- The paper introduces SC-GRPO, a self-conditioned variant of GRPO that employs token-level KL divergence as a multiplicative weight for refined credit assignment in RLVR.
- The paper demonstrates significant performance improvements, with Avg@8 gains of 8.1% and Pass@8 gains of 10.9% over competing methods across multiple benchmarks.
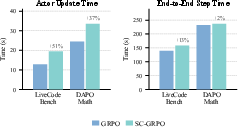
- The paper validates the approach by showing enhanced stability and efficiency in gradient routing without relying on external annotations or privileged demonstrations.
Self-Conditioned Credit Assignment for RLVR: An Analysis of SC-GRPO
Motivation and Problem Statement
RL with Verifiable Rewards (RLVR) has become foundational in training LLMs for high-difficulty reasoning tasks, where a verifier provides only sparse, binary feedback. Existing approaches, particularly GRPO and its extensions, assign uniform credit to all tokens in a rollout, which inherently dilutes the RL signal by underweighting pivotal decision points and wasting computation on uninformative tokens. Prior work on token-level credit assignment typically depends on additional resources: either finely-tuned reward models or privileged information (external ground-truth or expert demonstrations) for distillation. These dependencies pose serious barriers in practical RLVR, as such information is, by construction, unavailable.
The paper proposes SC-GRPO, a self-conditioned variant of GRPO, that eliminates reliance on external annotation or privileged demonstrations. The method leverages the observation that verified trajectories, available from the model's own past correct rollouts, can be used to construct a self-conditioned policy. By comparing per-token predictions of the model conditioned (teacher) and not conditioned (student) on these verified solutions, SC-GRPO derives token-level KL as a signal for credit assignment, thus enabling fine-grained gradient routing without leaving the RLVR paradigm.
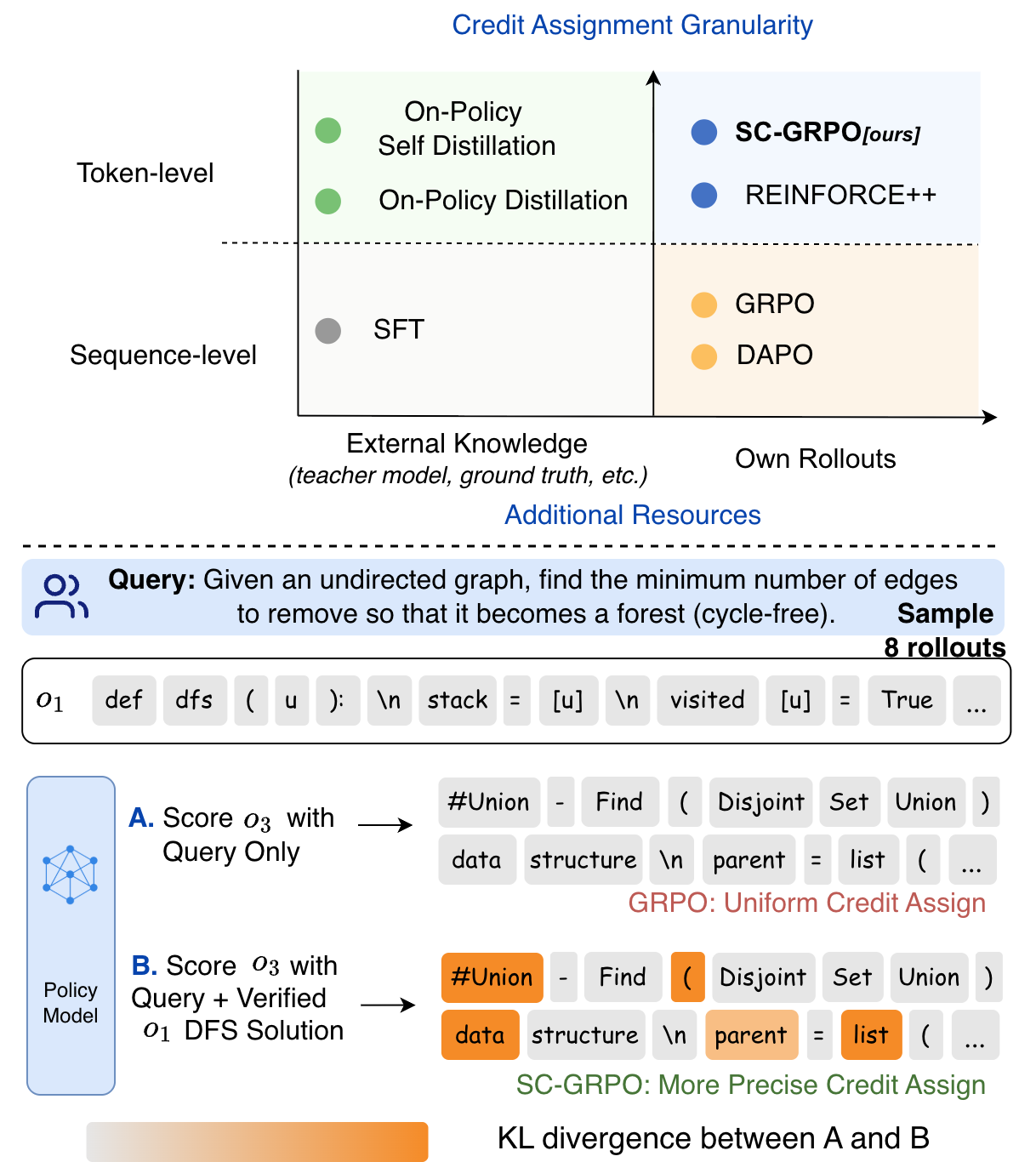
Figure 1: Conceptual depiction of SC-GRPO’s position among existing credit assignment methods and core mechanism on code generation.
Theoretical Foundation: Why Existing Self-Distillation Fails
In RLVR, the only supervision beyond binary outcome signals is the set of the model’s own verified trajectories. The paper rigorously demonstrates that direct adaptation of On-Policy Self-Distillation (OPSD), by conditioning the teacher on such trajectories and minimizing divergence to the student, leads to infeasible token-wise targets. Specifically, the resulting optimization objective compels the student to approximate an average distribution over all verified teachers—a mixture distribution that does not correspond to any single valid trajectory and ignores disagreement signals at decision points. As a result, such additive distillation losses (forward/reverse/bidirectional KL) either stagnate or degrade final policy performance.
Self-Conditioned GRPO (SC-GRPO): Mechanism
SC-GRPO departs from direct self-distillation by using the KL difference as a multiplicative weight on the GRPO gradient, rather than as an auxiliary loss. The update direction is determined by sequence-level advantage (as in GRPO), while the KL score modulates how much each token contributes to the parameter update, amplifying signal at high-KL (decision-relevant) tokens and suppressing gradient flow at routine or low-information positions.
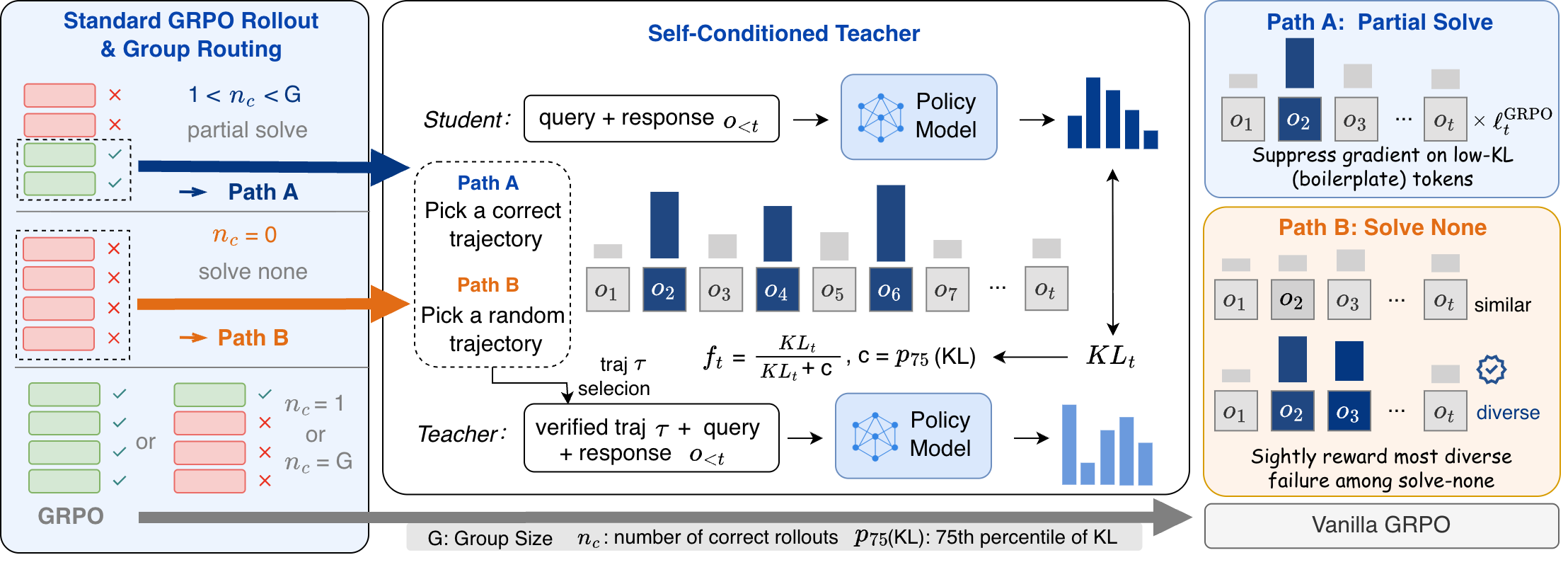
Figure 2: SC-GRPO workflow—teacher constructed via in-context verified trajectory, token-level KL computation, and KL-weighted gradient.
The method handles three group regimes:
- Partial-solve groups (some correct rollouts): Each incorrect rollout is paired with a reference correct trajectory for conditioning; KL is computed per-token.
- Solve-none groups (no correct rollouts): A random rollout within the group provides diversity signal, encouraging exploration when reward is absent.
- Single/all-correct groups: GRPO is used unchanged.
The KL weight for each token uses the function f(Dt)=Dt/(Dt+c), with c set adaptively to the 75th percentile KL per batch, ensuring only the most distinctive tokens modulate the RL loss.
Experimental Results
SC-GRPO is evaluated across five benchmarks: mathematical reasoning (AIME 2024/2025), code generation (LiveCodeBench v6), and multi-turn agentic tasks (AppWorld, WebShop), with Qwen3-8B as the base model. Metrics include Avg@8 (expected reward over 8 samples) and Pass@8 (at least one success in 8), reflecting both average-case and best-case generalization.
Summary of results:
Ablation and Analysis:
- Credit Assignment as an Auxiliary Loss: Variants that add the KL signal as an auxiliary loss were consistently weaker than simple GRPO, supporting the theoretical analysis.
- Adaptive KL Thresholds: Using the 75th percentile of batch KL as c yields the most discriminative weighting strategy.
- Diversity Signal: A small diversity coefficient is key in solve-none groups; too much exploration degrades learning.
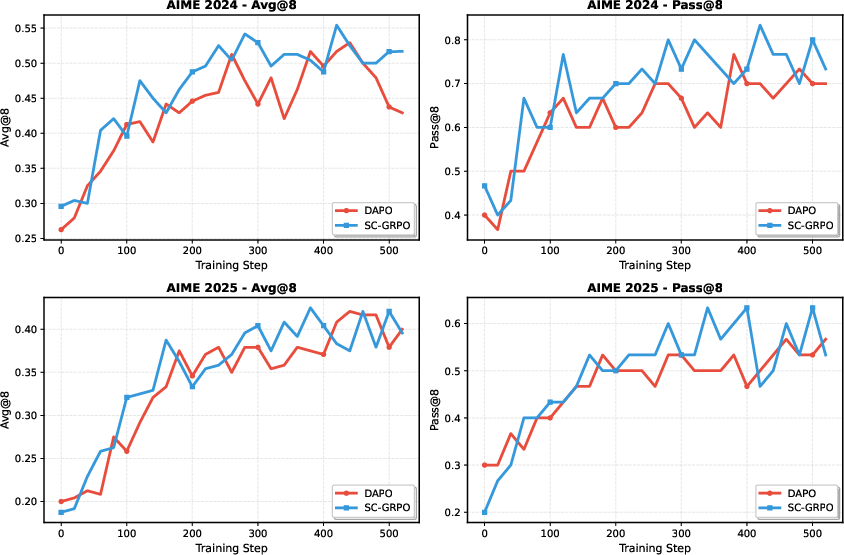
Figure 4: Training curves on AIME 2024/2025—SC-GRPO vs DAPO on both Avg@8 and Pass@8.
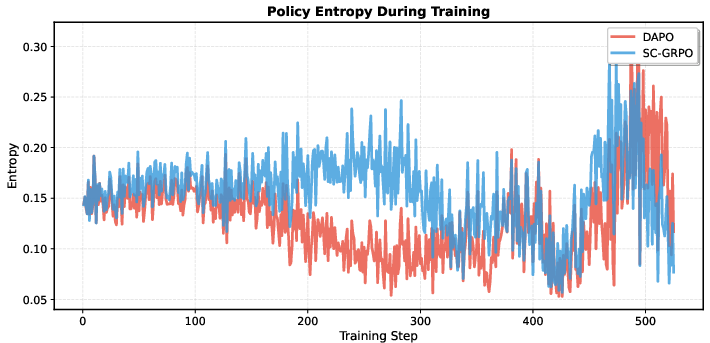
Figure 5: Policy entropy evolution—SC-GRPO achieves higher entropy, preserving exploration and solution diversity.
Out-of-Domain Generalization and Credit Assignment Visualization
SC-GRPO's gains generalize to held-out domains; when trained on LiveCodeBench and evaluated zero-shot on Codeforces, SC-GRPO maintains a 5.2% Avg@8 improvement over DAPO, demonstrating that the method benefits from improved credit assignment, not overfitting.
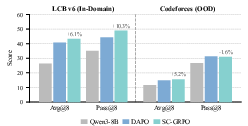
Figure 6: Out-of-domain generalization—LiveCodeBench-trained models evaluated on Codeforces.
Visualization of token-level heatmaps shows that KL-based weighting suppresses updates at routine tokens and focuses gradient mass on true decision points, e.g., the introduction of data structures or key computation steps in diverse code solutions. This property is pronounced when comparing rollouts implementing distinct algorithms (e.g., DFS vs DSU on a graph task).

Figure 7: Heatmap of per-token KL in a code-generation rollout—diffuse weights at routine tokens, high weights at algorithmic branch points.
Implications and Theoretical Significance
SC-GRPO demonstrates that by leveraging only information available in the RLVR paradigm (verified rollouts), one can perform fine-grained, token-level credit assignment without the need for auxiliary annotation or external teachers. The approach reestablishes the centrality of model-intrinsic signals (self-conditioned divergence) as a potent routing mechanism for RL gradients—provided they are used as weights and not targets.
In practical terms, SC-GRPO enables more efficient training of LLMs on reasoning and agentic tasks, reducing wasted gradient steps and improving convergence speed and stability across diverse RLVR benchmarks. Theoretically, this work contributes a new perspective on the role of self-distillation in RL: divergence is informative only insofar as it routes credit, not as a direct target.
Limitations and Prospects for Future Research
The work restricts experiments to 8B-parameter models and response lengths up to 12k tokens due to compute constraints; it remains untested whether the credit assignment advantages persist at the trillion-token scale needed for SOTA models. Moreover, applicability under extended reasoning protocols (explicit CoT, multi-turn deliberation, structured outputs) is untested. Potential future research includes adaptation to such protocols, automatic discovery of more expressive credit signals utilizing latent trajectory structure, and integration with process reward models while maintaining the RLVR constraint.
Conclusion
SC-GRPO provides an RLVR-native mechanism for token-level credit assignment by constructing self-conditioned teacher policies from the model's own verified outputs and employing per-token KL as a gradient weight. This architecture achieves consistently superior performance over existing RLVR and distillation baselines with negligible overhead, fundamentally advancing the methodology of RL for LLMs under verifiable, non-privileged feedback. The framework reconciles the need for fine-grained credit assignment with the practical constraints of RLVR, setting a new state-of-the-art for sample-efficient, stable, and generalizable LLM RL training.