Recurrent-Depth VLA: Implicit Test-Time Compute Scaling of Vision-Language-Action Models via Latent Iterative Reasoning
Abstract: Current Vision-Language-Action (VLA) models rely on fixed computational depth, expending the same amount of compute on simple adjustments and complex multi-step manipulation. While Chain-of-Thought (CoT) prompting enables variable computation, it scales memory linearly and is ill-suited for continuous action spaces. We introduce Recurrent-Depth VLA (RD-VLA), an architecture that achieves computational adaptivity via latent iterative refinement rather than explicit token generation. RD-VLA employs a recurrent, weight-tied action head that supports arbitrary inference depth with a constant memory footprint. The model is trained using truncated backpropagation through time (TBPTT) to efficiently supervise the refinement process. At inference, RD-VLA dynamically allocates compute using an adaptive stopping criterion based on latent convergence. Experiments on challenging manipulation tasks show that recurrent depth is critical: tasks that fail entirely (0 percent success) with single-iteration inference exceed 90 percent success with four iterations, while simpler tasks saturate rapidly. RD-VLA provides a scalable path to test-time compute in robotics, replacing token-based reasoning with latent reasoning to achieve constant memory usage and up to 80x inference speedup over prior reasoning-based VLA models. Project page: https://rd-vla.github.io/




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way for robots to “think” while they act. The idea is called Recurrent-Depth VLA (RD‑VLA). It helps a robot spend more brainpower on hard tasks and less on easy ones, without slowing down or using a lot of extra memory. Instead of making the robot explain its thoughts in words (which is slow and bulky), RD‑VLA lets the robot quietly refine its internal “thoughts” in loops until it’s confident, then act.
What is the paper trying to find out?
The authors wanted to solve three simple questions:
- Can robots use more thinking on harder tasks and less on easier ones, automatically?
- Can we avoid making robots “talk to themselves” with long text-like steps (which wastes time and memory)?
- Can we keep robot control fast and reliable while still allowing multi-step reasoning?
How did they do it? (Methods explained simply)
Think of a robot’s brain as a notebook where it writes down ideas before moving. RD‑VLA teaches the robot to:
- Start with a rough plan,
- Refine that plan in small steps (loops),
- Stop refining when the plan stops changing much,
- Then turn the refined plan into actions (like moving the arm).
Here are the main parts, using everyday analogies:
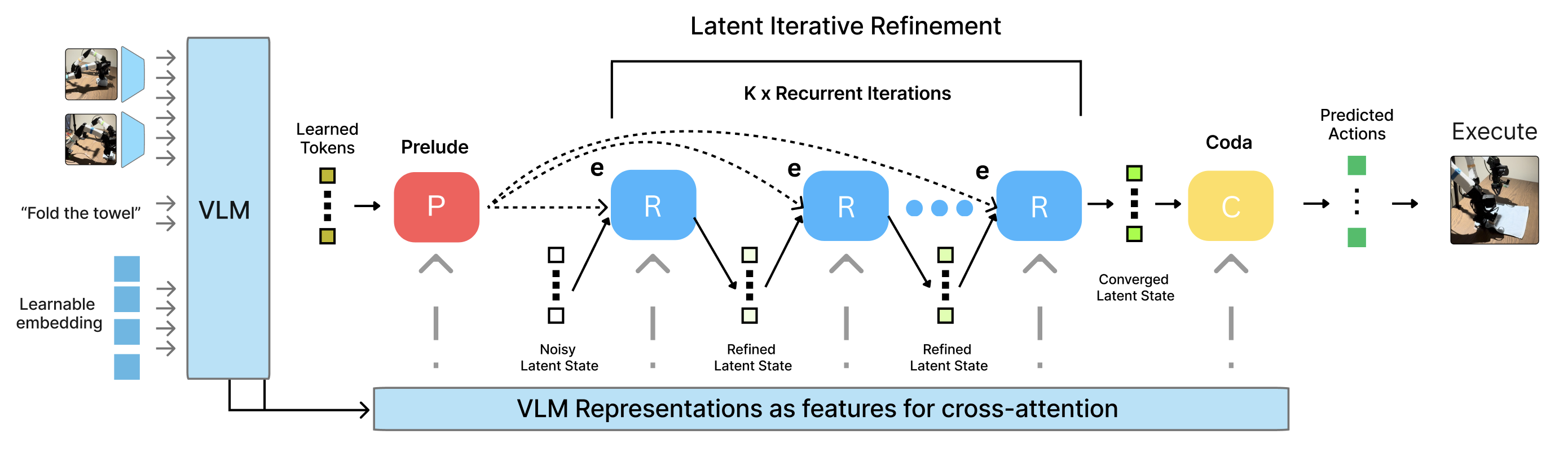
- Prelude (Start): The robot gathers useful clues from its cameras and instructions, like setting up a “starter kit” of notes.
- Recurrent Core (Loop): Instead of writing out its thoughts as sentences (tokens), the robot quietly improves its internal notes again and again, like sharpening a blurry photo until it’s clear. The same “thinking block” is reused each time, so memory stays constant.
- Coda (Finish): When the notes look good and stable, the robot turns them into actual movements.
Key ideas in simple terms:
- Latent reasoning: “Latent” means hidden internal thoughts. RD‑VLA keeps reasoning inside the robot’s internal representation instead of writing it out as text. This avoids slow, memory-heavy steps.
- Recurrent depth: The robot can think in as many loops as needed. Hard tasks get more loops; easy tasks get fewer.
- Adaptive stopping: The robot stops looping when its plan doesn’t change much anymore—like stopping when your answer stays the same after rechecking.
- Efficient training: The model is trained by practicing several refine steps but only learning strongly from the latest few (a method called TBPTT). This teaches it to improve progressively without wasting training effort.
Why not make the robot “talk” to itself?
- Token-based Chain-of-Thought (CoT) is like making the robot write a paragraph before each move. That takes time, uses lots of memory, and doesn’t fit well with smooth, continuous motions. RD‑VLA keeps all the thinking internal and continuous, which is better for real robot control.
What did they find?
The results show clear benefits:
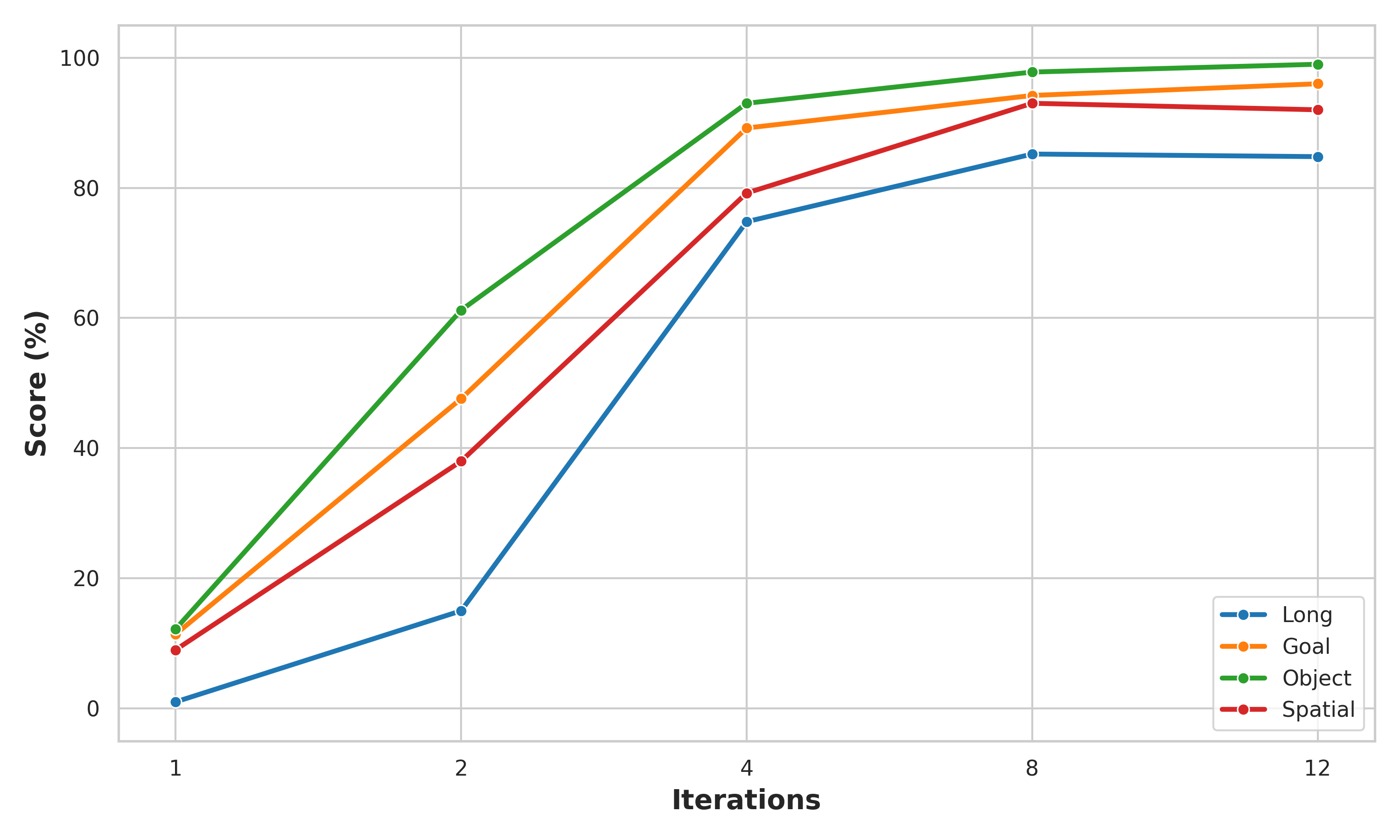
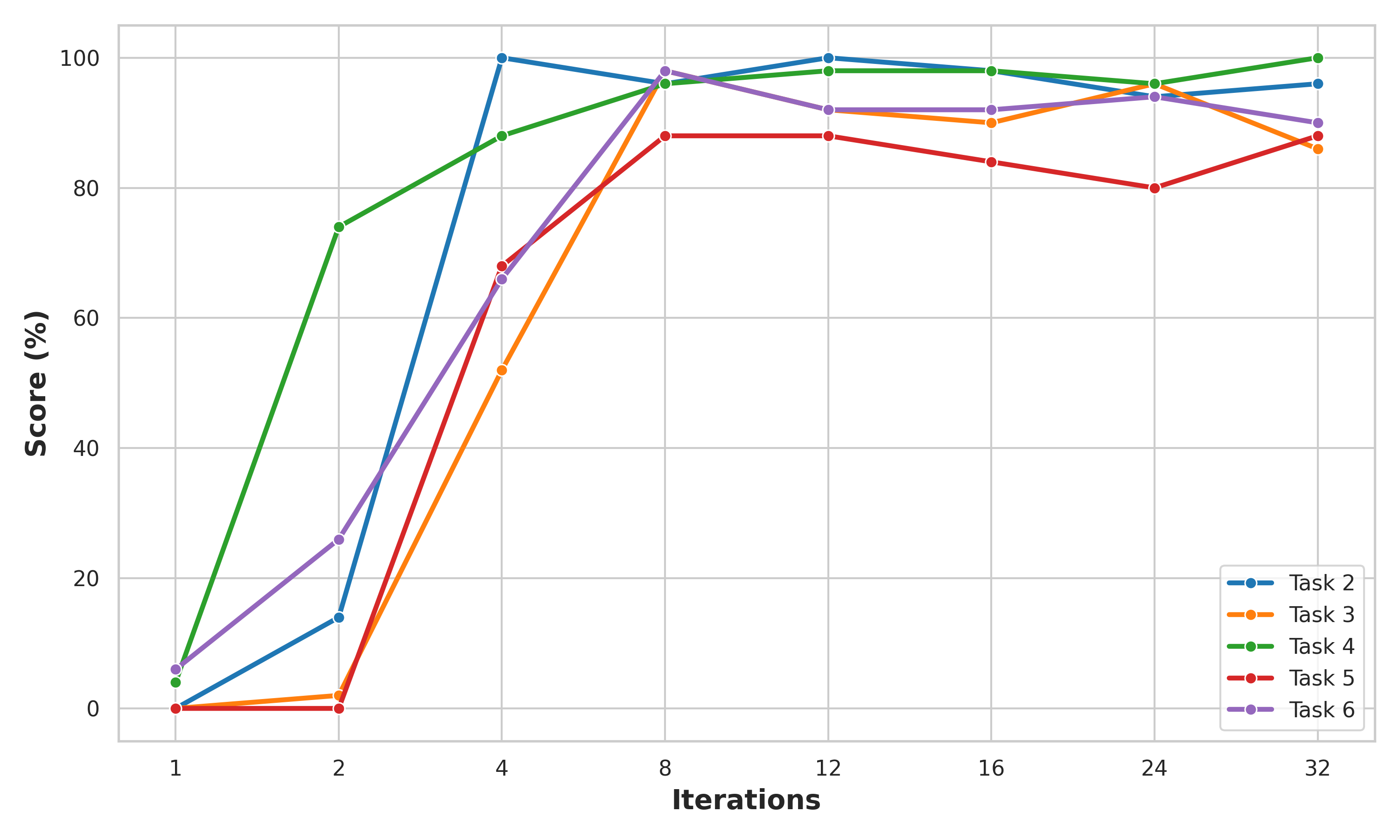
- More loops help a lot: Some tasks that completely failed with just one thinking step (0% success) jumped to over 90% success after four loops.
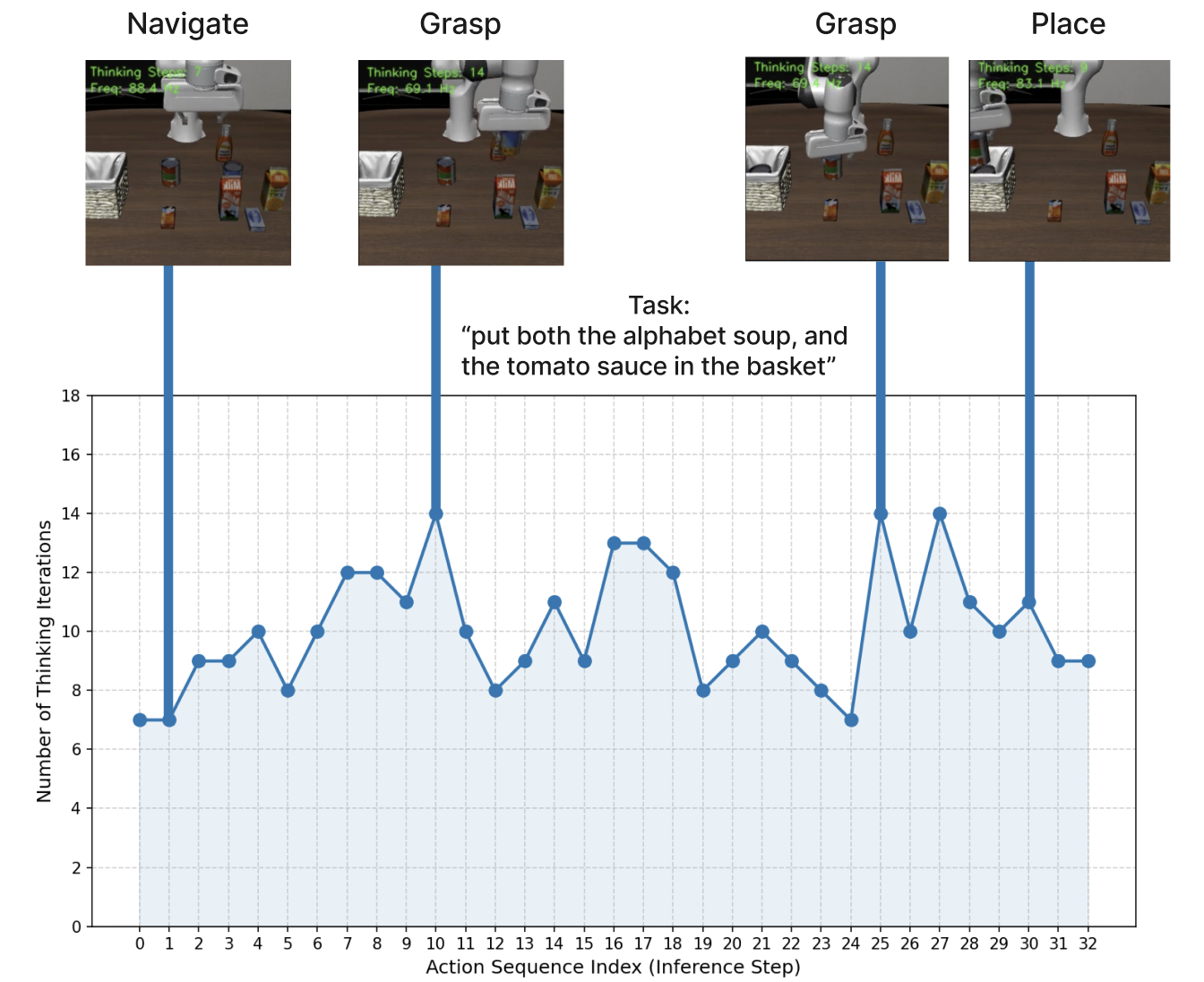
- Adaptive thinking works: The robot learns to think longer on hard steps (like grasping) and shorter on easy steps (like simple placing).
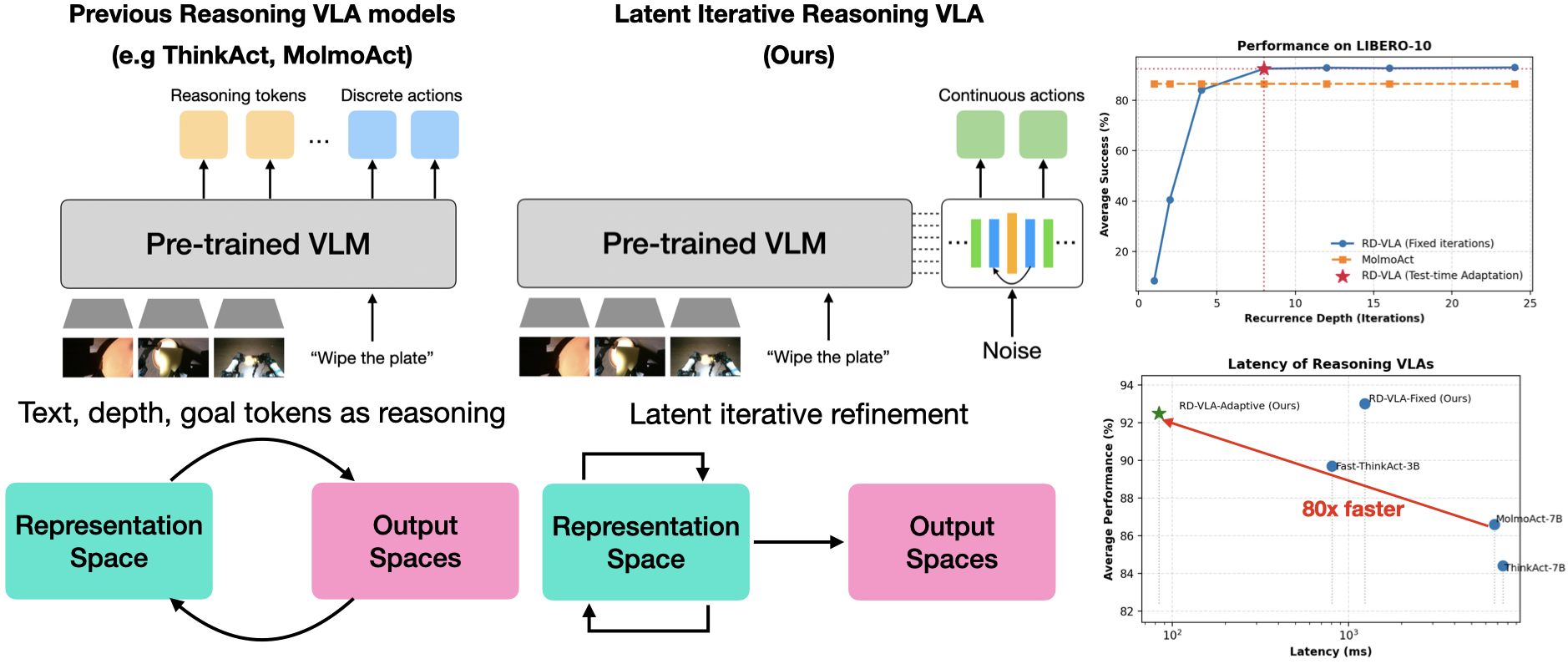
- Faster and lighter: RD‑VLA reached up to 80× faster inference (decision-making) than prior reasoning-based models, while keeping memory usage constant.
- Strong performance: On the LIBERO benchmark, it achieved about 93% success with a fixed number of loops and about 92.5% using adaptive stopping. On the CALVIN benchmark, it completed longer chains of tasks than other models (average chain length 3.39).
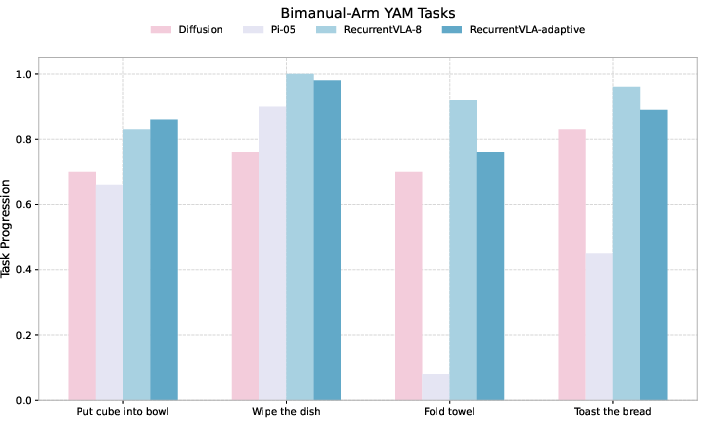
- Real-world success: The method worked on real tasks like folding a towel and toasting bread, often beating strong baselines.
Why is this important?
This approach shows that robots can be both smart and efficient:
- It gives robots a way to “think more” only when needed, making them faster and more reliable.
- It avoids bulky, text-based reasoning, which isn’t ideal for continuous movement.
- It keeps memory usage steady, which is helpful for running on small or power-limited systems.
- It opens the door to safer behavior: if the robot needs lots of thinking loops, that can signal uncertainty, and the robot can act more cautiously.
What’s the big picture and what’s next?
RD‑VLA is a step toward robots that adapt their effort like humans do—quick reflexes for simple moves, careful planning for tricky ones. In the future:
- Scaling to bigger models and more data could make this even stronger.
- Better ways to decide when to stop thinking and how often to replan could improve safety and speed.
- Hybrid systems might mix internal looping with occasional structured steps when useful.
In short, RD‑VLA helps robots “think in loops” inside their heads, making them faster, safer, and better at complex tasks without wasting time or memory.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, written to guide concrete future research.
- Backbone-agnostic claims are unvalidated: the approach is only instantiated with a Qwen2.5-0.5B-based MiniVLA; evaluate RD-VLA across diverse VLM/LLM backbones, larger model scales, and different vision encoders to quantify portability and scaling laws.
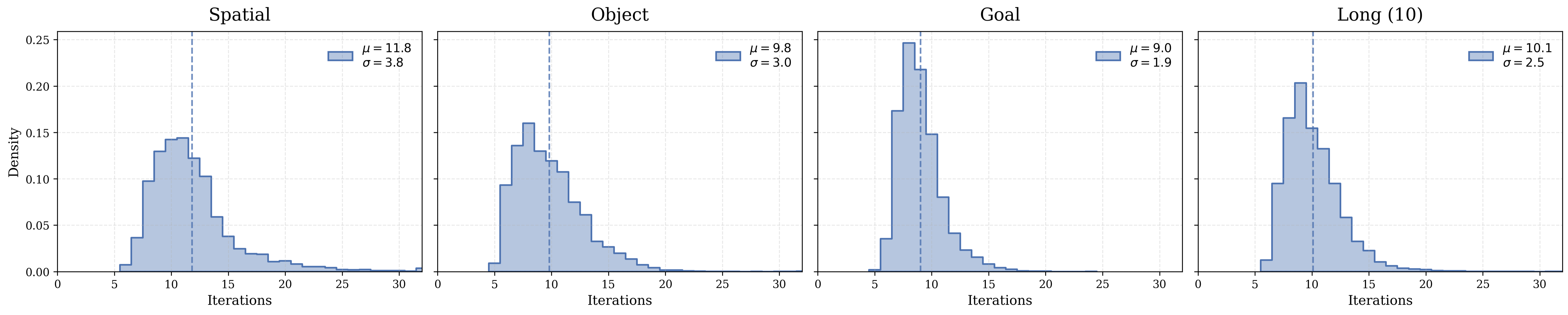
- Depth generalization and saturation: performance plateaus or degrades beyond ~12 iterations; investigate training protocols (e.g., contractive/fixed-point objectives, spectral constraints, recurrent regularizers) that guarantee stable refinement and prevent state saturation at larger unroll depths.
- Stopping criterion justification: the use of action-space MSE as a KL proxy lacks theoretical grounding; compare and calibrate convergence metrics in latent space (cosine distance, true KL on policy distributions, representation KL) and study sensitivity to action scaling and units.
- Adaptive execution coupling is heuristic: binary and linear-decay schedules lack safety guarantees; develop principled couplings (e.g., MPC with uncertainty, chance-constrained planners) and evaluate on safety-critical tasks with formal analyses of compounding error.
- TBPTT window effects: training gradients are propagated only through the last d=8 iterations; ablate d and recurrence sampling distributions to understand learning for deeper unrolls and the risk of mismatch between trained and deployed iteration counts.
- Scratchpad initialization and dynamics: the latent scratchpad is reinitialized with noise at each control step; evaluate carrying the scratchpad across timesteps to exploit temporal continuity, and compare to learned initial states or stateful memory mechanisms.
- Real-time control constraints: variable iteration counts can violate fixed control-cycle deadlines; design and test scheduling with worst-case latency bounds, iteration budgets, and fallback policies when convergence is not reached in time.
- Profiling of speed and memory claims: “constant memory” and “up to 80× speedup” are not rigorously benchmarked; provide detailed, reproducible profiling (GPU/CPU, batch sizes, sequence lengths) and breakdowns of latency and memory across unroll depth and baselines.
- Fairness of baseline comparisons: baselines differ substantially in parameter counts, training data, and recipes; conduct controlled comparisons with matched backbone sizes, identical datasets, training budgets, and seeds to isolate the effect of latent recurrence.
- Breadth of evaluation: real-world tests are limited in diversity (few tasks, static scenes, limited objects); expand to dynamic environments, occlusions, viewpoint changes, deformables, and cluttered, multi-contact manipulation to assess robustness.
- Out-of-distribution robustness: systematically test RD-VLA under OOD scenes, sensor noise/failures, adversarial perturbations, and domain shifts (cameras, lighting, embodiment) and develop detection/recovery strategies.
- Action parameterization details: the paper references “action chunks” and execution horizons without formal specification; define the action space, chunking/horizon choices, and analyze how these interact with convergence, stability, and task success.
- Proprioception and multimodal sensing: only basic proprioception is used; evaluate integration of force/tactile, depth/point clouds, audio, and richer robot state to determine their impact on latent reasoning and convergence behavior.
- Uncertainty calibration: iteration count and convergence metrics are used as proxies for epistemic uncertainty without calibration; assess calibration (e.g., ECE), reliability diagrams, and use calibrated uncertainty for risk-aware control.
- Alternative latent-reasoning baselines: comparisons focus on token reasoning; include strong latent iterative baselines (latent diffusion, energy-based refinement, flow policies with iterative sampling) to isolate the value of RD-VLA’s recurrent core.
- Theoretical analysis of refinement: provide conditions under which S_{k+1} is a “strictly better” refinement of S_k; study fixed-point existence, contraction properties, oscillations, and monotonicity, and relate these to empirical convergence.
- Representational collapse mitigation: Input Injection is proposed but not compared to alternatives (e.g., gated conditioner re-entry, residual/skip across iterations, spectral normalization, recurrent dropout); systematically evaluate collapse prevention strategies.
- Hyperparameter sensitivity: key choices (number of queries K, scratchpad dimension D, γ_init/σ_init, τ thresholds, adapter gating) lack sensitivity analyses; quantify robustness and provide default regimes with empirical guidance.
- Long-horizon memory across steps: the model recurs within a control step but lacks explicit memory across steps; study architectures that maintain and update a persistent latent plan/state trajectory over episodes.
- Safety analyses and guarantees: adaptive compute and execution are attractive but need formal safety assessments (e.g., bounded-risk guarantees, watchdogs leveraging recurrent variance) and evaluations in failure-inducing scenarios.
- Dataset scale and diversity: training data provenance and size are not detailed; assess data requirements, sample efficiency, and the effect of pretraining on large robot corpora (e.g., Open-X, DROID) versus task-specific fine-tuning.
- Interpretability of latent reasoning: S_k is opaque; develop tools to visualize latent trajectories, align them with task phases, and use interpretability for debugging and intervention.
- Hybrid token–latent reasoning: the paper proposes exploring per-token recurrent depth but does not evaluate it; study hybrid designs that selectively combine latent refinement with explicit CoT for tasks requiring symbolic planning.
- Deployment on resource-constrained hardware: examine RD-VLA’s performance on edge devices (embedded GPUs/CPUs), quantization/pruning strategies for the recurrent head, and end-to-end throughput under real-time constraints.
- Generalization across embodiments: evaluate transfer to varied robots (kinematics, actuation, grippers), action-space remappings, and embodiment-specific adapters to validate the “backbone-agnostic” claim in practice.
Glossary
- Action head: The output module that maps internal representations to robot actions; here it is recurrent and parameter-shared across iterations. "RD-VLA employs a recurrent, weight-tied action head that supports arbitrary inference depth with a constant memory footprint."
- Adaptive computation: A mechanism that adjusts the number of inference iterations based on model convergence or uncertainty. "We implement an adaptive computation mechanism at inference."
- Adaptive execution: A strategy that modulates how many actions to execute based on the depth of reasoning or uncertainty. "Adaptive computation determines how long to recur. At the same time adaptive execution determines how many actions to execute."
- Autoregressive decoding: Token-by-token generation used by many LLMs; costly when used for explicit reasoning tokens. "(Left) Previous reasoning VLAs (e.g., ThinkAct, MolmoAct) generate explicit reasoning tokens in output space, requiring expensive autoregressive decoding."
- Backpropagation through time (TBPTT): A training technique that backpropagates gradients through a limited number of recurrent steps. "The model is trained using truncated backpropagation through time (TBPTT) to efficiently supervise the refinement process."
- Chain-of-Thought (CoT): A prompting or supervision method that elicits explicit intermediate reasoning steps (tokens) before producing outputs. "While Chain-of-Thought (CoT) prompting enables variable computation, it scales memory linearly and is ill-suited for continuous action spaces."
- Coda: The non-recurrent decoding block that converts the refined latent state into actions. "The Coda performs the final decoding pass by moving the representation out of the latent manifold, attending to the self, and high-level VLM features ()."
- Cross-attention: An attention mechanism where queries attend to keys/values from another source to fuse information. "The Prelude (P) grounds learned queries via cross-attention to mid-layer VLM features."
- Diffusion Policies: Control policies that generate actions by iteratively denoising trajectories in the output space. "Diffusion Policies operate by iteratively denoising an action trajectory in the output space."
- Epistemic uncertainty: Uncertainty arising from limited knowledge or model parameters; used to modulate execution risk. "We hypothesize that high iteration counts imply higher epistemic uncertainty."
- Flow matching: A modeling technique that learns transport/flow fields to match distributions; applied here for action generation. "Building on these, introduced a generalist policy using flow-matching for multi-modal actions, with providing a more efficient, high-performance iteration for real-time deployment."
- Heavy-tailed log-normal Poisson distribution: A sampling scheme combining log-normal and Poisson properties to produce heavy-tailed counts. "we sample the number of iterations during training from a heavy-tailed log-normal Poisson distribution:"
- Kullback–Leibler (KL) divergence: A measure of discrepancy between probability distributions; used as a stopping signal. "We define a stopping criterion based on the Kullback-Leibler (KL) divergence between the action distributions of consecutive iterations."
- Latent iterative refinement: Repeatedly improving internal (latent) representations instead of emitting intermediate tokens. "achieves computational adaptivity via latent iterative refinement rather than explicit token generation."
- Latent manifold: The continuous vector space in which internal representations reside and are refined. "operating within a continuous latent manifold."
- Latent scratchpad: A set of latent variables serving as an internal workspace updated across recurrent steps. "Parallel to this, we initialize a latent scratchpad from a high-entropy truncated normal distribution to serve as the evolving state for the reasoning process:"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that inserts low-rank adapters into a pretrained model. "The frozen vision encoder ... [is] projected into a Qwen2-0.5B (24-layer) LLM backbone fine-tuned via LoRA."
- Multimodal LLMs (MLLMs): LLMs that process multiple modalities (e.g., vision and text). "While generalist VLAs built upon Multimodal LLMs (MLLMs) exhibit impressive visual understanding, they often remain brittle"
- Prelude: The non-recurrent interface block that initializes grounded latent queries for iterative refinement. "The process begins with the Prelude (), a non-recurrent interface that consumes learned queries."
- Proprioception: The robot’s internal state measurements (e.g., joint angles), used as additional conditioning signals. "This manifold consists of the 64 task-aligned latent tokens and 512 vision tokens from the VLM's final layer and the robot's current proprioception ."
- Recurrent transformers: Transformer architectures where layers or blocks are reused across iterations to scale compute at inference. "Recurrent Transformers is an architecture where all or some portion of layers in transformers are recurred, which means that representation of the later layer gets reinjected back into the earlier layers."
- Representational collapse: Degradation of internal representations during long unrolls, leading to loss of useful information. "To maintain representational stability and prevent the model from losing its grasp on the physical observations over long unrolls (representational collapse), we utilize a persistent Input Injection strategy."
- RMSNorm: A normalization technique based on root-mean-square statistics, used instead of standard LayerNorm. ""
- Test-time compute: The amount of computation performed during inference, which can be adaptively scaled per input. "RD-VLA provides a scalable path to test-time compute in robotics, replacing token-based reasoning with latent reasoning to achieve constant memory usage and up to 80Ã inference speedup over prior reasoning-based VLA models."
- Vision–Language–Action (VLA): Models that integrate visual perception, language understanding, and action generation for robotic control. "Current VisionâLanguageâAction (VLA) models rely on fixed computational depth, expending the same amount of compute on simple adjustments and complex multi-step manipulation."
- Weight tying: Sharing the same parameters across repeated iterations of a module to enable deep unrolling with constant memory. "RD-VLA shifts the computational burden to a weight-tied recurrent transformer core operating entirely within a continuous latent manifold."
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can leverage RD-VLA’s latent iterative reasoning, adaptive compute, and constant-memory recurrent action head today.
- High-throughput bin picking, kitting, and packing (Robotics, Manufacturing, E‑commerce)
- Tools/products/workflows: Drop-in RD-VLA action head for existing VLA policies (e.g., OpenVLA/MiniVLA), ROS2 node with adaptive stopping (MSE/“KL” threshold) and adaptive execution horizon, cycle-time optimizer that tunes per-station thresholds (τ, Hmin/Hmax).
- Why RD-VLA: Up to 80× faster than token-reasoning VLAs with constant memory; compute scales with task difficulty, reducing latency on easy picks and allocating more steps for difficult grasps.
- Assumptions/dependencies: Calibrated cameras, reliable proprioception, moderate task/domain adaptation with available robotic datasets; GPU or strong edge inference; safety interlocks.
- Mobile manipulation in warehouses and retail restocking (Robotics, Logistics)
- Tools/products/workflows: “Uncertainty-aware execution manager” that shortens action horizons when convergence is slow; fleet management plugin to cap per-robot test-time compute during peak loads.
- Why RD-VLA: Adaptive execution reduces misplacements and collision risk at uncertain states while keeping fast reactions in simple navigation/placement.
- Assumptions/dependencies: Robust navigation stack integration, shelf/slot perception, good lighting, calibration.
- Household service tasks (Robotics, Consumer)
- Examples: Towel folding, wiping dishes, sorting items, simple kitchen prep—mirrors the paper’s real tasks (towel folding, toasting bread, cube-in-bowl).
- Tools/products/workflows: Consumer robot skill library with RD-VLA runtime; “auto-threshold calibration” wizard that tunes τ per skill and home layout.
- Assumptions/dependencies: Variability in home environments; robust perception for occlusions/clutter; safety gating for human proximity.
- Assistive fetching and light caregiving (Healthcare, Elder care)
- Tasks: Fetch-and-carry, tidying, meal-delivery, opening drawers/doors.
- Tools/products/workflows: “Confidence-triggered handoff” (robot requests human assistance when iteration depth exceeds τ), real-time monitoring dashboard exposing iteration counts and action-change metrics to caregivers.
- Assumptions/dependencies: Regulatory compliance for assistive use; strict safety checks; curated skill sets tuned to the facility; human-in-the-loop escalation.
- Edge robotics under tight memory/power budgets (Energy-conscious embedded deployments)
- Tools/products/workflows: RD-VLA Tiny with weight-tying, INT8/FP8 quantization, and adaptive compute caps; budget-aware scheduler that prioritizes urgent control loops with small K.
- Why RD-VLA: Weight-tied recurrence supports constant memory while allowing deeper compute only when needed.
- Assumptions/dependencies: Efficient kernels (FlashAttention-like), hardware accelerators (Jetson/Edge TPU-class), task-specific fine-tuning.
- Agricultural robotic manipulation (Agritech)
- Tasks: Selective harvesting, sorting, gentle placement.
- Tools/products/workflows: Field-deployable RD-VLA policy with adaptive horizon to replan frequently in complex foliage; “weather-aware compute” that increases recurrence during adverse lighting/wind.
- Assumptions/dependencies: Robust grippers, variable lighting robustness, dataset adaptation to crops/terrain.
- Safety overlays and intervention policies (Operations, Safety/Compliance)
- Tools/products/workflows: Policy that pauses execution or reduces Hexec when latent convergence is slow; threshold-based uncertainty alarms integrated into safety PLCs; audit logs of per-step iteration counts.
- Assumptions/dependencies: Calibrated thresholds; operator training; validated mapping between iteration depth and risk for the task domain.
- Energy- and cost-aware robot ops (Finance/Operations)
- Tools/products/workflows: “Compute budgeter” that reports and caps test-time compute per shift; dashboards linking iteration distributions to energy and cycle time; A/B testing of τ for ROI.
- Assumptions/dependencies: Telemetry pipeline; cost and throughput baselines; willingness to trade tiny performance deltas for energy/cost gains.
- Research tooling for adaptive compute in manipulation (Academia)
- Tools/products/workflows: Open-source RD-VLA head with TBPTT training script, randomized recurrence schedule, and adaptive stopping baselines; benchmark suites for LIBERO/CALVIN with compute–performance curves; latent convergence metrics.
- Assumptions/dependencies: Access to benchmarks; multi-seed evaluation; reproducible training recipes.
- Software integration patterns (Software/Robotics)
- Tools/products/workflows: RD-VLA “Runtime SDK” with APIs for: (1) recurrent unroll control, (2) τ/Hexec auto-tuning, (3) safety callbacks; plug-ins for common stacks (ROS2, Isaac, MoveIt).
- Assumptions/dependencies: Modern CUDA/accelerator stack; observability hooks for per-iteration statistics.
Long-Term Applications
These opportunities require additional research, validation, scaling, or regulatory clearance before broad deployment.
- Surgical and high-precision medical manipulation (Healthcare)
- Vision: Latent uncertainty gating for ultra-fine tasks (suturing, tool handoffs), with automatic replan when convergence is slow.
- Tools/products/workflows: FDA-grade safety wrappers, simulation-to-real pipelines with rigorous validation of convergence–risk correlations.
- Assumptions/dependencies: Clinical trials, fail-safe actuation, redundant sensors, strong formal safety guarantees.
- Autonomous generalist home assistants (Robotics, Consumer)
- Vision: Long-horizon domestic tasks (multi-step meal prep, laundry routines) using hybrid reasoning (language-level planning + latent refinement).
- Tools/products/workflows: Planner–RD-VLA hybrid stack, skill-graph editors, continual learning with uncertainty-aware rehearsal.
- Assumptions/dependencies: Rich household datasets, robust grounding, privacy/security, reliable long-term autonomy.
- Multi-robot, compute-aware fleet orchestration (Logistics, Manufacturing)
- Vision: Scheduler that allocates per-robot test-time compute based on task urgency/difficulty, power caps, and SLAs.
- Tools/products/workflows: “Compute marketplace” that trades iteration budgets; fleet-level uncertainty dashboards influencing task assignment.
- Assumptions/dependencies: Standardized uncertainty metrics; cross-robot comparability; real-time orchestration infrastructure.
- Standardization and regulation of adaptive-compute safety (Policy)
- Vision: Norms for latent convergence thresholds, uncertainty reporting, and stop conditions; green-robotics standards linking adaptive compute to energy/carbons.
- Tools/products/workflows: Compliance test suites, certification protocols, reporting templates for per-task compute budgets.
- Assumptions/dependencies: Industry consensus, regulator engagement, evidence that iteration metrics correlate with risk.
- Hardware–algorithm co-design for recurrent depth (Semiconductors, Edge AI)
- Vision: Accelerators optimized for weight-tied recurrence, efficient input injection, and low-latency cross-attention; memory-constant inference chips.
- Tools/products/workflows: Compiler passes that reuse activations across unrolls; dynamic-kernel scheduling for variable depth.
- Assumptions/dependencies: Vendor buy-in, volume use cases, standardized model interfaces.
- Sim2real at scale with latent refinement (Robotics R&D)
- Vision: Training curricula that leverage randomized recurrence and noise-initialized scratchpads to improve transfer and robustness.
- Tools/products/workflows: Domain-randomized sims that explicitly train stop criteria and execution-horizon coupling; automated threshold search.
- Assumptions/dependencies: High-fidelity simulators, large-scale datasets, robust transfer evaluation.
- Interpretable, health‑monitoring robot controllers (Safety/Diagnostics)
- Vision: Use latent trajectories and convergence rates for anomaly detection, root-cause analysis, and predictive maintenance.
- Tools/products/workflows: “Latent health” dashboards; alerts when convergence patterns drift; explainability overlays tied to sensory contexts.
- Assumptions/dependencies: Long-term logs, validated links between latent signals and failure modes.
- Hazardous environment manipulation (Energy, Utilities, Disaster response)
- Vision: Refinery/plant inspections, valve operations, debris clearing, where adaptive compute balances speed and caution in variable conditions.
- Tools/products/workflows: RD-VLA with ruggedized perception; remote supervision that escalates when iteration counts spike.
- Assumptions/dependencies: Extreme lighting/temperature robustness, communication constraints, specialized end-effectors.
- Risk pricing and insurance products for robotics (Finance/Insurance)
- Vision: Premiums and SLAs based on uncertainty profiles (iteration distributions, action-change drift), enabling data-driven underwriting.
- Tools/products/workflows: Standard telemetry feeds; actuarial models linking convergence metrics to incident probabilities.
- Assumptions/dependencies: Data-sharing agreements; proven predictive power of latent metrics; legal frameworks.
- Education and workforce development for adaptive-compute robotics (Education/Training)
- Vision: Curricula and certifications focused on compute-aware policy tuning, safety calibration, and operational analytics.
- Tools/products/workflows: Academic kits with RD-VLA labs; “threshold tuning” practicums; capstone projects on hybrid latent–token reasoning.
- Assumptions/dependencies: Accessible hardware, open-source stacks, institutional adoption.
Notes on feasibility across applications
- Dependencies on foundation models and data: RD-VLA inherits perception from VLM backbones; performance depends on domain-specific fine-tuning and dataset coverage (e.g., LIBERO/CALVIN or task-specific logs).
- Threshold calibration: Safe and efficient operation relies on selecting appropriate stopping thresholds (τ) and execution horizons (Hmin/Hmax); auto-calibration and monitoring are recommended.
- Hardware and optimization: Real-time performance benefits from efficient attention kernels, quantization, and hardware accelerators; edge deployments may require model compression.
- Safety and compliance: For human-adjacent settings (healthcare, home, retail), integrate uncertainty-aware execution with conservative fail-safes and human-in-the-loop escalation; regulatory approval may be required.
- Scaling limits: Very deep recurrence may saturate or degrade; continuous validation and compute caps are necessary to avoid diminishing returns.
Collections
Sign up for free to add this paper to one or more collections.

