DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
Abstract: Reinforcement learning is crucial for aligning LLMs to perform complex reasoning tasks. However, current algorithms such as Group Relative Policy Optimization suffer from coarse grained, sequence level credit assignment, which severely struggles to isolate pivotal reasoning steps within long Chain of Thought generations. Furthermore, the standard unbounded Kullback Leibler divergence penalty induces severe gradient instability and mode seeking conservatism, ultimately stifling the discovery of novel reasoning trajectories. To overcome these limitations, we introduce Distribution Guided Policy Optimization, a novel critic free reinforcement learning framework that reinterprets distribution deviation as a guiding signal rather than a rigid penalty.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is about teaching big AI LLMs (like the ones that write step-by-step math solutions) to reason better. The authors create a new training method, called Distribution-Guided Policy Optimization (DGPO), that helps the model figure out which exact words or steps in a long answer were truly important, and reward those parts more. This makes the model learn smarter, not just longer.
What questions the paper tries to answer
- When an AI writes a long, step-by-step solution, how can we tell which specific steps were helpful and which were just filler?
- How can we let the model explore new, creative steps without punishing it too much for being different from its old habits?
- Can we do all this efficiently, without adding an extra heavy “critic” model that’s expensive to train?
How the method works (with everyday analogies)
Think of training the AI like coaching a team to solve puzzles:
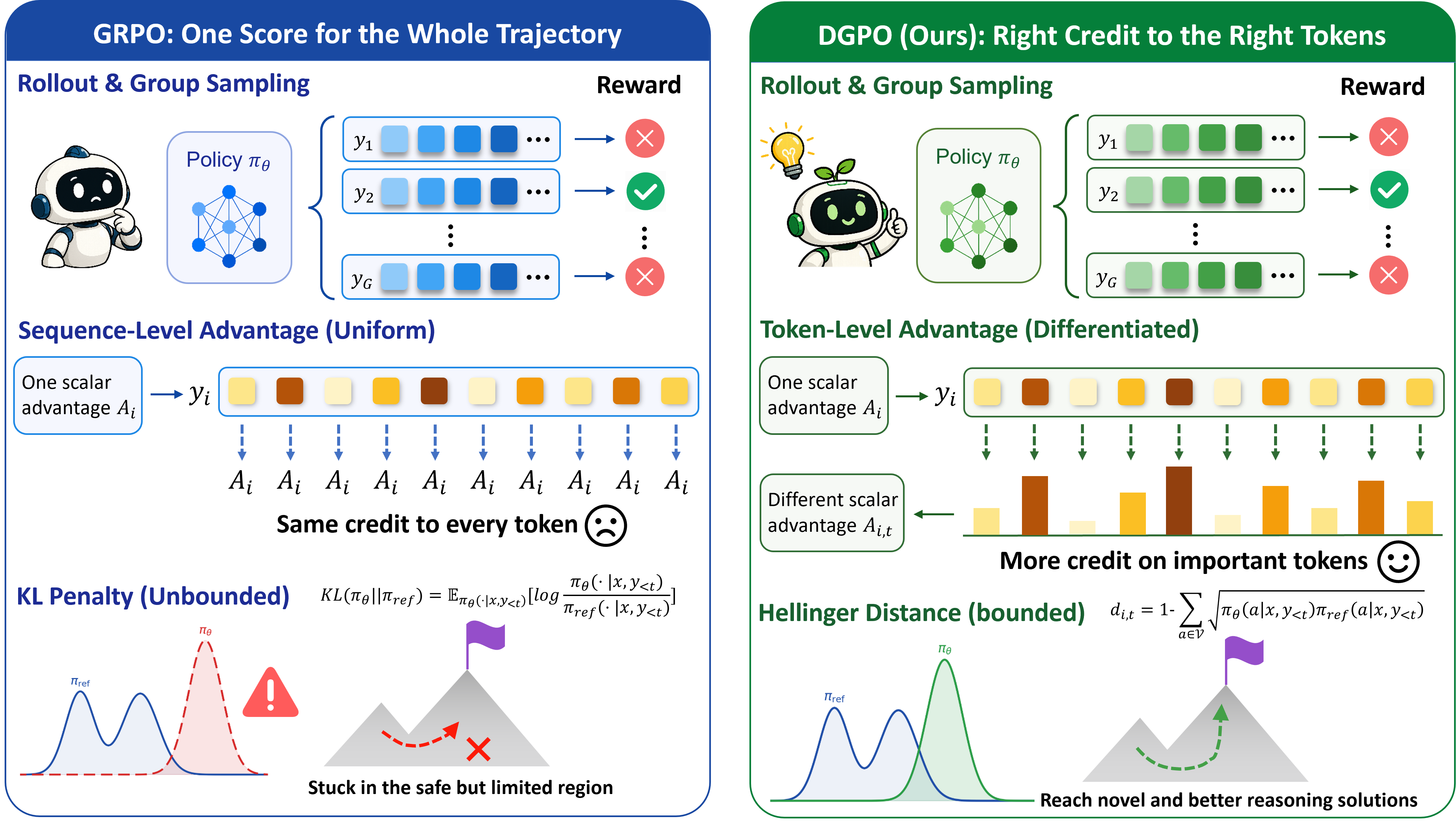
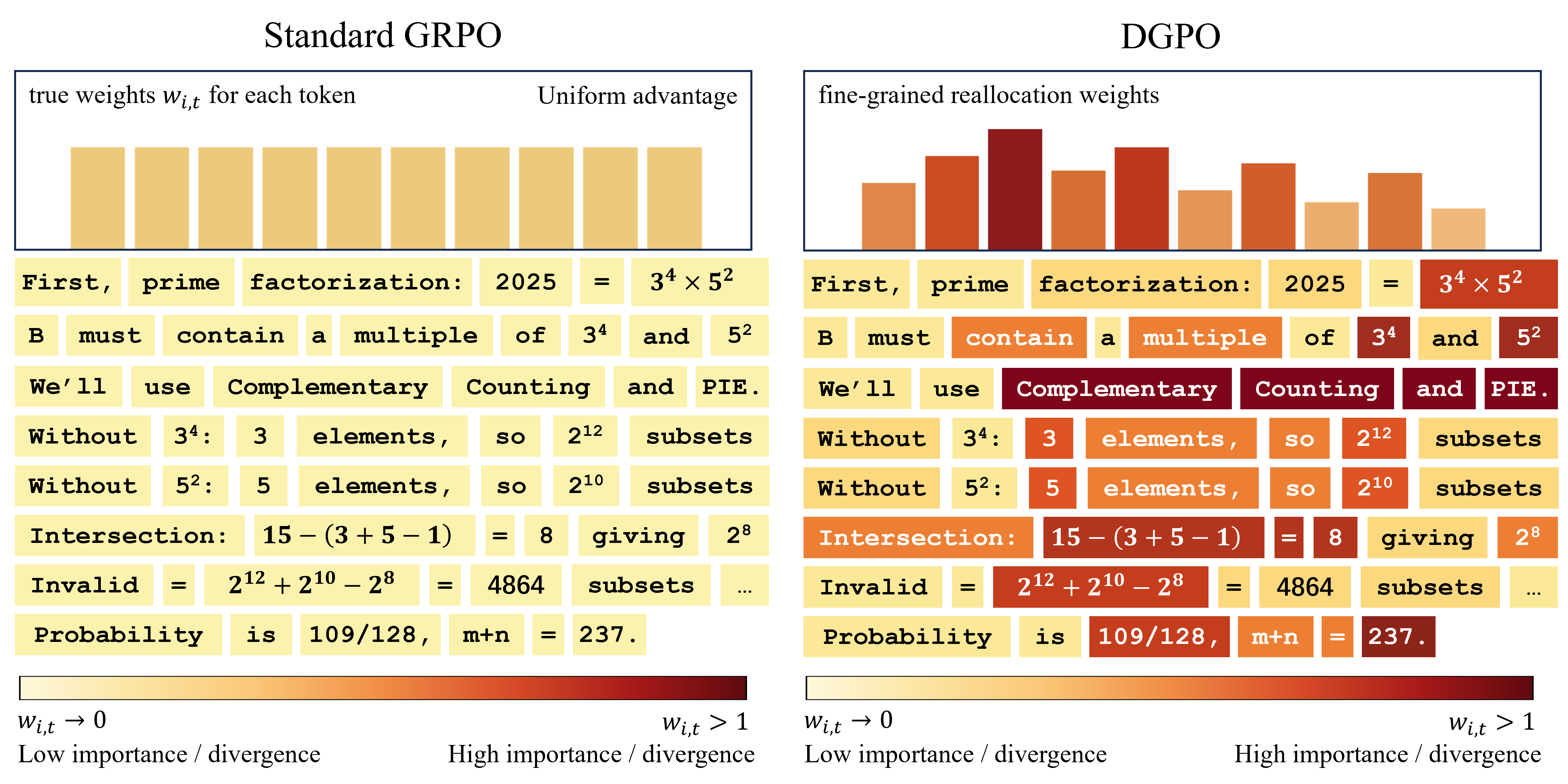
- The old way (GRPO): If the team solves a puzzle and gets a good score, you give the same pat on the back to every move they made during the whole game—even the boring passes. That’s called “coarse credit assignment,” and it wastes learning chances because the key brilliant moves don’t get extra attention.
- The new way (DGPO): You watch the full game and give bigger praise to the exact moves that actually led to success. You still give some credit to the rest, but much less. This is “fine-grained credit assignment.”
To do that, DGPO uses two key ideas:
- Measuring “interesting difference” safely
- The model has a “reference style” (like habits learned before). When it tries a new step that’s different from its old habits, that difference could be a good sign of discovery.
- Many older methods used a penalty called KL divergence to keep the model from drifting too far. But KL can blow up (become huge) when the model tries very new things, which makes training unstable and makes the model “play it safe.”
- DGPO replaces KL with the Hellinger distance. You can think of Hellinger as a safer, bounded meter from 0 to 1 that says “how different is this step from what you’d usually do?” Since it’s bounded, it won’t explode and crash training.
- Filtering out “fake innovations” with uncertainty (entropy gating)
- Not every different step is smart—some are just confident mistakes.
- DGPO checks how unsure the model is when it makes a step. Uncertainty (called “entropy”) is higher when the model knows it might be exploring.
- If a step is both different (by Hellinger distance) and the model was unsure/curious when making it (high entropy), DGPO rewards it more.
- If a step is different but the model is overly confident about a wrong choice (low entropy), DGPO down-weights it. This avoids reinforcing “confident nonsense.”
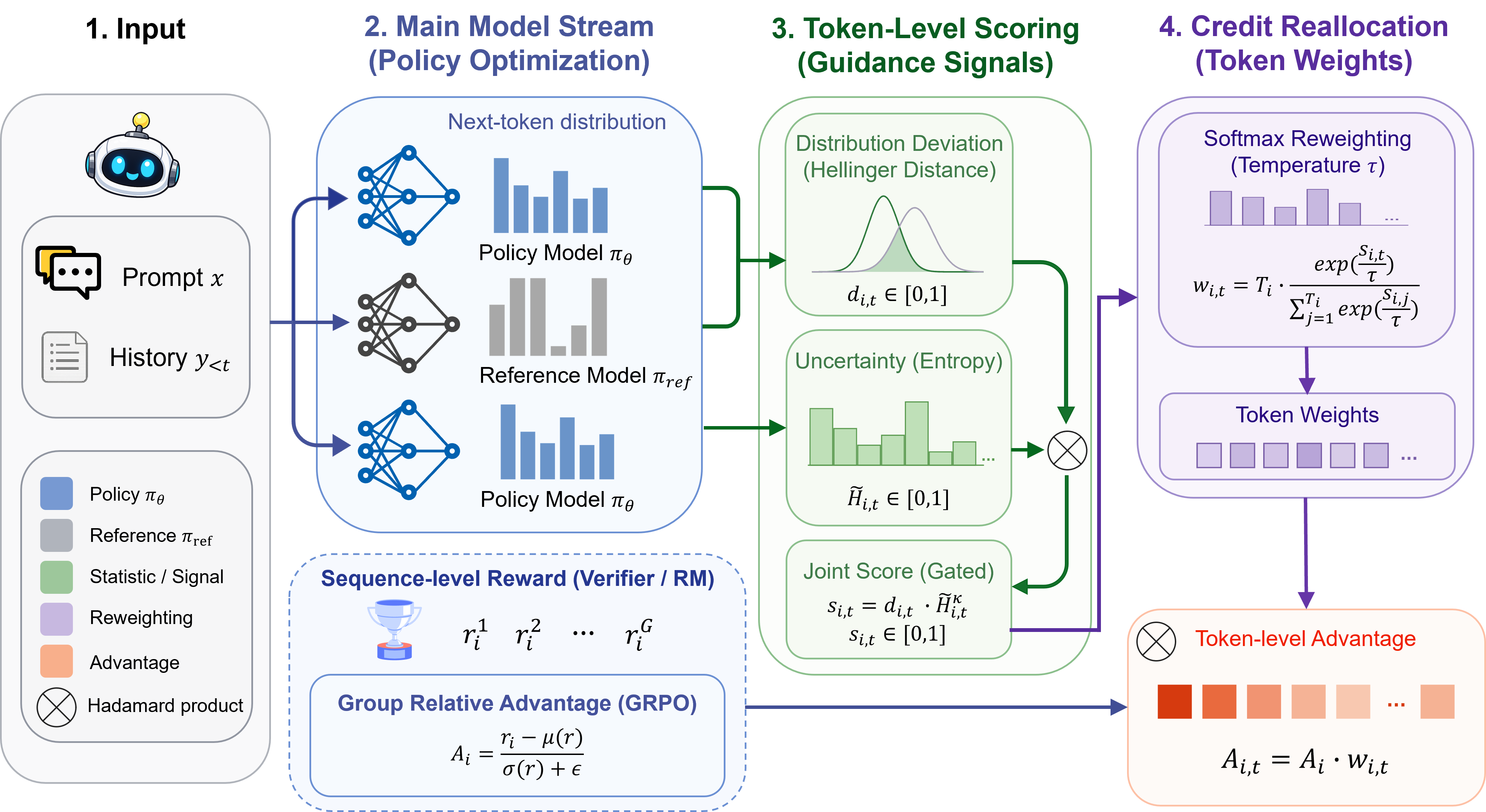
Putting it together
- The model first gets a single overall reward for the whole answer (like “final answer correct or not”).
- DGPO then redistributes that reward to each token (word piece) based on “difference × uncertainty,” so the truly helpful, exploratory steps get the biggest boost.
- Importantly, it does this without adding a separate “critic” network, keeping training light and efficient.
What the researchers found and why it matters
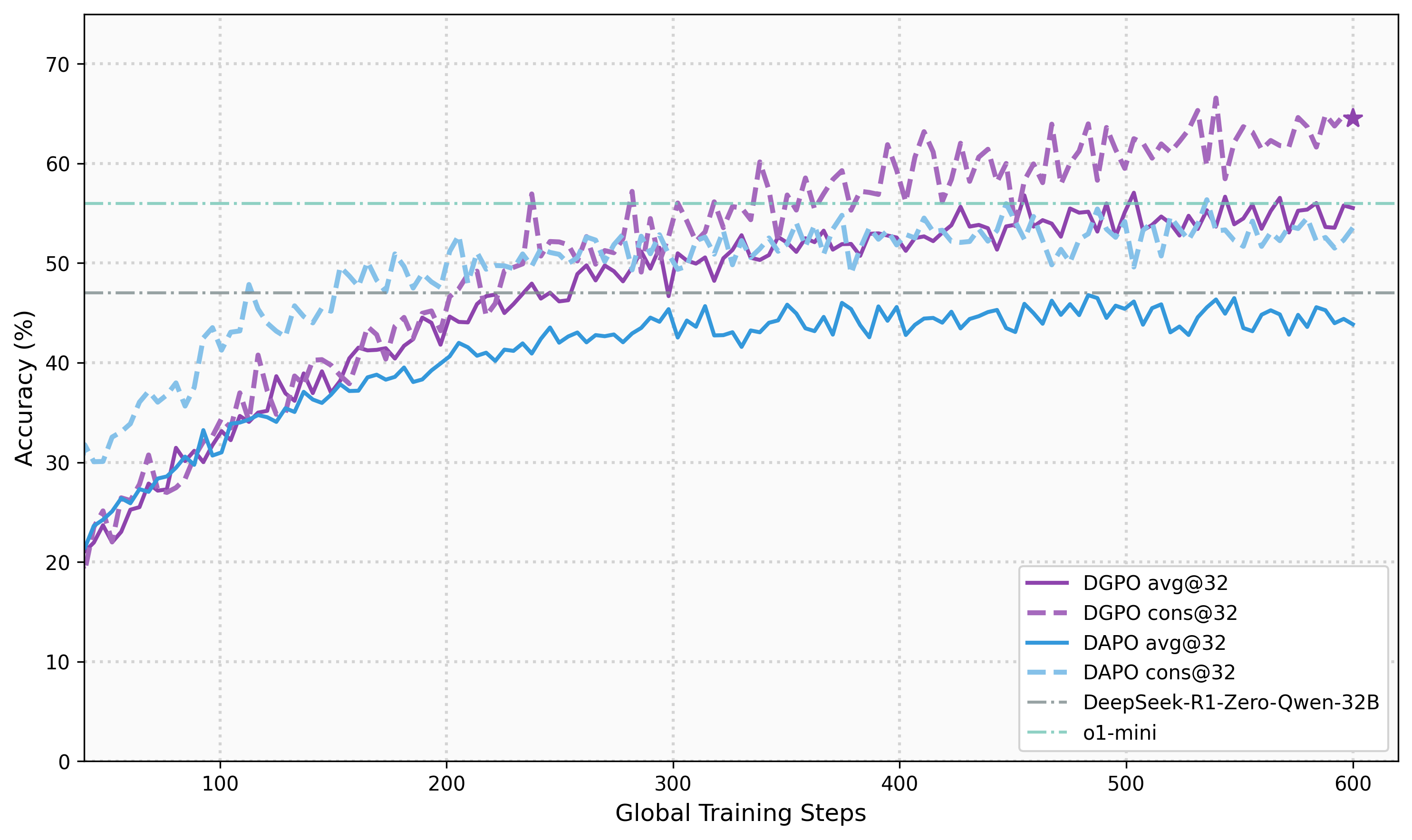
Here are the key results (on tough math benchmarks called AIME 2024 and AIME 2025, where models must reason step by step):
- On a large 32B-parameter model (Qwen2.5-32B-Base):
- AIME 2024: DGPO reached 60.0% Avg@32 accuracy (better than strong baselines like DAPO).
- AIME 2025: DGPO reached 46.0% Avg@32 accuracy (again beating baselines).
- On a smaller 7B model (Qwen2.5-7B-Math), DGPO also clearly improved results over older methods.
- Stability and efficiency:
- Training stayed stable because Hellinger distance is bounded (no “exploding penalties”).
- It remained memory- and speed-efficient, with only about 3.6% extra time compared to the baseline method, and no extra “critic” network needed.
- Ablation tests (turning parts off to see what matters) showed:
- Removing the entropy gate (the uncertainty filter) hurt performance.
- Switching back to the old KL penalty also hurt performance.
- This proves both parts—Hellinger distance and entropy gating—are important.
Why this matters: Teaching models which exact steps were helpful makes them learn smarter and faster. It also encourages safe exploration, so models can discover better reasoning paths without getting “scared” by harsh penalties. That means stronger problem-solving, especially on long, tricky tasks.
What this could change in the future
- Better reasoning: DGPO helps models focus their learning on the critical parts of their own thinking, which can lead to more accurate and reliable step-by-step solutions in math, science, coding, and more.
- Safer exploration: By rewarding useful novelty and filtering out confident mistakes, models can innovate without going off the rails.
- Practical training: Because DGPO is “critic-free” (no extra heavy network) and stable, it can be used at scale without huge computing costs.
- Broad impact: The same ideas—fine-grained credit, safe difference measures, and uncertainty-aware rewards—could improve many kinds of long-horizon AI tasks, from tutoring to planning to complex problem-solving.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions left unresolved by the paper that future work could address:
- Missing formal guarantees: No convergence, monotonic improvement, or regret bounds are provided for DGPO under token-level reweighting; derive theoretical guarantees and characterize conditions under which DGPO improves expected return.
- Divergence choice unexamined: Hellinger distance is motivated but alternatives within the α-divergence family (e.g., Jensen–Shannon, Renyi, χ²) are not compared; systematically evaluate which divergences and α values yield the best stability–exploration trade-off.
- Incomplete gradient analysis: The main text offers an approximate gradient argument; provide full derivations (including variance bounds) and empirical gradient-norm distributions to substantiate stability claims across training regimes.
- Entropy gating semantics: “Epistemic” uncertainty is approximated with predictive entropy, which conflates epistemic and aleatoric uncertainty; evaluate calibrated epistemic proxies (ensembles, MC-dropout, temperature scaling, ECE/Brier) and their impact on credit assignment.
- Gating formulation inconsistency: The paper alternates between s_{i,t} = d_{i,t}·H and s_{i,t} = d_{i,t}·Ĥ{κ}; clarify the exact functional form, normalization of entropy, and the role of κ in the main method and release precise implementation details.
- Behavior under negative advantages: Token reweighting amplifies positive and negative advantages alike; analyze whether concentrating negative A_i induces destructive updates at certain positions and propose safeguards (e.g., asymmetric weighting or floor/ceiling).
- Bias toward high-entropy tokens: Entropy gating may systematically prioritize syntactically ambiguous positions over semantically pivotal ones; quantify this bias and explore semantics-aware gating (e.g., attention/attribution, token type, step detectors).
- Off-policy bias and unbiasedness: Theoretical properties of per-token advantage redistribution combined with importance sampling and clipping (ε_c) are not analyzed; assess bias/variance effects and derive conditions for unbiased credit assignment.
- Reference policy design: The choice, update schedule, and anchoring strength of π_ref are under-specified; study fixed vs. slowly-updated references, drift control, and their effect on mode collapse and generalization.
- Eliminating token-level KL: Removing explicit KL regularization may permit distributional drift; evaluate long-run alignment, catastrophic forgetting, and safety/factuality degradation on out-of-domain prompts without KL anchoring.
- Robustness to noisy/mis-specified rewards: Results rely on clean, rule-based math verifiers; test DGPO under noisy human feedback, pairwise preference rewards, or adversarial reward misspecification to probe reward hacking resilience.
- Domain generalization: Evaluation is confined to AIME math; assess transfer to coding, scientific reasoning, open-domain QA, multi-hop fact checking, tool-use, and long-context tasks to establish breadth.
- Model/architecture diversity: Experiments focus on Qwen2.5 (32B base, 7B-Math); replicate on other families (Llama, Mixtral, Mistral, DeepSeek) and instruction-tuned vs. base checkpoints to test architectural robustness.
- Scaling behavior and cost: Throughput and memory overhead are profiled for 7B only; report full profiling at 32B+ scales, break down costs of Hellinger/entropy computations, and explore low-rank or sampled-vocab approximations for very large vocabularies.
- Group size and batch design: DGPO uses G=16 and large global batches; analyze sensitivity to G, trade-offs between group normalization variance and learning signal, and sample-efficiency vs. compute cost.
- Hyperparameter automation: τ and κ require tuning; develop adaptive/learned schedules (e.g., entropy- or variance-adaptive τ, κ) and provide principled defaults that generalize across tasks/models.
- Sequence-length effects: Weight normalization multiplies by T_i to keep mean weight 1; study whether this induces length bias, verbosity, or stability issues on very long CoT and propose length-aware normalization if needed.
- Tokenization dependence: Deviation is computed per token; examine sensitivity across tokenizers (BPЕ variants, sentencepiece) and whether subword granularity distorts deviation signals or credit assignment.
- Safety and harmful content: Exploration encouraged by deviation may increase unsafe/toxic outputs; measure toxicity, jailbreak susceptibility, and propose safety-aware gating or constraints.
- Compatibility with PRMs: DGPO is proposed as PRM-free; test hybrid variants that combine DGPO with lightweight/noisy PRMs or weak step verifiers to quantify complementary gains.
- Interaction with sampling policies: Training-time decoding strategy (temperature, top-k/p) and its interaction with DGPO’s exploration are not detailed; study how sampling controls affect stability and final performance.
- Statistical robustness: Results are reported as point estimates without variance across seeds; provide multiple seeds, confidence intervals, and significance tests, especially for close baselines (e.g., FIPO).
- Verifier brittleness and partial credit: Math evaluation uses exact-answer rewards; explore partial-credit or step-consistency rewards and assess DGPO’s behavior with graded/soft rewards and verifier errors.
- General capabilities retention: Post-RL effects on non-math tasks (instruction following, summarization, general QA) are not measured; evaluate catastrophic forgetting and multi-domain alignment retention.
- Temporal attribution limits: DGPO reweights local tokens but does not model long-range causal attributions; compare to counterfactual or credit-assignment methods (e.g., influence functions, hindsight relabeling) for steps whose impact manifests much later.
- Implementation clarity and reproducibility: Several equations (e.g., Hellinger distance, ρ_{i,t}) contain typos/missing brackets; provide a formal algorithm box, exact normalization constants, and release code to ensure faithful reproduction.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now, leveraging DGPO’s critic-free, token-level credit assignment, bounded Hellinger divergence, and entropy gating.
- Industry (AI/Software): Drop-in RLHF optimizer replacing GRPO/PPO for reasoning-heavy fine-tuning
- What: Integrate DGPO into existing RLHF pipelines to improve stability and exploration for long-chain reasoning without a critic network.
- Tools/Workflows: DGPO trainer module (Hellinger distance + entropy gate), hooks for group sampling, token-level advantage reweighting; integration with DeepSpeed/TRL/vLLM.
- Assumptions/Dependencies: Availability of a reference policy, outcome verifiers/reward models, access to token logits from current and reference models.
- Education: Higher-accuracy math tutors and exam prep assistants with step-by-step solutions
- What: Fine-tune math tutoring LLMs using DGPO to prioritize pivotal reasoning steps, improving correctness and clarity of explanations.
- Tools/Workflows: Outcome-verifier rewards (answer checkers, symbolic calculators), token-level heatmaps for teacher oversight.
- Assumptions/Dependencies: Reliable verifiers for problem classes; curated math corpora.
- Software Engineering: Code generation and code review improved by unit-test rewards
- What: Use DGPO with unit-test pass rates as outcome rewards to reinforce critical code tokens and reasoning chains, reducing regressions and “clever but wrong” code.
- Tools/Workflows: CI-style RL harness (sandboxed tests), token-level importance visualization to flag risky edits.
- Assumptions/Dependencies: High-quality, fast test suites; reproducible build environments.
- Scientific and Technical Reasoning Assistants: Symbolic math, equation manipulation, and derivation checking
- What: Train LLMs to produce reliable derivations with DGPO, using CAS/verifier outcomes to guide fine-grained credit assignment.
- Tools/Workflows: SymPy/NumPy verifiers; token-level attention to substitutions/deductions; iterative RL self-correction.
- Assumptions/Dependencies: Task-specific verifiers (e.g., symbolic simplification), domain datasets.
- Enterprise Knowledge Workflows: Hallucination-suppressing reasoning for customer support and knowledge assistants
- What: Combine DGPO’s entropy gating with outcome checks (e.g., retrieval-augmented fact verifiers) to discourage confident, low-entropy wrong steps while preserving exploration where uncertain.
- Tools/Workflows: RAG pipelines with factuality verifiers; dashboards for token-level “risk hot spots.”
- Assumptions/Dependencies: Accurate retrieval and factuality checks; domain knowledge bases.
- Training Efficiency for Smaller Labs: Stable long-sequence alignment without a critic network
- What: Use DGPO to enable resource-constrained teams to train 7B-class models for reasoning tasks with GRPO-like memory footprint and marginal overhead.
- Tools/Workflows: Two-model-forward setup (policy + reference), group sampling (e.g., G≈8–16); ZeRO-3-compatible training.
- Assumptions/Dependencies: Access to GPUs capable of handling group sampling; outcome rewards available.
- Dataset Curation & Interpretability: Token-level “pivotal step” mining and visualization
- What: Use DGPO’s redistributed token weights to identify and export decisive steps for dataset pruning, curriculum design, or teacher-forcing scripts.
- Tools/Workflows: Heatmaps of token importance; automatic extraction of “key-step” snippets; logging for audit trails.
- Assumptions/Dependencies: Correlation between importance weights and true reasoning salience; logging infrastructure.
- Academia (RL/NLP Research): Safer divergence control for exploration in RLHF
- What: Replace reverse-KL with bounded Hellinger in experiments to avoid mode-seeking collapse and gradient spikes; test across reasoning benchmarks.
- Tools/Workflows: Ablations on divergence choices; reproducible training scripts; visualization of gradient norms.
- Assumptions/Dependencies: Availability of outcome verifiers; comparable baselines for fair evaluation.
- Legal and Policy Drafting Assistants: Process-consistent long-form reasoning with reduced instability
- What: Apply DGPO to long-form reasoning tasks (e.g., legal argumentation), guided by rule-based checkers (structure, citation presence) as outcome signals.
- Tools/Workflows: Rule-based verifiers for structure/compliance; token-level auditing of argument transitions.
- Assumptions/Dependencies: Proxy rewards approximate quality (structure, citation adherence rather than legal correctness); human-in-the-loop validation.
- Quality Assurance and Monitoring: “Exploration meter” and stability dashboards for RLHF
- What: Operational metrics driven by Hellinger distance and entropy gating to monitor exploration vs. conservatism during training.
- Tools/Workflows: Training dashboards tracking bounded divergence, entropy distributions, and token weight concentration.
- Assumptions/Dependencies: Monitoring hooks and logging; thresholds tuned to domain/task.
Long-Term Applications
These opportunities require further research, scaling, domain-specific verifiers, or productization.
- Healthcare: Process-supervised clinical reasoning and decision support
- What: Deploy DGPO to train clinical assistants that prefer verifiable reasoning chains (e.g., differential diagnosis) with entropy-gated exploration.
- Tools/Workflows: Outcome verifiers tied to guidelines (e.g., care pathways), simulators, or retrospective datasets; token-level audit trails for clinicians.
- Assumptions/Dependencies: Strong, reliable medical verifiers; regulatory approvals; rigorous bias/safety evaluation.
- Finance: Risk modeling and compliance assistants with verifiable reasoning
- What: Apply DGPO to long-horizon financial analyses (stress scenarios, compliance checks), steering away from confident but spurious steps.
- Tools/Workflows: Rule-based compliance verifiers; backtesting frameworks as reward sources.
- Assumptions/Dependencies: High-fidelity simulators and evaluation datasets; risk controls and human oversight.
- Robotics and Planning: Long-horizon plan generation with token/action-level credit assignment
- What: Extend DGPO’s fine-grained credit reallocation to action sequences in planning agents (task decomposition, manipulation/locomotion strategies).
- Tools/Workflows: Simulators providing outcome rewards (success/failure metrics), uncertainty-aware exploration gates.
- Assumptions/Dependencies: Mapping tokens to actions; high-quality simulators; sample-efficiency improvements.
- Multimodal Reasoning: Vision-language and agentic pipelines
- What: Use DGPO to align multimodal chains (image → plan → action/explanation) while bounding divergence-driven exploration to stabilize training.
- Tools/Workflows: Outcome verifiers (e.g., VQA checkers, scene-graph consistency); token-/step-level credit visuals across modalities.
- Assumptions/Dependencies: Multimodal reward models; engineering support for cross-modal logits/entropy computation.
- Process Reward Model (PRM) Distillation: Self-supervised step labeling from DGPO signals
- What: Use DGPO’s token-level importance weights to generate pseudo-labels for PRMs, reducing human annotation load.
- Tools/Workflows: Offline mining of pivotal steps; PRM training pipelines; subsequent RL that combines PRM + outcome rewards.
- Assumptions/Dependencies: Empirical validation that weights align with correctness; filtering heuristics to avoid reinforcing spurious tokens.
- Personalization and On-Device Adaptation: Privacy-preserving alignment with bounded divergence
- What: Employ DGPO for lightweight, on-device preference tuning (e.g., reasoning style), balancing exploration with Hellinger constraints.
- Tools/Workflows: Federated RLHF variants; local outcome feedback (thumbs up/down) mapped to sequence-level rewards.
- Assumptions/Dependencies: Sufficient on-device compute; privacy-preserving verifiers; robust safety filters.
- Controllable Reasoning Style: User-facing “reasoning knobs” for creativity vs. conservatism
- What: Expose DGPO hyperparameters (temperature τ, entropy scaling κ) as product controls to adjust exploration intensity.
- Tools/Workflows: App-level sliders; telemetry to adapt defaults per domain/task.
- Assumptions/Dependencies: UX research; safeguards against unsafe exploration in sensitive tasks.
- Standards and Governance: Safer divergence constraints for RLHF guidelines and audits
- What: Incorporate bounded divergences (e.g., Hellinger) and token-level credit attribution into industry standards for RLHF stability and auditability.
- Tools/Workflows: Benchmark suites; audit protocols capturing divergence, entropy, and token weight logs.
- Assumptions/Dependencies: Community and regulatory adoption; cross-organization replicability.
- Automated Curriculum and Data Generation: Iterative self-improvement loops
- What: Use token-level signals to select or synthesize training samples focusing on weak steps, creating adaptive curricula for reasoning.
- Tools/Workflows: Step-difficulty mining; sample generation pipelines; bandit-like selection policies.
- Assumptions/Dependencies: Robustness of step mining; prevention of curriculum overfitting.
- Program Synthesis and Compiler Optimization: Rewarding pivotal code transformations
- What: Apply DGPO with compiler/test rewards to identify and reinforce critical transformations in synthesis/optimization.
- Tools/Workflows: Build-and-test reward harnesses; token-level analysis to guide further search.
- Assumptions/Dependencies: Deterministic, high-signal rewards; secure sandboxing; large, diverse code corpora.
- Energy and Infrastructure Planning: Long-horizon plan generation under simulator feedback
- What: Train planning LLMs with DGPO using simulator outcomes (grid stability, cost) to credit pivotal plan steps and discourage brittle heuristics.
- Tools/Workflows: Domain simulators as rewarders; uncertainty-aware exploration and scenario analysis.
- Assumptions/Dependencies: Accurate simulators; interdisciplinary validation; alignment with regulatory constraints.
In all cases, DGPO’s feasibility depends on having reliable outcome rewards or verifiers, a suitable reference policy for divergence computation, and engineering support to surface token-level signals for training and monitoring. Domain transfer beyond math benchmarks will require careful reward design, calibration of entropy gating, and thorough safety evaluation.
Glossary
- Advantage: In policy gradient RL, the relative benefit of an action compared to a baseline; used to scale updates. "a single scalar advantage is uniformly broadcasted across the entire generated sequence"
- alpha-divergence (α-divergence): A family of f-divergences generalizing measures like KL; used to compare probability distributions. "bounded Hellinger distance (an -divergence)"
- Autoregressive: A modeling setup where tokens are generated sequentially, each conditioned on previous tokens. "uniquely exacerbated in autoregressive LLMs"
- Avg@32: Average Pass@1 accuracy measured over 32 independent samples per problem. "Avg@32 accuracy"
- Behavior policy: The policy that generated the data used for importance sampling in off-policy updates. "behavior policy"
- Chain-of-Thought (CoT): A prompting/generation strategy where models produce explicit intermediate reasoning steps. "long-horizon Chain-of-Thought (CoT) behaviors"
- Cons@32: Consensus accuracy computed via majority vote across 32 samples. "Cons@32"
- Credit assignment: Determining which actions or tokens contributed to a reward in sequential decision-making. "coarse-grained, sequence-level credit assignment"
- Credit reallocation: Redistributing sequence-level advantage to token-level signals based on importance. "fine-grained credit reallocation"
- Critic-free: RL methods that do not use a learned value (critic) network for advantage estimation. "critic-free reinforcement learning framework"
- DAPO: A baseline critic-free RL method for LLM alignment used for comparison. "substantially outperforming competitive baselines like DAPO"
- Distribution deviation: The difference between current and reference policy distributions used as a guidance signal. "reinterprets distribution deviation as a guiding signal"
- Entropy gating mechanism: A weighting scheme that scales deviation signals by policy entropy to filter spurious deviations. "policy entropy gating mechanism"
- Epistemic uncertainty: Uncertainty arising from limited knowledge or data, often proxied by entropy in model outputs. "the policy's epistemic uncertainty"
- Gradient instability: Large, volatile gradients during training that can derail optimization. "severe gradient instability"
- Group Relative Policy Optimization (GRPO): A critic-free RL algorithm that normalizes rewards within groups to compute advantages. "Group Relative Policy Optimization (GRPO)"
- Hellinger distance: A bounded divergence metric between distributions, used here to stabilize exploration. "bounded Hellinger distance"
- Importance sampling ratio: The likelihood ratio between current and behavior policies used to correct off-policy updates. "importance sampling ratio"
- Kullback-Leibler (KL) divergence: A measure of dissimilarity between probability distributions; commonly used as a regularizer. "Kullback-Leibler (KL) divergence penalty"
- Mode-seeking conservatism: A tendency of some divergences (e.g., reverse KL) to overly favor high-probability modes of the reference, hindering exploration. "mode-seeking conservatism"
- Outcome Reward Models (ORMs): Reward models that evaluate only final outcomes rather than intermediate steps. "Outcome Reward Models (ORMs)"
- Pass@1: The probability that a single sample yields a correct solution. "Pass@1"
- Pass@32: The probability that at least one of 32 samples is correct. "Pass@32"
- Process Reward Models (PRMs): Models that assign rewards to intermediate reasoning steps rather than only final answers. "Process Reward Models (PRMs)"
- Proximal Policy Optimization (PPO): A policy gradient RL algorithm that uses clipping and (often) a critic network. "Proximal Policy Optimization (PPO)"
- Reference policy: A fixed or slowly changing policy used for regularization and comparison during training. "reference policy "
- Reverse KL divergence: KL divergence with arguments swapped (KL[p||q] vs KL[q||p]), which can be mode-seeking. "Reverse KL divergence"
- Sequence-level advantage: An advantage scalar computed for an entire generated sequence rather than per token. "sequence-level advantage"
- Shannon entropy: An information-theoretic measure of uncertainty in a probability distribution. "Shannon entropy"
- Softmax: A normalization function that converts logits to probabilities; also used to weight token-level scores. "temperature-scaled softmax"
- Temperature (τ): A scaling factor controlling the sharpness of softmax distributions or sampling diversity. "temperature hyperparameter"
- Top-p threshold: The cumulative probability cutoff in nucleus sampling controlling sampling diversity. "top-p threshold of 0.7"
- Value network: A learned function estimating expected returns, used by actor-critic methods but omitted in critic-free setups. "auxiliary value network"
- Z-score normalization: Standardizing values by subtracting the mean and dividing by the standard deviation; used for group-wise rewards. "group-wise Z-score normalization"
Collections
Sign up for free to add this paper to one or more collections.

