Continuous Reasoning for Vision-Language-Action
Abstract: Natural language is a powerful reasoning medium for language and vision-LLMs, but it is mismatched to the granularity of continuous control. Text and explicit subgoals operate at task-level granularity, whereas vision-language-action (VLA) policies must choose actions at a much finer temporal scale; a single reasoning step can therefore span many action chunks while remaining only weakly coupled to the action needed now. This suggests a different question for VLA: what should play the role of language? We argue that a useful VLA reasoning medium must be shareable across model instances, verifiable through downstream action improvement, and aligned with temporally extended control structure. Based on this view, we propose Continuous Reasoning for Vision-Language-Action. Our model first predicts continuous reasoning in the form of a structured set of continuous thoughts, then reuses them as shared context for chunk-structured action generation. Better action prediction alone does not certify good reasoning: if the same internal medium cannot be shared across model instances and independently verified through improved downstream control, the added latent may simply become a model-private shortcut that helps on seen behaviors without supporting generalizable control. We therefore instantiate continuous reasoning as a shared Gaussian latent interface and train it with a self-verification objective in which an exponential-moving-average teacher must successfully consume the student's reasoning when predicting target actions. Empirically, Continuous Reasoning improves LIBERO-PRO robustness and performs strongly on real robots, raising mean subtask success over π0.5 by 40.4% on TX-G2, an AgiBot G2-compatible variant, and 26.3% on HSR. This suggests that reasoning in VLA is less about extra tokens than about a shareable, verifiable internal language for action.








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Continuous Reasoning for Vision-Language-Action”
1) What is this paper about?
The paper is about teaching robots to think in a way that fits how they move. Today, many smart systems “reason” using words (like a step-by-step explanation in text). That works for answering questions, but it doesn’t match how robots control their arms and bodies, which happens smoothly and quickly over time. The authors propose a new kind of “inner language” for robots: not extra words, but a shared set of continuous, numeric thoughts that help the robot plan and act more reliably.
2) What questions are the researchers asking?
They ask: If robots need to reason before acting, what should that reasoning look like?
They say a good reasoning medium for robots should:
- Be reusable: if one model creates a good plan, another model should benefit from it.
- Be shareable: the plan should live in a common format that different models can read.
- Be the right size in time: it should match the rhythm of actions, guiding short action clips rather than just describing the whole task in vague words.
3) How did they do it? (Methods, in everyday language)
The team builds a robot control system that creates and uses “continuous thoughts” before producing actions.
Here’s the idea using simple analogies:
- Continuous thoughts are like silent sticky notes written in numbers instead of words. They are not sentences; they’re compact, precise hints the robot can use during movement.
- A shared number language: They map these thoughts into a common “alphabet” of numbers shaped like a bell-curve world (a Gaussian space). This makes the thoughts easy to share between different versions of the robot model.
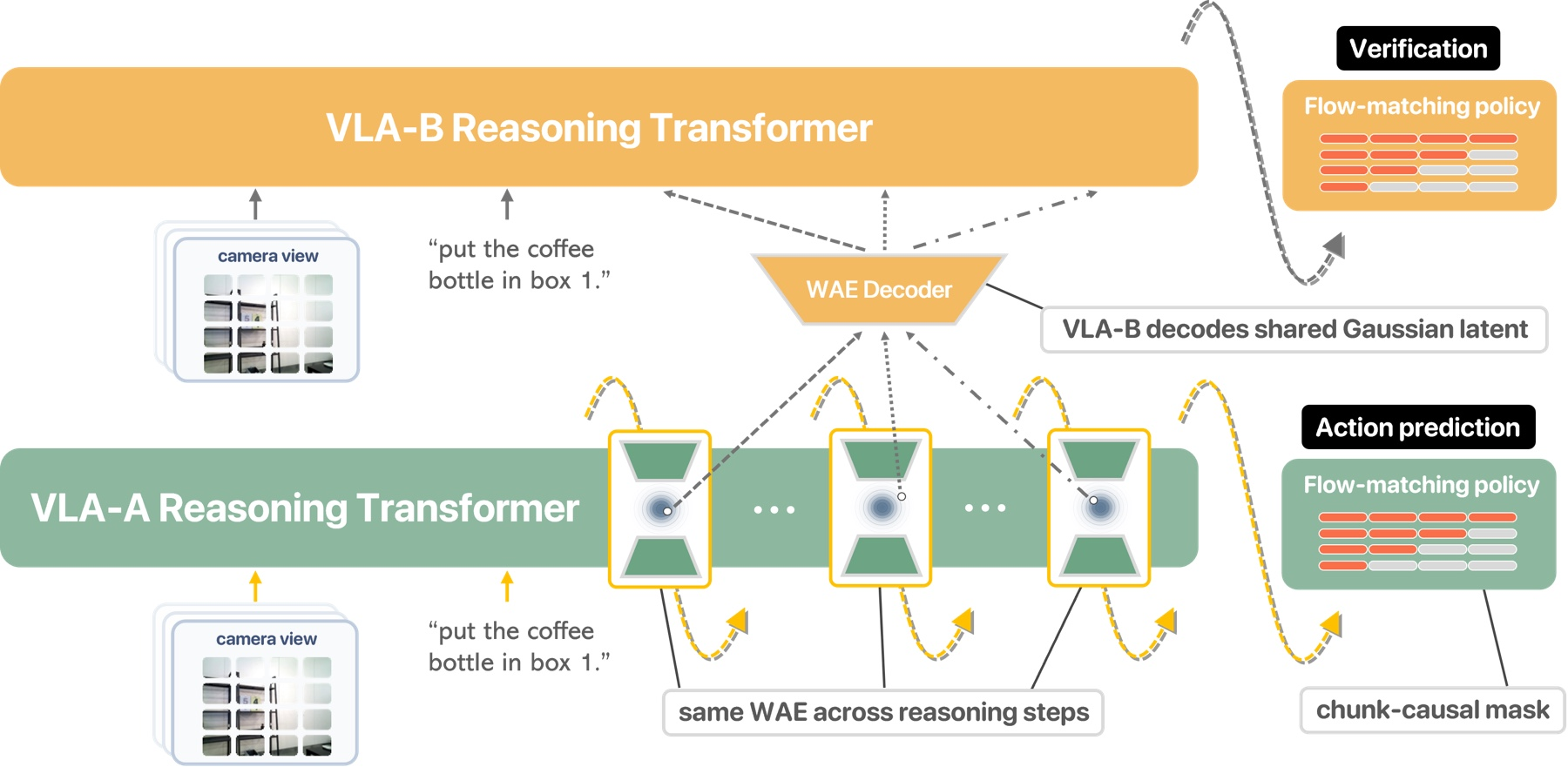
- Organizing the notebook (WAE): They use a tool called a Wasserstein autoencoder (WAE) to tidy and structure these thoughts so they’re not messy or private to just one model. Think of it as teaching everyone to write their sticky notes in the same handwriting and style.
- A careful teacher checks the notes (EMA teacher): During training, there’s a “teacher” model that is a slowly updated copy of the student. The teacher must read the student’s numeric thoughts and still predict the right actions. If the teacher can use those thoughts to act well, the thoughts are truly reusable and not just a private trick.
- Action clips (“chunks”): Instead of deciding every tiny motor movement one by one, the robot predicts short action clips in sequence (like planning a few seconds at a time). These clips line up better with the continuous thoughts than long, wordy plans.
- Learning to “denoise” actions (flow matching): To train actions, they practice turning noisy, blurred action sequences into clean ones. This is like learning to remove static from a radio signal so the music (the action) comes through clearly.
Putting it together: The robot first writes a few silent numeric thoughts, converts them into the shared number space, and both the student and the teacher use those shared thoughts to generate the action clips. The training rewards them only if the thoughts help both models act better, making the “reasoning” truly shareable and useful.
4) What did they find, and why does it matter?
They tested on tough robot benchmarks and real robots.
Main results:
- On a challenging test called LIBERO-PRO (which changes object positions, task goals, and looks), their method was more robust, especially when objects were moved or when the goal changed. That means the robot could better re-aim its actions when the world didn’t match training.
- On real robots (TX-G2 and HSR), they raised average subtask success by about 40.4% on TX-G2 and 26.3% on HSR compared to a strong baseline. This is a big jump for real-world performance.
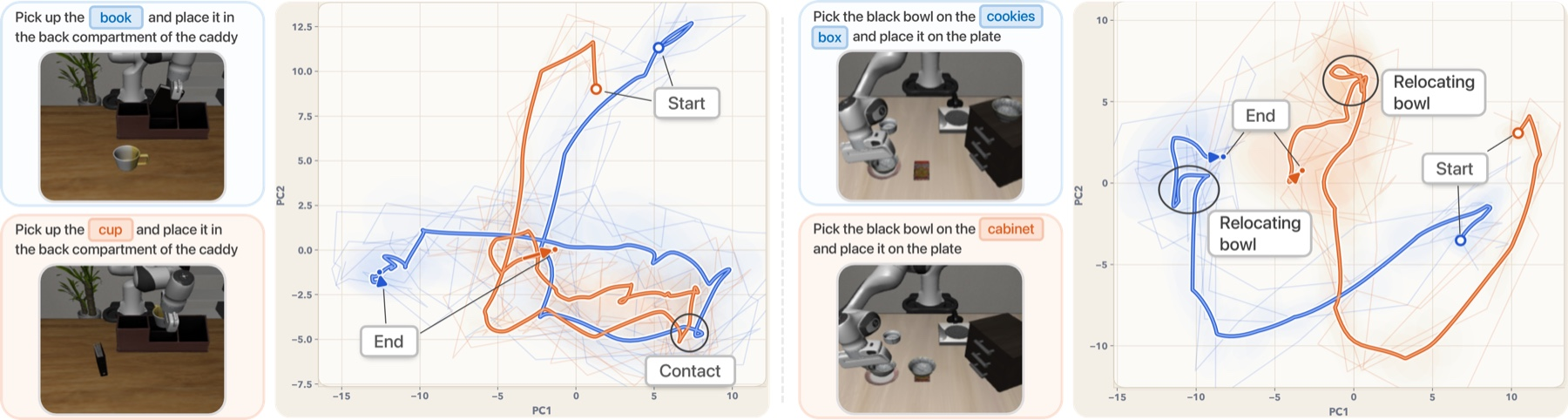
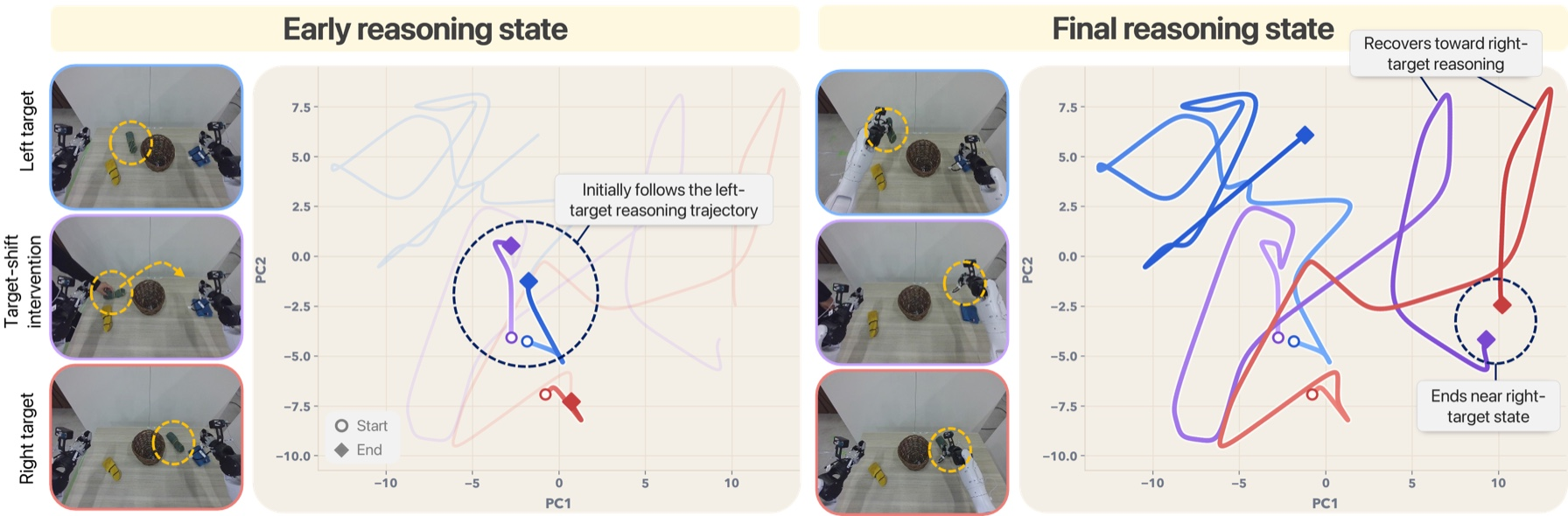
- Visual checks of the robot’s internal thoughts showed they adapt in phases (like approach, grasp, place) and re-anchor when the scene changes mid-run. For example, if a target object is moved during the task, the thought patterns shift accordingly, not just replaying the original plan.
- When they removed pieces of the method (like the shared number space, the teacher check, the action clips, or the continuous thoughts), performance dropped—especially for the hardest “position” and “task change” challenges. This suggests each piece is important.
Why it matters: These gains show that “reasoning for robots” should be more like a compact, shareable inner language of numbers that matches the timing of actions—not just more text.
5) What’s the impact of this research?
This work suggests a shift in how we think about robot planning:
- Instead of forcing robots to reason in words, give them a shared, testable internal language that fits smooth, continuous control.
- This could lead to more reliable home and workplace robots that can adjust when objects move, goals change, or the environment shifts.
- It may also help different robot models share know-how more easily, since they can pass around these standardized “thought codes.”
- Looking ahead, this approach could improve safety and generalization, and it raises new research questions like how to make these numeric thoughts more interpretable to humans while keeping their precise control benefits.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future work could address.
- Cross-model reusability: Validate whether thought codes are genuinely shareable by training producer–consumer pairs with different architectures/backbones, state encoders, and action decoders, and measuring performance when consuming each other’s thoughts without fine-tuning.
- Cross-embodiment transfer: Test whether thoughts produced by one robot (e.g., TX-G2) can be consumed by another (e.g., HSR) for comparable tasks, and quantify the degradation and conditions required for transfer (e.g., re-alignment layers, calibration).
- Independence of the verifier: Replace the EMA teacher with a truly independent consumer (non-EMA, different random seed/initialization, capacity, and training objective) to determine whether self-verification reflects real reusability rather than teacher–student coupling.
- Directional reuse: Evaluate both directions of reuse (teacher consumes student thoughts; student consumes teacher thoughts) and cross-pair reuse among a pool of models to establish symmetry and robustness of the shared interface.
- Bypass detection: Perform intervention tests (randomizing or zeroing thought codes at inference) to quantify the causal dependence of action prediction on the reasoning interface versus hidden bypasses through observation streams.
- Counterfactual thought swaps: Swap thought codes between different instructions/scenes while holding observations constant to test whether actions track the thought codes (faithfulness) and to measure error modes (e.g., spurious correlations).
- Information content and capacity: Measure mutual information between thoughts and actions/goals; sweep latent dimensionality, number of thought slots, and WAE bottleneck strength to find capacity–generalization trade-offs and detect posterior collapse.
- Prior choice sensitivity: Compare Gaussian WAE prior against alternative priors (mixture-of-Gaussians, hyperspherical, flow-based) and matching losses (adversarial, sliced-Wasserstein) to test how latent geometry affects shareability and robustness.
- Curriculum and thought slot scheduling: Analyze sensitivity to the thought-slot curriculum (S_curr), variable number of thoughts per episode, and adaptive slot allocation conditioned on task complexity/horizon.
- Online thought updates: The method generates thoughts once per horizon; systematically evaluate mid-episode updating/truncation (event-triggered or periodic refresh) under dynamic perturbations and partial observability.
- Granularity alignment: Ablate chunk size (C), number of chunks (K), and block-causal masking to map where the interface best aligns with control granularity and when it collapses to low-level noise or high-level semantics.
- Scaling to long horizons: Test performance and memory/computation scaling for substantially longer action horizons (e.g., minutes-long manipulation+navigation), including KV-cache and interface reuse costs.
- Backbone generality: Validate the approach with alternative action-generation backbones (diffusion transformers, autoregressive token policies, hybrid planners) to ensure the interface is not specific to flow-matching.
- Data efficiency: Measure gains in low-data regimes and few-shot task adaptation to test whether continuous reasoning improves sample efficiency versus action-only baselines.
- Robustness breadth: Beyond LIBERO-PRO, evaluate against systematic sim-to-real gaps, heavy sensor noise, latency, lighting changes, distractor motion, and adversarial perturbations to quantify robustness envelopes.
- Failure-mode taxonomy: Provide a detailed analysis of failure cases (especially where object/semantic performance remains “spuriously forgiving”), including where continuous reasoning harms performance or induces overcommitment to outdated plans.
- Comparative baselines: Include strong token-based/multimodal planning baselines with matched compute and decoding budgets (e.g., explicit subgoals, visual foresight) to isolate benefits of continuous thoughts over explicit reasoning traces.
- Fairness in real-robot comparisons: Address omitted baselines due to OOM by normalizing memory/throughput constraints (e.g., distilled variants) to establish fair head-to-head comparisons.
- Reuse beyond training partner: Demonstrate offline sharing—build a “thought library” produced by one model and consumed by another to improve performance or sample efficiency without joint training.
- Task compositionality: Test whether thoughts compose across instructions (e.g., combine two seen subtasks into an unseen compound task) and whether the interface supports zero-shot recomposition.
- Semantics alignment: Investigate alignment between thought codes and human-interpretable semantics (language phrases, spatial templates); explore supervised/weakly supervised alignment (text prompts ↔ thought projections) without sacrificing control fidelity.
- Quantitative “reusability” metric: Define and report a standardized metric for reusability/shareability (e.g., cross-consumer performance uplift over action-only baselines under frozen consumers) rather than relying solely on EMA teacher loss.
- Safety and adversarial thought injection: Study how malicious or noisy thought codes affect behavior; design authentication, gating, or consistency checks to prevent unsafe execution when thoughts are shared across agents.
- Multi-agent coordination: Evaluate whether shared continuous thoughts enable coordination (e.g., handovers, joint placement) and how to design multi-agent communication protocols over the same latent interface.
- Verification strength: Explore stronger verification signals (contrastive verification with negatives, cycle-consistency between producer and consumer, or reward-based verification in RL) to prevent decorative thoughts.
- RL integration: Investigate combining the interface with reinforcement learning (policy gradients, offline RL) and whether reward-conditioned thought formation improves long-horizon credit assignment.
- Task-phase awareness: Formalize and detect phase boundaries in the latent trajectories; test whether explicit phase supervision or constraints yield more stable re-anchoring and fewer mid-episode regressions.
- Theoretical grounding: Provide control-theoretic or information-theoretic analysis (e.g., minimal sufficient statistics for chunked control) to clarify when a shared continuous interface is necessary/sufficient for optimal action.
- Generalization across sensors: Evaluate modality robustness and transfer (RGB-only → RGB-D, multi-view, proprioception, tactile) and whether the same thought prior supports heterogeneous sensors.
- Compute/latency budget: Report training and inference costs, latency under real-time control, and scalability with additional cameras/sensors; assess whether the interface introduces bottlenecks in high-frequency control loops.
- Interoperability with planners/maps: Test integration with explicit planners (e.g., navigation maps, grasp planners) to see if thoughts can serve as a glue layer for hybrid systems and improve global–local coordination.
- Evaluation transparency: Release full E2E results (not only subtask success), hyperparameter sweeps, and seeds for reproducibility; detail dataset splits and coverage to contextualize robustness claims.
Practical Applications
Below is a structured summary of practical applications that derive from the paper’s core ideas: a reusable, shareable, and control-aligned “continuous reasoning” interface (WAE-structured Gaussian latent thoughts), chunk-structured action generation with flow matching, and self-verification via an EMA teacher. The list is grouped by immediacy and highlights sectors, potential tools/workflows, and feasibility dependencies.
Immediate Applications
- Robotics/Logistics: robust pick-and-place under layout change
- Sector: Robotics, Warehousing, Manufacturing
- Use case: Bin picking, kitting, shelf restocking, machine tending where object positions and fixtures change frequently; automatic retargeting of grasps/placements when pallets or trays shift.
- Tools/products/workflows: “Retargetable Picking Controller” built on chunked flow-matching + CR latent interface; Reasoning cache (server) to reuse thought codes across shifts/robots.
- Dependencies/assumptions: Sufficient task data with spatial/task perturbations; multi-camera perception; 10–20 Hz control loop; integration into existing ROS/PLC stacks; GPU for training and edge inference.
- Domestic/Service robots: resilient household manipulation
- Sector: Consumer robotics, Assistive tech, Hospitality
- Use case: Laundry sorting, dish loading, simple food/utensil handling where humans move items mid-execution; reduce brittle plan replay.
- Tools/products/workflows: “Household Task Module” (laundry/dishes) leveraging CR; latent “flight recorder” for episode-level diagnostics and improvements.
- Dependencies/assumptions: Safety constraints and force limits; curated in-home datasets; on-device privacy-preserving training; stable camera calibration.
- Mobile manipulation in hospitals/hospitality
- Sector: Healthcare, Facilities, Hospitality
- Use case: Fetch-and-place across rooms (e.g., bottles, trays), repeated nav→manipulation cycles with changing placements.
- Tools/products/workflows: HSR-compatible navigation–manipulation stack with chunk-causal control and horizon-level reasoning; EMA self-verification for deployment checks.
- Dependencies/assumptions: 2–5 Hz control loops for mobile platforms; reliable indoor navigation stack; clinical safety approvals for patient-facing contexts.
- Fast changeover in flexible manufacturing cells
- Sector: Manufacturing (High-mix/low-volume)
- Use case: Rapid adaptation when fixtures or workpiece locations move; share continuous thoughts among similar cells to reduce retuning time.
- Tools/products/workflows: “Few-shot retargeting” workflow—record a handful of demos, fine-tune with CR, export standardized latent thoughts for new lines.
- Dependencies/assumptions: Accurate cell calibration and safety interlocks; small demonstration collection pipeline; task chunking aligned with production operations.
- Cloud/edge fleet sharing of “reasoning” for speed and consistency
- Sector: Cloud robotics, Multi-robot systems
- Use case: Robots share compressed continuous thought codes for similar tasks/contexts (e.g., during shift change) rather than full trajectories; fast bootstrapping in new zones.
- Tools/products/workflows: “Thought bus” API (e.g., gRPC) with WAE-regularized latent codex; distributed MMD-compliant training.
- Dependencies/assumptions: Network QoS and latency bounds; security and encryption for shared latents; embodiment similarity (or a mapping layer) across fleet.
- Sim-to-real with better spatial/task robustness
- Sector: Simulation, Robotics R&D
- Use case: Train with diverse simulated spatial/task perturbations; deploy with improved re-anchoring instead of scripted waypoints.
- Tools/products/workflows: CR-enabled training curriculum; horizon-aware verification; automated ablation harness for position/task shifts.
- Dependencies/assumptions: Simulator that can randomize layouts/tasks; domain randomization; dataset coverage of key perturbation families.
- Academic R&D and benchmarking
- Sector: Academia, Applied research labs
- Use case: Study of VLA “reasoning as interface” beyond CoT text; reproducible LIBERO-PRO-style robustness evaluations; analysis of latent trajectories to diagnose control phases.
- Tools/products/workflows: Open-source PyTorch modules for WAE-MMD latent structuring, EMA teacher self-verification, chunked flow-matching heads; paired-scene latent visualizations.
- Dependencies/assumptions: Multi-GPU training and proper distributed MMD; public datasets (LIBERO-PRO/CALVIN/real-robot demos).
- Developer-facing debugging and QA
- Sector: Robotics software
- Use case: Record and replay “thought latents” to reproduce failures; compare teacher vs. student action fields to catch bypasses/non-reusable reasoning.
- Tools/products/workflows: “Thought recorder” and PCA/UMAP latent dashboards; verification loss monitors during staging.
- Dependencies/assumptions: Logging infrastructure; offline analysis pipeline; minimal overhead at runtime.
- Human-in-the-loop assistance during teleoperation or semi-autonomy
- Sector: Field robotics, Remote ops
- Use case: System proposes chunk-level action segments based on current thoughts; operator accepts/adjusts; system re-anchors when operator perturbs scene.
- Tools/products/workflows: Shared latent interface between auto-pilot and teleop UI; acceptance gating at chunk boundaries.
- Dependencies/assumptions: Clear HMI; override mechanisms; latency tolerance; operator training.
- Evaluation and internal policy guidance
- Sector: Standards, Corporate governance
- Use case: Adopt self-verification as a lab/QA protocol for “reusability” of intermediate reasoning; require demonstrable teacher consumption of thought latents before green-lighting deployments.
- Tools/products/workflows: Internal checklists and CI jobs that compute verification loss on held-out perturbations.
- Dependencies/assumptions: Access to teacher checkpoints; robust held-out perturbation suites.
Long-Term Applications
- Cross-vendor “internal language for action” standard
- Sector: Robotics industry consortia, Standards bodies
- Use case: A vendor-neutral spec for continuous reasoning latents (“thought bus”), promoting skill interoperability and third-party controller plug-ins.
- Tools/products/workflows: Open schema for Gaussian latent interface; compliance tests; shared decoding benchmarks.
- Dependencies/assumptions: Industry buy-in; IP and security frameworks; mappings for different embodiments/sensors.
- Multi-robot collaborative planning via shared latent thoughts
- Sector: Warehousing, Agriculture, Construction
- Use case: Teams exchange reasoning codes for task hand-offs and dynamic retargeting (e.g., when a human moves objects mid-task).
- Tools/products/workflows: Fleet “Reasoning Memory” service; latency-aware consensus on shared thoughts; cross-robot attention over decoded interfaces.
- Dependencies/assumptions: Reliable comms; alignment layers across robot types; conflict-resolution policies.
- Continual learning in fleets using self-verification at scale
- Sector: Cloud robotics, MLOps
- Use case: Robots upload reasoning–action pairs; teacher ensembles verify reusability before merging into central model; faster adaptation without catastrophic forgetting.
- Tools/products/workflows: Federated CR training with distributed MMD; horizon-aware curriculum schedulers; roll-out safeguards.
- Dependencies/assumptions: Data governance, privacy; compute budgets; robust drift detection.
- Safety monitors and process audits based on reusable reasoning
- Sector: Healthcare, Industrial safety, Compliance
- Use case: Independent verifier consumes thought latents to predict hazards or deviation from SOPs, triggering failsafes; latent-based audit trails for incident analysis.
- Tools/products/workflows: “Verifier module” trained to detect unsafe latent regions; automated alerts tied to chunk transitions.
- Dependencies/assumptions: Curated safety datasets; regulator acceptance of latent-based evidence; explainability tooling.
- Explainability bridges from latent thoughts to human summaries
- Sector: Policy, Regulatory tech, User trust
- Use case: Translate latent thoughts into concise, phase-aware natural-language rationales; improve operator trust and debuggability.
- Tools/products/workflows: Cross-modal translators aligning latent trajectories with templated explanations; calibration with counterfactual tests for faithfulness.
- Dependencies/assumptions: New research to ensure faithful mappings; avoid post-hoc hallucination; compute overhead management.
- Embodiment transfer and morphologically diverse fleets
- Sector: OEMs, System integrators
- Use case: Map shared latent thoughts across arms and grippers of different kinematics; transfer high-level reasoning while adapting low-level control.
- Tools/products/workflows: Adapters that align latent interfaces to embodiment-specific controllers; retargeting via learned Jacobian-aware decoders.
- Dependencies/assumptions: Paired datasets across embodiments; safety validation; calibration robustness.
- High-stakes domains with dynamic retargeting (e.g., surgical robotics)
- Sector: Healthcare, Energy infrastructure maintenance
- Use case: Fine-grained manipulation under evolving constraints (tissue motion, wind turbine inspection/repair) with robust re-anchoring to new geometries.
- Tools/products/workflows: CR integrated with precise force/impedance control; supervisory safety and certification stack; simulation-based validation.
- Dependencies/assumptions: Extensive validation and regulation; tactile/force sensing; higher control frequencies; new datasets.
- Autonomous driving and aerial robotics (adapted CR)
- Sector: Transportation, Inspection
- Use case: Chunk-level continuous reasoning for route segments or maneuver primitives; dynamic retargeting under roadwork/obstacle changes.
- Tools/products/workflows: Adapt CR to motion planning stacks; teacher-verification for maneuver reusability across vehicles.
- Dependencies/assumptions: Domain adaptation for dynamics and safety; multi-sensor fusion; higher-frequency control than current examples.
- Education and skill marketplaces for robots
- Sector: EdTech, Robotics tooling
- Use case: Package and distribute reusable latent “skill thoughts” alongside demos; enable rapid onboarding in labs and classrooms.
- Tools/products/workflows: “Skill packs” with thought codes + decoders; interactive visualizers for latent phases across tasks.
- Dependencies/assumptions: Common latent standards; open datasets; lightweight decoders for low-cost hardware.
- Public benchmarks and policy frameworks for robustness
- Sector: Academia, Policy
- Use case: LIBERO-PRO-like protocols mandated in procurement or grants to measure position/task retargeting; push toward verifiable intermediate reasoning.
- Tools/products/workflows: Open-source suites, robust scoring; official guidance that includes verification metrics.
- Dependencies/assumptions: Community adoption; shared evaluation infra; funding and governance.
Notes on feasibility and assumptions common across applications:
- Training data must cover spatial/task perturbations to realize the claimed robustness benefits; otherwise, retargeting may degrade.
- Compute budgets are non-trivial: flow matching + WAE + EMA teacher require multi-GPU training; inference should fit on edge GPUs with tight latency targets.
- The shared latent interface presumes similar observation spaces; cross-platform sharing requires alignment layers.
- Safety, privacy, and IP constraints govern sharing of latent thoughts across vendors or fleets.
- Real-world success depends on reliable state estimation (multi-camera setups, calibration) and robust low-level control to execute chunked plans.
Glossary
- Abstraction alignment: Matching the level of the reasoning representation to the temporal granularity of control so it can effectively guide actions. "Third, it should be abstraction-aligned: the representation should match the temporal granularity at which actions are organized, above low-level motor fluctuations but below free-form semantic language, so that it remains close enough to chunked action generation to guide control rather than merely describe it."
- Action chunk: A temporally extended unit of control used to structure action prediction over horizons. "a single reasoning step can therefore span many action chunks while remaining only weakly coupled to the action needed now."
- Autoregressive decoding: A generation process that produces outputs sequentially, each conditioned on previous outputs. "This decoder sits between fully bidirectional flow-matching action prediction and step-wise autoregressive decoding."
- Behavior tokenization: Discretizing or symbolizing behaviors to enable structured action generation or planning. "including chunked action prediction, behavior tokenization, diffusion-based control, language-guided decomposition, and latent subgoal structure"
- Bimanual platform: A robot with two manipulators (arms) for coordinated tasks. "TX-G2 is a bimanual platform with three cameras, and we query the deployed policy at 10\,Hz."
- Block-causal attention mask: An attention scheme where later chunks can attend to earlier ones but not vice versa, enforcing temporal causality at the chunk level. "Across chunks, we use a block-causal attention mask: action tokens in the same chunk share one attention block, while later chunks can attend to earlier chunks."
- CALVIN ABC→D: A long-horizon robotic manipulation benchmark evaluating sequential skill composition. "We report CALVIN ABCD in Appendix~\ref{sec:appendix-calvin} as a complementary long-horizon benchmark"
- Chain-of-thought traces: Explicit intermediate reasoning sequences (often textual) that articulate step-by-step reasoning. "including textual or multimodal chain-of-thought traces~\citep{cotVla,halo,dualCotVla,dVla,deepThinkVla}"
- Chunk-causal mask: A training variant controlling temporal dependencies across action chunks by enforcing causality at the chunk level. "w/o chunk-causal mask keeps continuous thoughts, latent structuring, and self-verification, but removes the block-causal dependency across action chunks."
- Chunk-structured action generation: Producing actions in temporally extended segments rather than individual low-level steps. "then reuses those thoughts as a shared reasoning context for chunk-structured action generation."
- Chunked decomposition: Splitting an action horizon into a fixed number of temporally extended chunks. "We divide the action horizon into temporally extended chunks, so that for chunk size . This chunked decomposition is important in our formulation"
- Chunked generative action policies: Action models that generate temporally extended action segments in structured blocks. "following the broader line of chunked generative action policies~\citep{act,diffusionPolicy,pi0,openvlaOft}"
- Continuous thoughts: Non-textual continuous vectors representing intermediate reasoning states used to guide action generation. "We represent continuous reasoning with raw thought vectors $\tau = [\tau_1, \ldots, \tau_{N_{\tau}]$, ... We refer to as the raw continuous thoughts."
- Diffusion-based control: Using diffusion generative models to synthesize control trajectories or actions. "including chunked action prediction, behavior tokenization, diffusion-based control, language-guided decomposition, and latent subgoal structure"
- EMA teacher (Exponential-moving-average teacher): A teacher model whose parameters are the exponential moving average of a student’s parameters, used to stabilize training and verify reusability. "we introduce a self-verification objective in which an exponential-moving-average teacher must successfully consume the student's thoughts in order to predict target actions."
- Flow-matching backbone: An action-generation model based on flow matching, serving as the main architecture for predicting action trajectories. "We consider language-conditioned action prediction ... using a chunked flow-matching backbone."
- Flow-matching objective: A training loss that fits a model’s vector field to transform noisy samples into data samples over time. "Action prediction is trained with a flow-matching objective over noisy trajectories"
- Flow-matching policy: An action policy that decodes actions by learning a flow to map noise to trajectories. "and then decodes them into a reasoning interface that is reused for chunk-structured action generation under a flow-matching policy."
- Gaussian bottleneck: A latent constraint forcing representations through a Gaussian prior to encourage structure and shareability. "w/o Gaussian latent space removes the WAE objective and the Gaussian bottleneck."
- Gaussian latent space: A shared latent space with a Gaussian prior that facilitates transfer and reuse of reasoning codes. "We instantiate continuous reasoning as a shared Gaussian latent interface"
- Horizon-aware verification: A training strategy that verifies reasoning effectiveness across the full temporal horizon of action generation. "We further align reasoning with high-level control structure through chunked generation, horizon-aware verification, and training choices..."
- IMQ-kernel MMD: Maximum Mean Discrepancy computed with the Inverse Multiquadric kernel to match latent distributions. "and then compute a single IMQ-kernel MMD loss on that global batch."
- KV cache: The key–value memory used by attention mechanisms to store and reuse intermediate states across steps. "that decoded state is committed to the KV cache so that later slots can attend to earlier ones."
- Latent codes: Encoded representations in a lower-dimensional latent space used for decoding reasoning interfaces and actions. "An encoder maps the thoughts to shared latent codes via "
- Latent planning: Planning using internal continuous latent representations rather than explicit symbolic or textual plans. "latent planning and compact reasoning states~\citep{thinkact,fastThinkAct,latentReasoningVla,last0,molmoact}"
- LIBERO-PRO: A robustness-oriented benchmark for evaluating VLA policies under controlled distribution shifts. "We begin with LIBERO-PRO~\citep{liberoPro}, a robustness-oriented benchmark that is substantially more challenging than standard LIBERO evaluation"
- Maximum Mean Discrepancy (MMD): A statistical distance between distributions used to enforce latent prior matching. "$\lambda_{\mathrm{mmd}\mathrm{MMD}(z, \mathcal{N}(0,I)).$"
- Prior matching: Regularizing latent codes to follow a chosen prior distribution (e.g., Gaussian). "The WAE objective combines reconstruction and prior matching,"
- Self-verification objective: A loss that requires a separate model instance (the EMA teacher) to successfully use the student’s reasoning interface to predict actions. "we introduce a self-verification objective in which an exponential-moving-average (EMA) teacher must successfully consume the student's thoughts in order to predict target actions."
- Shared latent geometry: A structured latent space that is common across model instances to enable reusability of reasoning. "we regularize the thoughts with a Wasserstein autoencoder (WAE) into a shared latent geometry"
- Teacher-student learning: A training paradigm where a teacher model guides or evaluates a student model, often via consistency objectives. "Our training design is also related to teacher-student learning and structured latent modeling."
- TX-G2: A real-robot platform used for evaluation, compatible with AgiBot G2. "TX-G2 (an AgiBot G2-compatible variant)"
- Vector field: The function defining the instantaneous velocity for transforming noisy actions toward the target actions in flow matching. "and target vector field ."
- Vision-language-action (VLA): Models that integrate vision and language inputs to generate actions for embodied control. "Vision-language-action (VLA) models have rapidly expanded the scope of robot policy learning"
- Wasserstein autoencoder (WAE): A generative model that enforces a structured latent space via Wasserstein distance or MMD-based regularization. "we regularize the thoughts with a Wasserstein autoencoder (WAE) into a shared latent geometry"
Collections
Sign up for free to add this paper to one or more collections.