- The paper introduces WindowsWorld, a benchmark with 181 tasks across 17 apps to evaluate autonomous GUI agents in realistic cross-application workflows.
- It employs a human-in-the-loop pipeline and checkpoint-based scoring to assess intermediate progress and final task success.
- Experimental findings reveal steep performance drops in multi-application, long-horizon tasks, highlighting challenges in context switching and error recovery.
WindowsWorld: A Process-Centric Benchmark for Cross-Application Autonomous GUI Agents
Motivation and Benchmark Design
WindowsWorld addresses a central deficiency of existing GUI agent benchmarks: the absence of systematic, process-centric evaluation of autonomous agents on realistic, professional multi-application workflows in desktop environments. Prior benchmarks, such as OSWorld and Windows Agent Arena, primarily focus on single-application tasks or short-horizon workflows, leading to inflated evaluation scores that obscure agents' deficiencies in context switching, cross-application information integration, and long-horizon planning. WindowsWorld explicitly targets these gaps by constructing a benchmark of 181 professionally grounded tasks spanning 17 desktop applications and 16 personas across five occupational categories. The task suite is structured into four difficulty levels, including deliberately infeasible instructions for negative constraint evaluation. Approximately 78% of tasks require multi-application coordination, a stark contrast to the distribution in prior works.
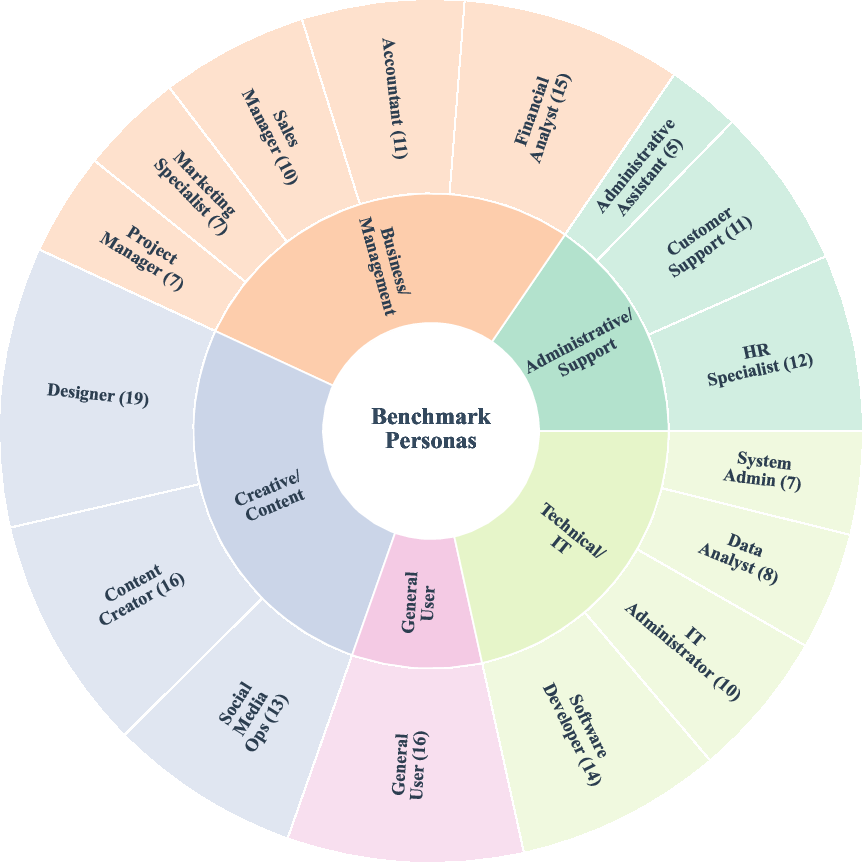
Figure 1: Left, distribution of applications and task counts; right, breakdown of 16 personas across 5 major professional domains.
Benchmark construction leverages a human-in-the-loop multi-agent pipeline. Task generation is seeded on persona-conditioned routines and application dependencies, refined by deduplication and semantic assurance modules, and culminates in human verification for instruction quality and ambiguity reduction. Task environments are synthesized via LLM-driven file scaffolding, ensuring all dependencies—like working documents, datasets, and download links—are programmatically provided.
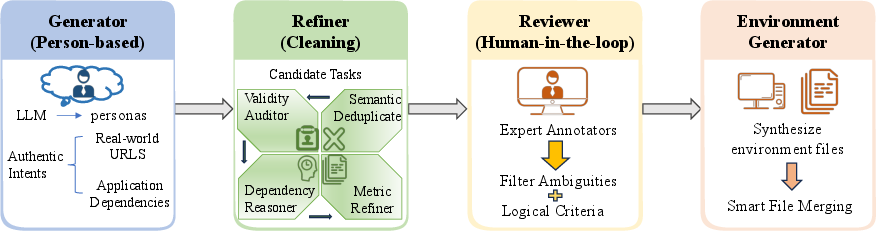
Figure 2: The overall architecture of the human-in-the-loop multi-agent pipeline for benchmark generation.
Task Taxonomy, Persona Specialization, and Evaluation Protocol
Tasks are classified on two axes—complexity and persona. L1 covers atomic single-app manipulations; L2 tasks require sequential multi-app workflows; L3 introduces dynamic, conditional reasoning across apps; L4 consists of infeasible or adversarial instructions. Each persona (e.g., Accountant, Creative Director, Software Engineer) grounds task content in realistic professional activity, further diversifying the operational context and UI interaction demands.
The evaluation protocol is process-centric. For each task, fine-grained intermediate checkpoints are defined and manually validated as path-essential, rather than trajectory-specific. This checkpoint-based assessment departs from the prevalent “all-or-nothing” final-state scoring, enabling reward for meaningful sub-goal achievement and supporting analysis of failure localization in long-horizon workflows.
Analysis of Benchmark Composition
WindowsWorld tasks exhibit significant diversity in both horizon length and application co-occurrence. Feasible tasks (L1–L3) require on average 5 sub-goals; the majority (71.8%) are multi-step and 77.9% engage at least two applications. Even after controlling for length by step-matching short L2 workflows to L1, cross-application tasks remain significantly more challenging, underscoring that the primary bottleneck lies in state transfer and context maintenance rather than step count alone.
Process-aware evaluation—facilitated by the integration of an LLM-based judge (Qwen3-VL-Plus)—demonstrates high reliability, with Pearson correlation scores exceeding 0.91 relative to human judgment on intermediate checkpoints. This enables robust automated scoring and facilities studies of both sub-goal and final-state competence.
Experimental Findings and Model Behavior
A spectrum of SOTA large multimodal models (e.g., Gemini-3-flash/pro, GPT-5.2, Claude-Sonnet 4.5, Qwen3-VL-Plus) and agent frameworks (Agent-S3, UiPath) are benchmarked. Performance is ablated across vision-only, set-of-mark (SoM), and hybrid (screenshot + accessibility tree) input modalities. Key results are as follows:
- Steep Drop in Multi-Application Performance: All evaluated models exhibit sharp decay in both intermediate and final-state scores with increasing task complexity. For Gemini-3-flash (Hybrid), Sint decreases from 67.5% (L1) to 38.6% (L3); Sfinal plummets from 35.9% (L1) to 16.7% (L3).
- Completion vs. Progress Gap: Even top-performing models like Gemini-3-flash (Hybrid) achieve only 20.4% terminal success rate across all task types, with up to a 30% gap between intermediate checkpoint completion and final task accomplishment.
- Failure on Negative Constraints and Infeasible Tasks: Agents perform unreliably on impossible/infeasible instructions (L4); e.g., GPT-5.2 (SoM) succeeds only 25% of the time in correctly rejecting unachievable tasks, indicating substantial hallucination risk.
- Independent Modality Impact: Structured hybrid inputs (visual + accessibility) improve grounding, while SoM overlays provide inconsistent benefit and sometimes degrade performance relative to raw screenshots, especially in coordinate localization.
- Persona-Dependent Outcomes: Analysis by persona category exposes a pronounced long-tail effect, with productivity and creative personas exhibiting larger progress–completion gaps attributable to global consistency challenges in document- and media-centric workflows.
Failure Modes and Trajectory Visualization
Detailed trajectory visualizations illustrate common error classes: (i) unreliable window focus, leading to spurious clipboard actions; (ii) pyautogui failures due to language/IME conflicts; and (iii) failures in content transfer across disparate app UI paradigms. These are typified by inefficient “drifting” executions—trajectories with extensive sub-goal progress but ultimate failure in global goal integration.
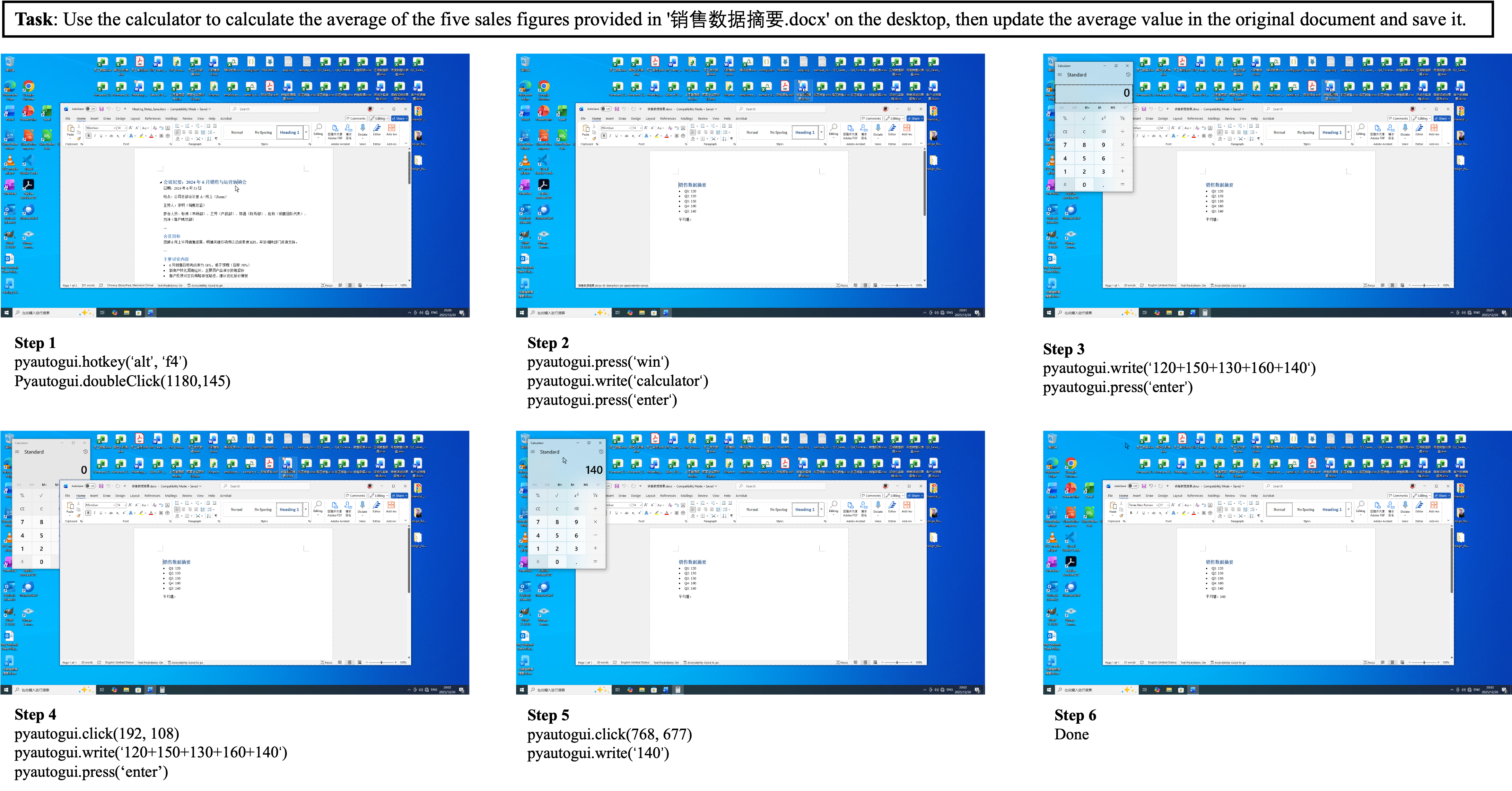
Figure 3: Example execution trace of a successful L1 multi-app task, showing agent GUI observation, action sequence, and state transitions.
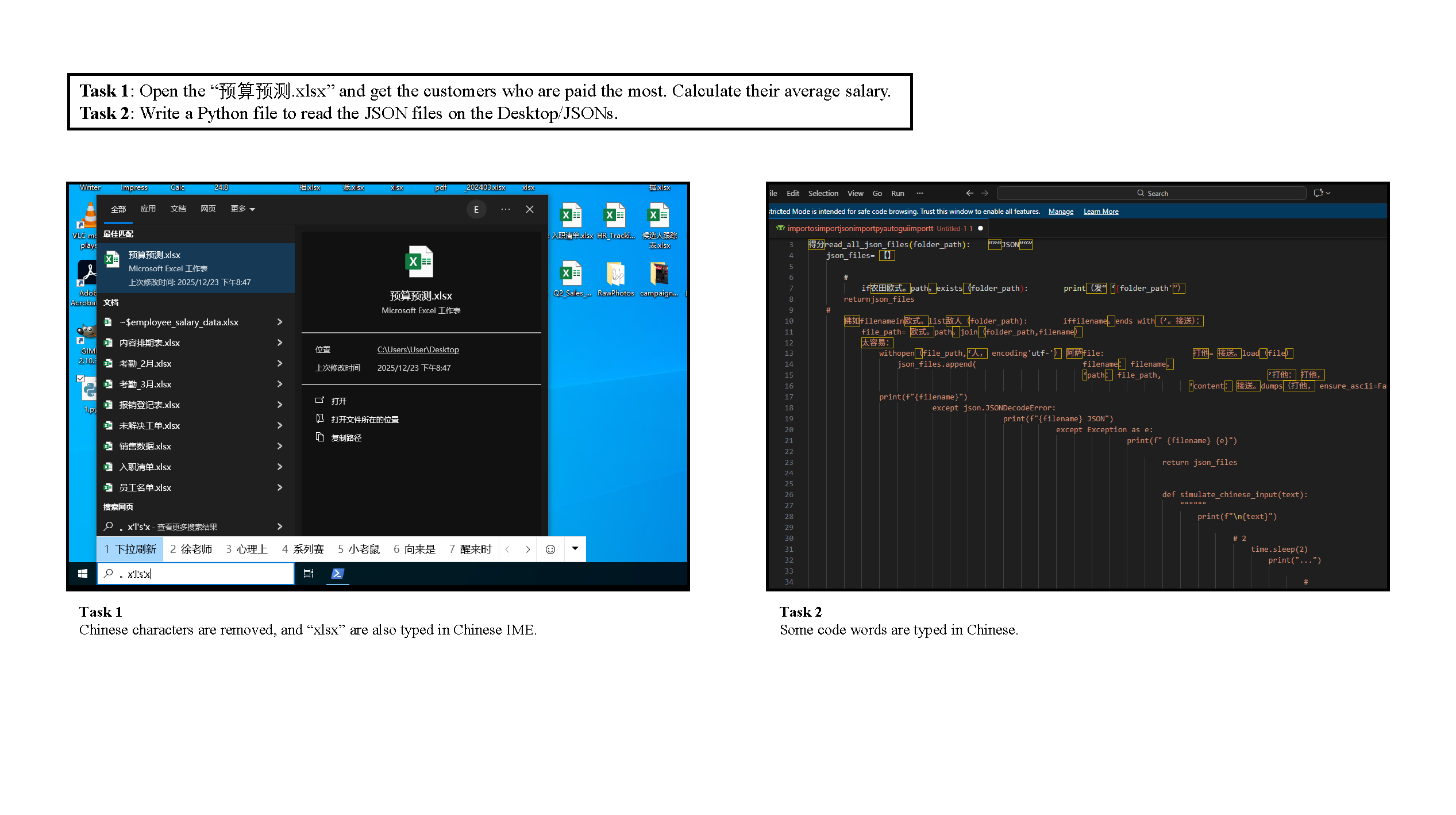
Figure 4: Illustration of stochastic GUI failures due to IME pop-up interference and input misalignment in automation.
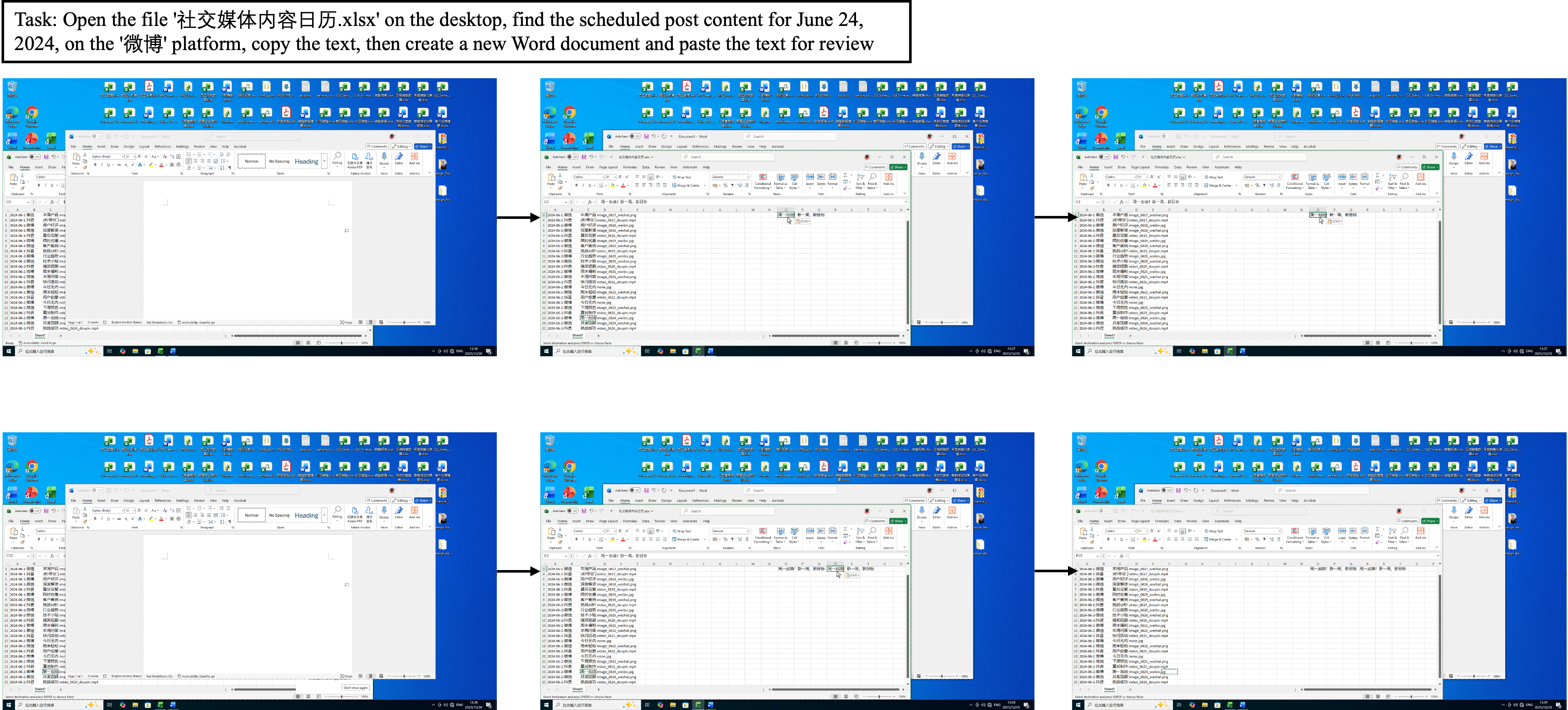
Figure 5: Failure in application switching, resulting in synchronization errors caused by improper window focus for clipboard operations.
Implications, Limitations, and Future Directions
WindowsWorld’s process-aware, persona-grounded, multi-application benchmark directly exposes the limitations of contemporary GUI agents and multimodal foundation models. Practically, the dominant barriers are not local semantic parsing or atomic action prediction, but context switching, multi-app state management, and consistent long-horizon planning. The persistent gap in checkpoint vs. global completion metrics indicates lack of agent “self-awareness” and robust error recovery in the face of stochastic GUI states (e.g., IME popups, environmental anomalies).
Theoretically, the benchmark implies that further scaling of model capacity alone is unlikely to close the observed performance deficits. Rather, advances in explicit state tracking, GUI context abstraction, and robust multi-modal policy architectures are required. Additionally, process-centric evaluation frameworks as introduced here should become standard for benchmarks targeting real-world agent deployment in digital productivity environments.
Anticipated future research catalyzed by WindowsWorld includes:
- Curriculum-based or RL fine-tuning on process-aware long-horizon tasks;
- Formal incorporation of Model Context Protocols for standardized tool access;
- Extension to multilingual OS environments and more expressive action modeling;
- Exploration of meta-agent architectures for more effective cross-application coordination.
Conclusion
WindowsWorld constitutes a thorough and challenging benchmark for process-aware evaluation of autonomous GUI agents in professional, multi-application desktop environments (2604.27776). By systematically revealing the limitations of current agentic models—particularly in cross-application coordination, context retention, and global consistency—it provides a critical step toward the realization and assessment of more robust, general-purpose AI agents for real-world computer use.