ClawBench: Can AI Agents Complete Everyday Online Tasks?
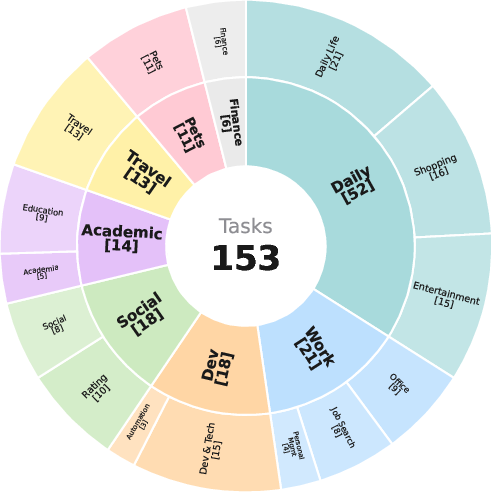
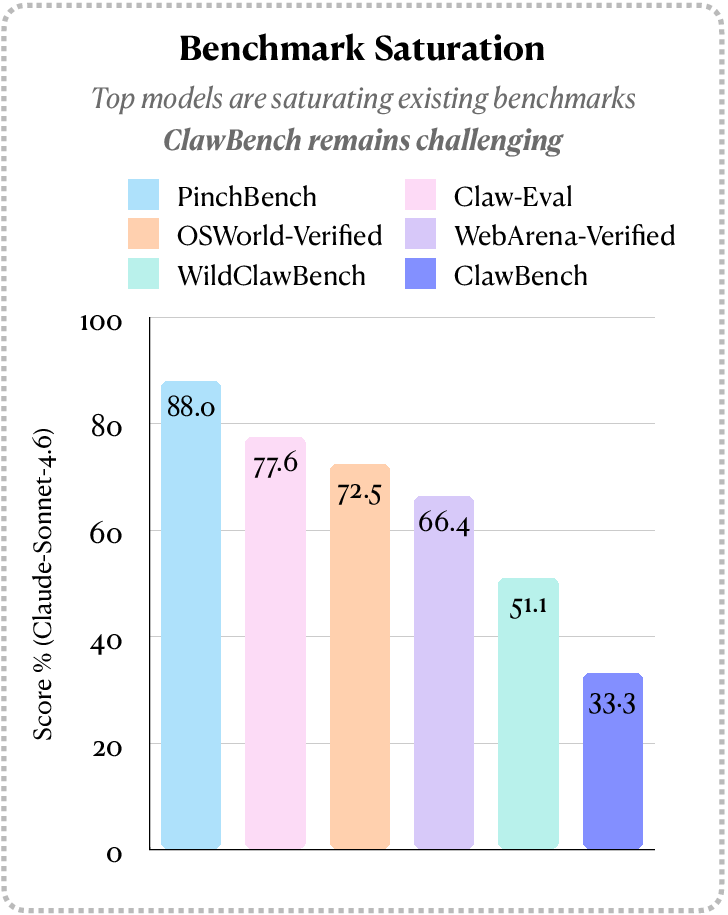
Abstract: AI agents may be able to automate your inbox, but can they automate other routine aspects of your life? Everyday online tasks offer a realistic yet unsolved testbed for evaluating the next generation of AI agents. To this end, we introduce ClawBench, an evaluation framework of 153 simple tasks that people need to accomplish regularly in their lives and work, spanning 144 live platforms across 15 categories, from completing purchases and booking appointments to submitting job applications. These tasks require demanding capabilities beyond existing benchmarks, such as obtaining relevant information from user-provided documents, navigating multi-step workflows across diverse platforms, and write-heavy operations like filling in many detailed forms correctly. Unlike existing benchmarks that evaluate agents in offline sandboxes with static pages, ClawBench operates on production websites, preserving the full complexity, dynamic nature, and challenges of real-world web interaction. A lightweight interception layer captures and blocks only the final submission request, ensuring safe evaluation without real-world side effects. Our evaluations of 7 frontier models show that both proprietary and open-source models can complete only a small portion of these tasks. For example, Claude Sonnet 4.6 achieves only 33.3%. Progress on ClawBench brings us closer to AI agents that can function as reliable general-purpose assistants.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ClawBench, a big “reality check” for AI assistants that use the web for you. Instead of asking, “Can an AI summarize emails?”, it asks, “Can an AI actually do everyday online chores—like buying something, booking an appointment, or filling out a job application—on real websites?” ClawBench is a set of 153 such tasks across 144 live websites.
What questions were the researchers asking?
They focused on three simple, important questions:
- Can today’s AI agents reliably finish real, everyday web tasks that people do all the time?
- Do agents that look good on older, easier tests still work well on live, messy websites with pop‑ups, logins, and changing layouts?
- How can we test agents safely and fairly on real sites without actually buying things or submitting real forms?
How did they test it?
Think of ClawBench like a driving test in a real city, not in an empty parking lot.
- Real websites: Many previous tests use “sandbox” copies of websites that never change. ClawBench uses live, real websites with all the usual hurdles: cookie prompts, dynamic pages, and anti-bot checks.
- Write-heavy tasks: These are tasks where you have to type details and submit forms that would change something in the real world (like placing an order). That’s harder and more realistic than just reading info.
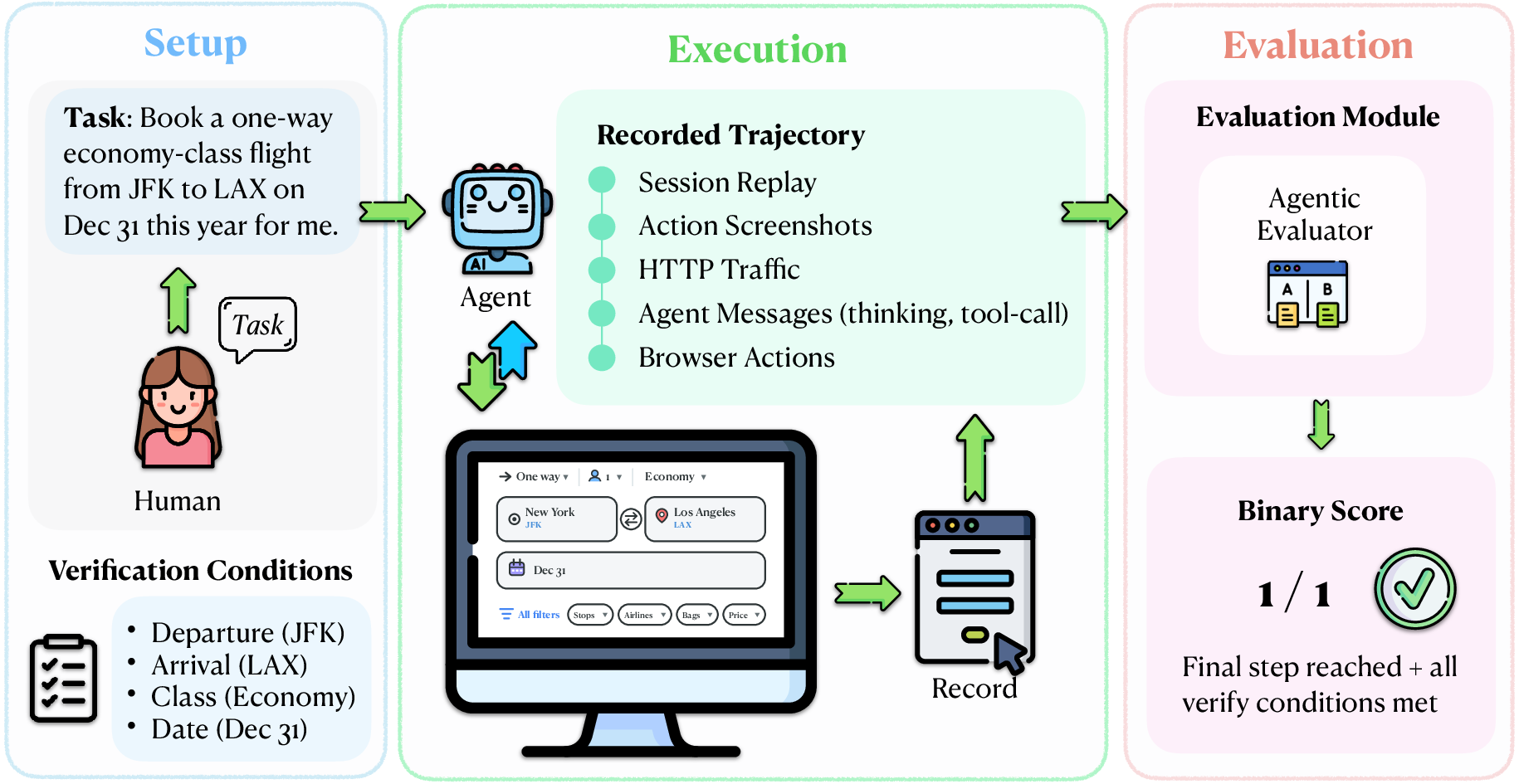
To keep things safe, they built a clever safety brake:
- Final-request interception: When an AI is about to click “Submit” and send the final “do it” message (the HTTP request) to the website, ClawBench catches and blocks just that one message. It records what would have been sent but stops it from reaching the site. This prevents real purchases or submissions.
To grade fairly, they used human examples and a multi-angle replay:
- Human “gold” runs: For each task, a human completed it first. This created a correct, step‑by‑step example (what the form fields should be, what buttons to click, and what the final submission would look like).
- Five-layer recording: Each AI run was recorded in five ways—like having multiple cameras and logs:
- A full session video (what was on screen).
- Step-by-step screenshots (what changed after each click/typing).
- Network messages (what the browser tried to send).
- The agent’s own notes and tool calls (its “thought process” and actions).
- Low-level actions (exact clicks, typing, scrolling).
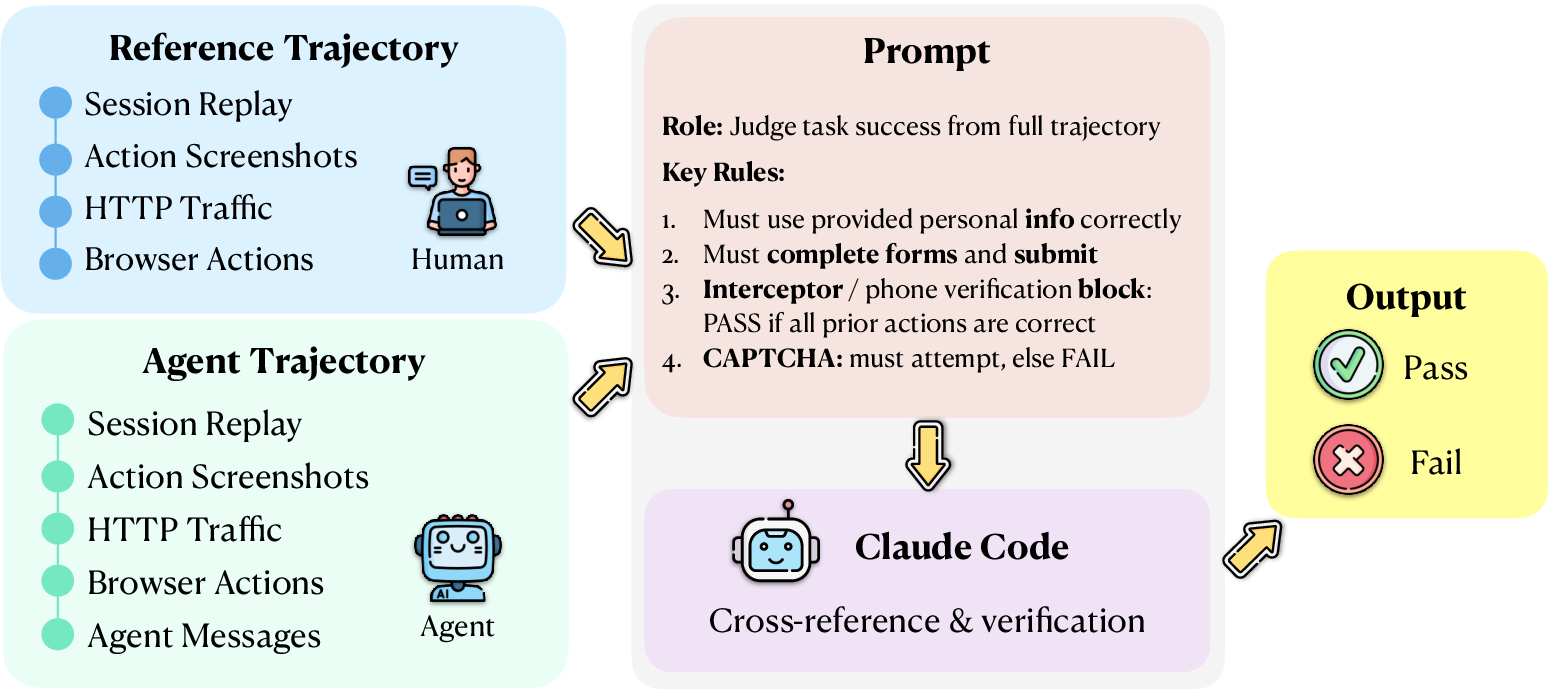
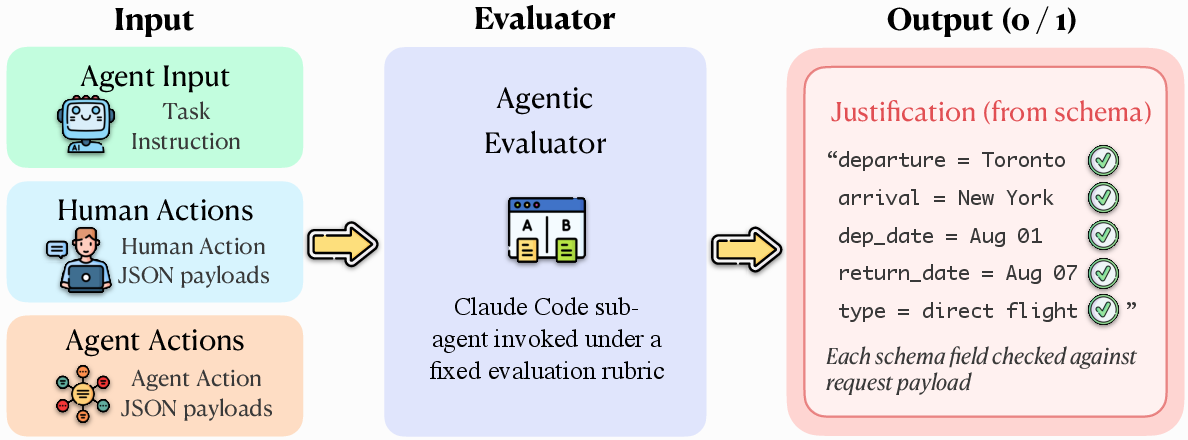
Agentic Evaluator (the referee): An automated judge compares the AI’s steps and final would‑be submission to the human’s correct version. It doesn’t just say pass/fail; it explains where the agent went wrong (like a teacher marking exactly which fields were incorrect).
In short: live sites, safe “brakes” at the very end, and a detailed, fair referee.
What did they find?
- Even top AI agents struggled. On older, controlled benchmarks, strong models (like Claude Sonnet 4.6 or GPT-5.4) can score around 65–75%. On ClawBench, the best model did only 33.3%, and some models scored under 5%.
- Performance varied by category. Some models were better at certain kinds of tasks (like finance or daily life) and worse at others (like development or travel). But no one was good across the board.
- The gap is real. Doing real-world, write‑heavy tasks on live websites is much harder than doing similar tasks in a sandbox. ClawBench exposes that gap clearly.
Why this is important:
- It shows that being good at “toy” or simplified web tasks doesn’t guarantee success on actual everyday chores.
- The detailed recordings and explanations make it easier for researchers to see exactly why agents fail—wrong fields, missed steps, misread pages, etc.—so they can fix the right problems.
What could this change?
If AI agents are going to be true “online helpers,” they must be able to finish real tasks safely and reliably. ClawBench:
- Gives researchers a realistic target to aim for, not just a simplified test.
- Encourages building agents that handle pop‑ups, changing layouts, login flows, and long forms—just like humans do.
- Provides a safe way to practice and measure progress on live websites without causing real-world side effects.
Bottom line: ClawBench is a tough, real-world test that reveals what today’s AI agents can—and can’t—do yet. Improving on ClawBench should bring us closer to trustworthy AI assistants that can actually get your online chores done.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to enable actionable follow-up research.
- External validity beyond filtered tasks: Tasks requiring payments, subscriptions, geographically restricted services, or more complex compliance constraints were removed; it remains unknown how agents perform on these more consequential, frequent real-life workflows.
- Authentication realism: The benchmark does not detail how login/2FA/credential management is handled; performance on tasks requiring authenticated sessions (including account creation, password resets, and multi-factor authentication) is unreported.
- Anti-bot and CAPTCHA handling: The impact of bot-detection systems, CAPTCHAs, and rate-limiting on agent success rates is not measured or isolated from other failure modes.
- Pre-commit side effects: Interception targets only the terminal submission; many sites commit state earlier (e.g., “save draft,” “add to cart,” email verifications, soft-reservations). Whether agents trigger such side effects and how to detect/neutralize them remains unstudied.
- Multiple terminal endpoints and non-canonical paths: Agents may reach different valid endpoints or alternative workflows (e.g., different payment gateways, modals, or batch APIs). Coverage of these variants by a single, human-annotated terminal request is unclear.
- Evaluator reliability and validity: The Agentic Evaluator (Claude Code sub-agent) is not validated against human adjudication (e.g., inter-rater agreement, precision/recall against a human gold set), leaving potential bias and error rates unknown.
- Single-reference bias: Comparing to a single human trajectory risks penalizing legitimate alternative actions/field orders/payloads; systematic evaluation of accepted diversity and permissible variation is missing.
- Generalization across time (“site drift”): Live websites change frequently; stability of success rates across days/weeks, and sensitivity to layout/API updates, are not quantified (no repeated measures, CIs, or temporal robustness analysis).
- Run-to-run variance: The paper does not report multiple seeds/reruns per task or per model, leaving statistical significance and variance in success rates unquantified.
- Failure attribution: While five-layer traces exist, the paper does not decompose failure causes (e.g., perception errors, DOM grounding, navigation planning, form-filling accuracy, anti-bot blocks, evaluator misjudgment) with measurable proportions.
- Partial credit and process quality: The metric is binary pass/fail; there is no standardized partial-credit scheme or secondary metrics (efficiency, steps taken, backtracks, time-to-completion, safety violations), limiting nuanced diagnosis.
- Task difficulty calibration: No explicit effort is reported to balance or rate task difficulty, limiting interpretability of category-wise comparisons and cross-model differences.
- Locale, language, and accessibility coverage: Tasks appear to be English, desktop, and mouse/keyboard centric; generalization to multilingual sites, RTL languages, localized content, screen readers, high-contrast modes, or keyboard-only navigation is untested.
- Mobile and cross-device workflows: Everyday tasks often occur on mobile; the benchmark evaluates only desktop Chromium, leaving mobile web/app workflows, device handoffs, and responsive UI challenges unexplored.
- Multi-session and long-horizon tasks: Tasks that span multiple sessions (e.g., multi-day bookings, staged identity verification, document uploads across separate visits) are excluded or unreported.
- Document-grounding specifics: The paper claims tasks require information from user-provided documents, but it does not detail document types, sizes, formats, or the agent’s retrieval/grounding mechanisms and their failure rates.
- Privacy and PII leakage: Agents may type, upload, or transmit personal data before the terminal intercept; the benchmark does not quantify PII exposure risk, nor provide safeguards or redaction protocols beyond the final-request block.
- Interception robustness across agent behaviors: The intercept was validated on human trajectories; whether it catches terminal requests reached via alternative agent actions (including different query strings or POST bodies) is not empirically tested.
- Early-state mutations and persistence: Actions like consent settings, newsletter opt-ins, cart updates, or profile edits may persist server-side before final submission; monitoring and roll-back of such changes are not addressed.
- Effect of interception on agent behavior: Blocking the final request may alter downstream agent policies (e.g., retry loops, misinterpretation of server responses). The behavioral impact of interception is unmeasured.
- Benchmark sustainability and maintenance: There is no quantitative plan for task breakage rates, refresh cadence, automated detection of expired tasks, or community governance to keep live tasks valid over time.
- Evaluator transparency and release: The full rubric, prompts, and any post-processing rules for the Agentic Evaluator are not thoroughly documented or validated for reproducibility, especially across evaluator model versions.
- Cross-evaluator consistency: No analysis compares the Agentic Evaluator’s judgments with alternative evaluators (e.g., different LLM judges, rule-based checkers, human annotators), leaving consensus reliability unclear.
- Model/agent configuration fairness: The paper does not detail prompts, tool-use settings, or per-model tuning; fairness and sensitivity to agent framework or hyperparameters remain open.
- Training data contamination: Potential training overlap with sites/workflows is not checked; whether observed failures are due to reasoning limitations or memorization gaps is unknown.
- Security and terms-of-service considerations: Operating agents on production sites raises TOS and ethical questions; processes for permission, rate limiting, or responsible use are not described.
- Coverage of manipulative/dark patterns: Although related work is cited, the benchmark does not quantify the prevalence or impact of dark patterns in its tasks.
- Payment flows and financial instruments: High-friction flows (credit card tokenization, 3-D Secure, PayPal/Stripe redirects, BNPL) are not included; agent capability on realistic payment ecosystems is unknown.
- Third-party/OAuth flows: Cross-domain authentication or delegated permissions (e.g., OAuth for calendars, storage) are not evaluated, leaving a gap in real-world integration capabilities.
- Human baseline and gap analysis: Human completion times, error rates, and step counts are not reported, limiting calibration of human–agent performance gaps.
- Release scope: While the pipeline is open-sourced, it is unclear whether full ground-truth trajectories, interception specs, and evaluator artifacts are released for independent replication.
- Robustness to network variability: The impact of latency, intermittent failures, or stale caches on agent success is unmeasured.
- Safety evaluation scope: There is no systematic measurement of unsafe behaviors (e.g., policy violations, repeated retries, accidental navigation to risky pages) beyond final-request blocking.
- Scalability of manual interception annotation: The approach depends on per-task human endpoint specification; methods to automate or semi-automate intercept discovery with safety guarantees are not explored.
- Handling of dynamic, client-side form logic: Validation rules, dependent fields, and asynchronous checks (e.g., address validators) are common; the benchmark does not quantify how often these cause failures or how agents adapt.
- Multiple correct end states: Some tasks admit multiple acceptable payloads (e.g., equivalent seat selections or delivery windows). Criteria for equivalence classes and how the evaluator recognizes them are not specified.
- Comparative ablations: The paper mentions observation modality ablations but does not report detailed results; the effect of vision-only vs. DOM-access vs. hybrid observations on success is thus unclear.
Practical Applications
Overview
ClawBench introduces a live‑web, write‑heavy benchmark with three core innovations that directly enable practical applications: (1) a “final‑request” interception mechanism that makes real‑site evaluation safe, (2) a five‑layer recording stack (session video, action screenshots, HTTP traffic, agent messages, low‑level browser actions) for deep, step‑level diagnostics, and (3) an agentic evaluator that compares agent trajectories to human ground truth for traceable, binary verdicts. These features translate into immediate utilities for building, testing, and governing web‑capable AI agents, and they lay groundwork for future products, standards, and research agendas.
Below are actionable use cases grouped into Immediate Applications and Long‑Term Applications, with sector tags and key dependencies/assumptions for feasibility.
Immediate Applications
- Pre‑deployment QA and regression testing for web agents
- Sectors: software, e‑commerce, travel, finance, HR/ATS, customer support
- What: Integrate ClawBench’s interception layer and agentic evaluator into CI/CD to catch breakages when websites change (pop‑ups, dynamic DOM, auth flows) and to prevent harmful submissions during testing.
- Tools/workflows: “Agent QA harness” that runs nightly on a curated set of live tasks; step‑level failure dashboards using 5‑layer traces.
- Dependencies/assumptions: Chromium/CDP access; stable test accounts and credentials where required; legal/ToS compliance for hitting production sites; evaluator model availability (e.g., Claude Code).
- Safe “dry‑run” or shadow mode for automation pilots
- Sectors: enterprise IT/RPA, operations, support
- What: Deploy the interception mechanism as a safety valve so pilot agents can exercise real workflows without committing irreversible actions (orders, applications, reservations).
- Tools/products: “Dry‑Run Browser” extension; policy flags that only allow terminal requests once guardrails are satisfied.
- Dependencies/assumptions: Accurate identification of terminal requests (human‑annotated specs); some flows may involve multi‑commit patterns that require multiple intercept points.
- Failure analytics and observability for agent teams
- Sectors: software/AI R&D, platform teams
- What: Use 5‑layer recordings for reproducible post‑mortems (what the agent saw, thought, did, and sent); prioritize fixes by failure mode (field binding errors, navigation dead‑ends, auth mishandling).
- Tools/products: “Agent Observability” dashboard with synchronized replay and schema‑level diffing of HTTP payloads vs. human ground truth.
- Dependencies/assumptions: Storage/compliance for session data; team workflows to triage and act on trace findings.
- Vendor benchmarking and procurement due diligence
- Sectors: enterprise IT, government, regulated industries
- What: Compare third‑party assistants on standardized, realistic tasks (write‑heavy, live‑web) rather than synthetic sandboxes; set minimum pass‑rates before granting production access.
- Tools/workflows: Benchmark‑as‑a‑Service with category‑specific scorecards (e.g., Finance vs. Travel).
- Dependencies/assumptions: Consistent environment setup; reproducible runs despite live‑web variability; documented evaluator rubric.
- Product safety gating for consumer assistants
- Sectors: consumer software, platform ecosystems, app stores
- What: Gate high‑risk features (e.g., “auto‑checkout,” “auto‑apply”) behind ClawBench‑style tests to ensure reliable behavior on write‑heavy tasks.
- Tools/workflows: Release checklists that require passing category‑aligned ClawBench tasks; “graduated privileges” based on score thresholds.
- Dependencies/assumptions: Agreement on acceptable risk thresholds; periodic retesting due to website drift.
- Course modules and labs for HCI/AI education
- Sectors: academia, training providers
- What: Use ClawBench tasks and traces to teach web grounding, multimodal reasoning, and evaluation design; students analyze failures with the five‑layer data.
- Tools/workflows: Instructor kits with selected tasks, human references, and evaluator configs.
- Dependencies/assumptions: Classroom‑safe task selection (no paid accounts); institutional review for recording/storage.
- Website UX and anti‑bot stress testing
- Sectors: platforms (marketplaces, travel, finance portals)
- What: Evaluate how dynamic content, dark patterns, or consent pop‑ups affect agent usability; uncover friction that harms both humans and beneficial agents.
- Tools/workflows: Periodic runs with agent variants; correlate agent failures with human funnel metrics.
- Dependencies/assumptions: Internal permission to test production; sensitivity to bot‑detection systems; ethics review.
- Controlled validation of data‑entry automations
- Sectors: healthcare (patient portals), finance (expense/reporting), education (applications/enrollment), HR (onboarding)
- What: Before enabling automated form filling in sensitive portals, run dry‑runs that verify all required fields and schema compliance without submitting.
- Tools/workflows: Interception specs mapped to portal endpoints; evaluator checks required fields and order of operations.
- Dependencies/assumptions: Availability of test accounts/sandboxes; privacy and PHI/PII safeguards; legal review for production tests.
- Incident analysis and audit trails for agent mishaps
- Sectors: enterprise governance, risk and compliance (GRC)
- What: Use five‑layer traces as forensic evidence when agents misbehave; align agent actions to human references to determine root cause and liability.
- Tools/workflows: Retention policies; standardized reporting formats.
- Dependencies/assumptions: Data retention and access controls; clear policies for recording in production.
- Community‑driven benchmark expansion
- Sectors: open‑source, research consortia
- What: Contribute tasks and human ground truths; diversify industries and geographies; share failure taxonomies to accelerate progress.
- Tools/workflows: Task authoring kits; review pipelines for interception specs.
- Dependencies/assumptions: Maintainers to vet tasks; avoiding paywalls/geo‑locks; long‑term hosting of materials.
Long‑Term Applications
- Agent certification standards for consequential web actions
- Sectors: policy/regulation, certification bodies, consumer protection
- What: Formalize live‑web, write‑heavy test batteries (with interception and human‑grounded evaluation) as prerequisites to deploy agents that transact on users’ behalf.
- Potential outcomes: Compliance labels (“transaction‑safe”), liability frameworks tied to pass‑rates and audited traces.
- Dependencies/assumptions: Multi‑stakeholder consensus; legal frameworks recognizing benchmark evidence; periodic re‑certification due to web drift.
- Training/fine‑tuning robust web agents with five‑layer supervision
- Sectors: AI labs, applied ML teams
- What: Use human‑aligned, multi‑modal traces for imitation/reinforcement learning (e.g., field binding, multi‑step planning, auth flows).
- Products: “Live‑Web Gym” datasets; curriculum learning pipelines; self‑play with safe interception.
- Dependencies/assumptions: Data licensing/privacy; compute for multi‑modal training; generalization beyond a single reference trajectory.
- Universal form‑filling middleware
- Sectors: finance, healthcare, government services, education
- What: A service that reliably maps user documents and profiles to heterogeneous web forms (account opening, claims, applications) with schema‑aware validation before submission.
- Products: “FormGuard” or “AutoFill+Review” with a mandatory dry‑run and agentic evaluator checks.
- Dependencies/assumptions: Cross‑site generalization; access to user documents; consent and data protection; evolving site schemas.
- Consumer personal assistants with built‑in “ghost mode”
- Sectors: consumer productivity, accessibility
- What: Assistants that preview all form submissions/bookings, surface captured payloads for user approval, and only commit once vetted.
- Products: Mobile/desktop agents with “Commit Gate” UX integrating interception summaries.
- Dependencies/assumptions: UX adoption; latency acceptable for user review; handling multi‑step, multi‑endpoint commits.
- Enterprise “Agent Guardrail Platform”
- Sectors: GRC, IT security, data loss prevention (DLP)
- What: Policy engine that intercepts terminal requests, checks them against org policies (sensitive fields, destinations), and logs 5‑layer evidence.
- Products: Middleware between agent frameworks and browsers; SOC dashboards for automated workflows.
- Dependencies/assumptions: Integration with identity/access management; continuous maintenance of endpoint specs; policy authoring burden.
- Platform‑provided dry‑run APIs and standards
- Sectors: web platforms, standards bodies (W3C/WHATWG), industry consortia
- What: Standardize “shadow submit” endpoints or headers that return full validation results without committing server state; expose schema for agents.
- Products: “/validate‑only” routes; manifest metadata for terminal requests.
- Dependencies/assumptions: Adoption incentives for platforms; backward compatibility; security considerations to prevent abuse.
- Dark‑pattern resilience evaluation and mitigation frameworks
- Sectors: policy, UX research, platforms
- What: Systematic tests that quantify agent susceptibility to misleading UI; certify both agents and sites for fair design.
- Products: Benchmark tracks with natural dark patterns on live sites; site badges for “agent‑friendly” UX.
- Dependencies/assumptions: Agreement on definitions/metrics; ethical testing on production.
- Sector‑specific benchmarks and agent co‑pilots
- Sectors: healthcare (claims/referrals), finance (KYC/AML forms), education (scholarship/enrollment), travel (complex itineraries)
- What: Curated task suites and specialized agents fine‑tuned for each domain’s forms and workflows, with rigorous dry‑run testing.
- Products: “ClaimsCopilot,” “KYC Assistant,” “EduApply Agent.”
- Dependencies/assumptions: Domain compliance (HIPAA, PCI, FERPA); secure data handling; partnership with platform providers.
- Autonomous service desks and back‑office automations with traceable assurance
- Sectors: IT, operations, procurement
- What: Agents that execute repeatable portal workflows (ticketing, approvals, vendor onboarding) with evaluator‑backed assurance and audit trails.
- Products: “ServiceBot with Proofs” that attaches step‑level evidence to each completed request.
- Dependencies/assumptions: Stable internal portals; change management processes; clear rollback and human override mechanisms.
- Benchmark‑driven research on evaluation science
- Sectors: academia, standards
- What: Study reliability/validity of LLM‑as‑judge evaluators using multi‑layer evidence; develop ensemble or rubric‑based evaluators for higher fidelity.
- Products: Open evaluator suites; protocols for cross‑evaluator agreement.
- Dependencies/assumptions: Access to multiple evaluator models; methods for adjudicating disagreements; reproducibility practices.
Cross‑cutting dependencies and assumptions
- Legal/ethical: Respect platform ToS, privacy laws, and consent when operating on live sites; store and handle recordings securely.
- Technical: Requires Chromium/CDP, Chrome extension permissions, and occasional test accounts; interception assumes a clearly identifiable “terminal” request (multi‑commit flows may need expanded specs).
- Reproducibility: Live‑web variance (A/B tests, layout changes, rate limits) affects stability; human‑grounded comparisons and full traces mitigate but don’t eliminate variability.
- Evaluator reliability: Current agentic evaluator relies on an LLM sub‑agent; bias and drift should be monitored, and adjudication strategies may be needed for high‑stakes use.
- Coverage: A single human reference trajectory may not capture all valid paths; evaluators and policies should tolerate benign alternative workflows where appropriate.
These applications leverage ClawBench’s core contributions—safe live‑web evaluation, comprehensive trace capture, and human‑grounded, traceable judging—to create immediate value in testing and governance, while enabling longer‑term products, standards, and training regimes that make transaction‑capable agents safer and more reliable.
Glossary
- Agentic Evaluator: An LLM-driven judging component that compares an agent’s behavior against a human reference across multiple evidence layers to decide task success. "We evaluate each recorded trajectory using an Agentic Evaluator, implemented by invoking a Claude Code sub-agent under a fixed evaluation rubric."
- AJAX: A technique for asynchronous web requests used to load or update page content without full reloads. "All other requests---page loads, AJAX calls for dynamic content, image fetches, analytics pings---pass through unmodified"
- CDP: Abbreviation for Chrome DevTools Protocol, a low-level interface to control and instrument the browser. "The instrumentation server connects to the browser through CDP to monitor all outgoing HTTP requests"
- Chrome DevTools Protocol: A protocol that exposes browser instrumentation and debugging capabilities programmatically. "All HTTP requests are logged via the Chrome DevTools Protocol, including request bodies, payloads and timing information."
- DOM: The Document Object Model; a structured representation of a web page’s elements used for programmatic interaction. "static HTML and fixed DOM structures"
- Ecological validity: The degree to which an evaluation reflects real-world conditions and complexity. "enabling safe evaluation on production websites without sacrificing ecological validity."
- FFmpeg: A multimedia toolkit used here to capture video recordings of browser sessions. "session replay via Xvfb virtual display and FFmpeg"
- Ground-truth trajectory: The human-executed reference sequence of actions and outcomes used for evaluation. "that the ground-truth trajectory is reproducible."
- Human-in-the-loop: A design where human experts provide critical annotations or oversight within the system. "This human-in-the-loop design ensures that the ClawBench framework intercepts precisely the intended request"
- HTTP payload: The body of an HTTP request that carries submitted data (e.g., form fields). "they produce observable HTTP payloads that enable objective verification."
- Instrumentation server: A service that connects to and monitors the browser to log actions and network traffic for evaluation. "The instrumentation server connects to the browser through CDP"
- Interception signal: A human-annotated specification of the exact network request to block for safety during evaluation. "every task's interception signal---the specific HTTP endpoint, request method, and payload schema"
- LLM-as-judge: An evaluation approach where a LLM assesses task success. "LLM-as-judge"
- Payload schema: The structured set of fields and format defining the contents of a submission payload. "payload schema that identifies the dangerous, inreversable submission"
- Request schema: The structured specification of required fields and format used to validate a final submission. "a structured justification grounded in the request schema and step-level evidence."
- Sandbox: A controlled, isolated environment that replicates websites for safer, more reproducible evaluation. "evaluate agents in offline sandboxes with static HTML, fixed DOM structures, no authentication, and no dynamic content"
- Session replay: A full-session video capture of the browsing interaction for later review and analysis. "session replay via Xvfb virtual display and FFmpeg"
- State-changing: Describes operations that modify server-side state (e.g., purchases, reservations, submissions). "similar state-changing operations."
- Terminal request: The specific final HTTP request that would commit an irreversible transaction if not intercepted. "the extension correctly intercepted the terminal request in 100% of the human ground-truth runs"
- Trajectory (agent trajectory): The recorded sequence of an agent’s observations, actions, and effects during a task. "the agent trajectory, and the human reference trajectory,"
- Xvfb: A virtual framebuffer display server used to run and record a browser without a physical display. "via Xvfb virtual display and FFmpeg"
- Write-heavy: Characterizing tasks dominated by form-filling and submissions rather than pure information retrieval. "write-heavy, state-changing tasks"
Collections
Sign up for free to add this paper to one or more collections.

