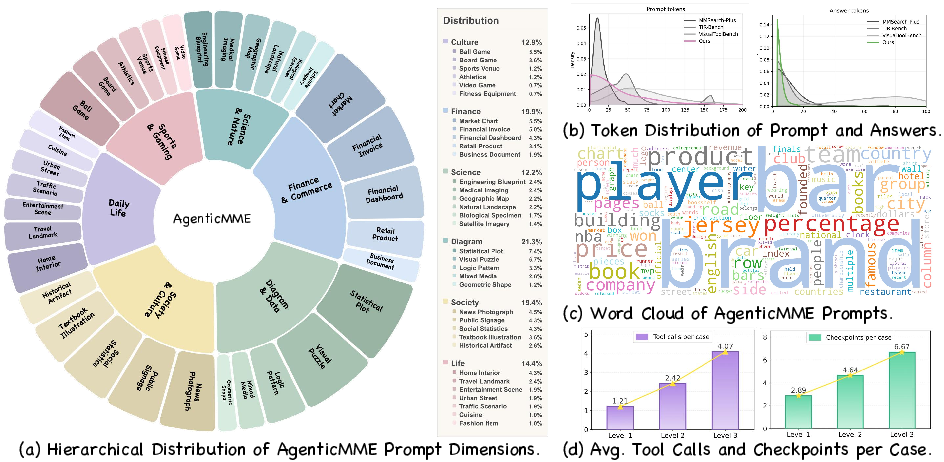
- The paper introduces Agentic-MME, a detailed benchmark that evaluates both visual and knowledge tool integration in MLLMs through process-level verification.
- It presents 418 real-world tasks across six domains with over 2,000 human-curated checkpoints to assess escalating task complexities.
- It empirically reveals substantial accuracy gaps between models and human performance, emphasizing the need for robust planning and reliable tool use in multimodal intelligence.
Agentic-MME: Process-Verified Benchmarking of Agentic Multimodal Intelligence
Motivation and Limitations of Previous Benchmarks
Recent advances in Multimodal LLMs (MLLMs) have shifted the field from static image-text understanding towards agentic settings, in which models actively invoke tools to manipulate images (Visual Expansion) and acquire external knowledge (Knowledge Expansion) through web search. Despite this paradigm shift, existing benchmarks inadequately capture the true complexity of agentic problem-solving, due to three major deficiencies: (1) lack of unified, flexible tool integration that enables fluid switching across heterogeneous visual and search APIs; (2) fragmentation in evaluation—testing visual and search actions in isolation, ignoring real-world synergistic workflows; (3) heavy reliance on final-answer accuracy as the sole metric, with no process-level verification of tool invocation correctness, efficiency, or intermediate state fidelity.
Agentic-MME directly addresses these gaps with a process-verified, fine-grained benchmark that systemically audits both agentic tool use and reasoning at an intermediate trajectory level.
Benchmark Design and Task Stratification
Agentic-MME comprises 418 real-world tasks sampled from six domains, stratified into three escalating difficulty levels. Each task is finely annotated with over 2,000 human-curated checkpoints, requiring significant annotation effort (>10 person-hours per task). The difficulty levels are defined as follows:
- Level 1 (Visual Expansion Focus): Requires a single visual tool operation; minimal knowledge expansion.
- Level 2 (Visual + Knowledge Expansion): Combines short visual processing sequences with fact retrieval from the web.
- Level 3 (Synergistic Tool Coupling): Demands multiple rounds of intertwined visual manipulation and open-ended search, often requiring the agent to implement a hypothesize–verify loop and cross-modal grounding.

Figure 1: Case studies in Agentic-MME showcase the increasing complexity of agentic workflows across levels, from isolated visual transformation to deeply synergistic, multi-hop vision and web search.
The tasks are constructed to ensure that: (i) visual interaction is indispensable (evidence is intentionally occluded or ambiguous in the raw image); (ii) knowledge retrieval is necessary and cannot be circumvented with vision-only processing; and (iii) solution paths can be objectively verified, step by step.
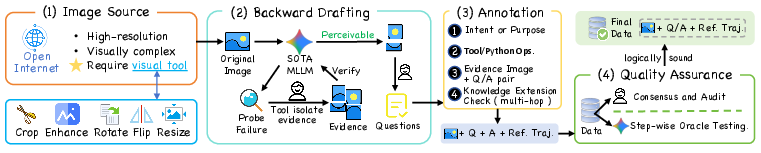
Figure 2: The data pipeline integrates rigorous image sourcing, model-in-the-loop backward drafting, and step-by-step annotation, ensuring process-level supervision.
Stepwise Process Verification and Unified Execution Harness
Agentic-MME's key innovation is its dual-axis evaluation protocol:
- V-axis (Visual): Audits whether the agent actively invokes transformations and whether the resulting artifacts contain the required cues. Each visual operation is checkpointed for both intent and artifact correctness.
- S-axis (Strategy/Knowledge): Evaluates the quality of search query formulation, keyword selection, correct navigation of multi-hop web evidence, and the successful extraction of relevant factual information.
To support heterogeneous MLLM architectures, Agentic-MME provides a unified execution harness supporting both atomic function-calling (Atm) and code generation (Gen) modes. In Atm, agents interact via explicit function-based tool APIs; in Gen, models write free-form code for visual processing. All traces are standardized and audited via an AST-based trace parser for visual commands and deterministic logging of search and retrieval actions.
Dataset Properties and Domain Diversity
Agentic-MME is constructed to maximize both semantic and operational diversity:
Empirical Analysis and Error Decomposition
Extensive experiments reveal critical limitations in current MLLMs:
- Accuracy Gap: The strongest model (Gemini3-pro, Atm) yields only 56.3% end-to-end accuracy, plunging to 23.0% on Level-3, while human performance exceeds 82% even on hardest tasks.
- Process/Auditability: All models, especially open-source variants, underperform severely in S-axis metrics—e.g., Qwen3-VL-235B achieves S≈20% on Level-3, signifying failure in composing effective search strategies.
- Interface Sensitivity: Structured APIs offer higher tool-invocation fidelity compared to code (Gen) mode, yet Gen mode demonstrates greater flexibility for complex operations, suggesting an avenue for future hybridization.
- Tool Misuse Patterns: Error analysis uncovers that many models invoke tools eagerly but fail to manipulate the right regions (low Vtrue), misuse search (bad queries), or omit necessary agentic actions (passive guessing dominates ~50% of observed failures).
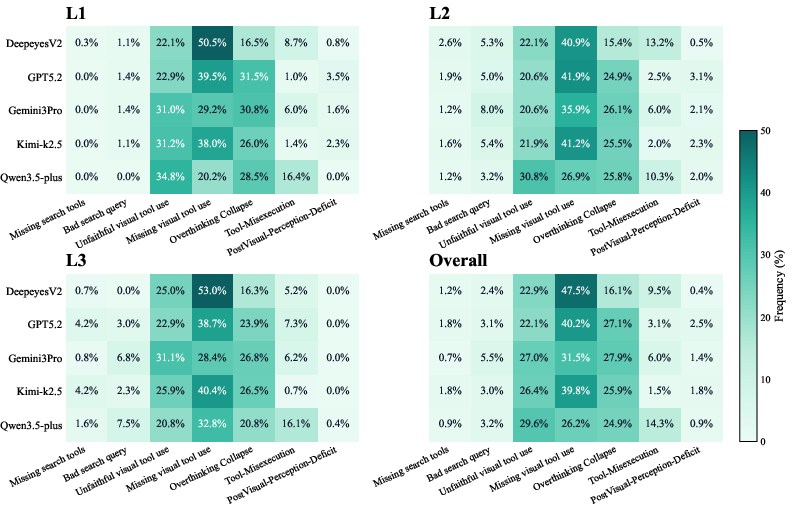
Figure 4: Fine-grained failure mode heatmap, exposing frequent passive guessing, overthinking, unfaithful execution, and interface-induced errors across increasing difficulty.
- Efficiency (Overthinking): Most agents either under- or over-utilize tools, with closed-source models sometimes "overthinking" (making redundant calls) and open-source models demonstrating tool aversion.
- Process Supervision Utility: Feeding agents ground-truth intermediate states and annotations yields substantial accuracy improvements (>20% increase in some cases), but performance even then fails to saturate human levels on Level-3, highlighting intrinsic limitations in long-horizon orchestration.
Benchmark Validation
Control studies confirm Agentic-MME is resistent to data leakage and cannot be solved by language-only or passive perception baselines. Only an agent capable of both visual and knowledge expansion, coupled with process-level decision-making, can consistently succeed.
Limitations, Theoretical Implications, and Future Directions
Agentic-MME sets a new standard for process-level evaluation in agentic MLLMs, providing not only accuracy metrics but also fine-grained behavioral diagnostics. However, the findings underscore that modern MLLMs still lack robust planning, integrated cross-modal reasoning, and tool-use reliability required for real-world multimodal autonomy. Importantly, process-level supervision—beyond final-answer correctness—is essential for revealing bottlenecks and guiding future architectural advances.
Promising future directions include:
Conclusion
Agentic-MME unifies fine-grained process verification with realistic agentic multimodal tasks, offering detailed insights into both current model limitations and the path to robust agentic intelligence. Experimental results establish a substantial, persistent gap between model and human performance, particularly in synergistic, multi-step workflows. Agentic-MME thus provides an indispensable resource for the next generation of agentic MLLM research—serving as a rigorous basis for both evaluation and directed improvement of multimodal reasoning and tool-augmented intelligence.