LaST-R1: Reinforcing Action via Adaptive Physical Latent Reasoning for VLA Models
Abstract: Vision-Language-Action (VLA) models have increasingly incorporated reasoning mechanisms for complex robotic manipulation. However, existing approaches share a critical limitation: whether employing explicit linguistic reasoning that suffers from latency and discretization, or utilizing more expressive continuous latent reasoning, they are predominantly confined to static imitation learning that limits adaptability and generalization. While online reinforcement learning (RL) has been introduced to VLAs to enable trial-and-error exploration, current methods exclusively optimize the vanilla action space, bypassing the underlying physical reasoning process. In this paper, we present \textbf{LaST-R1}, a unified VLA framework that integrates latent Chain-of-Thought (CoT) reasoning over physical dynamics prior to action execution, along with a tailored RL post-training paradigm. Specifically, we propose \textbf{Latent-to-Action Policy Optimization (LAPO)}, a novel RL algorithm that jointly optimizes the latent reasoning process and the action generation. By bridging reasoning and control, LAPO improves the representation of physical world modeling and enhances robustness in interactive environments. Furthermore, an \textbf{adaptive latent CoT mechanism} is introduced to allow the policy to dynamically adjust its reasoning horizon based on environment complexity. Extensive experiments show that LaST-R1 achieves a near-perfect 99.8\% average success rate on the LIBERO benchmark with only one-shot supervised warm-up, significantly improving convergence speed and performance over prior state-of-the-art methods. In real-world deployments, LAPO post-training yields up to a 44\% improvement over the initial warm-up policy across four complex tasks, including both single-arm and dual-arm settings. Finally, LaST-R1 demonstrates strong generalization across simulated and real-world environments.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
LaST-R1: A simple explanation
What is this paper about?
This paper is about teaching robots to be better at doing hands-on tasks (like opening a bag zipper or placing a block) by helping them “think before they act.” The authors build a new robot brain called LaST-R1 that looks at images, understands language instructions, thinks in a compact “inner voice,” and then moves. They also create a new training method so the robot learns not just how to move, but also how to think in useful ways for the physical world.
What questions are the researchers asking?
They focus on three big questions:
- Can a robot plan its moves using a quick, private kind of step-by-step thinking (instead of slow, wordy explanations) before it acts?
- Can we train the robot so it improves both its thinking and its actions by trying things out, getting rewards, and learning from mistakes?
- Can the robot decide when it needs to think a lot and when it can act quickly, depending on how hard the task is?
How did they do it?
The team built a Vision-Language-Action (VLA) model. Think of it like this:
- Vision: the robot sees through cameras.
- Language: it reads an instruction like “open the bottle cap.”
- Action: it moves its arms and grippers to do the task.
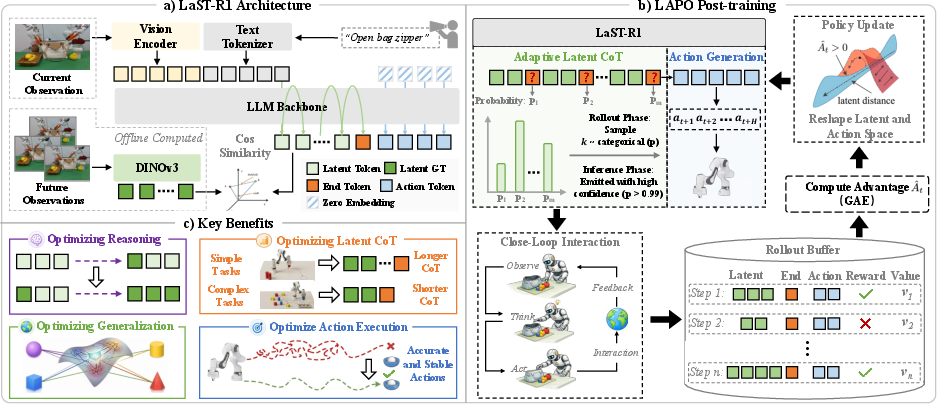
Here’s the key idea: before moving, the robot makes a short series of “latent” reasoning steps. “Latent” just means this thinking is in a compact, math-like code inside the model—like private notes in its head—rather than long sentences in English. This is faster and better for continuous motions (like smoothly rotating a cap).
To train this, they combine two phases:
- A quick warm-up where the robot copies one example of a task (one demonstration).
- Online practice with trial and error, where the robot tries the task in a simulator or real world and gets a reward if it succeeds.
They introduce a new training method called LAPO (Latent-to-Action Policy Optimization). Most robot training methods only tweak how the robot moves. LAPO tweaks both:
- the robot’s inner thinking (its “latent” reasoning), and
- the robot’s actions (how it moves).
That way, rewards can shape how the robot thinks and how it acts, making both smarter over time.
They also add “adaptive thinking.” The robot can decide how many inner thoughts it needs before acting. Easy tasks? Think briefly, act fast. Hard tasks? Think more steps, then act. This keeps the robot both efficient and careful.
Finally, they start with powerful pre-trained models that already understand images and language well, then adapt them for robot tasks. They use:
- An image model to give strong visual features (like a reliable “eye” for the robot),
- A LLM to understand instructions,
- And a way to turn continuous arm motions into tokens the model can handle.
What did they find, and why does it matter?
The results are strong in both simulation and the real world.
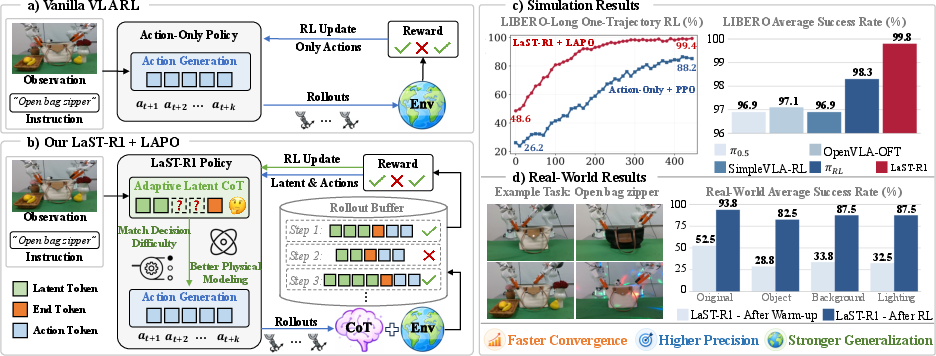
- In simulation (the LIBERO benchmark), LaST-R1 reached about 99.8% average success with just one example per task before practice. That’s near perfect and better than other top methods.
- In real-world tests (like opening a zipper or a bottle cap), LaST-R1 improved success by up to 44% compared to its starting point, reaching about 90% average success across multiple tasks.
- It also generalized well to new situations—like different objects, backgrounds, and lighting—without needing new demonstrations each time.
Why this matters:
- Thinking + acting is better than acting alone. By training the robot’s inner reasoning and its movements together, the robot understands physical situations more deeply and adapts better.
- Adaptive thinking saves time. The robot doesn’t overthink easy steps, so it’s faster, but it can plan more when things get tricky.
- Fewer examples needed. Getting lots of expert demonstrations is expensive. Succeeding with one example and then learning by practice is a big win.
Here are the main takeaways:
- The robot uses a fast, private “inner voice” (latent Chain-of-Thought) to plan before moving.
- A new training method (LAPO) lets rewards shape both thoughts and actions, not just actions.
- The robot learns to choose how long to think based on task difficulty.
- It reaches near-perfect results in simulation with minimal examples and gets strong results in the real world.
- It handles new objects and lighting better than many previous systems.
What’s the bigger picture?
This approach could make future robots more reliable and adaptable in homes, hospitals, and factories. Instead of needing thousands of examples, robots could learn quickly, think just enough for each task, and handle surprises better. The idea of training a robot’s “thinking” and “doing” together may become a foundation for smarter, safer, and more flexible robot assistants.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide concrete future work:
- Ambiguity in “offline” latent target computation: the paper claims DINOv3 latent targets are precomputed offline with zero overhead, but online RL and deployment see novel images per step; clarify how targets are obtained at runtime and quantify the true compute/latency cost if features must be computed online.
- Lack of theoretical guarantees for LAPO: the latent likelihood ratio rz uses a heuristic isotropic Gaussian centered on current outputs with fixed σ; provide convergence/bias analysis, connections to PPO/TRPO, or conditions under which joint latent–action clipping is stable.
- Hyperparameter sensitivity is underexplored: no systematic study of σ (latent variance), λ1–λ3 (loss weights), εmin/εmax (clipping), β (temperature), the 0.99 early-exit threshold, or the candidate set size/positions M for <latent_end>; report robustness curves and automatic tuning strategies.
- Latent–action coupling may double-count advantages: LAPO optimizes separate clipped objectives for latents and actions at the same step; analyze whether this biases gradient estimates or harms monotonic improvement, and explore KL-regularized joint constraints or orthogonal gradients.
- Limited interpretability of latent CoT: no probing/causal analyses show that latents encode physical dynamics or predictive structure; add diagnostics (e.g., linear probes, counterfactual interventions, rollout prediction, attention maps) to verify what is “reasoned.”
- Fixed latent geometry and distance metric: rz relies on Euclidean distance in embedding space; evaluate alternative geometries (e.g., cosine/MAHAL), learned uncertainty (learned σ or heteroscedastic models), or variational formulations that better capture latent distributions.
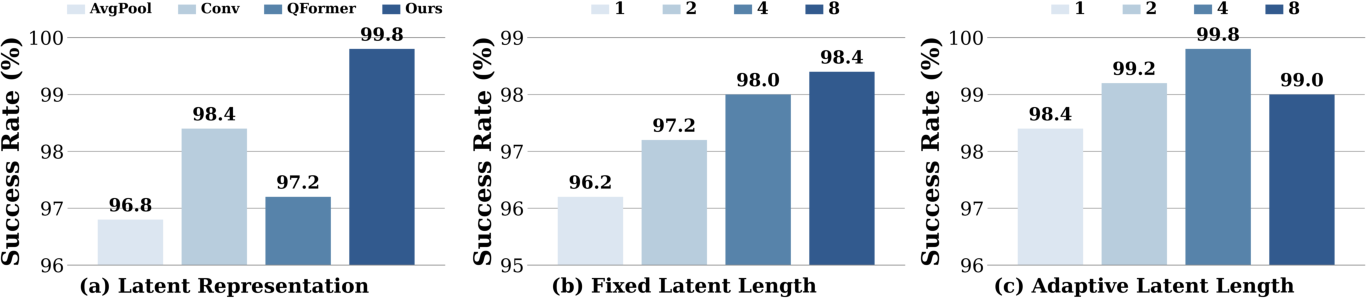
- DINOv3 “top-k channels of CLS” design is ad hoc: no ablation on k, backbone choice, or multi-scale features; benchmark alternatives (multi-layer pooling, spatial tokens, SAEs, feature distillation) and study stability under domain shift.
- Action tokenization discretization not tested against continuous control heads: compare tokenized actions to continuous Gaussian policies on precision, smoothness, jerk, and contact-rich control; quantify quantization error vs. task success.
- Euler-angle orientation representation risks singularities: assess quaternions or 6D rotation representations and analyze effects on stability and accuracy.
- Action chunk length H is not ablated: study how chunk size affects latency, control smoothness, credit assignment, and failure recovery across tasks.
- Adaptive reasoning lacks compute-aware regularization: the policy is not explicitly penalized for longer reasoning; add compute/time costs or FLOPs-regularized objectives and quantify the latency–performance frontier.
- Early-exit design is heuristic: the 0.99 confidence threshold and fixed candidate indices {2,4,6,8} are not derived; explore learned halting policies (e.g., ACT-style halting, budgeted RL), continuous halting distributions, and per-task adaptive candidate sets.
- No wall-clock real-time metrics: report end-to-end inference latency, control frequency, and time-to-action under varying reasoning lengths on both GPU and embedded hardware.
- Reward design and supervision details are sparse: clarify whether rewards are sparse/dense, shaped, or learned; study robustness to reward misspecification and extend to settings without binary task success signals.
- Safety, resets, and exploration risk in real-world RL are not addressed: detail safety constraints, reset strategies, contact/force limits, and failure handling; evaluate safe exploration methods or shielded RL.
- Sample efficiency in real world is unclear: report the number of real interactions/episodes, total time, and data budget required to reach reported success rates; compare to baselines under matched interaction budgets.
- Generalization breadth is limited: OOD tests cover objects/background/lighting but not camera pose shifts, occlusions, dynamic distractors, sensor noise, or latency; extend evaluations to these factors and report degradation profiles.
- Limited embodiment diversity: real-world tests use the same platform (Franka) with simple bi-manual concatenation; assess cross-embodiment transfer (different arms/hands), kinematic mismatch, and explicit bi-manual coordination constraints.
- No explicit 3D or multi-view fusion: sim uses a single view; real-world uses three cameras without 3D scene grounding; evaluate depth/3D reconstruction or calibrated multi-view fusion to handle occlusions and viewpoint changes.
- Memory over very long horizons: latent CoT is capped at Nmax=8; study tasks requiring longer-term memory, recurrence across steps, or hierarchical planning with subgoals/options.
- Critic design choice is narrow: value uses only the <latent_end> embedding; compare alternatives (pooling over latents, cross-attention to visual tokens, dual encoders) and report critic accuracy/stability.
- Failure-mode analysis is missing: characterize when LAPO degrades performance (e.g., latents locking into suboptimal manifolds, catastrophic forgetting, non-stationarity) and propose mitigations (e.g., replay, regularization, curriculum).
- Fairness of baseline comparisons: some baselines have different warm-up datasets or camera setups; include matched-setting re-runs or normalized data/compute budgets to isolate algorithmic gains.
- Language robustness not evaluated: test sensitivity to instruction paraphrases, longer compositional prompts, and ambiguous/underspecified language; evaluate instruction grounding failures.
- Domain shift in foundation features: freezing DINOv3 may be brittle in robot domains; assess fine-tuning/adapter strategies for DINO, domain-adaptive pretraining, or confidence-triggered fallback when visual features are unreliable.
- Dual-arm coordination is implicit: concatenated actions lack explicit coordination models (e.g., relative constraints, shared objectives, force synchrony); evaluate constrained or graph-structured policies for coordinated bi-manual manipulation.
Practical Applications
Immediate Applications
The following applications can be deployed with current robotics stacks, subject to standard integration and safety practices. Each item includes sectors, tools/products/workflows that could emerge, and key assumptions/dependencies.
- On-site adaptation of robotic manipulators for new SKUs and fixtures
- Sectors: Robotics, Manufacturing, Logistics, E-commerce fulfillment
- What: Use LaST-R1’s one-shot SFT warm-up followed by LAPO online RL to adapt pick-place, kitting, packing, fastening, and insertion tasks to new object geometries, packaging, or bin layouts with minimal demonstrations.
- Tools/workflows: “LAPO Trainer” module added to existing robot cell; quick SFT from a single demonstration; on-line RL with reward signals from success detectors; LoRA-based on-robot updates for fast iteration.
- Assumptions/dependencies: Access to a pretrained VLA backbone (e.g., Qwen3-VL family), safe reward design, environment reset capability, calibrated cameras (single or multi-view), and safety interlocks for exploration.
- Rapid deployment of dual-arm coordination skills
- Sectors: Robotics, Manufacturing (assembly), Consumer electronics repair/refurbishment, Lab automation
- What: Leverage latent reasoning-before-acting to coordinate bimanual tasks (e.g., zipper manipulation, cap twisting, cable routing, sponge wiping).
- Tools/workflows: Dual-arm LaST-R1 policy with synchronized action-token decoding; “Bimanual Skill Pack” containing action tokenizers and grasp planners.
- Assumptions/dependencies: Dual-arm control stack with 14-DoF mapping, reliable grasp sensing, and safe-force control for contact-rich manipulation.
- Fast line changeovers with minimal downtime
- Sectors: Manufacturing, Food & beverage packaging, Automotive
- What: Use adaptive latent CoT to shorten inference on routine motions and extend reasoning on novel layouts, speeding convergence during shifts or SKU swaps.
- Tools/workflows: “Reasoning Budget Controller” that adjusts <latent_end> thresholds to meet takt-time constraints; KPI dashboards for convergence speed and success rate.
- Assumptions/dependencies: Stable reward proxies (e.g., vision-based success metrics), compute on edge GPU, and process monitoring to cap exploration.
- Generalization to visual perturbations without new labels
- Sectors: Robotics, Warehousing/logistics, Retail, Field operations
- What: Improve robustness to lighting, background, and object variations via LAPO post-training on-site, reducing re-labeling and data collection.
- Tools/workflows: “OOD Stress Test Suite” that schedules RL rollouts under varied lights/backgrounds, with automated pass/fail criteria.
- Assumptions/dependencies: On-site cameras with configurable exposure/lighting; domain randomization scripts; safety perimeter for trial-and-error.
- Precision insertion and fastening under tight tolerances
- Sectors: Electronics assembly, Medical devices manufacturing, Aerospace
- What: Deploy latent-anchored reasoning (DINOv3 targets) to stabilize micro-adjustments in insertion, threading, or screwing.
- Tools/workflows: “Fine-Motion Controller” that fuses force/vision cues; micro-reward shaping for alignment and insertion depth.
- Assumptions/dependencies: High-quality vision and optionally force/torque sensing; sub-millimeter calibration; conservative exploration bounds.
- On-robot RL with low-touch updates
- Sectors: Robotics, SME manufacturing, RaaS providers
- What: Use LoRA-only updates to adapt policies on real hardware quickly, reducing downtime and compute cost.
- Tools/workflows: “LoRA Tuner for Robotics” that hot-swaps adapters per task; rollback checkpoints; continuous evaluation harness.
- Assumptions/dependencies: Sufficient on-robot GPU; robust checkpointing; operations protocols for halting/continuing runs safely.
- Simulation-to-real transfer with quick RL refinement
- Sectors: Robotics, Education, Academic labs, Prototyping shops
- What: Start with sim-trained LaST-R1 and run brief LAPO post-training to bridge sim2real gaps in new labs or classrooms.
- Tools/workflows: Sim curriculum + automatic real-world fine-tuning jobs; “Sim-to-Real Health Check” for drift/latency; standardized LIBERO-style testbeds.
- Assumptions/dependencies: High-fidelity sim assets; task-aligned reward shaping; safe execution wrappers.
- Research acceleration in manipulation reasoning
- Sectors: Academia, Robotics startups, Foundation model labs
- What: Use LaST-R1/LAPO to study how latent reasoning affects credit assignment, sample efficiency, and OOD generalization, replacing action-only PPO baselines.
- Tools/workflows: Open-source “LAPO Library” with hooks for latent logging/visualization; ablation packs for latent length, DINOv3 anchoring, and tokenization.
- Assumptions/dependencies: Access to datasets (e.g., LIBERO, DROID), reproducible training infra, and GPU time.
- Safer, more efficient on-robot learning procedures
- Sectors: Policy/governance for robotics deployments, Safety engineering
- What: Codify guardrails for online RL on hardware (e.g., early-exit reasoning thresholds, action clipping, emergency stop integration).
- Tools/workflows: “RL Safety Wrapper” integrating force limits, workspace geofencing, and exploration budgets; compliance checklists for real-world learning.
- Assumptions/dependencies: Organizational safety culture, appropriate sensors, and documented shutdown pathways.
- Better compute utilization in embedded inference
- Sectors: Edge AI hardware, Mobile manipulation
- What: Adaptive latent CoT reduces compute on easy states, lowering power draw and latency on embedded platforms.
- Tools/workflows: “Adaptive Inference Runtime” that couples <latent_end> with dynamic batching and DVFS (dynamic voltage and frequency scaling).
- Assumptions/dependencies: Support for token-parallel decoding; telemetry to monitor thermal and latency budgets.
Long-Term Applications
These use cases need further research, larger-scale validation, integration with domain-specific safety/quality standards, or hardware scaling.
- Home and hospitality service robots with continual adaptation
- Sectors: Consumer robotics, Hospitality, Facilities services
- What: Personalized chores (tidying, dish loading, laundry handling), room setup, and maintenance with few-shot adaptation to each home/hotel.
- Tools/workflows: Federated LAPO post-training across fleets; home-safe exploration policies; user-in-the-loop correction loops.
- Assumptions/dependencies: Strong safety guarantees for exploration near humans; robust object/scene understanding; privacy-preserving update pipelines.
- Assistive care and clinical support manipulation
- Sectors: Healthcare, Eldercare, Rehabilitation
- What: Non-invasive assistive tasks (fetch-and-carry, opening containers, organizing supplies) with reasoning-before-acting to reduce failure modes.
- Tools/workflows: Medical-grade “Assistive Manipulation Suite” with verified rewards, haptic feedback, and clinician override interfaces.
- Assumptions/dependencies: Regulatory approvals, formal safety verification, high reliability under strict hygiene and liability constraints.
- Field maintenance and inspection in energy and utilities
- Sectors: Energy (solar/wind), Oil & gas, Water utilities, Nuclear (restricted)
- What: Component handling (valve turning, connector fastening, debris removal) with OOD robustness to weather, lighting, and wear.
- Tools/workflows: “Field-RL Pack” for on-site fine-tuning; ruggedized sensing; remote human oversight tools and kill switches.
- Assumptions/dependencies: Harsh-environment hardware, connectivity for supervision, strict risk management for exploration.
- Construction, disaster response, and decommissioning manipulation
- Sectors: Construction, Public safety, Environmental remediation
- What: Ad hoc manipulation in unstructured scenes (door opening, cutting, lifting, debris clearing) with adaptive reasoning scopes.
- Tools/workflows: Integrated teleop + LAPO co-learning; curriculum RL from mock sites; safety envelopes for fragile or hazardous materials.
- Assumptions/dependencies: Advanced perception in dust/smoke; robust locomotion; multi-sensor fusion; disaster-zone safety protocols.
- Multi-robot and human-robot teaming with shared latent reasoning
- Sectors: Warehousing, Manufacturing, Space robotics, Agriculture
- What: Share latent CoT representations across agents to coordinate tasks (handoffs, sequencing, collaborative assembly).
- Tools/workflows: “Latent Bus” for cross-agent reasoning tokens; joint-LAPO with multi-agent credit assignment; consistency regularizers.
- Assumptions/dependencies: Low-latency comms, distributed RL stability, conflict resolution/safety across agents.
- Autonomous laboratories and scientific manipulation
- Sectors: Pharma/biotech, Materials, Chemistry automation
- What: Complex pipetting, sample prep, and instrument operation with adaptive planning horizons tuned to protocol complexity.
- Tools/workflows: “Lab-LAPO” with task graphs and outcome assays as reward signals; electronic lab notebook integration.
- Assumptions/dependencies: High-precision end-effectors, contamination control, standardized interfaces to instruments.
- Standardized evaluation and certification of latent-reasoning robots
- Sectors: Policy, Standards bodies, Insurance
- What: Benchmarks and certification processes emphasizing OOD generalization, safe online RL, and latency/energy profiles of adaptive reasoning.
- Tools/workflows: Public test suites beyond LIBERO (lighting, background, deformables); audit tools for latent token dynamics and failure forensics.
- Assumptions/dependencies: Industry consensus, transparency requirements, third-party labs, and incident reporting frameworks.
- Hardware-software co-design for latent reasoning acceleration
- Sectors: Semiconductors, Edge AI systems, Robotics platforms
- What: Accelerators for parallel action-token decoding and variable-length latent generation; low-latency KV-cache reuse.
- Tools/workflows: “Reasoning-Aware Schedulers” and compiler passes; token-parallel kernels optimized for control loops.
- Assumptions/dependencies: Vendor support, standardized model graph definitions, thermal/power headroom on mobile platforms.
- Tool-use and deformable-object manipulation at scale
- Sectors: Household robotics, Food processing, Textile handling
- What: Learn complex, contact-rich behaviors (cutting, wiping, folding, packaging flexible items) via joint latent-action optimization.
- Tools/workflows: Physics-informed reward shaping; tactile+vision fusion; deformable simulation pretraining.
- Assumptions/dependencies: Reliable tactile sensing, sim fidelity for deformables, safe contact exploration.
- Cross-embodiment policy reuse via latent anchors
- Sectors: Robotics OEMs, RaaS, Education
- What: Transfer skills across different arms/grippers by preserving DINOv3-based latent targets and re-tokenizing actions per platform.
- Tools/workflows: “Embodiment Adapter” that maps latent CoT to robot-specific action vocabularies; automated calibration pipelines.
- Assumptions/dependencies: Accurate kinematics/dynamics models, embodiment-agnostic visual features, domain-specific safety tuning.
- Cloud services for fleet-wide continual improvement
- Sectors: Robotics platforms, Enterprise IT, Cloud providers
- What: Privacy-preserving aggregation of rollouts and rewards to deliver improved LaST-R1 weights/adapters back to fleets.
- Tools/workflows: Federated RL orchestration; drift detection; staged rollouts (canary → full deployment).
- Assumptions/dependencies: Data governance, bandwidth, secure model update mechanisms, rollback capabilities.
Notes on common assumptions and dependencies
- Model and data: Access to a strong VLA backbone (e.g., Qwen3-VL-4B or similar), pretraining on diverse manipulation datasets, and offline DINOv3 feature extraction for latent anchoring.
- Hardware and sensing: Calibrated cameras (potentially multi-view), reliable grasp/force sensing for contact-rich tasks, and sufficient edge compute for token-parallel decoding.
- RL safety: Well-defined rewards, exploration limits, and interlocks (E-stop, action/force clipping, geofencing); environment reset mechanisms.
- Software integration: Action tokenization compatible with robot controllers, KV-cache reuse for low latency, LoRA-based on-robot updates for practical iteration.
- Governance and compliance: Safety certification, incident logging, privacy-preserving data handling, and auditability of learning runs and latent dynamics.
Glossary
- 2D-RoPE: Two-dimensional rotary positional embeddings used to encode spatial positions in vision transformers. "2D-RoPE with interpolated absolute positional embeddings"
- Action chunk: A sequence of low-level control commands executed over a short horizon as a single policy output. "action chunk "
- Action tokenizer: A discretization scheme that maps continuous robot actions to discrete tokens for sequence modeling. "We adopt a parameter-free action tokenizer"
- Advantage estimate: A policy-gradient signal measuring how much better an action is than the state’s baseline value. "and denotes the advantage estimate"
- Autoregressive generation: Sequentially predicting tokens where each token conditions on previously generated tokens. "The model autoregressively produces latent reasoning tokens"
- Bidirectional attention: An attention mechanism that allows tokens to attend to both past and future positions in a sequence. "with bidirectional attention over placeholder vectors."
- Chain-of-Thought (CoT): A reasoning paradigm where intermediate steps are produced to guide decision-making. "Chain-of-Thought (CoT) reasoning"
- CLS token: A special pooled representation token used by vision transformers as a holistic image embedding. "we extract its <CLS> token"
- Clipped surrogate loss: A PPO-style objective that clips probability ratios to stabilize policy updates. "we compute a joint LAPO clipped surrogate loss."
- DINOv3: A vision foundation model providing rich, semantically dense features for image understanding. "using DINOv3~\cite{simeoni2025dinov3}, a state-of-the-art vision foundation model."
- Discount factor: The parameter that down-weights future rewards in reinforcement learning. "where is the discount factor"
- DoF (Degrees of Freedom): Independent controllable motion axes in a robot’s kinematic structure. "a 7-DoF end-effector control vector"
- End-effector: The robot’s tool or gripper whose pose and state are controlled to manipulate objects. "end-effector control vector"
- Euler angles: A 3-parameter representation of 3D orientation using rotations about coordinate axes. "represented as Euler angles"
- Generalized Advantage Estimation (GAE): A variance-reduced method to compute advantage signals from trajectories. "via Generalized Advantage Estimation (GAE)"
- Isotropic Gaussian: A Gaussian distribution with equal variance in all dimensions, often used for simple likelihood modeling. "using an isotropic Gaussian centered at the current policy output"
- KV cache: Cached key/value tensors from transformer attention layers reused to speed up decoding. "we reuse the KV cache from the latent generation phase"
- Latent Chain-of-Thought (CoT): Internal, non-linguistic reasoning steps represented in a compact latent space prior to acting. "latent Chain-of-Thought (CoT) reasoning"
- Latent-to-Action Policy Optimization (LAPO): An RL algorithm that jointly optimizes latent reasoning tokens and action outputs. "Latent-to-Action Policy Optimization (LAPO)"
- latent_end token: A special token signaling the end of latent reasoning and transition to action prediction. "a special <latent\_end> token"
- LLM backbone: The LLM core used to process token sequences and generate latents/actions. "and fed into the LLM backbone"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects trainable low-rank adapters into attention layers. "we incorporate Low-Rank Adaptation (LoRA)~\cite{hu2022lora} into all attention layers of LaST-R1"
- Out-of-distribution (OOD): Data or tasks that differ from the training distribution, used to assess generalization. "out-of-distribution (OOD) generalization"
- Parallel decoding: Producing multiple output tokens in one forward pass to improve inference efficiency. "while employing parallel decoding to improve inference efficiency~\cite{kim2025fine}."
- Proximal Policy Optimization (PPO): A popular on-policy RL algorithm using clipped objectives for stable updates. "Proximal Policy Optimization (PPO) \cite{schulman2017proximal}"
- Q-Former: A query transformer module that extracts a compact set of latent tokens from visual features. "extracting latents using a Q-Former~\cite{li2023blip}."
- Qwen3-VL-4B: A multimodal large model used as the base VLA backbone. "pre-trained Qwen3-VL-4B \cite{bai2025qwen3vltechnicalreport}"
- SE(3): The Lie group of 3D rigid-body poses combining rotations and translations. "in space."
- SigLIP2-Large: A vision encoder model producing dense visual tokens for downstream reasoning and control. "SigLIP2-Large, which employs 2D-RoPE"
- Top-k selection: Selecting the k largest-magnitude features to form a compact latent target vector. "apply top- ( = 2560) selection"
- Value head: A neural head that estimates the state value for advantage computation in actor-critic RL. "we introduce a value head composed of a 4-layer MLP to estimate state values"
- Vision-Language-Action (VLA): Models that map multimodal observations and instructions to control actions for robotics. "Vision-Language-Action (VLA) models"
- Zero-shot generalization: Successful performance on unseen conditions without task-specific fine-tuning. "achieves zero-shot generalization to unseen objects, backgrounds, and lighting conditions"
Collections
Sign up for free to add this paper to one or more collections.