- The paper introduces novel CAPTCHA paradigms—ASCII art and overlapping audio—that exploit human perceptual strengths while challenging modern LLMs.
- The study shows that LLMs achieve as low as 0.16% accuracy on ASCII challenges and suffer significant performance drops in noisy audio conditions.
- The findings suggest that cost-intensive CAPTCHA methods could economically deter bots despite potential improvements in machine learning models.
Perceptual Gaps: Human-Optimal Modalities as Next-Generation CAPTCHA Design
Context and Motivation
The rapid integration of advanced multimodal LLMs into digital infrastructures has fundamentally undermined the value of traditional CAPTCHA systems. As exemplified by the abilities of large multimodal models such as GPT-5.2, Gemini 3, and Claude Opus 4.5 to reliably solve both text- and image-based CAPTCHAs, automated public Turing test mechanisms now fail to robustly distinguish between human agents and modern bots. There is a pressing need to design challenge formats that exploit domains where human perception remains decisively superior to AI, while maintaining cheap generation and broad accessibility.
This paper introduces and rigorously evaluates two novel CAPTCHA paradigms: vision-based challenges leveraging ASCII art, and audio-based question-answering in adversarial (overlapping or noisy) acoustic contexts. These modalities are motivated by human-evolved neural specializations in pattern recognition and the "cocktail party" effect, domains underrepresented in the supervised training of existing vision and audio models.
Traditional and Modern CAPTCHAs: Limitations in the Era of Multimodal LLMs
Classical CAPTCHA mechanisms rely on making machine perception and semantic extraction difficult, for example through image distortions, object recognition, and logical puzzles.

Figure 1: Example of reCAPTCHA v2, a widely-used image-based challenge now routinely solved by modern multimodal LLMs.
Demonstrating the obsolescence of these paradigms, the paper documents LLMs such as GPT-4o achieving trivial success with contemporary image-based CAPTCHAs.
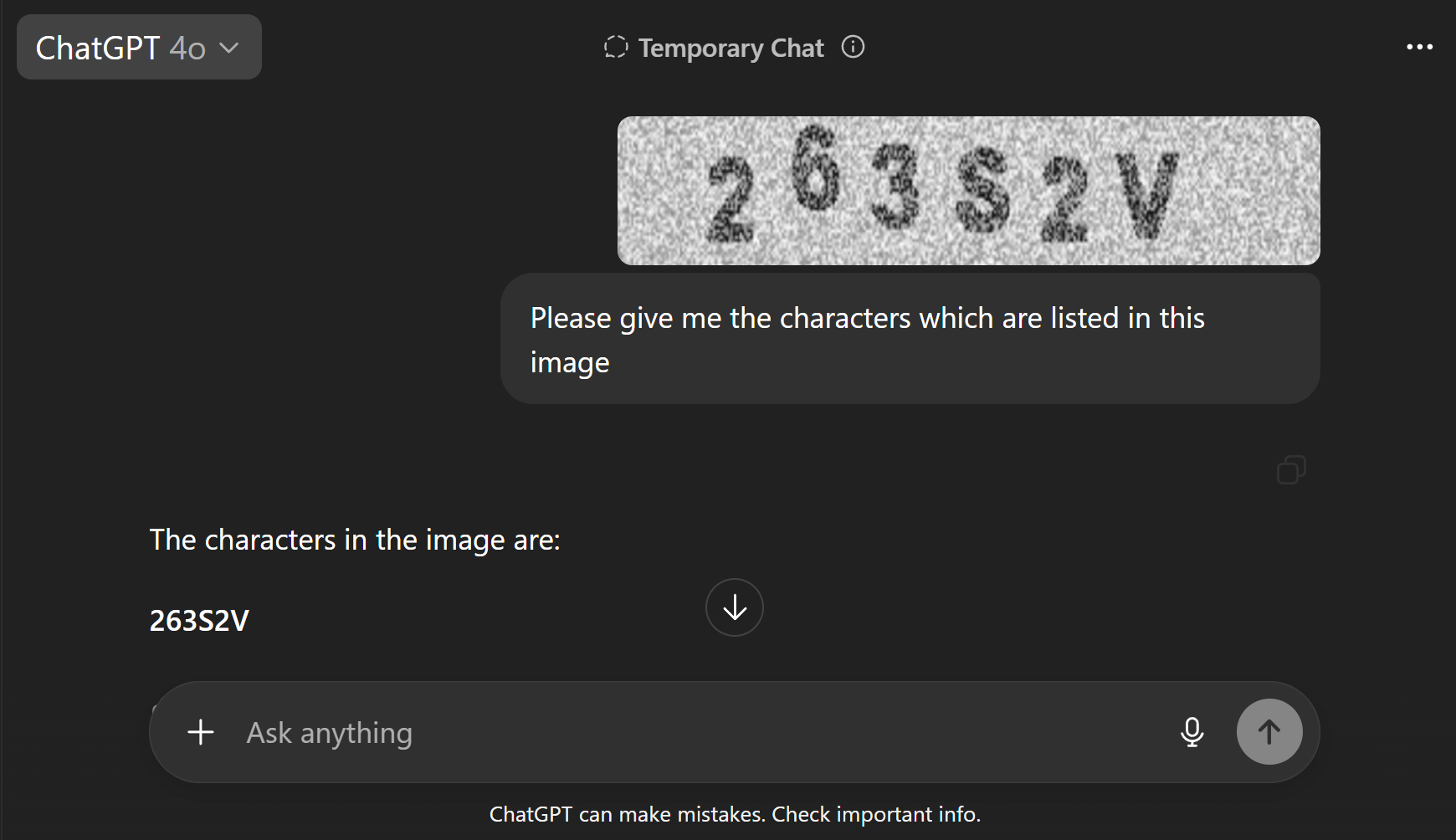
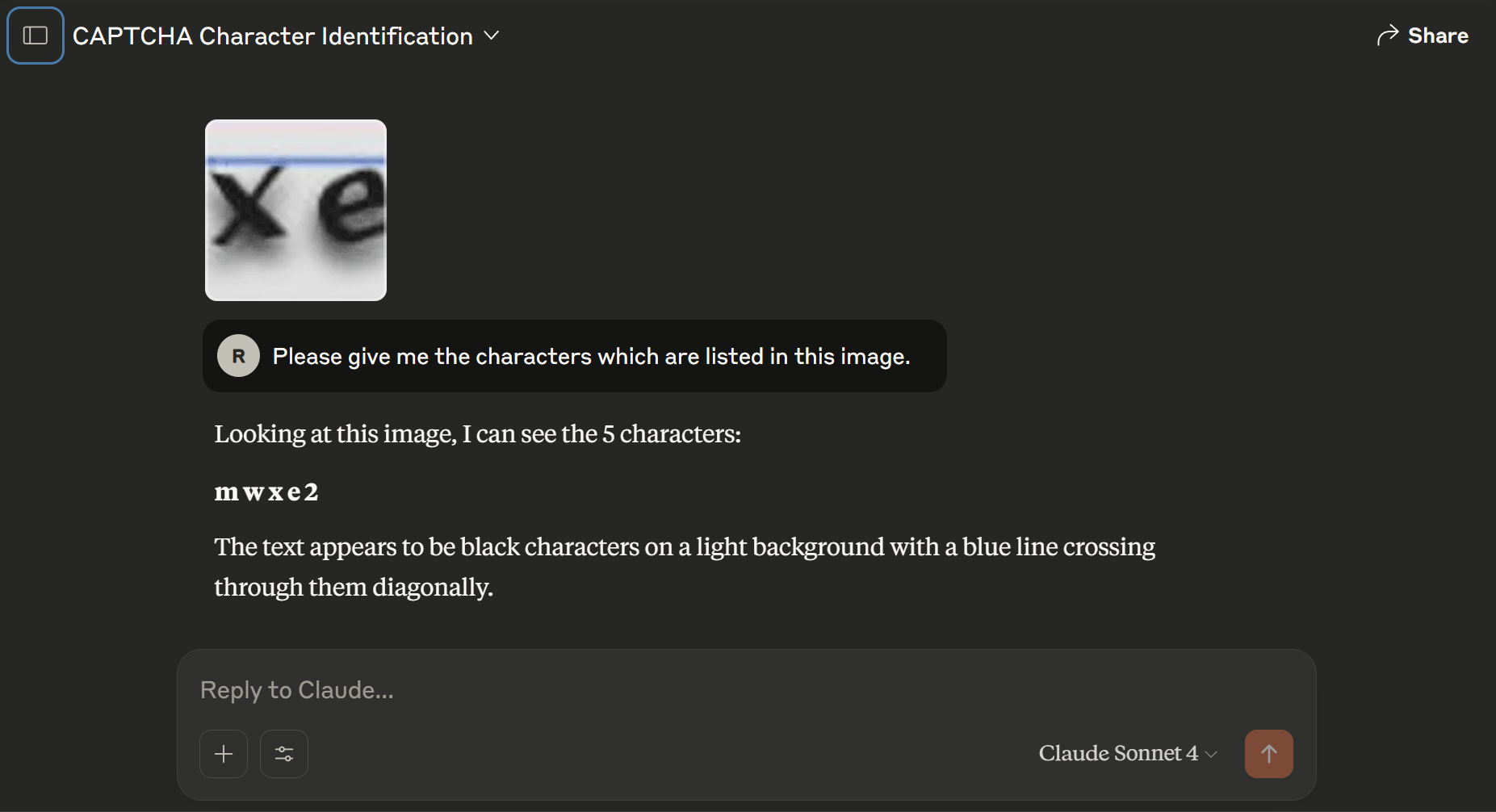
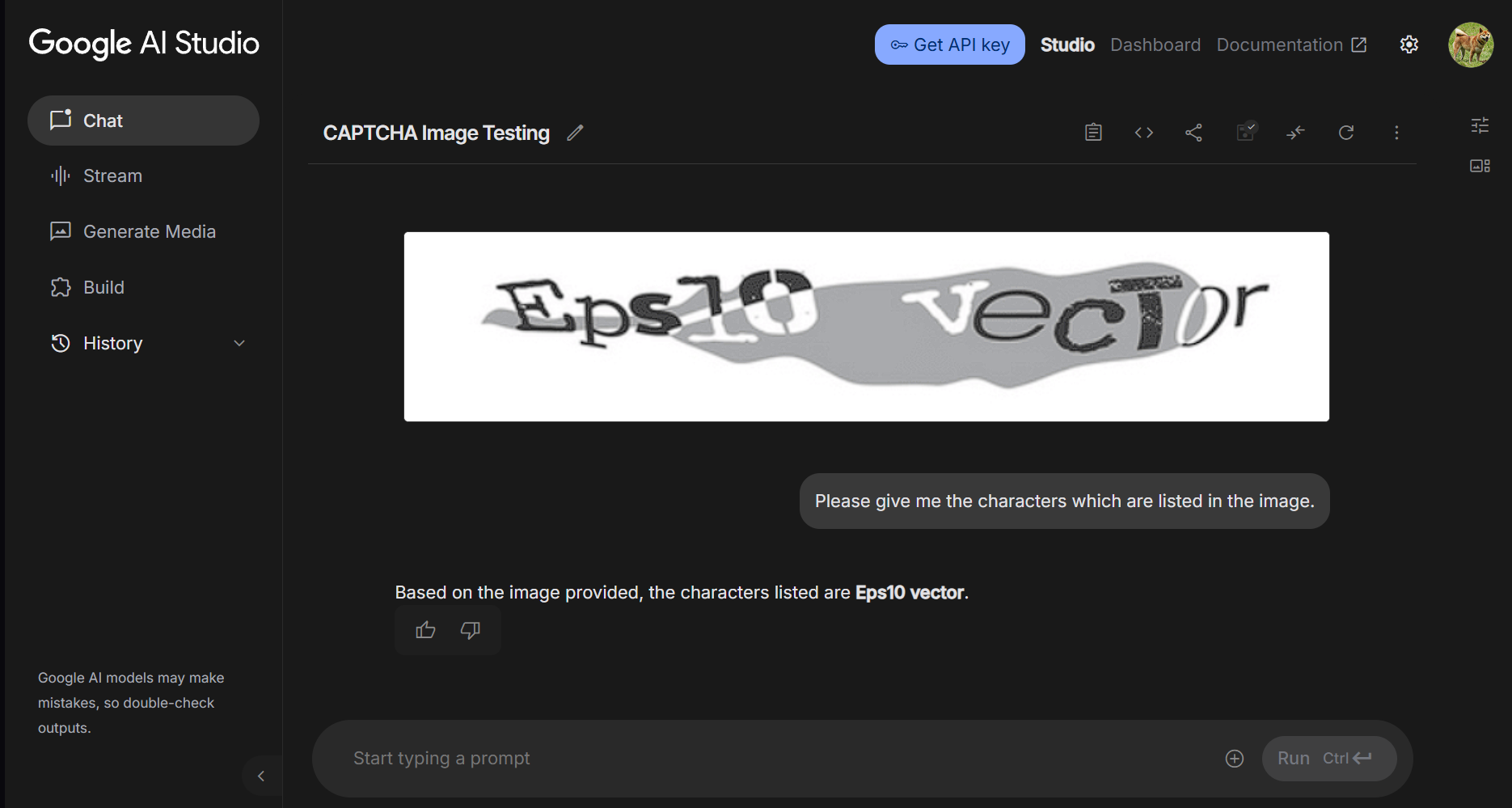
Figure 2: GPT-4o accurately parses visually perturbed text, reflecting the collapse of traditional CAPTCHA solvability gaps.
Human-Favorable Domains: The Case for ASCII Art Recognition
The vision-based strategy is motivated by the structural sparsity and gestalt-centric features of ASCII art—an encoding regime ubiquitous in human-computer interfaces but relatively neglected in model pretraining and fine-tuning. Despite the superficial textual nature of these challenges, SOTA multimodal LLMs display a catastrophic inability to parse or reconstruct the ground truth text from ASCII renderings under both text and image input modalities.
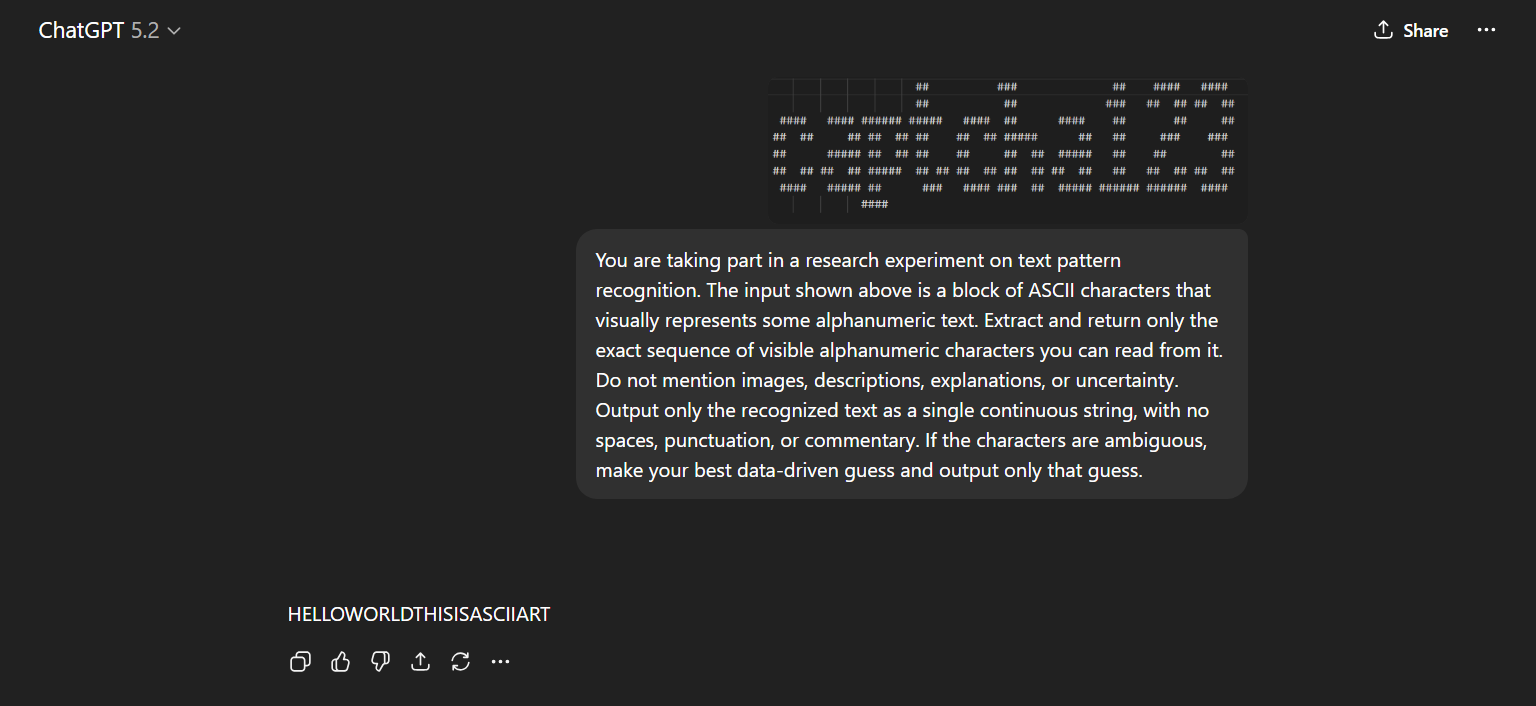
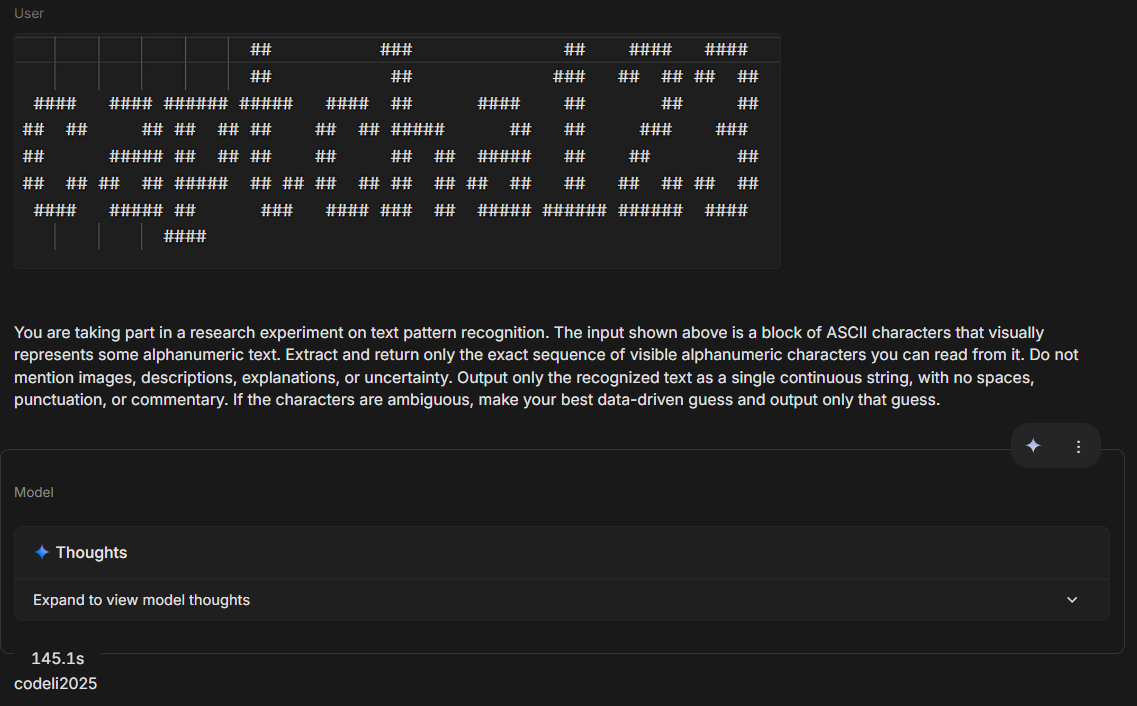
Figure 3: Leading LLMs (ChatGPT 5.2, Gemini 3 Pro) fail on even very simple ASCII CAPTCHAs, returning at most a single character over extended inference periods.
Quantitatively, across a large-scale evaluation, the maximum exact match (full accuracy) for ASCII CAPTCHAs is 0.16% (Gemini 3 Flash Preview, image-mode), with mean normalized character similarity seldom exceeding 55%. Inference times present further practical deterrence: solving attempts routinely span several seconds to minutes, in strong contrast to sub-10ms generation costs. Notably, none of the evaluated foundation models consistently extract meaningful information from ASCII renderings—even on tasks that remain trivial for unaided human observers.
These findings are robust across tokenization regimes and visual architectures, implying a fundamental gap not attributable to lack of exposure or insufficient sample size, but rather the absence of spatial grouping and alignment priors present in human visual processing (Gestalt principles).
Multispeaker and Noisy Audio: Exploiting the Cocktail Party Effect
On the audio axis, the paper explores question-answering tasks embedded in environments with overlapping/competing voices and synthetic noise. Human listeners exploit evolved attentional and segregational processes (the cocktail party effect) to disentangle target speech; in contrast, ASR and LLMs not purpose-trained for source separation display marked performance degradation.
Empirically, accuracy under baseline (clean audio) conditions approaches 73–75% (Gemini 3, VoxTral). When exposed to overlapping or noisy audio, success rates decrease substantially, e.g., Gemini 3 falls to ~48%, and VoxTral to ~31–46%. Performance for GPT Audio Mini hovers near random guessing (20–27%) under adverse audio, indicating that robust machine parsing of adversarially designed, information-rich acoustic mixtures remains a hard unsolved problem.
However, dynamic, large-scale generation of unique audio instances incurs substantially higher computational cost compared to ASCII art, somewhat limiting the scalability and real-time applicability of this approach.
Cost Asymmetry: Resource-Intensive Deterrence
An important strategic observation is that even if advances in representation learning close the gap in absolute accuracy, the inference cost on resource-intensive CAPTCHAs (especially those based on ASCII art or complex audio) is nontrivial. The marginal cost per solution for an adversarial agent may thus surpass the potential economic value, shifting the security paradigm away from perfect distinguishability toward break-even economics—a notion paralleling Proof-of-Work mechanisms in decentralized systems.
Implications and Future Directions
Theoretical implications: The work reinforces the absence of any task that is "fundamentally" hard for machines but trivial for humans under operational constraints. Any advantage is likely temporary, pending architecture-specific fine-tuning, broader data augmentation, or explicit adversarial training. Notwithstanding, the present-day failures of SOTA LLMs on ASCII and multispeaker audio tasks indicate persistent perceptual gaps that are resistant to naïve scaling or transfer learning.
Practical impact: These findings present web and content providers with actionable alternatives for mitigating bot traffic and content scraping, at least until model adaptation closes these gaps. Further, any progress by LLMs on adversarial audio separation constitutes a net positive externality for accessibility technologies, hearing aids, and automatic transcription in noisy environments.
Limitations and open research: The absence of quantitative human baselines and exclusion of model retraining or architectural adaptation limit certainty on long-term robustness. Immediate directions include assembling a human-vs-agent performance gold standard, as well as evaluating rapid fine-tuning strategies for LLMs and Vision-LLMs (VLMs) on synthetic ASCII and mixed-audio datasets.
Conclusion
The paper substantiates that as of current model generations, novel CAPTCHA regimes built from ASCII art and adversarial audio expose persistent perceptual gaps in even the most advanced multimodal LLMs. These schemes maintain all necessary properties for practical deployment: cheap, scalable generation, high human solvability, and strong AI hardness—at least temporarily.
If model-centric advancements erase this gap, cost-based deterrence will likely become the principal line of defense: making the unit economics of bot-based adversarial attacks infeasible even when solvability parity is achieved. The work thus redefines the short- and medium-term terrain for human verification protocols in a post-LLM digital ecosystem.