- The paper demonstrates that naive self-distillation can harm long-horizon tool-use RL by collapsing executable actions.
- The methodology leverages dynamic sibling sampling, external LLM summarization, and divergence-based advantage reweighting to guide policy gradients.
- Empirical results on τ³-airline and AppWorld show improved task completion and maintained tool-use capabilities compared to baseline methods.
Motivation and Failure of Direct Self-Distillation
Reinforcement learning (RL) for multi-turn tool-use language agents presents a challenging credit assignment problem due to the long horizon and compositional nature of tool-augmented trajectories. Group-relative policy optimization (GRPO) and related policy gradient methods broadcast trajectory-level rewards across token sequences, dispersing the advantage indiscriminately over reasoning, API calls, and answers. Self-distillation (SD), wherein a student imitates its own successful behaviors or those of a privileged teacher, is hypothesized to address this by enriching token-level training signals.
However, the authors empirically show that direct token-level SD can be detrimental in long-horizon tool-use RL. On benchmarks such as τ3-airline, naive SD consumes tool-use behaviors already present in pretrained or supervised checkpoints and disincentivizes executable action trajectories, collapsing agent behavior to trivial information-only responses. This is a silent failure mode concealed by aggregate metrics—test pass@1 for SDPO degrades to 0.317 (from 0.583 with GRPO+KL), and state-changing action success falls to zero.
This mechanism arises due to the SD loss encouraging the student to match the teacher’s probability distribution per token, regardless of verifier reward: it amplifies both desirable behaviors and spurious shortcuts. The SD gradient can directly compete with the policy-gradient update, steering the agent toward unreproducible or unrewarded action plans, particularly when the teacher distribution is conditioned on privileged or noisy context inaccessible during deployment.
Sibling-Guided Credit Distillation: Methodology
To address these shortcomings, Sibling-Guided Credit Distillation (SGCD) reframes the role of distillation from a source of direct actor gradients to a source of credit assignment. The core insight is to use distillation-derived signals exclusively to modulate the policy-gradient advantage, preserving reward-grounded updates as the sole driver for the actor parameters.
The SGCD pipeline comprises four sequential stages:
- Dynamic Sibling Sampling: For each prompt, mixed sibling rollouts (successful and failed) are generated under the current policy using group sampling. Only mixed groups, with both verified successes and failures, are retained for constructing credit evidence.
- External LLM Summarization: A strong external LLM—operating only during training—summarizes sibling rollouts into a stepwise credit reference. This summary abstracts reusable state checks, successful action choices, identified deviation points, and represents credit assignment evidence while strictly masking any benchmark-private or literal answer information.
- Detached Divergence Computation: The policy under training is then forward-scored twice for each token: first in the standard student context, and second with the credit reference prefix. Dense top-K reverse KL divergence and teacher entropy are computed for each token position, forming a tokenwise credit saliency profile. The divergence and entropy are strictly stop-gradient with respect to the actor parameters—ensuring the absence of any direct teacher-driven actor gradients.
- Bounded Credit Reweighting: The tokenwise scalar advantage is replaced by a bounded, divergence-derived multiplier within the GRPO loss. High-saliency tokens, corresponding to high teacher/student disagreement and confident teacher predictions, receive amplified advantage; the sign of the trajectory-level advantage is preserved. The overall actor update thus remains strictly aligned with verifier-anchored policy gradients, with the distillation merely concentrating where within the sequence advantage should be delivered.
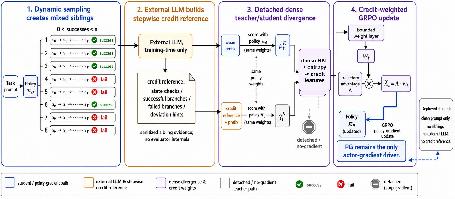
Figure 1: SGCD overview. Dynamic sampling, external LLM credit summarization, dense teacher/student divergence features, and bounded credit weights are integrated for training-only credit assignment; runtime does not require the external LLM or sibling evidence.
Theoretical Properties
SGCD preserves several key theoretical properties. All gradient flow to actor parameters passes through the policy ratio and GRPO surrogate; there is no gradient path from the teacher (detached features). The reweighted advantage scales but does not invert the verifier-grounded signal, ensuring that the local tokenwise policy updates cannot oppose the reward. The weight clipping guarantees a bounded effect envelope: SGCD can double local credit at most, and batch gradients remain within a factor of two of GRPO.
Experimental Results and Diagnostics
SGCD is evaluated on two multi-turn tool-use RL benchmarks: AppWorld and τ3-airline. On AppWorld, starting from Qwen3.5-4B, SGCD improves the test_normal Task Goal Completion (TGC) from 42.9 (GRPO) to 45.6, and test_challenge TGC from 24.7 to 27.0. The gains, though modest over a strong GRPO baseline, are consistent and robust.
In τ3-airline, the diagnostic focus, SGCD achieves held-out pass@1 of 0.602 (vs 0.583 GRPO+KL and 0.317 SDPO). Crucially, SGCD preserves state-changing action success at 43.5%, whereas SDPO collapses to 0% after training. The method directly addresses the hidden failure mode, as observed in stepwise reward and tool-use diagnostics.
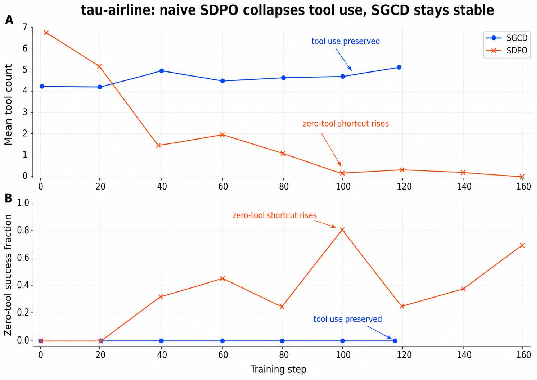
Figure 2: τ3-airline diagnostic curves. SDPO collapses tool/action behavior late in training, while SGCD maintains nonzero tool use and avoids zero-tool stagnation.
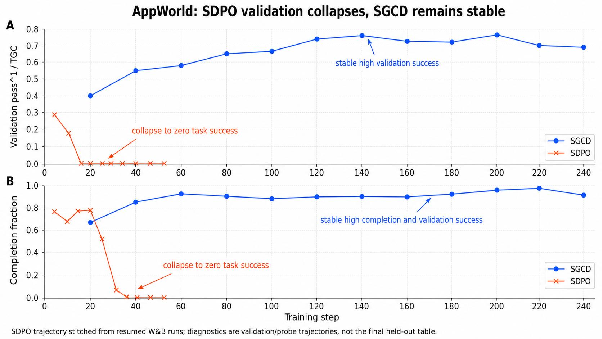
Figure 3: AppWorld diagnostic curves. SGCD preserves stable task completion throughout training; SDPO shows early collapse in both outcome success and action completion.
Ablative experiments confirm the necessity of the sibling credit reference, divergence-driven weighting, and the bounded reweighting strategy. Removing the sibling reference or divergence weighting erodes the gains, and reverting to an uncapped/distillation auxiliary drives performance below vanilla GRPO.
Practical and Theoretical Implications
SGCD establishes a strict separation between distillation-derived signals and actor updates in long-horizon tool-use RL. By using teacher/student divergence only for advantage reweighting and not as a competing actor loss, the method avoids overfitting to privilege-conditioned or ungrounded behaviors, thereby safeguarding tool-use capabilities critical for agent deployment.
The experimental evidence demonstrates that richer credit assignment via mixed sibling comparisons and contextual LLM summaries can concentrate policy improvement within complex trajectories, even when the observed effect over strong baselines is incremental. The method's deployability is enhanced by the fact that all privileged signals are training-only; the deployed student operates with standard prompts and no external dependencies.
With increasing interest in agentic LLM applications, SGCD suggests that richer, context-sensitive credit mechanisms can be orthogonally combined with current group-relative policy gradient optimizers to reliably amplify behavioral competence. Extensions to other model families, scale regimes, and broader benchmarks remain open.
Conclusion
By systematically dissecting the failure of naive self-distillation in tool-use RL and introducing SGCD, this work provides a robust framework for long-horizon credit assignment via distillation-derived, sibling-guided, detached advantage weighting. Empirical gains are consistent across hard RL benchmarks, and the method’s bounded effect and reward alignment illustrate a sound inductive bias for future RL finetuning protocols for compositional language agents.

