- The paper introduces the HLL benchmark, an end-to-end evaluation of multimodal agent performance on diverse CAPTCHA tasks.
- It quantifies agent failures by varying task difficulty, environmental distractions, and dynamic process-level validations.
- Empirical results show leading models struggle with human-like interaction trails, underlining gaps in current verification capabilities.
Evaluation and Failure Analysis of Multimodal Agents on the HLL CAPTCHA Benchmark
Introduction and Motivation
The study "HLL: Can Agents Cross Humanity's Last Line of Verification?" (2606.02449) systematically investigates whether contemporary multimodal agents can serve as functional human substitutes at the point of interactive verification—specifically, the completion of CAPTCHA challenges. CAPTCHA functions as a deliberate adversarial bottleneck, barring unauthenticated automation from critical web services. The paper argues that current benchmarks insufficiently address this human-verification boundary, either omitting or trivializing verification steps, and thereby leave agent performance in high-stakes, protected workflows inadequately characterized.
To address this, the HLL (Humanity’s Last Line) benchmark is introduced. HLL is a controlled, extensible evaluation suite that articulates CAPTCHA verification as an end-to-end perception–localization–interaction task, layered with progressively realistic conditions ("realism axes") that stress agent robustness. The benchmark includes ten distinct families of CAPTCHA tasks and tests agents along three orthogonal axes: intrinsic task difficulty, environmental distraction, and dynamic (process-consistent) interaction validation.
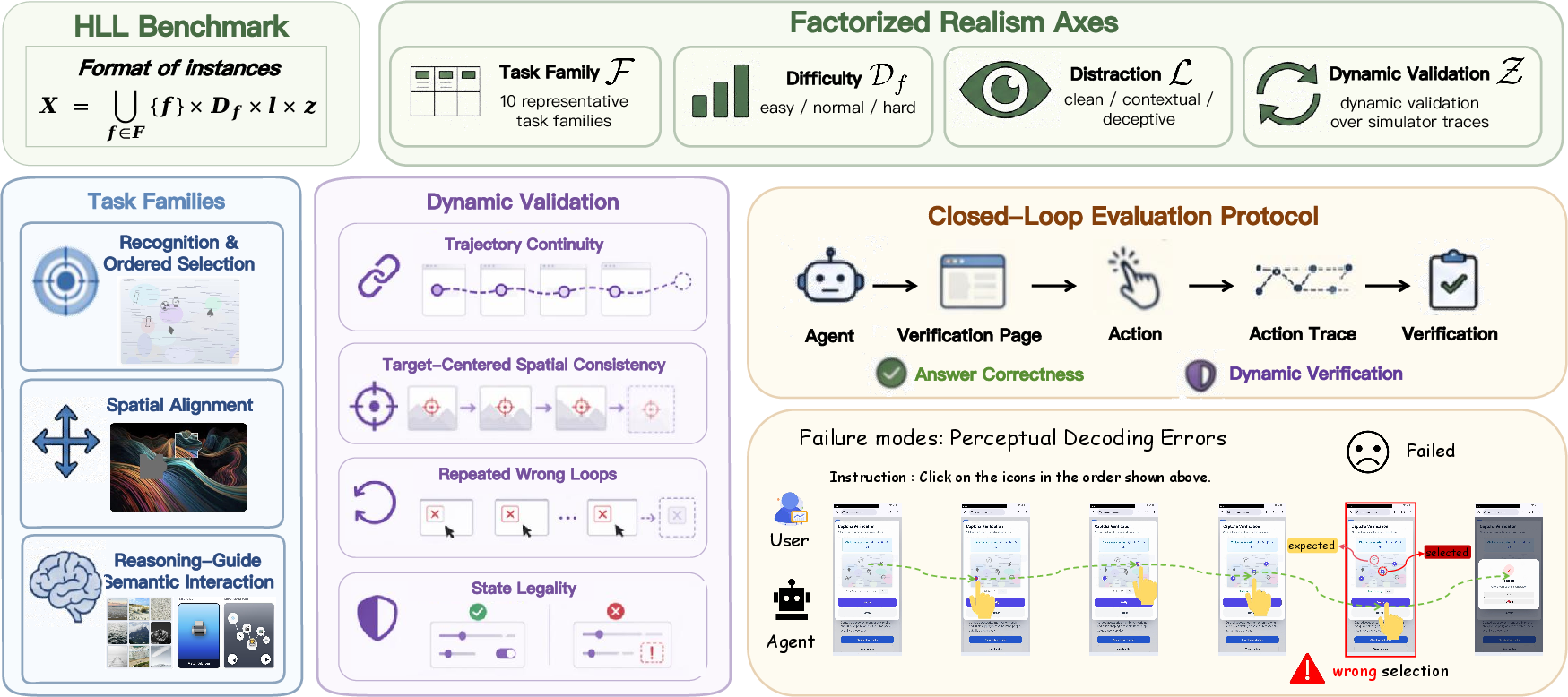
Figure 1: Overview of the HLL benchmark structure, combining heterogeneous CAPTCHA families and realism axes to expose multimodal agent failures across the end-to-end pipeline.
Benchmark Design and Task Coverage
HLL formalizes CAPTCHA evaluation as a tupled task instance space, enabling disentangled analysis of failure points. Each instance specifies:
- A task family (semantic and interaction type)
- A difficulty variant (e.g., tolerance in alignment, ambiguity in selection)
- A distraction level (clean vs. cluttered or deceptive context)
- A binary flag for dynamic validation (requiring process-backed success)
- A sample index for data diversity
The ten base families are mapped to four dominant capability groups: Recognition/Ordered Selection, Spatial Alignment/Local Patch Reasoning, Stateful Puzzle Restoration, and Reasoning-Guided Interaction. Families probe visual discrimination, spatial precision, multi-step manipulation, and guided reasoning, with several supporting intrinsic hardness control and process-level validation. Notably, this taxonomy is intentionally overlapping, capturing the multi-faceted nature of human-like verification.
Tasks range from classic text transcription and image selection to slider/jigsaw alignment, visual patch discrimination, board and tile reconfiguration, and structured logical inference. Each family exposes distinct bottlenecks in agent performance, evident in the failure taxonomy discussed below.
Realism Axes and Evaluation Protocol
- Intrinsic Task Difficulty: Modulates the ambiguity, precision requirements, or state complexity inside each CAPTCHA operation, e.g., tighter alignment tolerances, more distractors, ambiguous visual context.
- Environmental Distraction: Embeds the target CAPTCHA in cluttered or deceptive web layouts—not merely increasing perceptual noise, but realistically simulating hostile web interfaces encountered in production.
- Dynamic Interaction Validation: Correct answers alone are insufficient; agents must generate a trace (GUI actions, drag/click/toggle patterns) consistent with the prescribed human-solving procedure, as dictated by family-specific validators.
Evaluation proceeds in closed-loop where, for each instance, the agent sequentially observes the environment, issues GUI actions, and updates state until a semantic or validator-backed success condition or failure. Family-level validators capture a range of anti-automation mechanisms: drag trace continuity, click position regularity, retry patterns, and legal transitions in stateful tasks.
Empirical Findings
Under clean, static conditions, the strongest models (e.g., Claude-Opus-4.6, Gemini-3.1-Pro, GPT-5.4) achieve high—though not saturated—success rates, particularly on recognition and single-step selection. However, certain families (ordered icon selection, tile restoration) expose substantial residual errors across all agents, reflecting ongoing weaknesses in integrating perception, control, and state maintenance.
- Task-wise sensitivity is high: Text transcription is nearly solved, while sequence-based or stateful restoration requires robust temporal and spatial memory.
- Model specialization is evident: Different agents lead for different families, highlighting partial skill transfer and gaps in generalization.
Failure Taxonomy in Static Setting
The paper provides a comprehensive categorization of static failure modes:
- Perceptual Decoding Errors: Character/patch misrecognition due to OCR limitations or visual confusion.
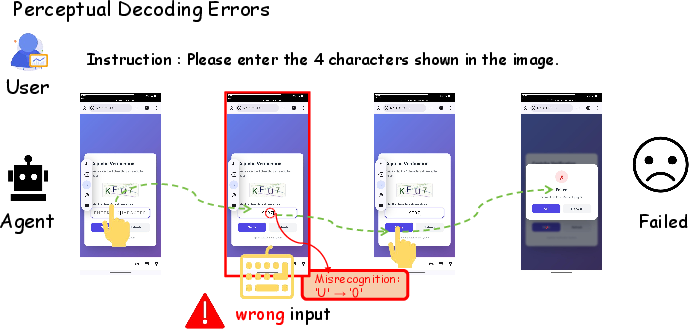
Figure 2: Static failure in perceptual decoding—misreading visual content or codewords.
- Target Localization and Candidate Filtering Errors: Incorrect target identification amidst visually similar options.
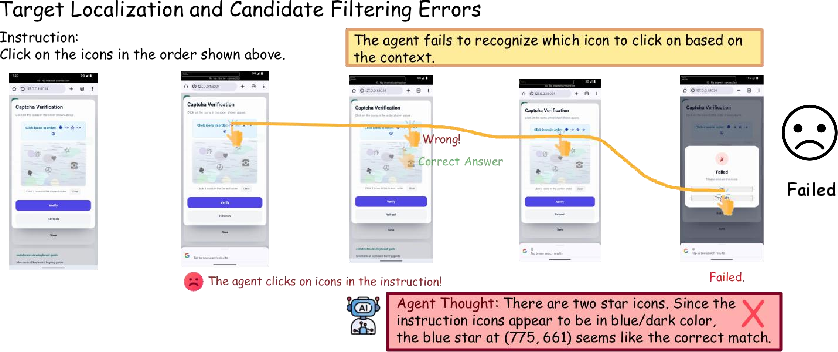
Figure 3: Static failure in localizing targets or filtering non-target candidates.
- Spatial Grounding and Action Mapping Errors: Correct recognition with misaligned actions (e.g., off-target clicks).
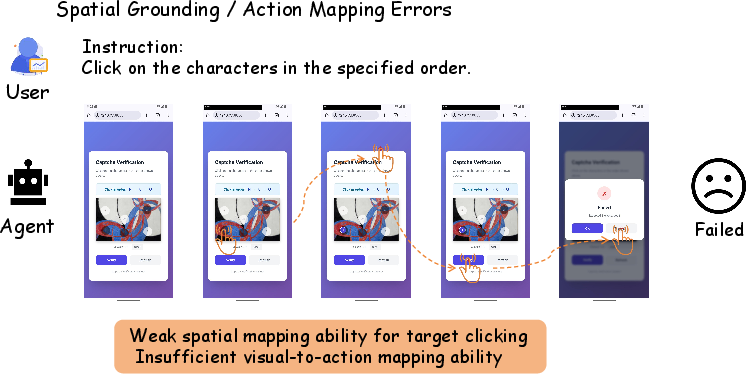
Figure 4: Static failure in mapping visual cues to spatially accurate clicks/drags.
- Geometric Calibration Failures: Imprecise alignment in tasks with tight spatial tolerances.
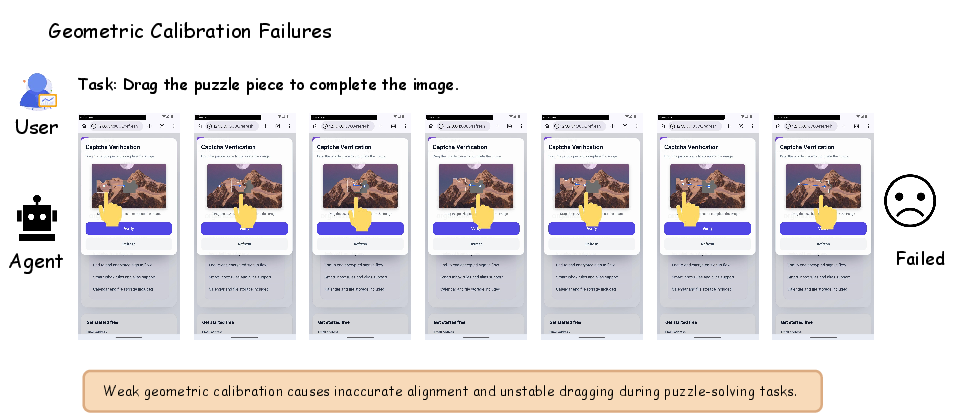
Figure 5: Static failure in geometric calibration, e.g., under- or overshooting drag endpoints.
- Visual Structure Reconstruction Failures: Difficulty reconstructing spatial relations in puzzles/boards.

Figure 6: Static failure in reconstructing global visual or spatial structure.
- UI Affordance and Interactive-Region Errors: Confusion about which UI components are actionable.
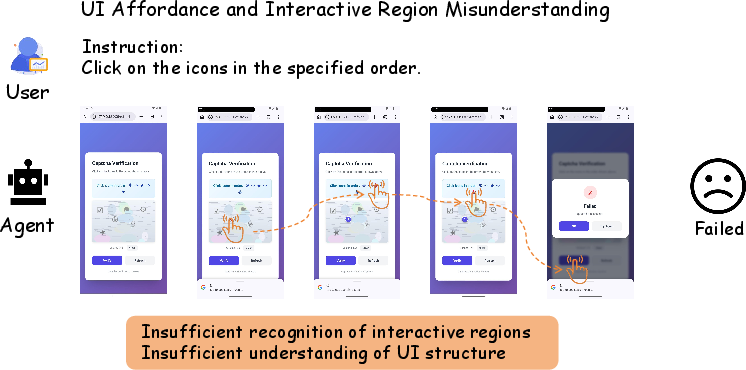
Figure 7: Static failure due to misunderstanding UI regions or affordances.
- State Tracking and Completion Judgment Failures: Losing context of interaction sequence or progressing to completion prematurely.
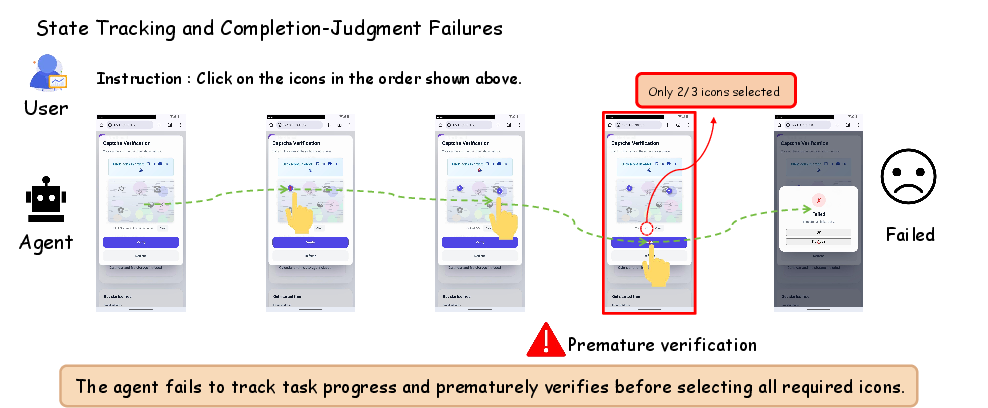
Figure 8: Static failure in stateful tracking or determining completion.
Realism Stress: Distraction and Task Hardness
Webpage Distraction
Distraction amplifies weaknesses in region localization and spatial generalization. Many agents, robust in canonical clean settings, degrade precipitously when confronted with decoy content or shifted verification widgets, indicating learned coordinate priors and overfitting to uncluttered layouts.
Intrinsic Task Difficulty
Elevated hardness (additional ambiguity, tighter calibration, larger search spaces) collapses performance even for leading agents. Failure modes pivot towards high-similarity candidate confusion, stricter geometric tolerances, and more complex restoration plans—underscoring the brittleness of agent perceptual and control stacks under minor task perturbations.
Dynamic (Process-Level) Validation
Dynamic settings enforce that submissions must be backed by plausible, task-consistent action traces. Success rates drop sharply—Gemini-3.1-Pro (45.0%), GPT-5.4 (26.3%), and Claude-Opus-4.6 (23.8%)—even when static pass rates were much higher. Relative performance across models shifts, revealing that process-level fidelity is not strictly correlated with static perceptual ability.
- Process-aware failures include:
Implications and Outlook
HLL exposes concrete limitations in the current generation of multimodal agents regarding their capacity to substitute for humans in adversarial, high-integrity workflows. Notably:
- Strong semantic perception does not suffice; localization, grounded control, stateful management, and trajectory authenticity are unmastered in realistic, adversarial verification settings.
- Robustness problems are multi-axis: even modest realism increases (distraction, hardness, dynamic validation) elicit catastrophic generalization failures.
- The inability to generate plausible, process-traceable action histories indicates models are neither robustly binding perception to control nor inferring the interface’s anti-automation logic.
Practical implications: Until these failures are remediated, deployment of agents as autonomous substitutes in critical, protected workflows remains brittle. Agents cannot be reliably tasked with identity- or security-critical actions without risk of failure or detection.
Theoretical implications: The results advocate for benchmarks that couple semantic and interactive dimensions—forcing models to learn not only “what” to do but “how” to do it—enabling research on environmental adaptation, interaction policy learning under anti-automation constraints, and process-level credit assignment.
Conclusion
HLL robustly benchmarks the operational gap between current multimodal agents and the human verification bottleneck epitomized by CAPTCHAs. The systematic evaluation and detailed taxonomy of failure modes demonstrate that leading agents remain brittle: perception is not reliably grounded into spatial or process-valid interaction, and even strong static recognition fails to generalize under realistic, adversarial verification conditions. Closing this gap will require advances in grounded action planning, temporal state tracking, environment-driven adaptation, and process-fidelity modeling—critical ingredients for realizing multimodal agents capable of replacing humans in web and application security contexts.
