- The paper introduces a comprehensive 538-task benchmark to evaluate autonomous desktop GUI agents on professional workflows and human-in-the-loop collaboration.
- The methodology formalizes GUI agent evaluation as a deterministic, execution-grounded control problem, categorizing tasks into atomic, compositional, and long-horizon levels.
- Experimental results reveal that even state-of-the-art agents exhibit limited reliability and consistency, highlighting challenges in planning, state tracking, and interactive adaptation.
DeskCraft: Benchmarking Desktop Agents on Professional Workflows and Human-in-the-Loop Collaboration
Motivation and Benchmarking Landscape
Recent advancements in multimodal LLMs have catalyzed research into autonomous desktop GUI agents. However, extant benchmarks predominantly focus on short-horizon, atomic tasks and lack coverage of professional, long-horizon workflows or systematic human-in-the-loop (HITL) protocols. This limitation stymies progress toward robust desktop agents capable of sustained, complex, and collaborative operations in real-world scenarios.
DeskCraft is introduced to close this gap, providing a 538-task benchmark with a multi-level difficulty taxonomy, comprehensive application/domain coverage, and a structured, executable protocol for human-agent collaboration.
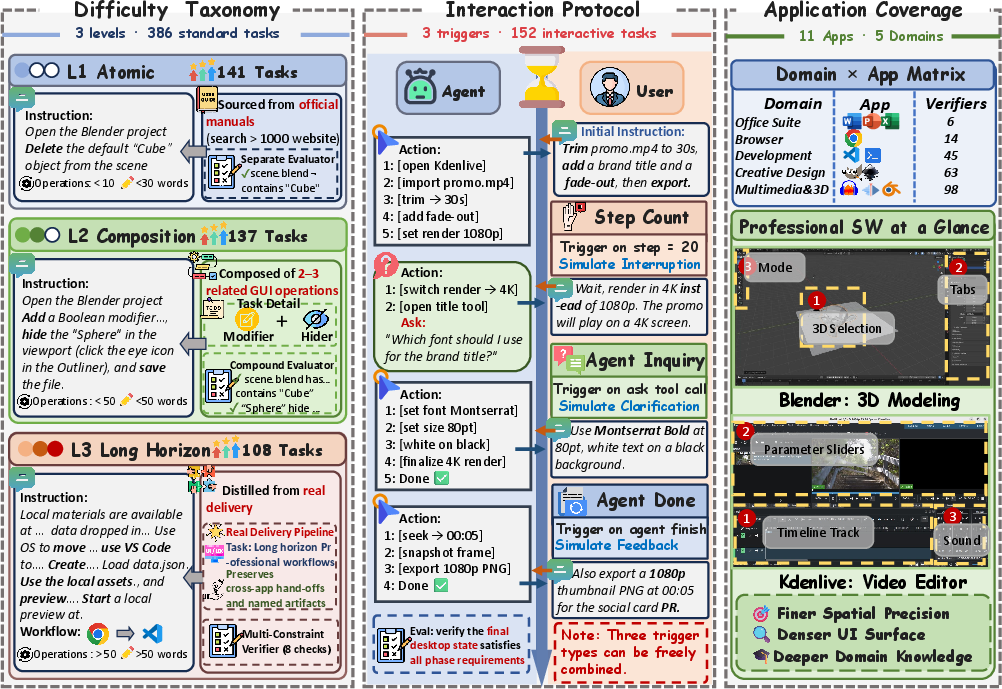
Figure 1: Overview of DeskCraft: taxonomy of 386 standard tasks across three difficulty levels, 152 interactive tasks structured by composable triggers, and coverage of 11 applications across 5 domains with substantial domain complexity.
DeskCraft formalizes GUI agent evaluation as a deterministic, execution-grounded control problem in realistic desktop environments. The benchmark defines each task as a tuple τ=(s0,u0,Φ,E,R), comprising the initial desktop state, instruction(s), explicit interaction phases, the execution environment, and a deterministic evaluation function.
The tasks are categorized across three execution-centric levels:
- L1 (Atomic): One-shot, well-specified atomic GUI actions (e.g., editing a text field).
- L2 (Compositional): Small workflows requiring composition of 2–4 dependent operations.
- L3 (Long-Horizon): Real-world, interdependent multi-step workflows distilling professional scenarios (e.g., 3D scene rendering, multi-track audio, video pipeline assembly).
The actual task length and complexity are empirically validated, with L3 tasks requiring an order-of-magnitude more steps, longer instructions, and richer evaluator policies (Figure 2).
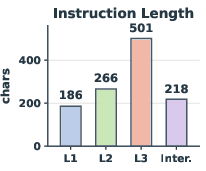
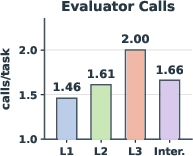

Figure 2: Mean instruction length increases commensurately from L1 to L3, correlating with higher semantic complexity.
Human-in-the-Loop Interaction Protocol
Unlike static benchmarks, DeskCraft explicitly models rich human-agent interaction through a composable trigger protocol supporting mid-turn and post-turn goal evolution:
- Mid-Turn Interaction:
- Agent-initiated clarification (agent_ask): agent raises clarification queries under ambiguity.
- User-initiated interruption (step_count): users interject with new requirements based on execution progress.
- Post-Turn Interaction:
- Feedback/correction (agent_done): after the agent signals completion, users may evaluate and revise deliverables.
Each interactive task consists of multiple deterministic phases, with a simulator LLM ensuring reproducibility.
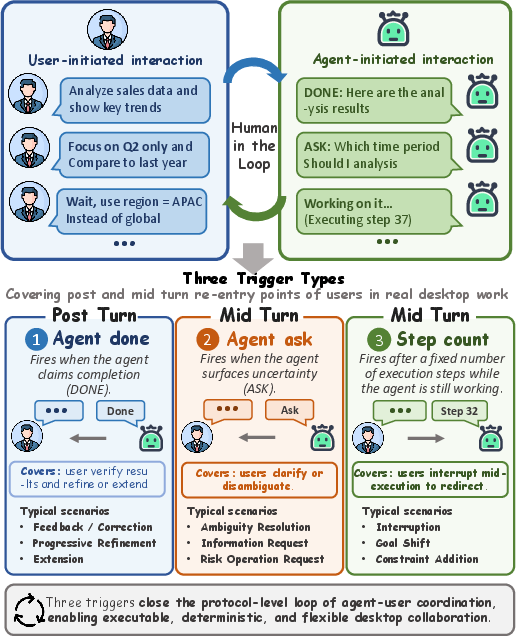
Figure 3: DeskCraft interaction protocol: phase advancement via agent_done, step_count, or agent_ask triggers, operationalizing realistic human-agent workflows.
Application and Domain Coverage
DeskCraft significantly expands professional software coverage, including office suites, professional creative tools (GIMP, Inkscape, Kdenlive, Audacity, Blender), and multi-application developer workflows. Distributions of task types and assets are systematically stratified (Figure 4).
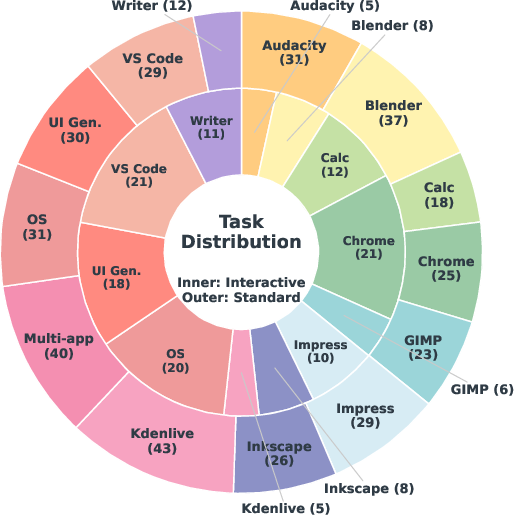
Figure 4: Per-application breakdown of standard and interactive tasks; multi-application workflows constitute a substantive fraction, reflecting industrial relevancy.
Tasks are systematically derived from official documentation, tutorials, and practitioner workflows, ensuring relevance, diversity, and evaluation reproducibility.
Experimental Evaluation
Agent Cohort
The benchmark is used to evaluate 18 agents subdivided into:
- Proprietary frontier models: GPT-5.4, Kimi-K2.6, Kimi-K2.5
- Open-source generalist VLMs: Qwen3-VL series, Qwen3.5, Qwen3.6
- Open-source GUI-focused CUA models: EvoCUA, GUI-Owl, OpenCUA, OS-Atlas-Pro, UI-TARS
Overall Task Success
The strongest models exhibit sharply limited performance:
- Kimi-K2.6 achieves 33.8% on standard tasks (L1–L3), GPT-5.4 achieves 31.6%.
- Interactive (HITL) regime is strictly harder: GPT-5.4 tops at 27.6%, Kimi-K2.6 at 25.7%.
This gap underscores bottlenecks in sustained planning, multi-phase coordination, and interactive capacity.
Run-to-Run Reliability
Increasing rollouts raises pass@k (fraction of tasks completed at least once out of k attempts), but passk (fraction of tasks succeeded in all k attempts) declines, indicating pronounced stochasticity and lack of agent robustness (Figure 5).
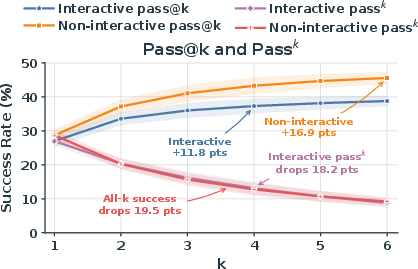
Figure 5: Kimi-K2.6 pass@k and passk trends; success rates rise with attempts per task but consistent success remains elusive, highlighting scenario brittleness.
Long-Horizon Analysis
Performance degrades steeply with increased workflow length and interdependence. While extending action budgets from 100 to 300 steps recovers a minority of remaining successes, most agents saturate early, suggesting fundamental limitations in long-range planning and state management.
Human-Agent Collaboration: Scenario Breakdown
Analysis across interaction scenario families (progressive refinement, ambiguity, correction, interruption):
- Agents perform best when revisions/feedback are explicit and local (correction).
- Performance on interruption and requirement-change is low, with agents frequently failing to replan or recover workflow state mid-execution.
- Most agents do not proactively request clarifications under underspecified instructions; overcommitment to ambiguous goals is the dominant failure mode.
Implications and Future Directions
DeskCraft exposes a persistent delta between LLM-driven GUI agents and industrial requirements for robust desktop automation:
- Current frontier agents exhibit only partial competence on sustained, multi-phase workflows, and fail to generalize across professional domains and HITL scenarios.
- Reliability and consistency across runs remain a critical challenge, even for the highest-performing systems.
- The bottleneck in agent design is shifting from GUI grounding to workflow-level planning, execution monitoring, and interactive adaptation.
- HITL protocols reveal that richer interaction models—not just larger models or training corpora—are needed for deployment-grade agents.
DeskCraft will serve as a foundational testbed for advances in curriculum learning, explicit world-state modeling, cooperative planning, interactive RLHF, and controlling long-range agent drift. Its emphasis on deterministic, verifiable evaluation and scenario richness provides a necessary substrate for measurable progress.
Conclusion
DeskCraft establishes a new standard for desktop agent evaluation, unifying long-horizon, human-in-the-loop, and professional workflow tasks into a reproducible benchmark. Experimental results unequivocally demonstrate that current multimodal agents, both proprietary and open-source, fail to reliably operationalize realistic desktop workflows. Progress will require conceptual advances in agent planning, robust state tracking, and dynamic HITL coordination—directions that DeskCraft now enables to be measured scientifically.
Reference: "DeskCraft: Benchmarking Desktop Agents on Professional Workflows and Human-in-the-Loop Collaboration" (2606.03103)

