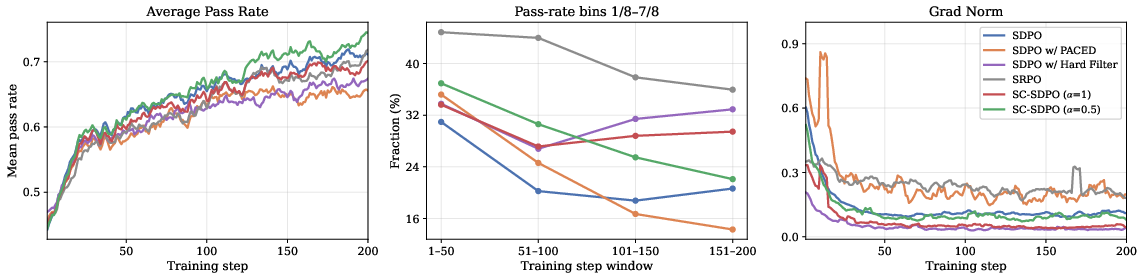
Performance Gains: SC-SDPO (α=0.5) achieves +3.2/+4.3 improvements (mean@16/maj@16) over unweighted SDPO on Qwen3-8B, and +1.8/+3.0 on OLMo-3-7B. These are consistent across disciplines and exhibit pronounced gains where pass-rate distributions have broad intermediate regimes.
Dense Credit Assignment Essential: GRPO baselines lag substantially, confirming the necessity of per-token signal for effective RLVR post-training.
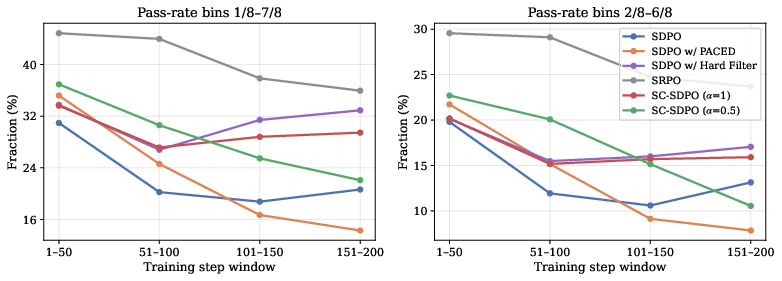
Weighting Schemes: Batch-adaptive, on-policy recomputation outperforms static schemes and hard filtering. PACED and p(1−p)0 variants suppress learning signal, while SRPO (sample routing) achieves high retention of intermediate-difficulty samples but greater gradient instability.
Figure 1: Averaged training dynamics across five datasets, showing mean pass rate, intermediate-pass-rate sample fraction, and gradient norms per training step.
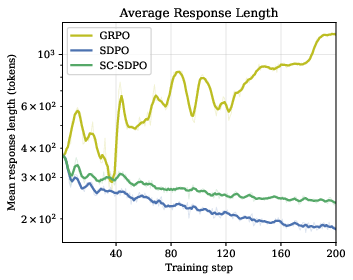
Figure 2: Average response length (in tokens) over 200 training steps, demonstrating that SC-SDPO sustains longer, more elaborate outputs compared to SDPO.
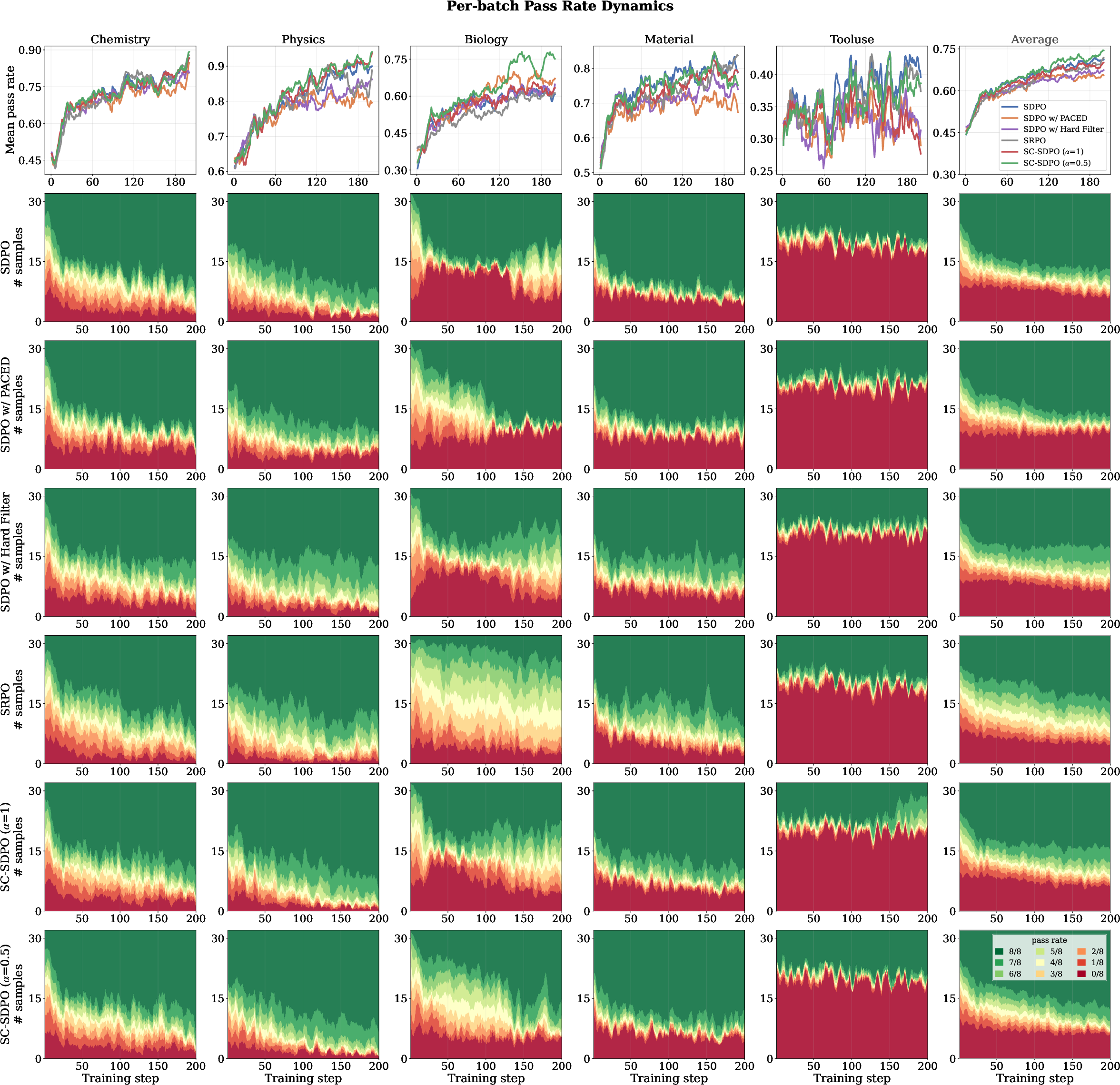
Figure 3: Per-batch pass rate dynamics across datasets, with stacked area charts visualizing retention and migration of training samples across pass-rate bins.
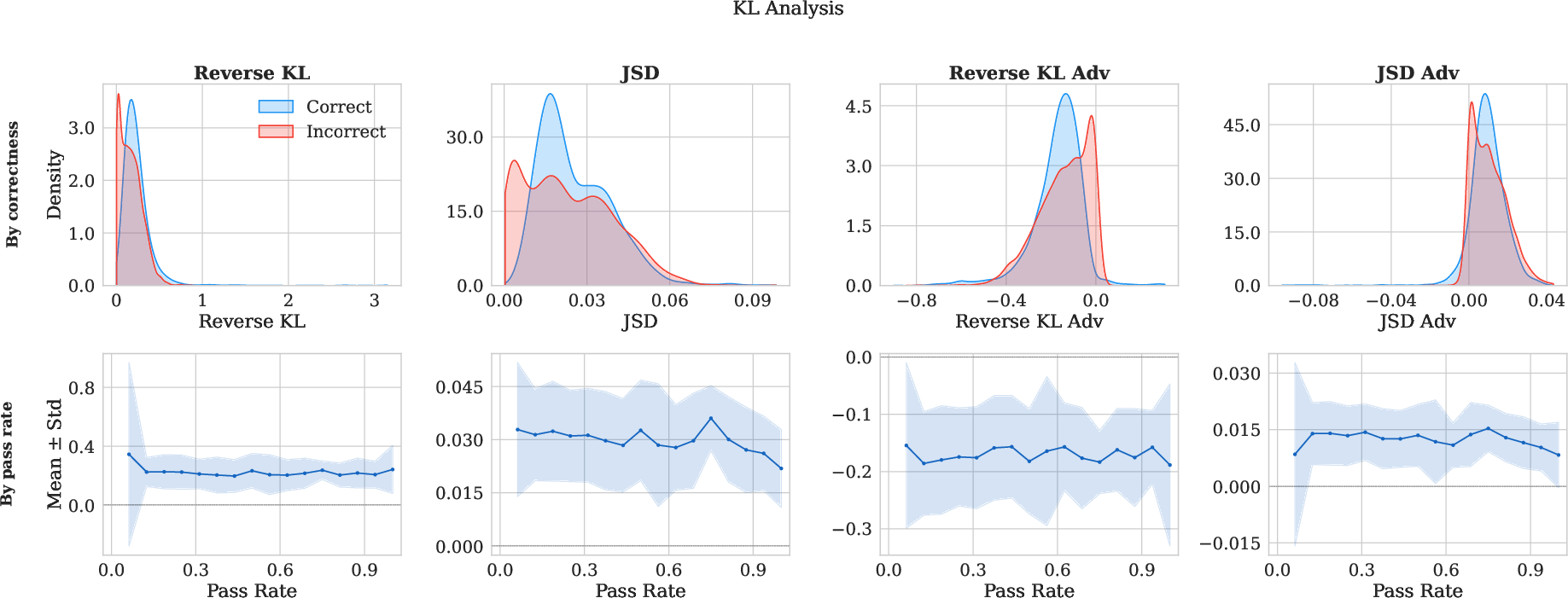
Figure 4: KL-based analysis of Qwen3-8B’s SDPO logit-level advantage, stratified by rollout correctness and illustrating insensitivity to pass rate.
Practical and Theoretical Implications
Pass-rate weighting restores a critical aspect of reasoning-centric RLVR: focusing gradient budget on the intermediate-difficulty (contrastive) zone where self-distillation is maximally informative. The batch-adaptive weighting yields a curriculum which adapts dynamically, greatly improving learning efficiency and stability without architectural or hyperparameter complexity.
The theoretical results generalize previous analyses, clarifying that reward normalization is essential for maximizing learnability; the ideal scaling is not p(1−p)1 (variance), but p(1−p)2 (standard deviation), as dictated by GRPO’s normalized update.
On the practical front, SC-SDPO’s simple modification is model-agnostic and aligns well with larger-scale in-context learners. The method’s minimal compute overhead and robustness to batch composition make it suitable for scaling experiments and deployment in operational LLMs.
Limitations and Future Directions
The effectiveness of SC-SDPO is subject to several caveats:
Granularity: With limited rollouts (e.g., p(1−p)3), pass rates are discretized; increasing p(1−p)4 improves weighting resolution at cost of inference.
Reward Structure: The theoretical justification assumes binary reward; in settings with partial credit or continuous rewards, the optimal weighting exponent may differ.
Task Scope: Application to open-ended or non-verifiable domains could require alternative proxies for competence.
Model Scale: Empirical results are restricted to models up to 8B parameters; further scaling studies are warranted.
Conclusion
This work synthesizes advances in self-distillation and difficulty-aware training, precisely analyzing and remedying the representational gap between SDPO and GRPO. By deriving and validating the scale-consistent pass-rate weighting, SC-SDPO achieves robust gains in both accuracy and training stability, demonstrating that dense token-level credit and dynamic question-level modulation are complementary and necessary for optimal LLM reasoning. The framework is widely applicable and constitutes a principled advance in RLVR/OPD for reasoning-centric LLMs (2605.27765).
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.