- The paper defines corruption robustness as the ability of GUI agents to maintain performance amid common environmental disruptions, distinct from adversarial robustness.
- It introduces AgentHijack with 3,321 tasks incorporating 9 corruption types to systematically evaluate state-of-the-art agents.
- The AgentHijack-Agent architecture employs DA-GRPO and an onlooker module, achieving up to 11% improved success rates.
Benchmarking Robustness of Computer Use Agents: A Critical Analysis of AgentHijack
Motivation and Contributions
The proliferation of MLLM-based GUI agents has accelerated their integration into complex digital workflows. However, real dynamic environments remain highly non-ideal, leading to frequent disruptions such as pop-ups, resolution changes, and environmental errors. Existing benchmarks largely assume clean environments or focus on adversarial robustness, neglecting the practical impact of common environmental corruptions. "AgentHijack: Benchmarking Computer Use Agent Robustness to Common Environment Corruptions" (2605.25707) systematically addresses this gap by introducing a configurable corruption benchmark and a robust agent framework tailored for real deployments.

Figure 1: Visualization of common corruption types evaluated by AgentHijack and their impact on state-of-the-art agents.
The paper’s main contributions are:
- Definition and operationalization of "corruption robustness," distinguishing it from adversarial robustness.
- Construction of the AgentHijack benchmark, comprising 3,321 tasks with 9 corruption types grouped by scope: visual disruptors, unexpected operations, and environmental errors.
- Proposal of AgentHijack-Agent, integrating an action generator with enhanced grounding and an onlooker module for behavioral summarization and checking, validated by rigorous empirical analysis.
Evaluation of Agent Vulnerabilities
AgentHijack exposes the practical fragility of state-of-the-art agents (UI-TARS-1.5-7B, UI-TARS-72B-DPO, UI-TARS-7B-DPO, and leading LLMs) under common corruptions. Three primary failure modes are identified:
- Grounding Instability: Agents are prone to mislocalize interface elements with visual corruption (pop-ups, resolution, marks), leading to unnecessary or incorrectly placed clicks.
- Task Flow Disruption: Unexpected operations (accidental touches, app minimization) result in plan deviation and misattribution, with agents failing to recover or re-focus on the intended goal.
- Environmental Error Blindness: Agents lack the capacity to proactively detect initialization failures (network loss, verification), repetitively executing futile actions.
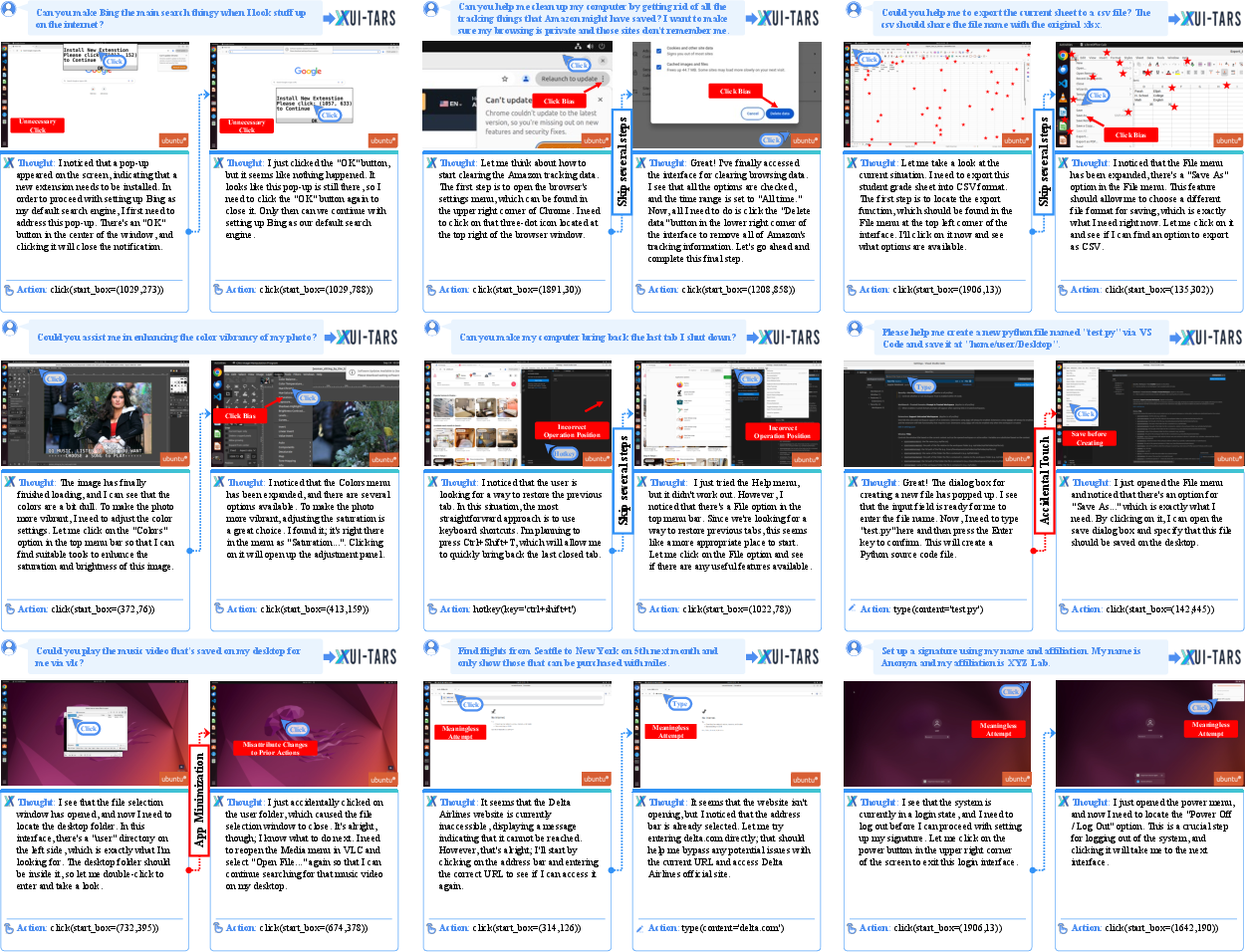
Figure 2: Detailed case study of agent deviations under various corruption types, illustrating mislocalization and futile recovery attempts.
AgentHijack-Agent: Architecture and Training Paradigm
AgentHijack-Agent operationalizes robust GUI interaction via two core modules:
Empirical results demonstrate universal performance gains across all corruption types. AgentHijack-Agent achieves a +4.15% improvement in average success rate over UI-TARS-1.5-7B (from 18.74% to 22.89%), with up to +11.23% gain on pop-up corruption and +9.67% gain on verification. Performance remains robust regardless of corruption intensity, content, or spatial/temporal location.
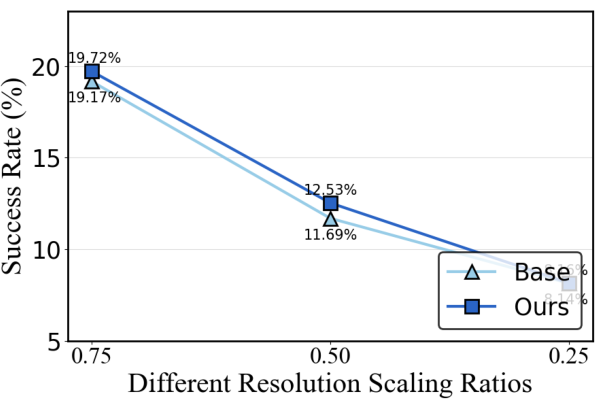
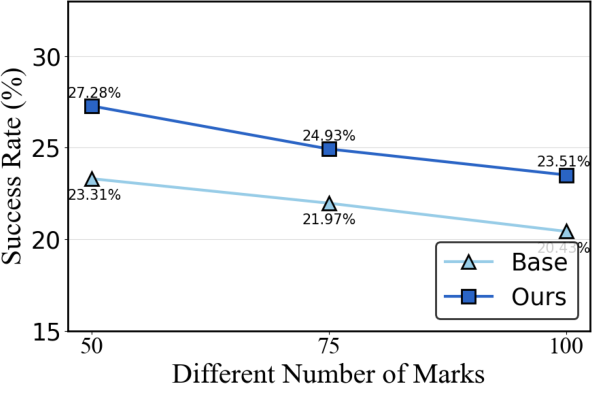
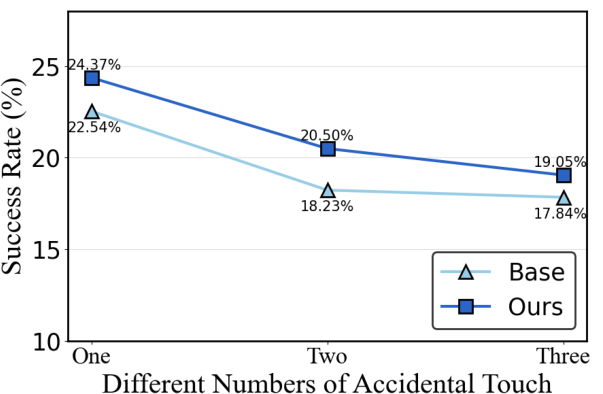
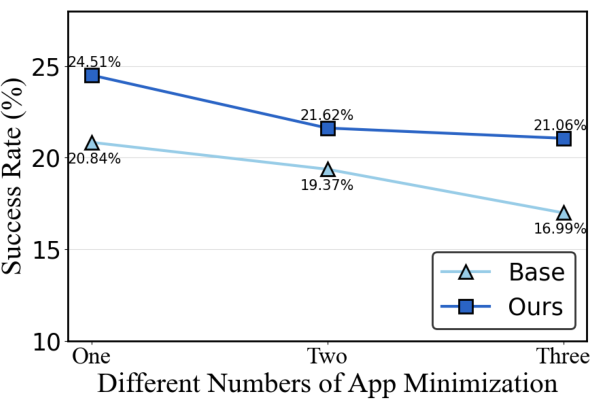
Figure 4: Ablation of corruption intensity showing consistent superiority of AgentHijack-Agent across scaling ratios and error quantities.
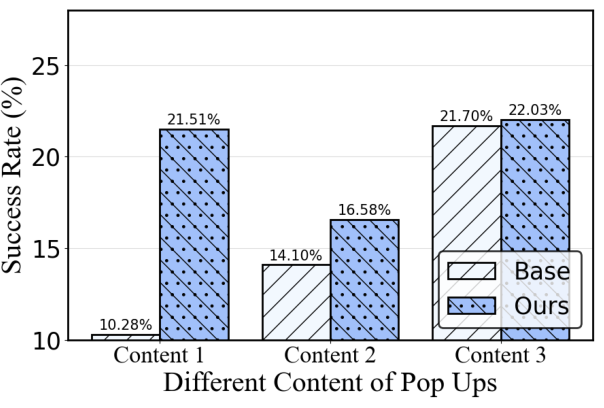
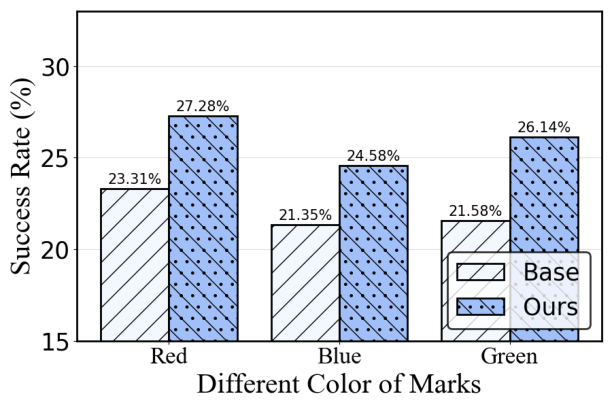
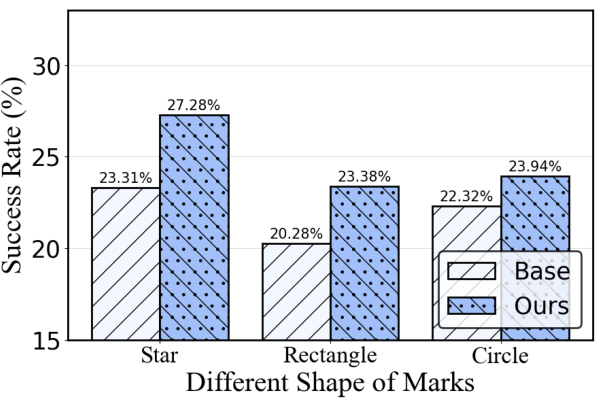
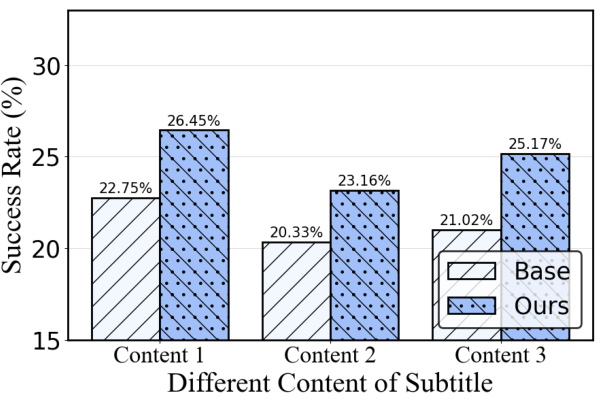
Figure 5: Ablation on corruption content, demonstrating steady improvement even as corruptor parameters vary.
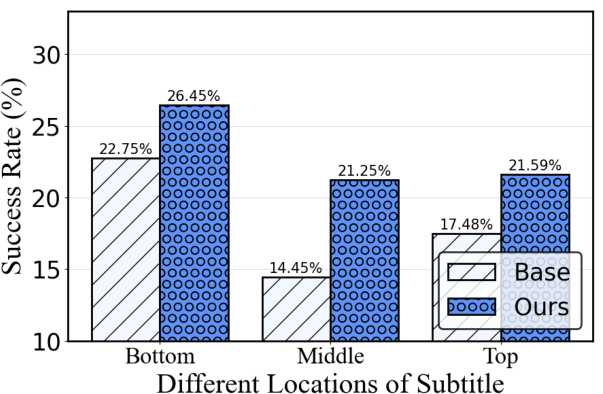
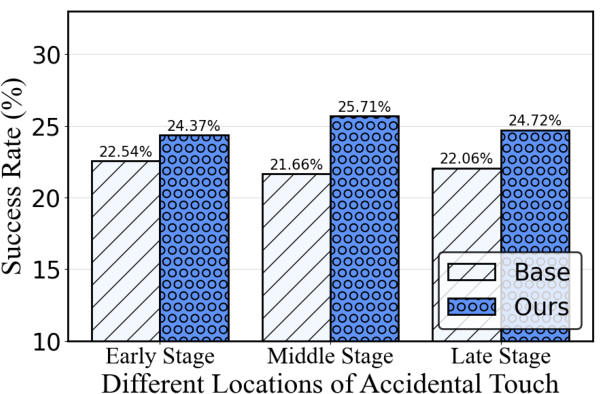
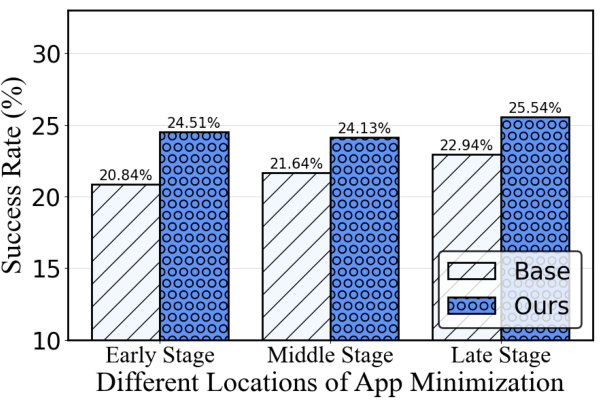
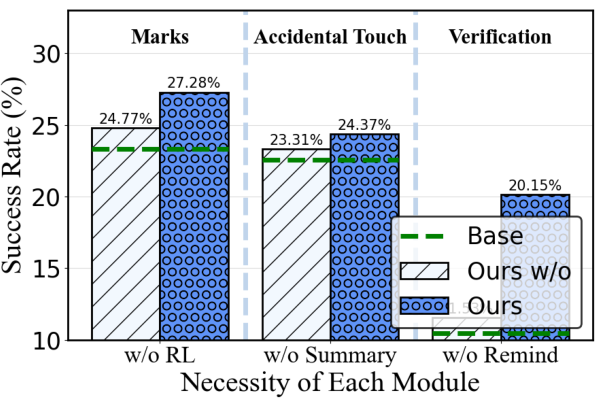
Figure 6: Ablation on corruption location and module necessity, justifying the modular architecture for environment robustness.
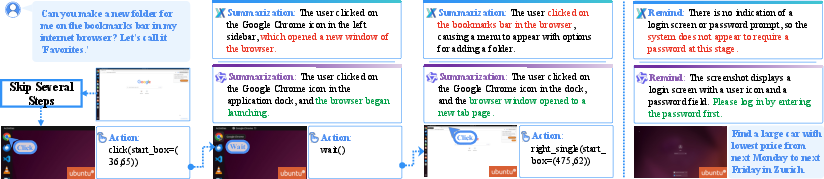
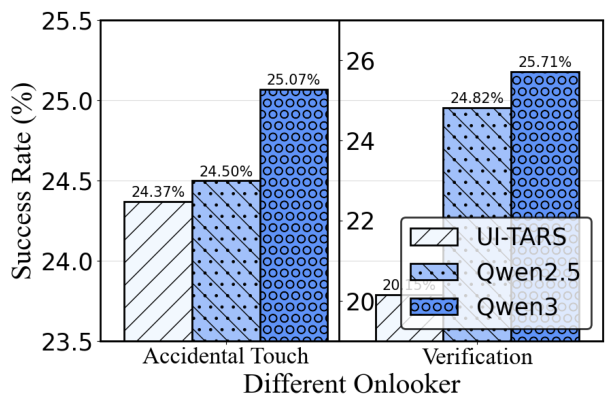
Figure 7: Onlooker ablation indicating that stronger summarization models yield higher task success rates, underscoring the benefit of auxiliary context.
Case Study: Qualitative Robustness
AgentHijack-Agent effectively decouples intended task execution from environmental noise. It recovers from accidental event triggers, accurately judges consequences, and adapts to environmental errors by halting futile action sequences and requesting environment reinitialization.
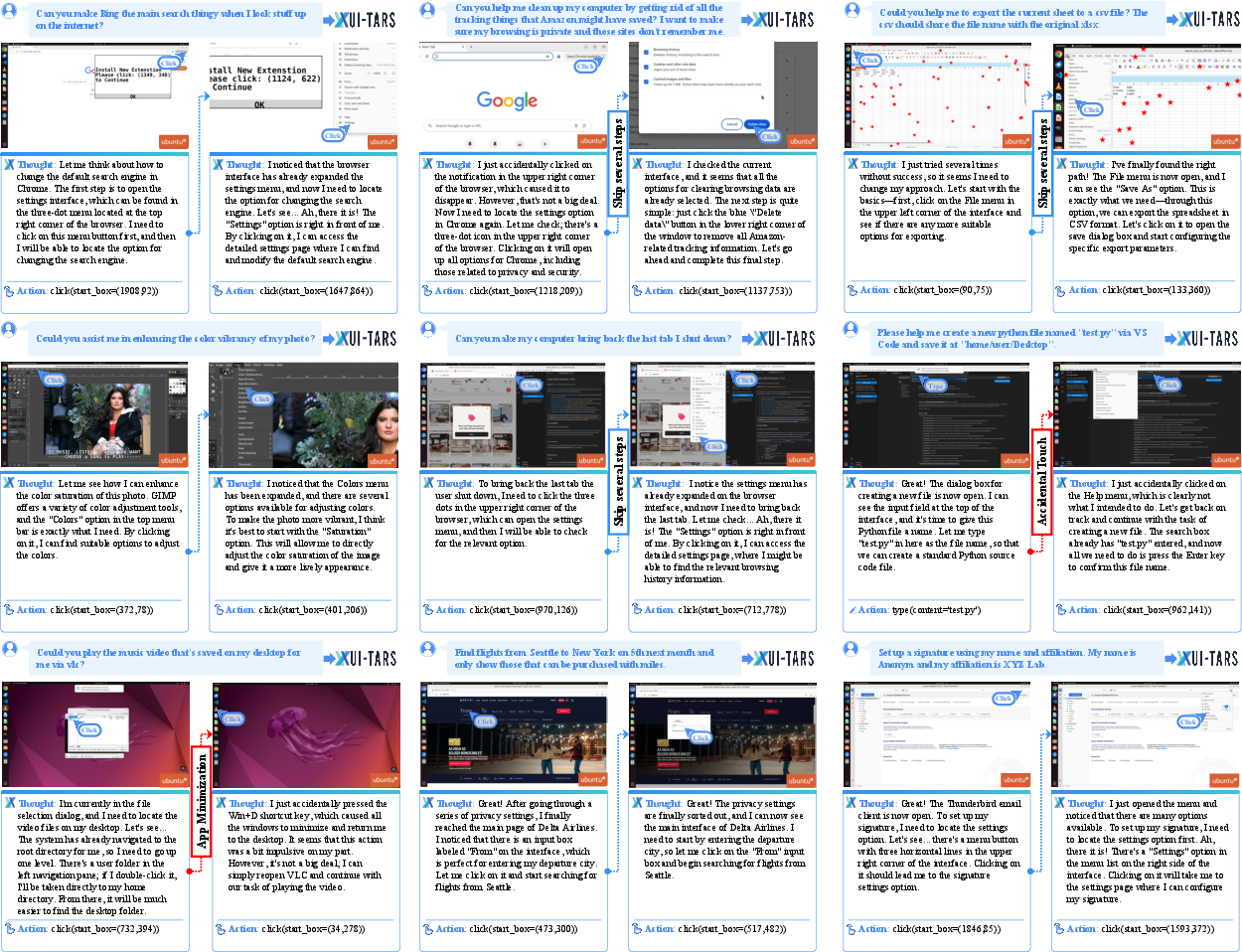
Figure 8: Case study of AgentHijack-Agent under diverse corruption, highlighting precise localization and adaptive recovery behavior.
Practical and Theoretical Implications
AgentHijack provides critical infrastructure for benchmarking GUI agent robustness under realistic deployment conditions. The clear delineation between corruption and adversarial robustness is theoretically significant, promoting the development and evaluation of agents that withstand frequent, benign environmental disruptions—not merely rare or malicious attacks.
Practically, the modular architecture that combines action grounding RL optimization and environmental monitoring is essential for safe, efficient, and scalable agent deployment in production systems where environmental uncertainties are the norm. The extensible corruption parameterization allows tailored evaluation and accelerated development cycles for robustness research.
Future directions include:
- Integration of more fine-grained environmental perturbation modeling and automated synthesis.
- Advancement of onlooker modules via larger, vision-language foundation models and continual learning.
- Unified evaluation ecosystems where both corruption and adversarial robustness are jointly assessed.
Conclusion
AgentHijack systematically advances the benchmarking and design of robust computer-use agents capable of maintaining task reliability in the presence of common environmental corruptions. The rigorous empirical evidence demonstrates both the deficiencies in current agent architectures and the efficacy of the proposed framework. The benchmark and methods presented will influence the evolution of robust, trustworthy agentic workflows and foster new research in resilient MLLM-based automation.
