- The paper introduces BrowserArena, a novel platform evaluating LLMs on real-world web navigation tasks using live user-submitted challenges.
- It employs pairwise comparisons and human feedback to uncover practical strengths, identify common failure modes such as CAPTCHA and pop-up handling, and highlight performance disparities among models.
- The study demonstrates that multimodal capabilities significantly impact web navigation success, paving the way for improved agent evaluation methodologies.
BrowserArena: Evaluating LLM Agents on Real-World Web Navigation Tasks
The paper "BrowserArena: Evaluating LLM Agents on Real-World Web Navigation Tasks" introduces a novel platform for evaluating LLMs in the context of web navigation tasks. This study focuses on assessing the practical capabilities of LLMs as web agents interacting with live websites, highlighting both the strengths and persistent failure modes of these agents.
Introduction
BrowserArena is developed to address the limitations of existing benchmarks for web agents that primarily operate within sandboxed, closed environments. By transitioning evaluations to the open web, BrowserArena facilitates the collection of diverse user-submitted tasks, offering a more realistic appraisal of LLM capabilities. The platform includes head-to-head comparisons and step-level human feedback to identify recurrent failure modes such as CAPTCHA resolution, pop-up banner removal, and direct URL navigation.
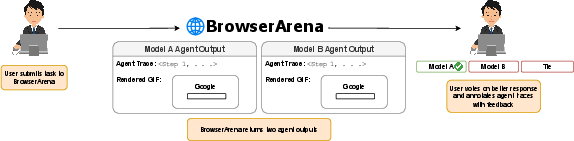
Figure 1: An overview of the study procedure showing how users interact with BrowserArena.
Methodology
The BrowserArena utilizes a live open-web evaluation strategy. Users submit tasks which are processed by randomly selected LLM agents configured to navigate and interact with diverse web environments using the BrowserUse library. This allows for the assessment of agents on tasks with ambiguous specifications, using pairwise comparisons to model human preferences and evaluate agent outputs beyond predetermined success criteria.
The research encompasses a detailed examination of user-submitted tasks and human preference data to construct a model leaderboard, demonstrating a notable gap in Vision LLMs (VLMs) capability to model human preferences accurately.
Experimental Evaluation
The platform evaluates five different models, revealing variabilities in their performance across user-submitted tasks. The ranking based on user preferences shows that some models, like the non-multimodal R1, perform better unexpectedly. This highlights that while multimodal capabilities are beneficial, they are not the sole determinant of successful navigation tasks.
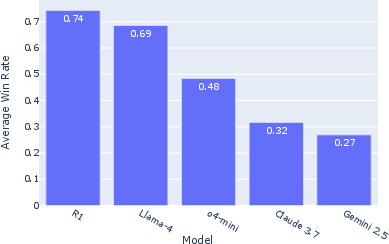
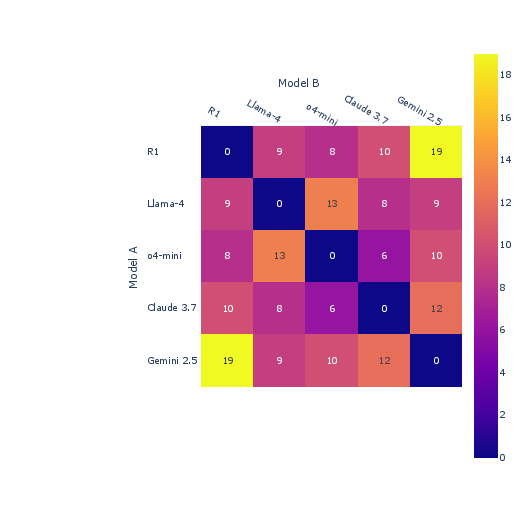
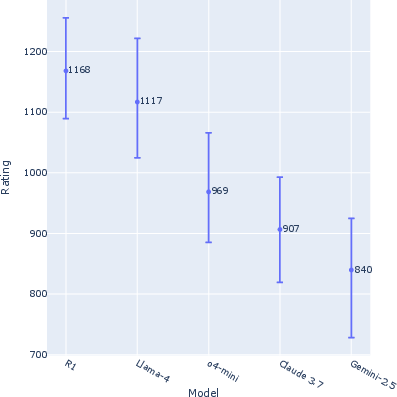
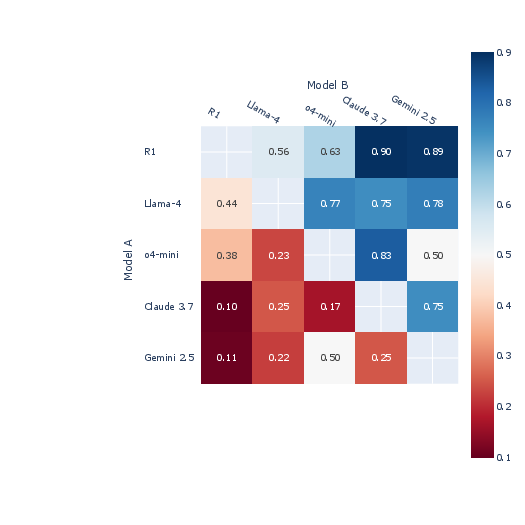
Figure 2: Average Win Rate across models.
Further, human evaluator agreement is assessed to measure consistency among human judges, which shows moderate agreement, with higher agreement observed when tie votes are filtered. This signifies differing thresholds among evaluators rather than inconsistent agent evaluation.
The study also highlights a substantial gap between human and VLM judgments, pointing out that multimodal inputs can adversely affect judge reliability, as demonstrated by input ablations that improve agreement when using trace-only evaluations.
Identification of Failure Modes
Step-level annotations from users led to the identification of three prominent failure modes: CAPTCHA solving, pop-up banner closure, and direct navigation. The paper details methodologies to construct targeted datasets reproducing these scenarios with high frequency to study variations in agent behavior.
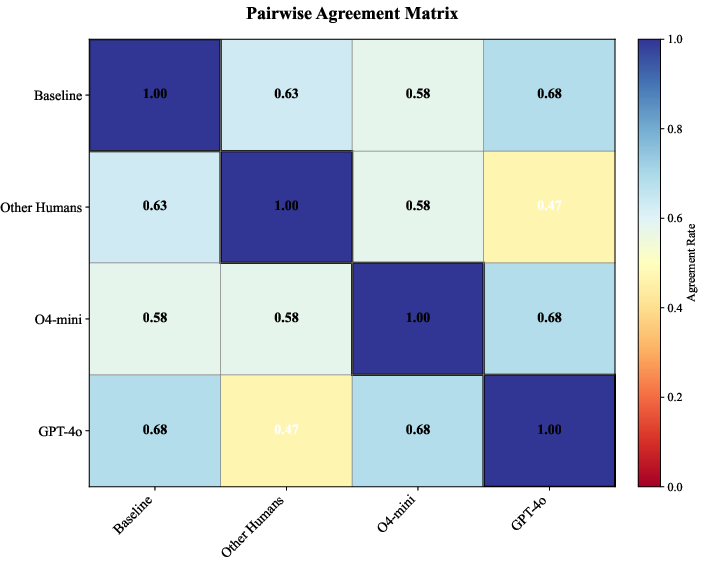
Figure 3: Pairwise agreements between the baseline labels, the new annotators, and two vision-languages models.
Captcha Solving: Different models exhibit varying strategies to circumvent CAPTCHA, with strategies ranging from direct link navigation to using proxies and archives. Notably, o4-mini demonstrates wider strategic diversity, suggesting better adaptation to CAPTCHA constraints.
Pop-Up Banner Closure: The evaluation reveals the necessity of multimodal capabilities for effective identification and closure of pop-up banners. Models with such capabilities perform noticeably better than those without.
Direct Navigation: Agents primarily favor invoking Google Search for information retrieval over direct navigation to targeted sites, emphasizing reliance on search engines for knowledge-intensive tasks.
Conclusions
The introduction of BrowserArena represents a significant step forward in benchmark methodologies for evaluating LLM web agents. By focusing on user-submitted tasks and employing pairwise comparisons, it uncovers insights into agent behavior in dynamic and real-world web scenarios. This study demonstrates that multimodal capabilities significantly impact web agent performance and highlights the methodological enhancements necessary for future evaluations.
Limitations and Future Work
The platform's evaluations are contingent upon the capabilities provided by the BrowserUse framework, implying that alternate agent configurations might yield different results. Additionally, failure modes are system-specific and could vary with different setups, suggesting a need for further exploration and refinement of configurations for universal applicability.
Overall, BrowserArena sets the groundwork for future advancements in LLM web agent evaluations, paving the way for more inclusive and realistic agent deployment frameworks.